 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Cross-Lingual Cross-Age Group Adaptation for Low-Resource Elderly Speech Emotion Recognition
Jun 26, 2023
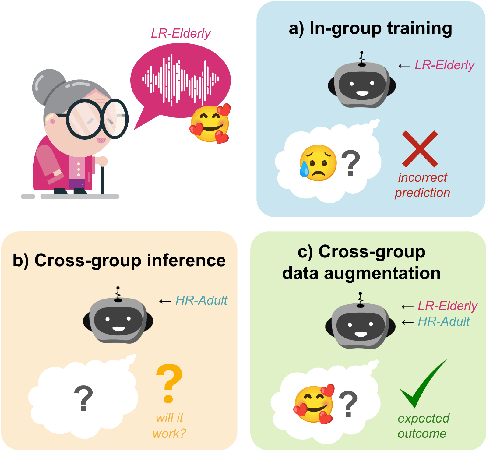
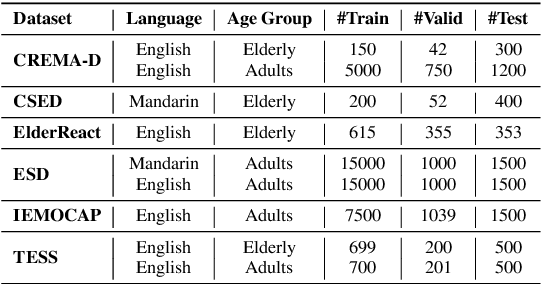
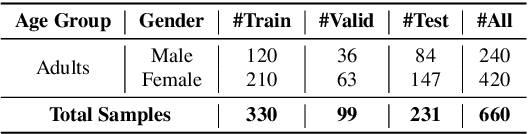
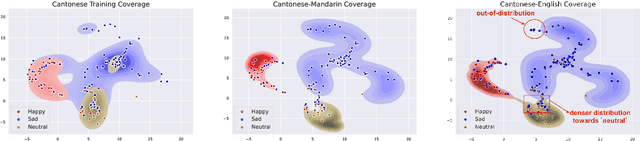
Speech emotion recognition plays a crucial role in human-computer interactions. However, most speech emotion recognition research is biased toward English-speaking adults, which hinders its applicability to other demographic groups in different languages and age groups. In this work, we analyze the transferability of emotion recognition across three different languages--English, Mandarin Chinese, and Cantonese; and 2 different age groups--adults and the elderly. To conduct the experiment, we develop an English-Mandarin speech emotion benchmark for adults and the elderly, BiMotion, and a Cantonese speech emotion dataset, YueMotion. This study concludes that different language and age groups require specific speech features, thus making cross-lingual inference an unsuitable method. However, cross-group data augmentation is still beneficial to regularize the model, with linguistic distance being a significant influence on cross-lingual transferability. We release publicly release our code at https://github.com/HLTCHKUST/elderly_ser.
Active Learning for Classifying 2D Grid-Based Level Completability
Sep 08, 2023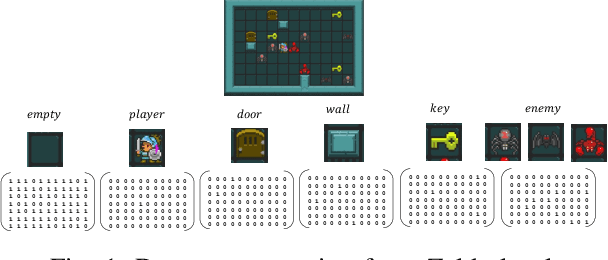
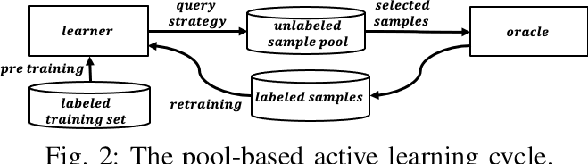
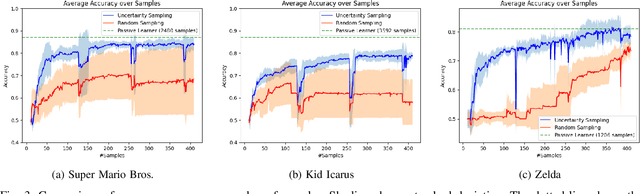
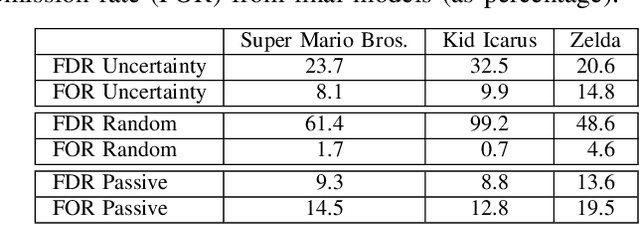
Determining the completability of levels generated by procedural generators such as machine learning models can be challenging, as it can involve the use of solver agents that often require a significant amount of time to analyze and solve levels. Active learning is not yet widely adopted in game evaluations, although it has been used successfully in natural language processing, image and speech recognition, and computer vision, where the availability of labeled data is limited or expensive. In this paper, we propose the use of active learning for learning level completability classification. Through an active learning approach, we train deep-learning models to classify the completability of generated levels for Super Mario Bros., Kid Icarus, and a Zelda-like game. We compare active learning for querying levels to label with completability against random queries. Our results show using an active learning approach to label levels results in better classifier performance with the same amount of labeled data.
* 4 pages, 3 figures
Prompting Audios Using Acoustic Properties For Emotion Representation
Oct 05, 2023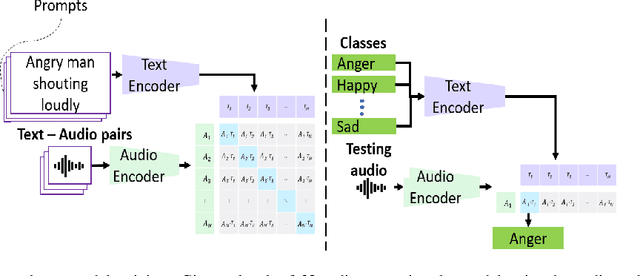
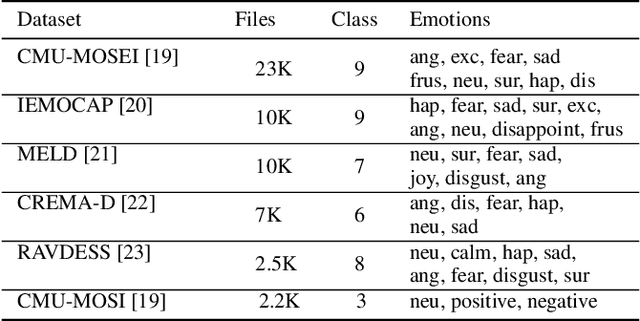
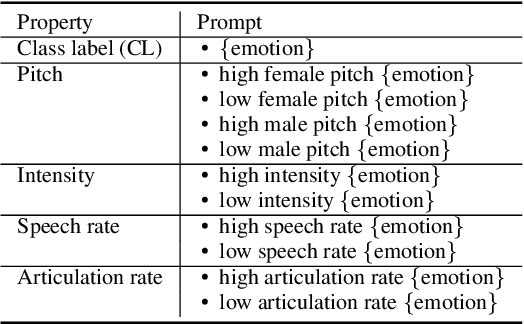
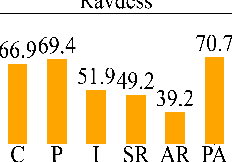
Emotions lie on a continuum, but current models treat emotions as a finite valued discrete variable. This representation does not capture the diversity in the expression of emotion. To better represent emotions we propose the use of natural language descriptions (or prompts). In this work, we address the challenge of automatically generating these prompts and training a model to better learn emotion representations from audio and prompt pairs. We use acoustic properties that are correlated to emotion like pitch, intensity, speech rate, and articulation rate to automatically generate prompts i.e. 'acoustic prompts'. We use a contrastive learning objective to map speech to their respective acoustic prompts. We evaluate our model on Emotion Audio Retrieval and Speech Emotion Recognition. Our results show that the acoustic prompts significantly improve the model's performance in EAR, in various Precision@K metrics. In SER, we observe a 3.8% relative accuracy improvement on the Ravdess dataset.
ViSoBERT: A Pre-Trained Language Model for Vietnamese Social Media Text Processing
Oct 28, 2023English and Chinese, known as resource-rich languages, have witnessed the strong development of transformer-based language models for natural language processing tasks. Although Vietnam has approximately 100M people speaking Vietnamese, several pre-trained models, e.g., PhoBERT, ViBERT, and vELECTRA, performed well on general Vietnamese NLP tasks, including POS tagging and named entity recognition. These pre-trained language models are still limited to Vietnamese social media tasks. In this paper, we present the first monolingual pre-trained language model for Vietnamese social media texts, ViSoBERT, which is pre-trained on a large-scale corpus of high-quality and diverse Vietnamese social media texts using XLM-R architecture. Moreover, we explored our pre-trained model on five important natural language downstream tasks on Vietnamese social media texts: emotion recognition, hate speech detection, sentiment analysis, spam reviews detection, and hate speech spans detection. Our experiments demonstrate that ViSoBERT, with far fewer parameters, surpasses the previous state-of-the-art models on multiple Vietnamese social media tasks. Our ViSoBERT model is available only for research purposes.
Deep Transfer Learning for Automatic Speech Recognition: Towards Better Generalization
Apr 27, 2023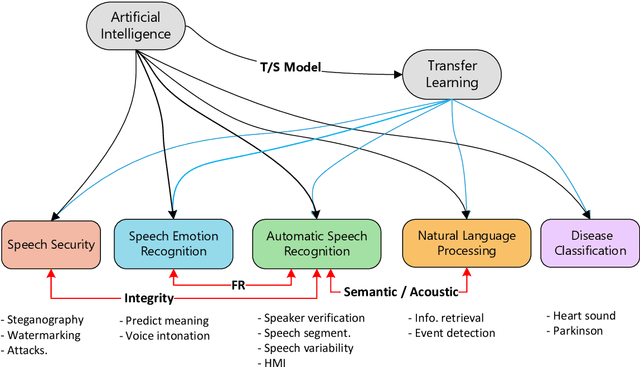
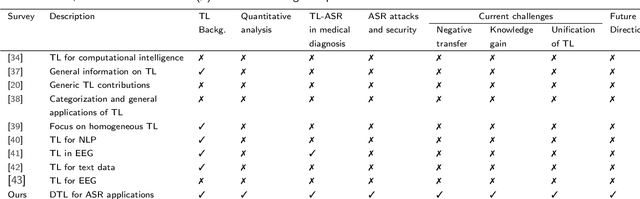
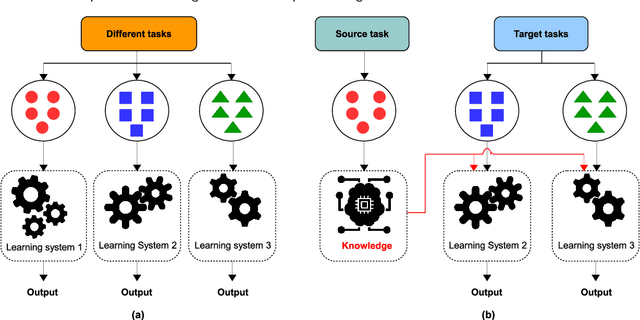

Automatic speech recognition (ASR) has recently become an important challenge when using deep learning (DL). It requires large-scale training datasets and high computational and storage resources. Moreover, DL techniques and machine learning (ML) approaches in general, hypothesize that training and testing data come from the same domain, with the same input feature space and data distribution characteristics. This assumption, however, is not applicable in some real-world artificial intelligence (AI) applications. Moreover, there are situations where gathering real data is challenging, expensive, or rarely occurring, which can not meet the data requirements of DL models. deep transfer learning (DTL) has been introduced to overcome these issues, which helps develop high-performing models using real datasets that are small or slightly different but related to the training data. This paper presents a comprehensive survey of DTL-based ASR frameworks to shed light on the latest developments and helps academics and professionals understand current challenges. Specifically, after presenting the DTL background, a well-designed taxonomy is adopted to inform the state-of-the-art. A critical analysis is then conducted to identify the limitations and advantages of each framework. Moving on, a comparative study is introduced to highlight the current challenges before deriving opportunities for future research.
AVATAR: Robust Voice Search Engine Leveraging Autoregressive Document Retrieval and Contrastive Learning
Sep 04, 2023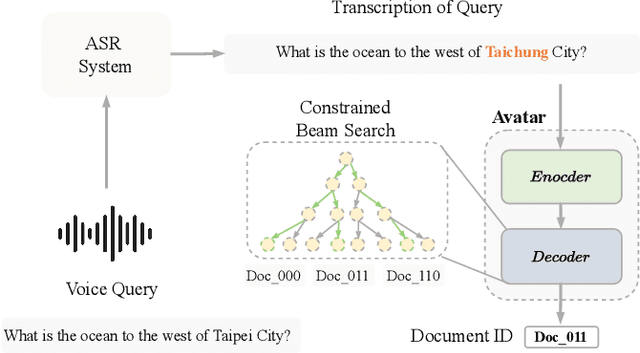
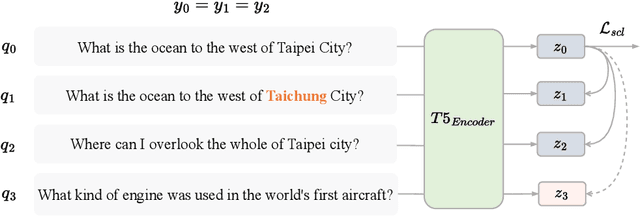

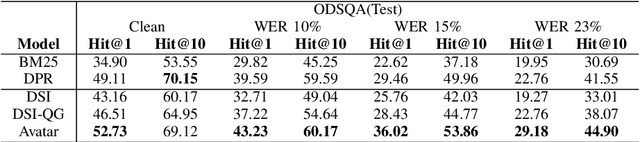
Voice, as input, has progressively become popular on mobiles and seems to transcend almost entirely text input. Through voice, the voice search (VS) system can provide a more natural way to meet user's information needs. However, errors from the automatic speech recognition (ASR) system can be catastrophic to the VS system. Building on the recent advanced lightweight autoregressive retrieval model, which has the potential to be deployed on mobiles, leading to a more secure and personal VS assistant. This paper presents a novel study of VS leveraging autoregressive retrieval and tackles the crucial problems facing VS, viz. the performance drop caused by ASR noise, via data augmentations and contrastive learning, showing how explicit and implicit modeling the noise patterns can alleviate the problems. A series of experiments conducted on the Open-Domain Question Answering (ODSQA) confirm our approach's effectiveness and robustness in relation to some strong baseline systems.
Pre-Finetuning for Few-Shot Emotional Speech Recognition
Feb 28, 2023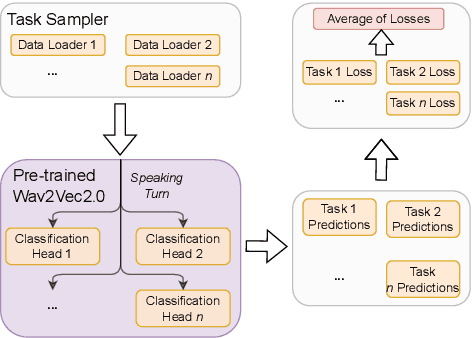
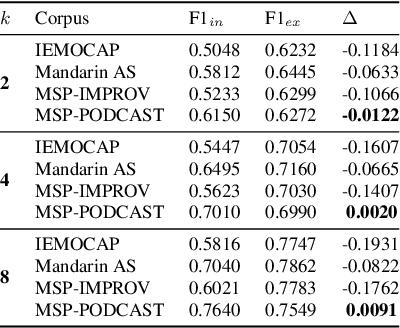
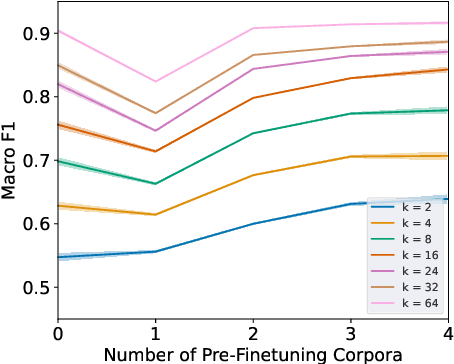
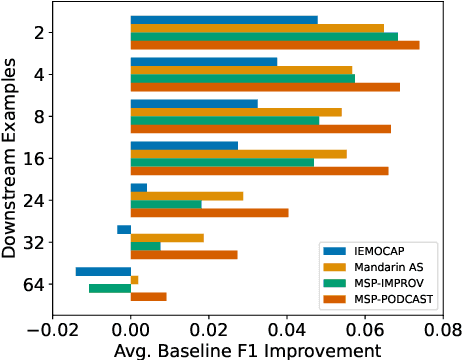
Speech models have long been known to overfit individual speakers for many classification tasks. This leads to poor generalization in settings where the speakers are out-of-domain or out-of-distribution, as is common in production environments. We view speaker adaptation as a few-shot learning problem and propose investigating transfer learning approaches inspired by recent success with pre-trained models in natural language tasks. We propose pre-finetuning speech models on difficult tasks to distill knowledge into few-shot downstream classification objectives. We pre-finetune Wav2Vec2.0 on every permutation of four multiclass emotional speech recognition corpora and evaluate our pre-finetuned models through 33,600 few-shot fine-tuning trials on the Emotional Speech Dataset.
Effect of Attention and Self-Supervised Speech Embeddings on Non-Semantic Speech Tasks
Aug 30, 2023Human emotion understanding is pivotal in making conversational technology mainstream. We view speech emotion understanding as a perception task which is a more realistic setting. With varying contexts (languages, demographics, etc.) different share of people perceive the same speech segment as a non-unanimous emotion. As part of the ACM Multimedia 2023 Computational Paralinguistics ChallengE (ComParE) in the EMotion Share track, we leverage their rich dataset of multilingual speakers and multi-label regression target of 'emotion share' or perception of that emotion. We demonstrate that the training scheme of different foundation models dictates their effectiveness for tasks beyond speech recognition, especially for non-semantic speech tasks like emotion understanding. This is a very complex task due to multilingual speakers, variability in the target labels, and inherent imbalance in the regression dataset. Our results show that HuBERT-Large with a self-attention-based light-weight sequence model provides 4.6% improvement over the reported baseline.
End-to-End Automatic Speech Recognition model for the Sudanese Dialect
Dec 21, 2022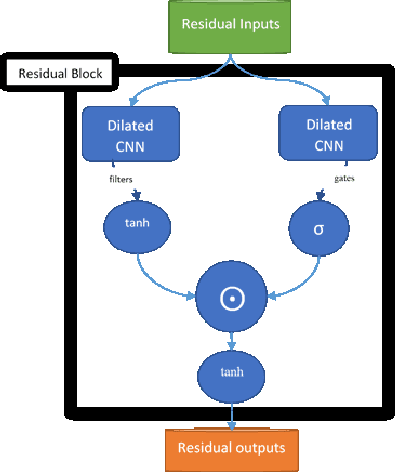

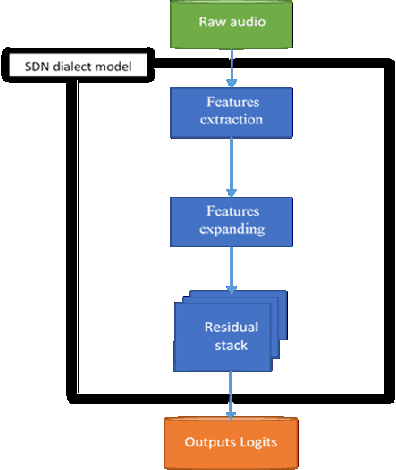

Designing a natural voice interface rely mostly on Speech recognition for interaction between human and their modern digital life equipment. In addition, speech recognition narrows the gap between monolingual individuals to better exchange communication. However, the field lacks wide support for several universal languages and their dialects, while most of the daily conversations are carried out using them. This paper comes to inspect the viability of designing an Automatic Speech Recognition model for the Sudanese dialect, which is one of the Arabic Language dialects, and its complexity is a product of historical and social conditions unique to its speakers. This condition is reflected in both the form and content of the dialect, so this paper gives an overview of the Sudanese dialect and the tasks of collecting represented resources and pre-processing performed to construct a modest dataset to overcome the lack of annotated data. Also proposed end- to-end speech recognition model, the design of the model was formed using Convolution Neural Networks. The Sudanese dialect dataset would be a stepping stone to enable future Natural Language Processing research targeting the dialect. The designed model provided some insights into the current recognition task and reached an average Label Error Rate of 73.67%.
Benchmarking Evaluation Metrics for Code-Switching Automatic Speech Recognition
Nov 22, 2022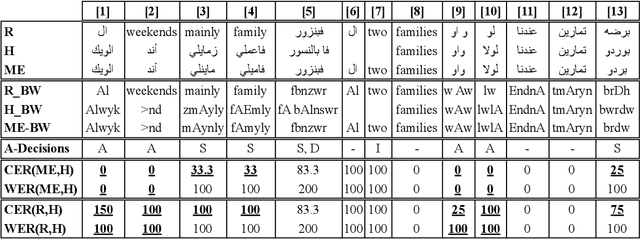

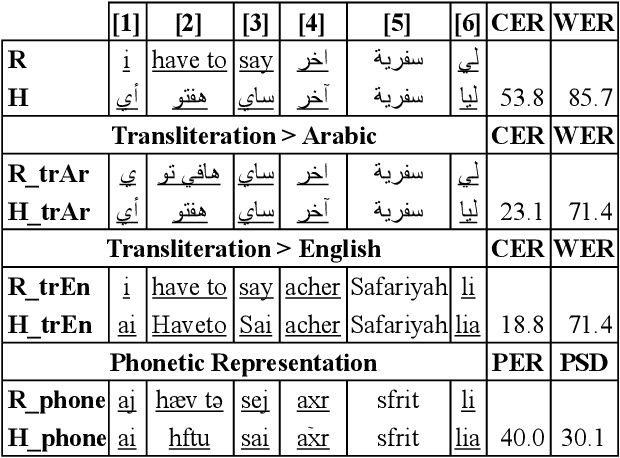

Code-switching poses a number of challenges and opportunities for multilingual automatic speech recognition. In this paper, we focus on the question of robust and fair evaluation metrics. To that end, we develop a reference benchmark data set of code-switching speech recognition hypotheses with human judgments. We define clear guidelines for minimal editing of automatic hypotheses. We validate the guidelines using 4-way inter-annotator agreement. We evaluate a large number of metrics in terms of correlation with human judgments. The metrics we consider vary in terms of representation (orthographic, phonological, semantic), directness (intrinsic vs extrinsic), granularity (e.g. word, character), and similarity computation method. The highest correlation to human judgment is achieved using transliteration followed by text normalization. We release the first corpus for human acceptance of code-switching speech recognition results in dialectal Arabic/English conversation speech.