 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
AutoPrep: An Automatic Preprocessing Framework for In-the-Wild Speech Data
Sep 25, 2023
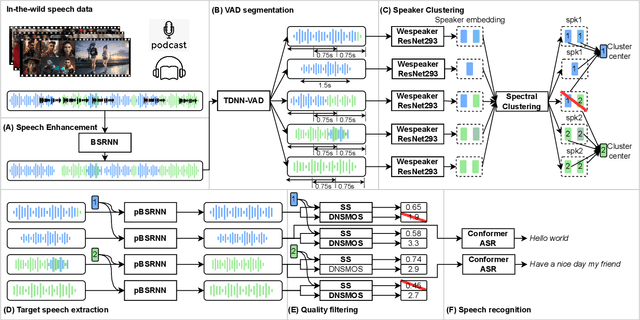
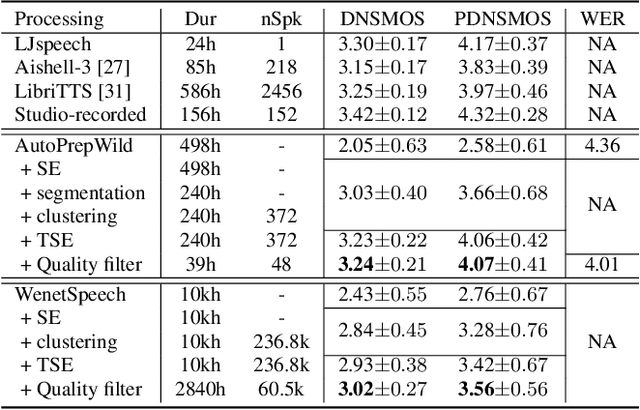

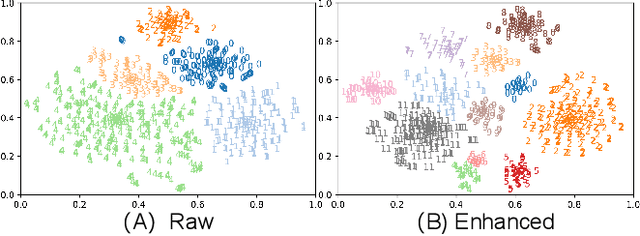
Recently, the utilization of extensive open-sourced text data has significantly advanced the performance of text-based large language models (LLMs). However, the use of in-the-wild large-scale speech data in the speech technology community remains constrained. One reason for this limitation is that a considerable amount of the publicly available speech data is compromised by background noise, speech overlapping, lack of speech segmentation information, missing speaker labels, and incomplete transcriptions, which can largely hinder their usefulness. On the other hand, human annotation of speech data is both time-consuming and costly. To address this issue, we introduce an automatic in-the-wild speech data preprocessing framework (AutoPrep) in this paper, which is designed to enhance speech quality, generate speaker labels, and produce transcriptions automatically. The proposed AutoPrep framework comprises six components: speech enhancement, speech segmentation, speaker clustering, target speech extraction, quality filtering and automatic speech recognition. Experiments conducted on the open-sourced WenetSpeech and our self-collected AutoPrepWild corpora demonstrate that the proposed AutoPrep framework can generate preprocessed data with similar DNSMOS and PDNSMOS scores compared to several open-sourced TTS datasets. The corresponding TTS system can achieve up to 0.68 in-domain speaker similarity.
Open-vocabulary Keyword-spotting with Adaptive Instance Normalization
Sep 13, 2023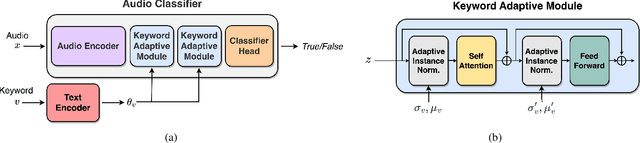

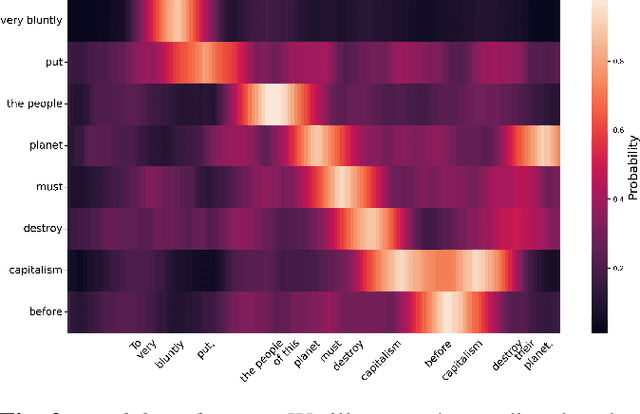
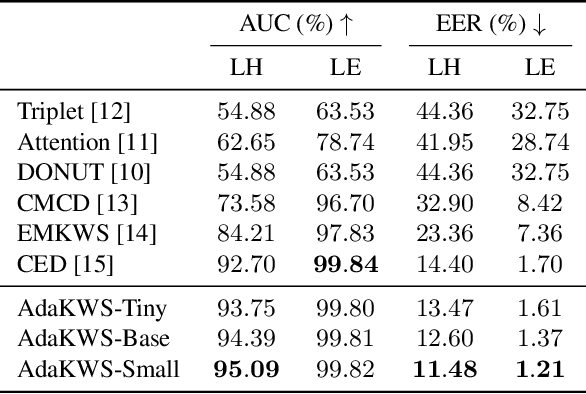
Open vocabulary keyword spotting is a crucial and challenging task in automatic speech recognition (ASR) that focuses on detecting user-defined keywords within a spoken utterance. Keyword spotting methods commonly map the audio utterance and keyword into a joint embedding space to obtain some affinity score. In this work, we propose AdaKWS, a novel method for keyword spotting in which a text encoder is trained to output keyword-conditioned normalization parameters. These parameters are used to process the auditory input. We provide an extensive evaluation using challenging and diverse multi-lingual benchmarks and show significant improvements over recent keyword spotting and ASR baselines. Furthermore, we study the effectiveness of our approach on low-resource languages that were unseen during the training. The results demonstrate a substantial performance improvement compared to baseline methods.
speech and noise dual-stream spectrogram refine network with speech distortion loss for robust speech recognition
May 30, 2023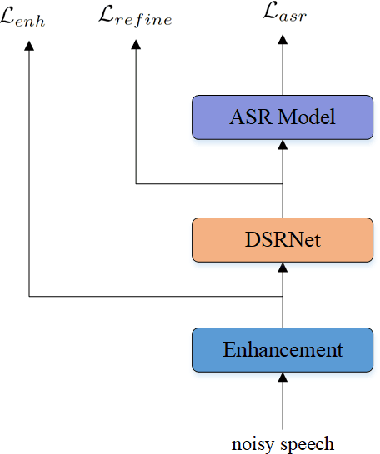

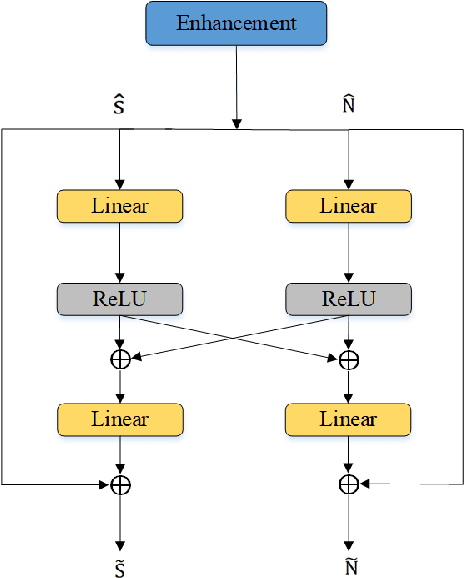
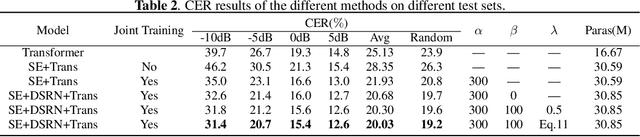
In recent years, the joint training of speech enhancement front-end and automatic speech recognition (ASR) back-end has been widely used to improve the robustness of ASR systems. Traditional joint training methods only use enhanced speech as input for the backend. However, it is difficult for speech enhancement systems to directly separate speech from input due to the diverse types of noise with different intensities. Furthermore, speech distortion and residual noise are often observed in enhanced speech, and the distortion of speech and noise is different. Most existing methods focus on fusing enhanced and noisy features to address this issue. In this paper, we propose a dual-stream spectrogram refine network to simultaneously refine the speech and noise and decouple the noise from the noisy input. Our proposed method can achieve better performance with a relative 8.6% CER reduction.
Corpus Synthesis for Zero-shot ASR domain Adaptation using Large Language Models
Sep 18, 2023While Automatic Speech Recognition (ASR) systems are widely used in many real-world applications, they often do not generalize well to new domains and need to be finetuned on data from these domains. However, target-domain data usually are not readily available in many scenarios. In this paper, we propose a new strategy for adapting ASR models to new target domains without any text or speech from those domains. To accomplish this, we propose a novel data synthesis pipeline that uses a Large Language Model (LLM) to generate a target domain text corpus, and a state-of-the-art controllable speech synthesis model to generate the corresponding speech. We propose a simple yet effective in-context instruction finetuning strategy to increase the effectiveness of LLM in generating text corpora for new domains. Experiments on the SLURP dataset show that the proposed method achieves an average relative word error rate improvement of $28\%$ on unseen target domains without any performance drop in source domains.
CoMFLP: Correlation Measure based Fast Search on ASR Layer Pruning
Sep 21, 2023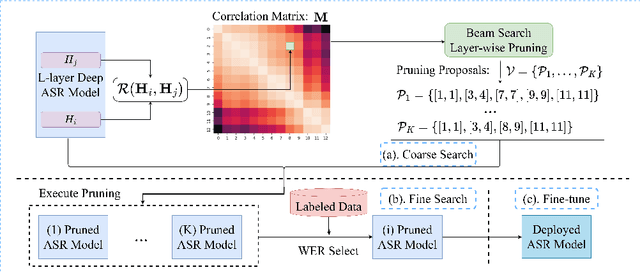
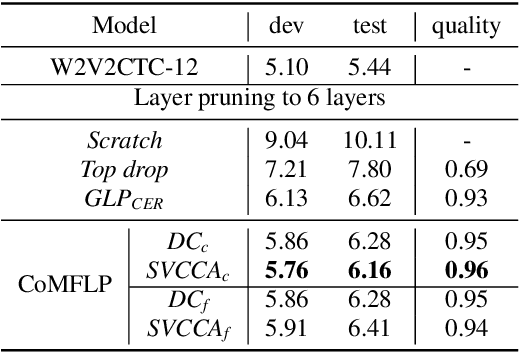
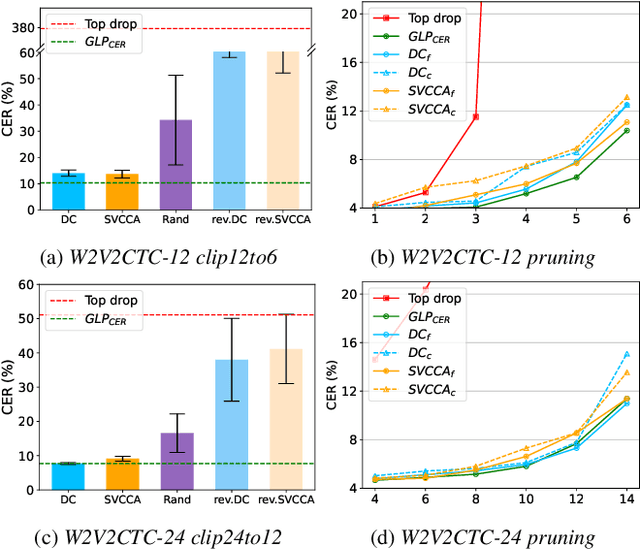
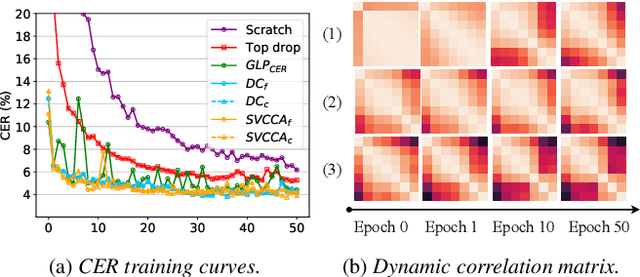
Transformer-based speech recognition (ASR) model with deep layers exhibited significant performance improvement. However, the model is inefficient for deployment on resource-constrained devices. Layer pruning (LP) is a commonly used compression method to remove redundant layers. Previous studies on LP usually identify the redundant layers according to a task-specific evaluation metric. They are time-consuming for models with a large number of layers, even in a greedy search manner. To address this problem, we propose CoMFLP, a fast search LP algorithm based on correlation measure. The correlation between layers is computed to generate a correlation matrix, which identifies the redundancy among layers. The search process is carried out in two steps: (1) coarse search: to determine top $K$ candidates by pruning the most redundant layers based on the correlation matrix; (2) fine search: to select the best pruning proposal among $K$ candidates using a task-specific evaluation metric. Experiments on an ASR task show that the pruning proposal determined by CoMFLP outperforms existing LP methods while only requiring constant time complexity. The code is publicly available at https://github.com/louislau1129/CoMFLP.
A Multiscale Autoencoder (MSAE) Framework for End-to-End Neural Network Speech Enhancement
Sep 21, 2023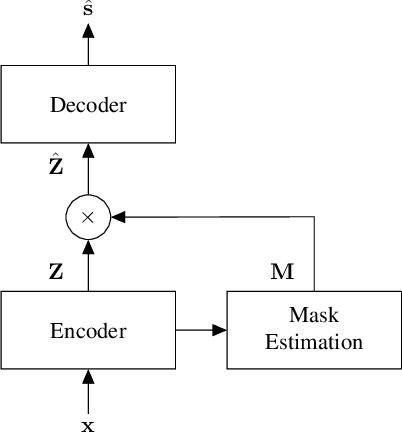
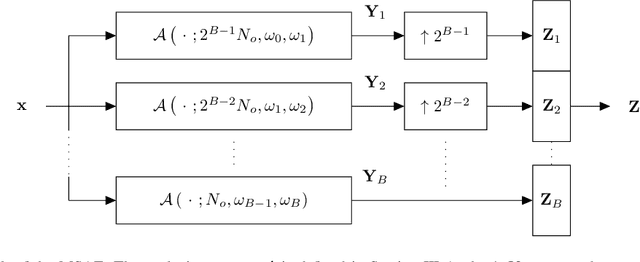
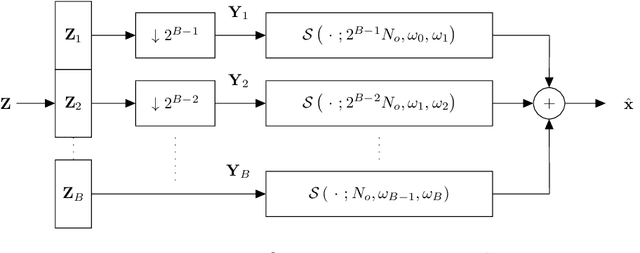
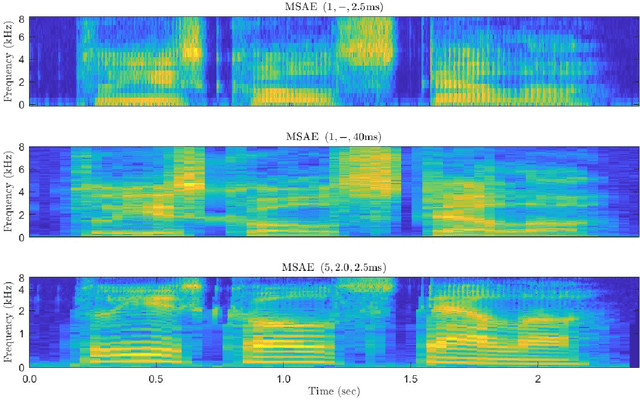
Neural network approaches to single-channel speech enhancement have received much recent attention. In particular, mask-based architectures have achieved significant performance improvements over conventional methods. This paper proposes a multiscale autoencoder (MSAE) for mask-based end-to-end neural network speech enhancement. The MSAE performs spectral decomposition of an input waveform within separate band-limited branches, each operating with a different rate and scale, to extract a sequence of multiscale embeddings. The proposed framework features intuitive parameterization of the autoencoder, including a flexible spectral band design based on the Constant-Q transform. Additionally, the MSAE is constructed entirely of differentiable operators, allowing it to be implemented within an end-to-end neural network, and be discriminatively trained. The MSAE draws motivation both from recent multiscale network topologies and from traditional multiresolution transforms in speech processing. Experimental results show the MSAE to provide clear performance benefits relative to conventional single-branch autoencoders. Additionally, the proposed framework is shown to outperform a variety of state-of-the-art enhancement systems, both in terms of objective speech quality metrics and automatic speech recognition accuracy.
Mapping AI Arguments in Journalism Studies
Sep 03, 2023
This study investigates and suggests typologies for examining Artificial Intelligence (AI) within the domains of journalism and mass communication research. We aim to elucidate the seven distinct subfields of AI, which encompass machine learning, natural language processing (NLP), speech recognition, expert systems, planning, scheduling, optimization, robotics, and computer vision, through the provision of concrete examples and practical applications. The primary objective is to devise a structured framework that can help AI researchers in the field of journalism. By comprehending the operational principles of each subfield, scholars can enhance their ability to focus on a specific facet when analyzing a particular research topic.
Improving the Gap in Visual Speech Recognition Between Normal and Silent Speech Based on Metric Learning
May 23, 2023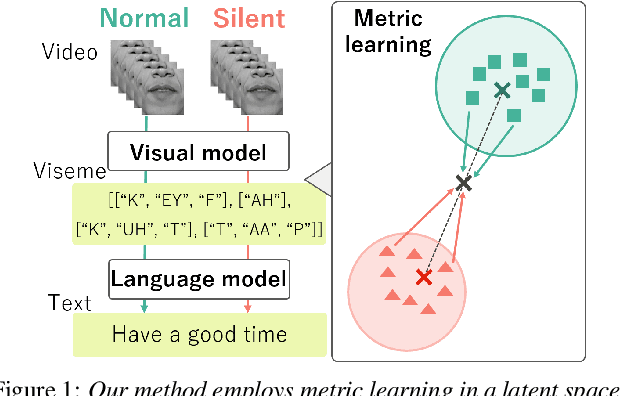
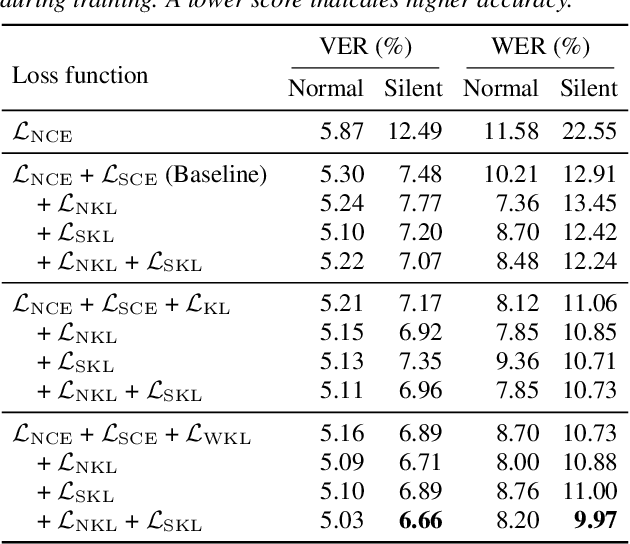
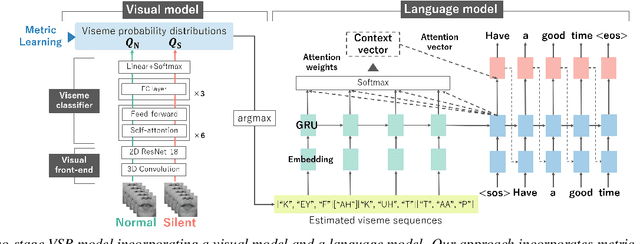
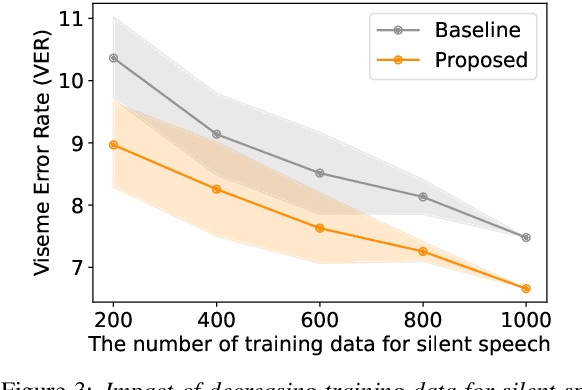
This paper presents a novel metric learning approach to address the performance gap between normal and silent speech in visual speech recognition (VSR). The difference in lip movements between the two poses a challenge for existing VSR models, which exhibit degraded accuracy when applied to silent speech. To solve this issue and tackle the scarcity of training data for silent speech, we propose to leverage the shared literal content between normal and silent speech and present a metric learning approach based on visemes. Specifically, we aim to map the input of two speech types close to each other in a latent space if they have similar viseme representations. By minimizing the Kullback-Leibler divergence of the predicted viseme probability distributions between and within the two speech types, our model effectively learns and predicts viseme identities. Our evaluation demonstrates that our method improves the accuracy of silent VSR, even when limited training data is available.
Continuous Modeling of the Denoising Process for Speech Enhancement Based on Deep Learning
Sep 17, 2023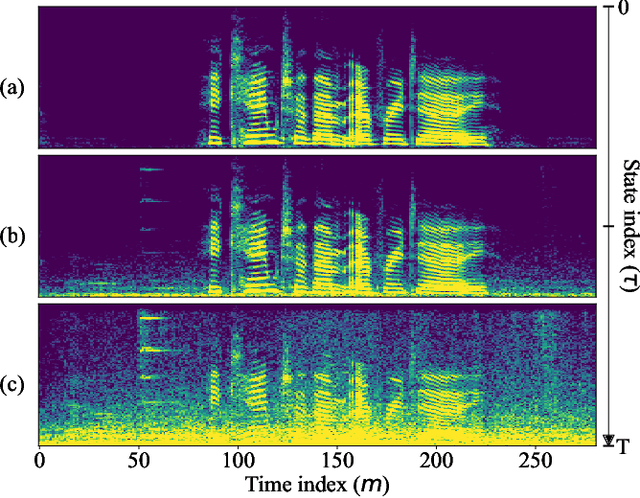
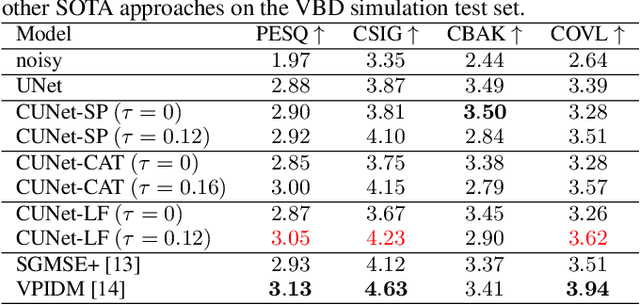
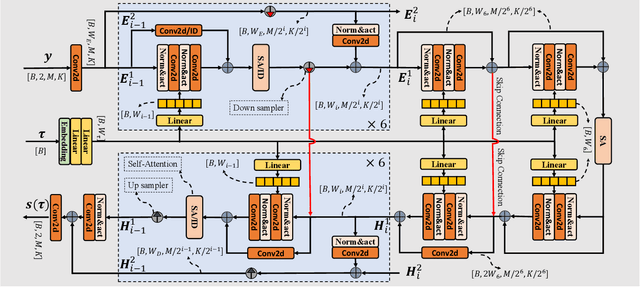
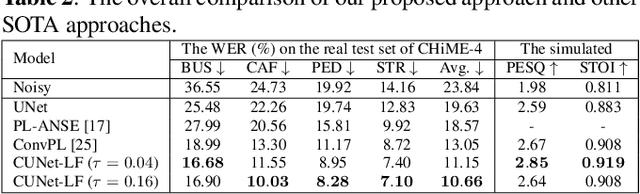
In this paper, we explore a continuous modeling approach for deep-learning-based speech enhancement, focusing on the denoising process. We use a state variable to indicate the denoising process. The starting state is noisy speech and the ending state is clean speech. The noise component in the state variable decreases with the change of the state index until the noise component is 0. During training, a UNet-like neural network learns to estimate every state variable sampled from the continuous denoising process. In testing, we introduce a controlling factor as an embedding, ranging from zero to one, to the neural network, allowing us to control the level of noise reduction. This approach enables controllable speech enhancement and is adaptable to various application scenarios. Experimental results indicate that preserving a small amount of noise in the clean target benefits speech enhancement, as evidenced by improvements in both objective speech measures and automatic speech recognition performance.
TranUSR: Phoneme-to-word Transcoder Based Unified Speech Representation Learning for Cross-lingual Speech Recognition
May 23, 2023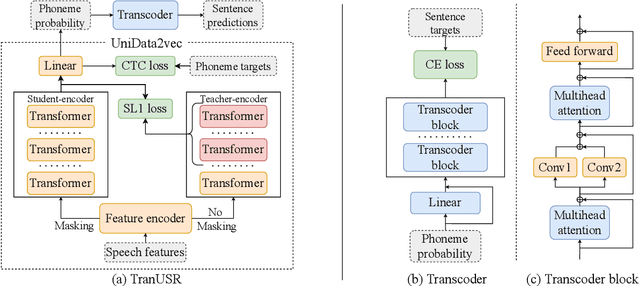
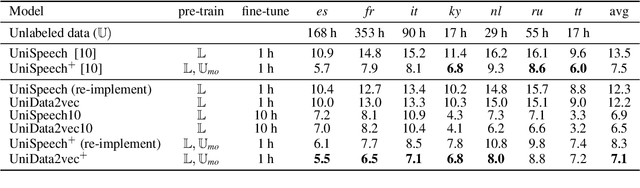

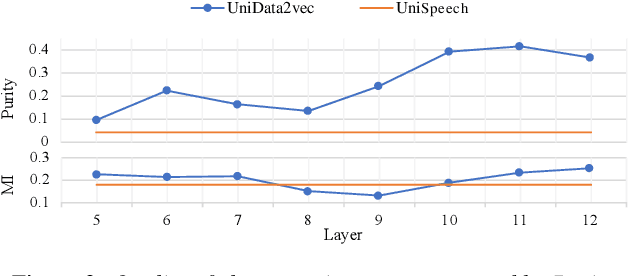
UniSpeech has achieved superior performance in cross-lingual automatic speech recognition (ASR) by explicitly aligning latent representations to phoneme units using multi-task self-supervised learning. While the learned representations transfer well from high-resource to low-resource languages, predicting words directly from these phonetic representations in downstream ASR is challenging. In this paper, we propose TranUSR, a two-stage model comprising a pre-trained UniData2vec and a phoneme-to-word Transcoder. Different from UniSpeech, UniData2vec replaces the quantized discrete representations with continuous and contextual representations from a teacher model for phonetically-aware pre-training. Then, Transcoder learns to translate phonemes to words with the aid of extra texts, enabling direct word generation. Experiments on Common Voice show that UniData2vec reduces PER by 5.3\% compared to UniSpeech, while Transcoder yields a 14.4\% WER reduction compared to grapheme fine-tuning.