 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Sampling Is Not Choosing: Intentionality, Agency, and Moral Responsibility in Large Language Models
Jun 11, 2026Recent advances in large language models (LLMs) have prompted claims that such systems exhibit agency or qualify as moral agents. This paper argues that these attributions are misguided. We maintain that moral responsibility requires commitment-bearing agency grounded in intrinsic intentionality and self-attributed action, and that such agency constitutes the form of free will relevant to responsibility. Although LLMs generate coherent and normatively evaluable outputs, their operation is fully characterized by probabilistic input-output mappings learned from data. Their apparent intentionality is derived rather than intrinsic, and their outputs are neither owned as commitments nor guided by reasons. Variability introduced by stochastic sampling does not amount to choice or authorship. We address objections from the intentional stance, functionalism, compatibilism, and the presence of moral reasoning in model outputs, arguing that none suffice to establish genuine agency.
Multilingual Word-Level Forced Alignment with Self-Supervised Representations and Learned Dynamic Programming
Jun 09, 2026We present a method for accurate multilingual word-level forced alignment, consisting of an alignment encoder and a learned alignment decoder. The encoder integrates two representations: one from the Massively Multilingual Speech (MMS) model and another from a self-supervised phoneme boundary detector (UnSupSeg). It learns to fuse them and to estimate word-boundary probabilities over long temporal contexts. The alignment decoder is a learned dynamic programming that combines encoder outputs with segmental features over the MMS and UnSupSeg representations to infer final word boundaries. Trained iteratively on TIMIT and Buckeye, the proposed approach outperforms Montreal Forced Aligner (MFA) and MMS-based alignment on both datasets. On unseen languages (Dutch, German, and Hebrew), the proposed model achieves performance consistently better than or on par with existing alignment approaches, indicating its potential to scale to 1100+ languages supported by MMS without further training.
Mitigating Multimodal LLMs Hallucinations via Relevance Propagation at Inference Time
May 03, 2026Multimodal large language models (MLLMs) have revolutionized the landscape of AI, demonstrating impressive capabilities in tackling complex vision and audio-language tasks. However, a critical challenge remains: these models often suffer from hallucinations, generating outputs that diverge from the provided perceptual inputs. This tendency stems from an inherent imbalance in modality utilization during inference, where the dominance of textual tokens undermines the potential of perceptual inputs. As a result, the model frequently resorts to textual language priors at the expense of grounded evidence. To tackle this issue, we propose Learning Inference-time Modality Enhancement (LIME), a training-free framework designed to bolster multimodal grounding by explicitly enhancing modality usage during decoding. LIME leverages Layer-wise Relevance Propagation (LRP) to quantify token-level contributions and defines a relevance-based objective that promotes increased reliance on perceptual inputs. This objective is enforced through inference-time updates to the model's key-value representations, without modifying model parameters or requiring additional training data. We evaluate LIME across multiple multimodal benchmarks in both vision and audio domains, demonstrating consistent reductions in hallucinations and enhanced grounding while preserving generation quality. Further analysis shows that LIME increases modality contribution and produces more localized and semantically aligned relevance patterns.
Joint Enhancement and Classification using Coupled Diffusion Models of Signals and Logits
Feb 17, 2026Robust classification in noisy environments remains a fundamental challenge in machine learning. Standard approaches typically treat signal enhancement and classification as separate, sequential stages: first enhancing the signal and then applying a classifier. This approach fails to leverage the semantic information in the classifier's output during denoising. In this work, we propose a general, domain-agnostic framework that integrates two interacting diffusion models: one operating on the input signal and the other on the classifier's output logits, without requiring any retraining or fine-tuning of the classifier. This coupled formulation enables mutual guidance, where the enhancing signal refines the class estimation and, conversely, the evolving class logits guide the signal reconstruction towards discriminative regions of the manifold. We introduce three strategies to effectively model the joint distribution of the input and the logit. We evaluated our joint enhancement method for image classification and automatic speech recognition. The proposed framework surpasses traditional sequential enhancement baselines, delivering robust and flexible improvements in classification accuracy under diverse noise conditions.
Analyzing and Guiding Zero-Shot Posterior Sampling in Diffusion Models
Feb 07, 2026Recovering a signal from its degraded measurements is a long standing challenge in science and engineering. Recently, zero-shot diffusion based methods have been proposed for such inverse problems, offering a posterior sampling based solution that leverages prior knowledge. Such algorithms incorporate the observations through inference, often leaning on manual tuning and heuristics. In this work we propose a rigorous analysis of such approximate posterior-samplers, relying on a Gaussianity assumption of the prior. Under this regime, we show that both the ideal posterior sampler and diffusion-based reconstruction algorithms can be expressed in closed-form, enabling their thorough analysis and comparisons in the spectral domain. Building on these representations, we also introduce a principled framework for parameter design, replacing heuristic selection strategies used to date. The proposed approach is method-agnostic and yields tailored parameter choices for each algorithm, jointly accounting for the characteristics of the prior, the degraded signal, and the diffusion dynamics. We show that our spectral recommendations differ structurally from standard heuristics and vary with the diffusion step size, resulting in a consistent balance between perceptual quality and signal fidelity.
CarelessWhisper: Turning Whisper into a Causal Streaming Model
Aug 17, 2025Automatic Speech Recognition (ASR) has seen remarkable progress, with models like OpenAI Whisper and NVIDIA Canary achieving state-of-the-art (SOTA) performance in offline transcription. However, these models are not designed for streaming (online or real-time) transcription, due to limitations in their architecture and training methodology. We propose a method to turn the transformer encoder-decoder model into a low-latency streaming model that is careless about future context. We present an analysis explaining why it is not straightforward to convert an encoder-decoder transformer to a low-latency streaming model. Our proposed method modifies the existing (non-causal) encoder to a causal encoder by fine-tuning both the encoder and decoder using Low-Rank Adaptation (LoRA) and a weakly aligned dataset. We then propose an updated inference mechanism that utilizes the fine-tune causal encoder and decoder to yield greedy and beam-search decoding, and is shown to be locally optimal. Experiments on low-latency chunk sizes (less than 300 msec) show that our fine-tuned model outperforms existing non-fine-tuned streaming approaches in most cases, while using a lower complexity. Additionally, we observe that our training process yields better alignment, enabling a simple method for extracting word-level timestamps. We release our training and inference code, along with the fine-tuned models, to support further research and development in streaming ASR.
How Does a Deep Neural Network Look at Lexical Stress?
Aug 10, 2025Despite their success in speech processing, neural networks often operate as black boxes, prompting the question: what informs their decisions, and how can we interpret them? This work examines this issue in the context of lexical stress. A dataset of English disyllabic words was automatically constructed from read and spontaneous speech. Several Convolutional Neural Network (CNN) architectures were trained to predict stress position from a spectrographic representation of disyllabic words lacking minimal stress pairs (e.g., initial stress WAllet, final stress exTEND), achieving up to 92% accuracy on held-out test data. Layerwise Relevance Propagation (LRP), a technique for CNN interpretability analysis, revealed that predictions for held-out minimal pairs (PROtest vs. proTEST ) were most strongly influenced by information in stressed versus unstressed syllables, particularly the spectral properties of stressed vowels. However, the classifiers also attended to information throughout the word. A feature-specific relevance analysis is proposed, and its results suggest that our best-performing classifier is strongly influenced by the stressed vowel's first and second formants, with some evidence that its pitch and third formant also contribute. These results reveal deep learning's ability to acquire distributed cues to stress from naturally occurring data, extending traditional phonetic work based around highly controlled stimuli.
Keyword Spotting with Hyper-Matched Filters for Small Footprint Devices
Aug 06, 2025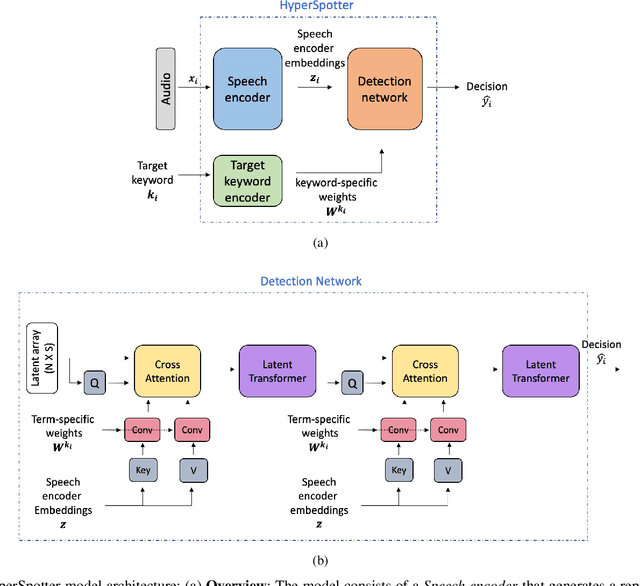
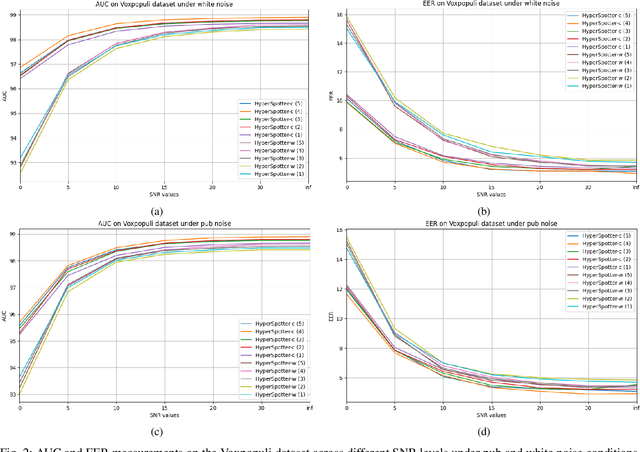
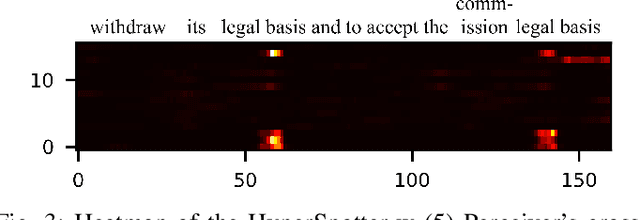
Open-vocabulary keyword spotting (KWS) refers to the task of detecting words or terms within speech recordings, regardless of whether they were included in the training data. This paper introduces an open-vocabulary keyword spotting model with state-of-the-art detection accuracy for small-footprint devices. The model is composed of a speech encoder, a target keyword encoder, and a detection network. The speech encoder is either a tiny Whisper or a tiny Conformer. The target keyword encoder is implemented as a hyper-network that takes the desired keyword as a character string and generates a unique set of weights for a convolutional layer, which can be considered as a keyword-specific matched filter. The detection network uses the matched-filter weights to perform a keyword-specific convolution, which guides the cross-attention mechanism of a Perceiver module in determining whether the target term appears in the recording. The results indicate that our system achieves state-of-the-art detection performance and generalizes effectively to out-of-domain conditions, including second-language (L2) speech. Notably, our smallest model, with just 4.2 million parameters, matches or outperforms models that are several times larger, demonstrating both efficiency and robustness.
UmbraTTS: Adapting Text-to-Speech to Environmental Contexts with Flow Matching
Jun 11, 2025Recent advances in Text-to-Speech (TTS) have enabled highly natural speech synthesis, yet integrating speech with complex background environments remains challenging. We introduce UmbraTTS, a flow-matching based TTS model that jointly generates both speech and environmental audio, conditioned on text and acoustic context. Our model allows fine-grained control over background volume and produces diverse, coherent, and context-aware audio scenes. A key challenge is the lack of data with speech and background audio aligned in natural context. To overcome the lack of paired training data, we propose a self-supervised framework that extracts speech, background audio, and transcripts from unannotated recordings. Extensive evaluations demonstrate that UmbraTTS significantly outperformed existing baselines, producing natural, high-quality, environmentally aware audios.
FlowTSE: Target Speaker Extraction with Flow Matching
May 20, 2025Target speaker extraction (TSE) aims to isolate a specific speaker's speech from a mixture using speaker enrollment as a reference. While most existing approaches are discriminative, recent generative methods for TSE achieve strong results. However, generative methods for TSE remain underexplored, with most existing approaches relying on complex pipelines and pretrained components, leading to computational overhead. In this work, we present FlowTSE, a simple yet effective TSE approach based on conditional flow matching. Our model receives an enrollment audio sample and a mixed speech signal, both represented as mel-spectrograms, with the objective of extracting the target speaker's clean speech. Furthermore, for tasks where phase reconstruction is crucial, we propose a novel vocoder conditioned on the complex STFT of the mixed signal, enabling improved phase estimation. Experimental results on standard TSE benchmarks show that FlowTSE matches or outperforms strong baselines.