 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Improving Distinction between ASR Errors and Speech Disfluencies with Feature Space Interpolation
Aug 04, 2021
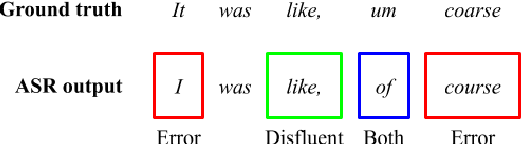
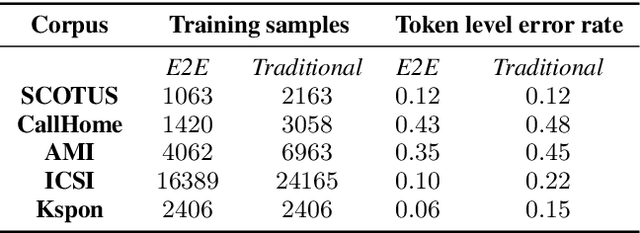
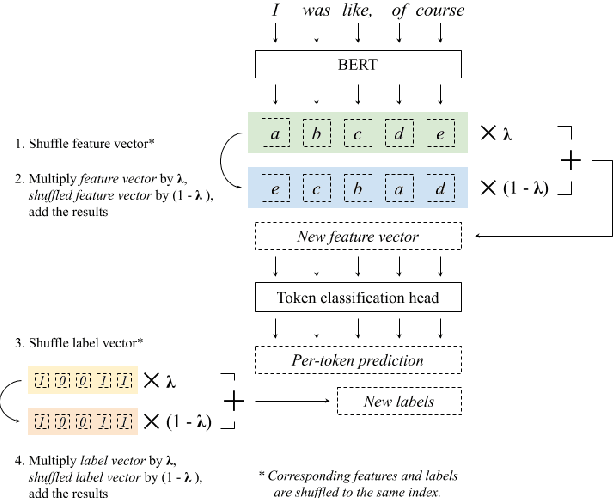
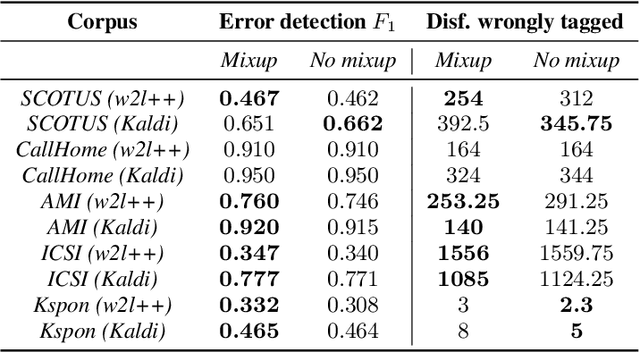
Fine-tuning pretrained language models (LMs) is a popular approach to automatic speech recognition (ASR) error detection during post-processing. While error detection systems often take advantage of statistical language archetypes captured by LMs, at times the pretrained knowledge can hinder error detection performance. For instance, presence of speech disfluencies might confuse the post-processing system into tagging disfluent but accurate transcriptions as ASR errors. Such confusion occurs because both error detection and disfluency detection tasks attempt to identify tokens at statistically unlikely positions. This paper proposes a scheme to improve existing LM-based ASR error detection systems, both in terms of detection scores and resilience to such distracting auxiliary tasks. Our approach adopts the popular mixup method in text feature space and can be utilized with any black-box ASR output. To demonstrate the effectiveness of our method, we conduct post-processing experiments with both traditional and end-to-end ASR systems (both for English and Korean languages) with 5 different speech corpora. We find that our method improves both ASR error detection F 1 scores and reduces the number of correctly transcribed disfluencies wrongly detected as ASR errors. Finally, we suggest methods to utilize resulting LMs directly in semi-supervised ASR training.
Bounds on mutual information of mixture data for classification tasks
Jan 27, 2021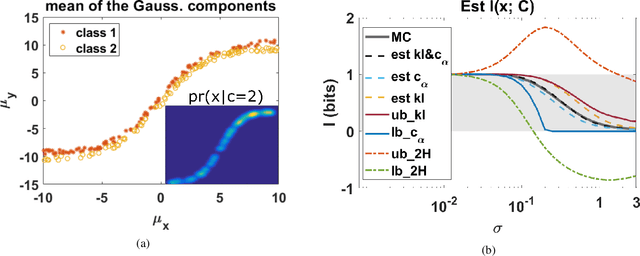
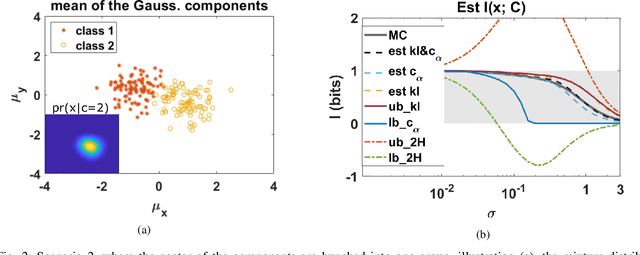
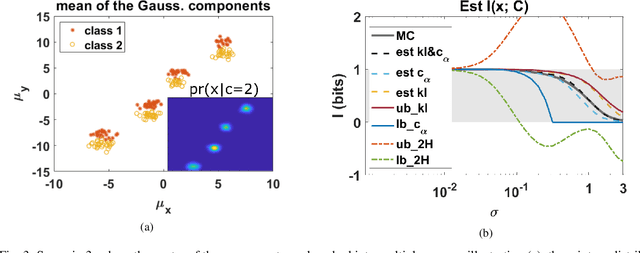
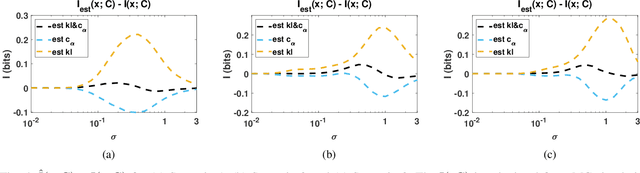
The data for many classification problems, such as pattern and speech recognition, follow mixture distributions. To quantify the optimum performance for classification tasks, the Shannon mutual information is a natural information-theoretic metric, as it is directly related to the probability of error. The mutual information between mixture data and the class label does not have an analytical expression, nor any efficient computational algorithms. We introduce a variational upper bound, a lower bound, and three estimators, all employing pair-wise divergences between mixture components. We compare the new bounds and estimators with Monte Carlo stochastic sampling and bounds derived from entropy bounds. To conclude, we evaluate the performance of the bounds and estimators through numerical simulations.
SEP-28k: A Dataset for Stuttering Event Detection From Podcasts With People Who Stutter
Feb 24, 2021
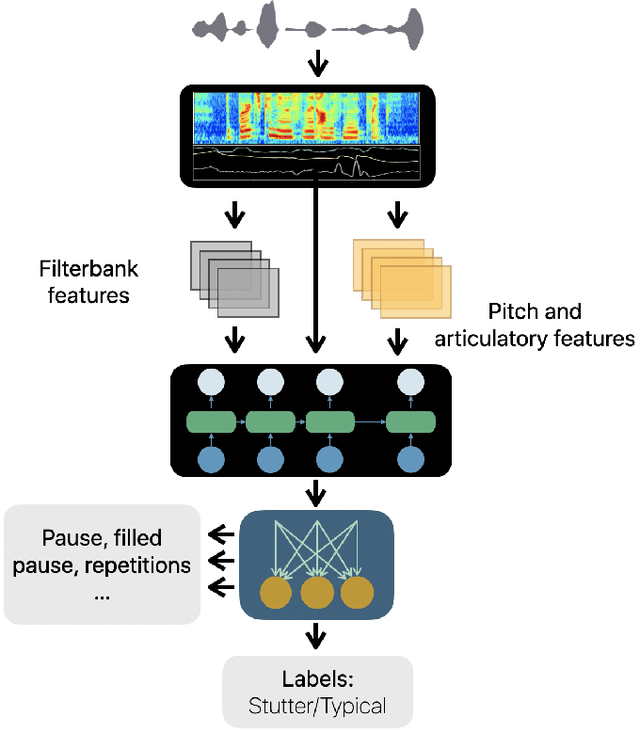
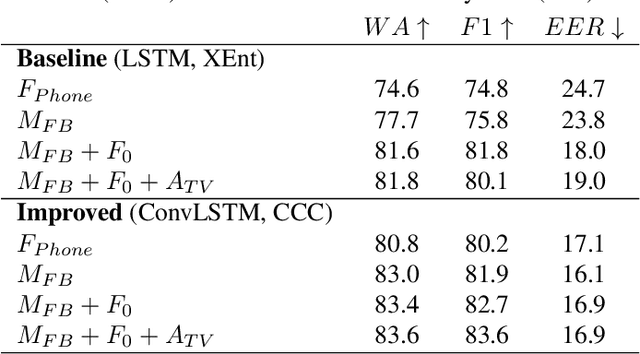
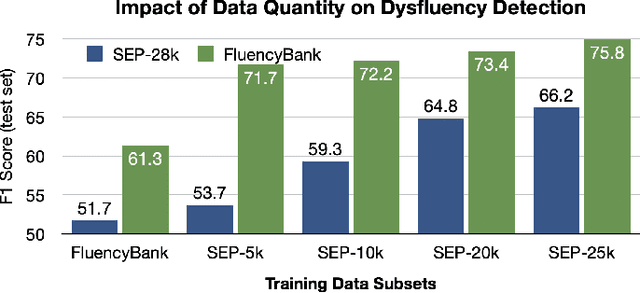
The ability to automatically detect stuttering events in speech could help speech pathologists track an individual's fluency over time or help improve speech recognition systems for people with atypical speech patterns. Despite increasing interest in this area, existing public datasets are too small to build generalizable dysfluency detection systems and lack sufficient annotations. In this work, we introduce Stuttering Events in Podcasts (SEP-28k), a dataset containing over 28k clips labeled with five event types including blocks, prolongations, sound repetitions, word repetitions, and interjections. Audio comes from public podcasts largely consisting of people who stutter interviewing other people who stutter. We benchmark a set of acoustic models on SEP-28k and the public FluencyBank dataset and highlight how simply increasing the amount of training data improves relative detection performance by 28\% and 24\% F1 on each. Annotations from over 32k clips across both datasets will be publicly released.
User-Initiated Repetition-Based Recovery in Multi-Utterance Dialogue Systems
Aug 02, 2021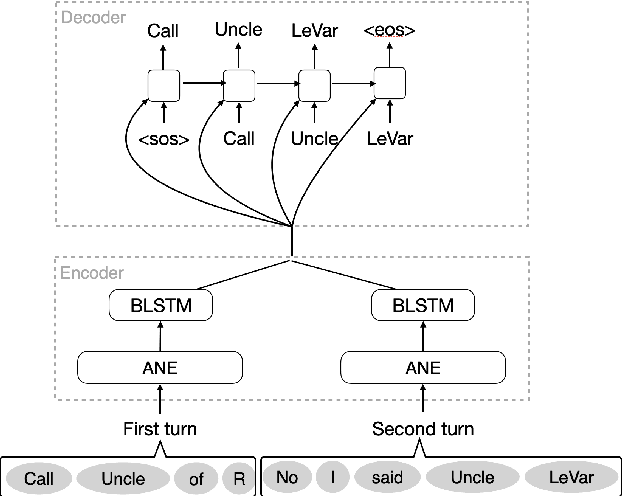
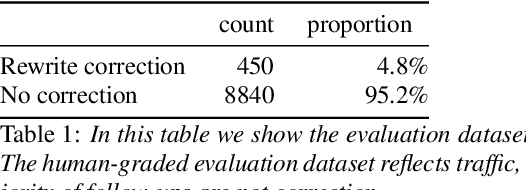
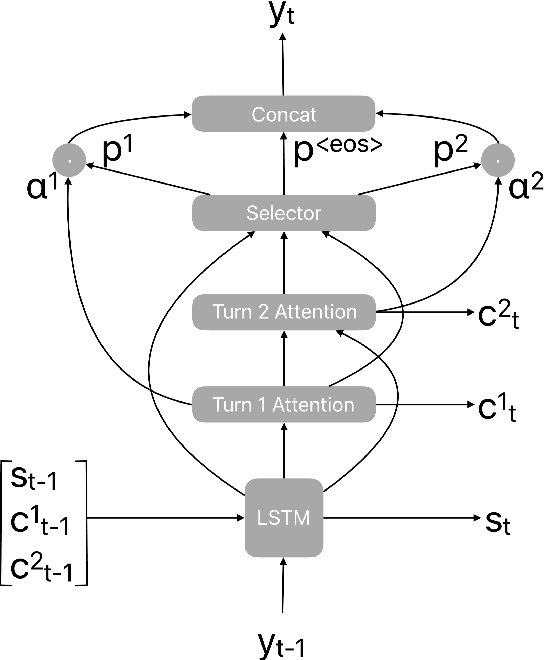

Recognition errors are common in human communication. Similar errors often lead to unwanted behaviour in dialogue systems or virtual assistants. In human communication, we can recover from them by repeating misrecognized words or phrases; however in human-machine communication this recovery mechanism is not available. In this paper, we attempt to bridge this gap and present a system that allows a user to correct speech recognition errors in a virtual assistant by repeating misunderstood words. When a user repeats part of the phrase the system rewrites the original query to incorporate the correction. This rewrite allows the virtual assistant to understand the original query successfully. We present an end-to-end 2-step attention pointer network that can generate the the rewritten query by merging together the incorrectly understood utterance with the correction follow-up. We evaluate the model on data collected for this task and compare the proposed model to a rule-based baseline and a standard pointer network. We show that rewriting the original query is an effective way to handle repetition-based recovery and that the proposed model outperforms the rule based baseline, reducing Word Error Rate by 19% relative at 2% False Alarm Rate on annotated data.
KARI: KAnari/QCRI's End-to-End systems for the INTERSPEECH 2021 Indian Languages Code-Switching Challenge
Jun 10, 2021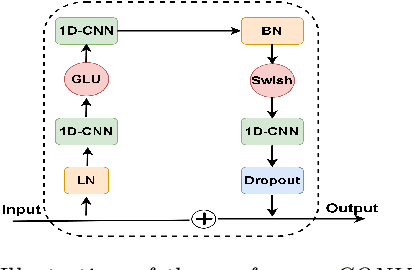

In this paper, we present the Kanari/QCRI (KARI) system and the modeling strategies used to participate in the Interspeech 2021 Code-switching (CS) challenge for low-resource Indian languages. The subtask involved developing a speech recognition system for two CS datasets: Hindi-English and Bengali-English, collected in a real-life scenario. To tackle the CS challenges, we use transfer learning for incorporating the publicly available monolingual Hindi, Bengali, and English speech data. In this work, we study the effectiveness of two steps transfer learning protocol for low-resourced CS data: monolingual pretraining, followed by fine-tuning. For acoustic modeling, we develop an end-to-end convolution-augmented transformer (Conformer). We show that selecting the percentage of each monolingual data affects model biases towards using one language character set over the other in a CS scenario. The models pretrained on well-aligned and accurate monolingual data showed robustness against misalignment between the segments and the transcription. Finally, we develop word-level n-gram language models (LM) to rescore ASR recognition.
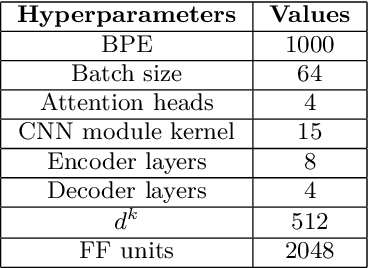
TENET: A Time-reversal Enhancement Network for Noise-robust ASR
Jul 08, 2021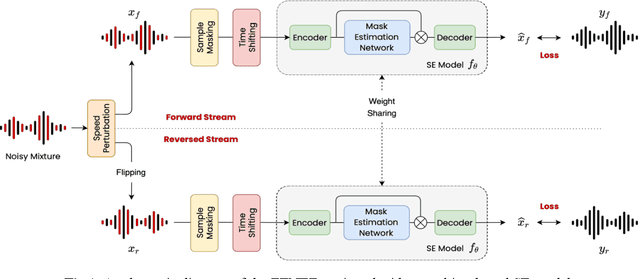
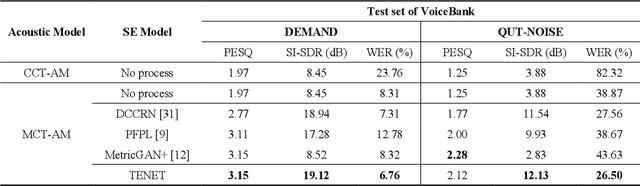
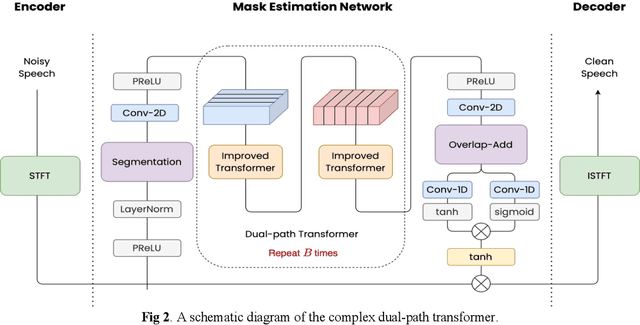
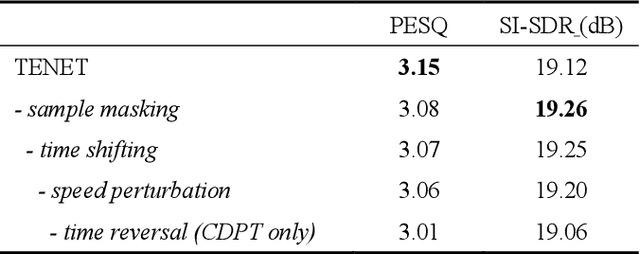
Due to the unprecedented breakthroughs brought about by deep learning, speech enhancement (SE) techniques have been developed rapidly and play an important role prior to acoustic modeling to mitigate noise effects on speech. To increase the perceptual quality of speech, current state-of-the-art in the SE field adopts adversarial training by connecting an objective metric to the discriminator. However, there is no guarantee that optimizing the perceptual quality of speech will necessarily lead to improved automatic speech recognition (ASR) performance. In this study, we present TENET, a novel Time-reversal Enhancement NETwork, which leverages the transformation of an input noisy signal itself, i.e., the time-reversed version, in conjunction with the siamese network and complex dual-path transformer to promote SE performance for noise-robust ASR. Extensive experiments conducted on the Voicebank-DEMAND dataset show that TENET can achieve state-of-the-art results compared to a few top-of-the-line methods in terms of both SE and ASR evaluation metrics. To demonstrate the model generalization ability, we further evaluate TENET on the test set of scenarios contaminated with unseen noise, and the results also confirm the superiority of this promising method.
Discriminative Self-training for Punctuation Prediction
Apr 21, 2021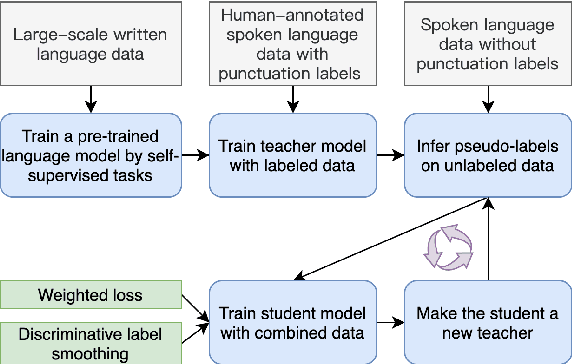
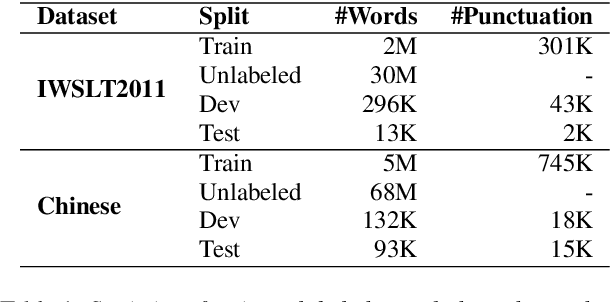
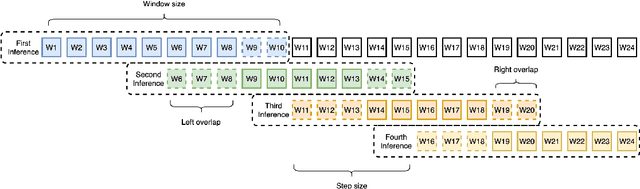
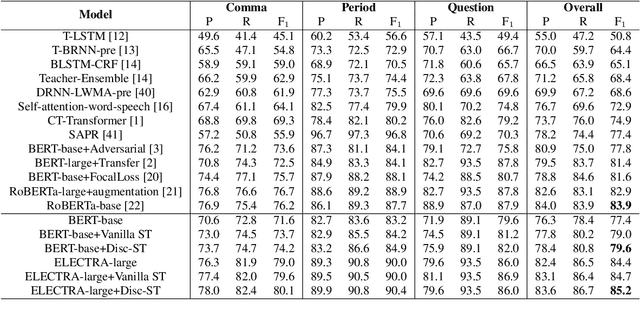
Punctuation prediction for automatic speech recognition (ASR) output transcripts plays a crucial role for improving the readability of the ASR transcripts and for improving the performance of downstream natural language processing applications. However, achieving good performance on punctuation prediction often requires large amounts of labeled speech transcripts, which is expensive and laborious. In this paper, we propose a Discriminative Self-Training approach with weighted loss and discriminative label smoothing to exploit unlabeled speech transcripts. Experimental results on the English IWSLT2011 benchmark test set and an internal Chinese spoken language dataset demonstrate that the proposed approach achieves significant improvement on punctuation prediction accuracy over strong baselines including BERT, RoBERTa, and ELECTRA models. The proposed Discriminative Self-Training approach outperforms the vanilla self-training approach. We establish a new state-of-the-art (SOTA) on the IWSLT2011 test set, outperforming the current SOTA model by 1.3% absolute gain on F$_1$.
Similarity-and-Independence-Aware Beamformer with Iterative Casting and Boost Start for Target Source Extraction Using Reference
Oct 18, 2021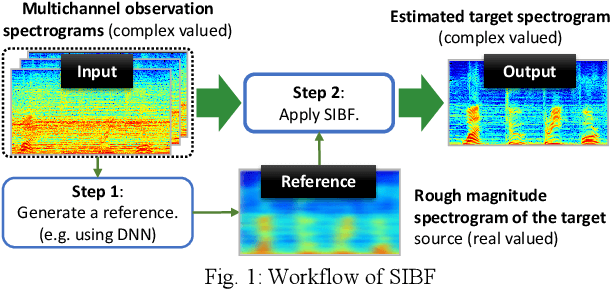
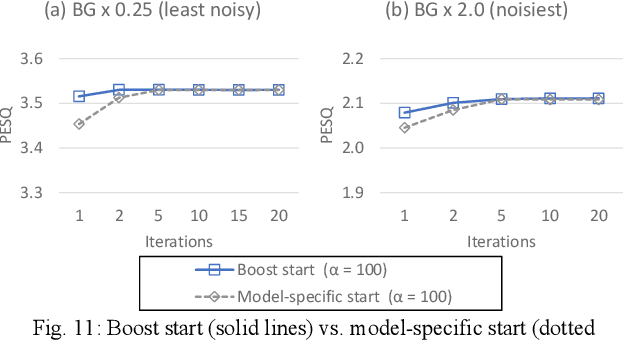
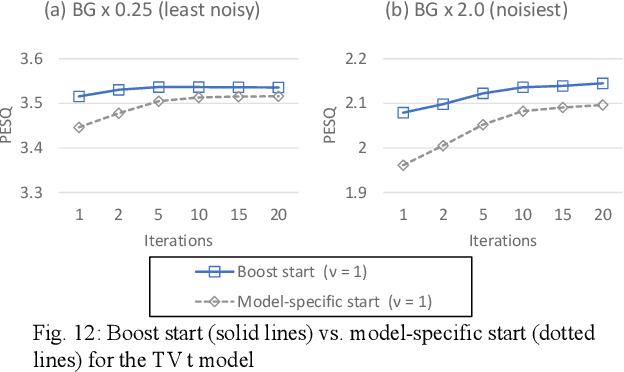
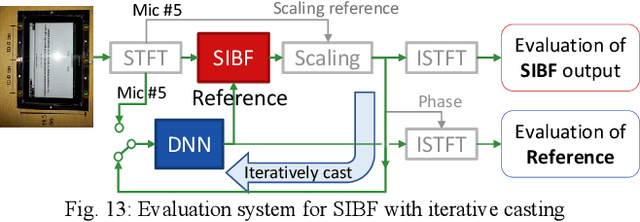
Target source extraction is significant for improving human speech intelligibility and the speech recognition performance of computers. This study describes a method for target source extraction, called the similarity-and-independence-aware beamformer (SIBF). The SIBF extracts the target source using a rough magnitude spectrogram as the reference signal. The advantage of the SIBF is that it can obtain a more accurate signal than the spectrogram generated by target-enhancing methods such as speech enhancement based on deep neural networks. For the extraction, we extend the framework of deflationary independent component analysis (ICA) by considering the similarities between the reference and extracted target sources, in addition to the mutual independence of all the potential sources. To solve the extraction problem by maximum-likelihood estimation, we introduce three source models that can reflect the similarities. The major contributions of this study are as follows. First, the extraction performance is improved using two methods, namely boost start for faster convergence and iterative casting for generating a more accurate reference. The effectiveness of these methods is verified through experiments using the CHiME3 dataset. Second, a concept of a fixed point pertaining to accuracy is developed. This concept facilitates understanding the relationship between the reference and SIBF output in terms of accuracy. Third, a unified formulation of the SIBF and mask-based beamformer is realized to apply the expertise of conventional BFs to the SIBF. The findings of this study can also improve the performance of the SIBF and promote research on ICA and conventional beamformers. Index Terms: beamformer, independent component analysis, source separation, speech enhancement, target source extraction
A Comparative Study of Modular and Joint Approaches for Speaker-Attributed ASR on Monaural Long-Form Audio
Jul 06, 2021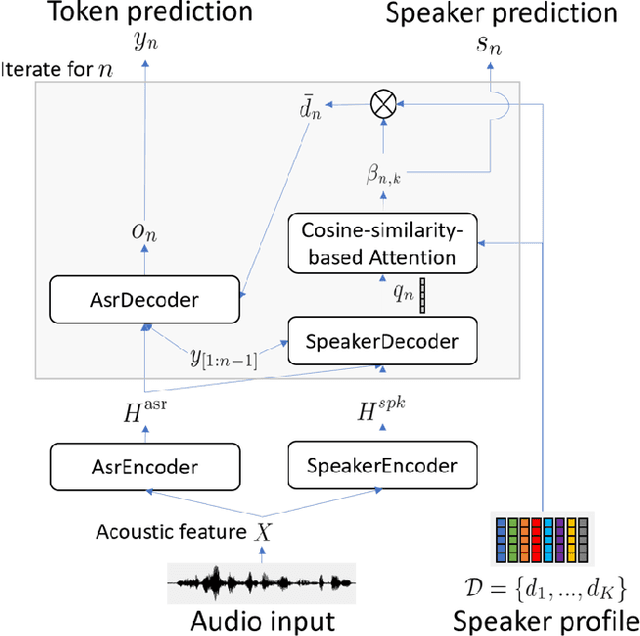
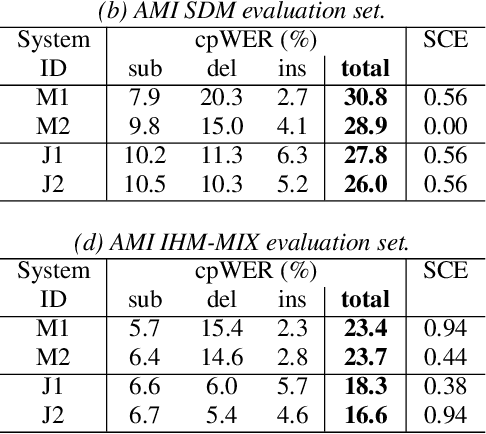
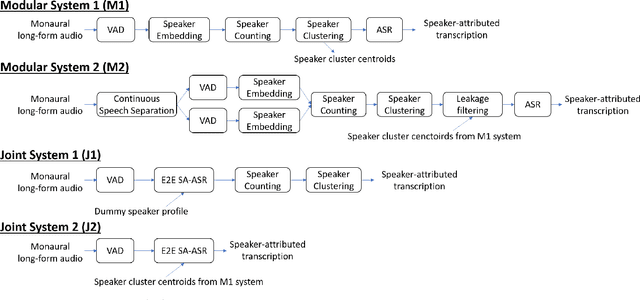
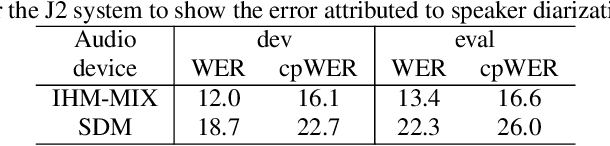
Speaker-attributed automatic speech recognition (SA-ASR) is a task to recognize "who spoke what" from multi-talker recordings. An SA-ASR system usually consists of multiple modules such as speech separation, speaker diarization and ASR. On the other hand, considering the joint optimization, an end-to-end (E2E) SA-ASR model has recently been proposed with promising results on simulation data. In this paper, we present our recent study on the comparison of such modular and joint approaches towards SA-ASR on real monaural recordings. We develop state-of-the-art SA-ASR systems for both modular and joint approaches by leveraging large-scale training data, including 75 thousand hours of ASR training data and the VoxCeleb corpus for speaker representation learning. We also propose a new pipeline that performs the E2E SA-ASR model after speaker clustering. Our evaluation on the AMI meeting corpus reveals that after fine-tuning with a small real data, the joint system performs 9.2--29.4% better in accuracy compared to the best modular system while the modular system performs better before such fine-tuning. We also conduct various error analyses to show the remaining issues for the monaural SA-ASR.
Mitigating Noisy Inputs for Question Answering
Aug 08, 2019
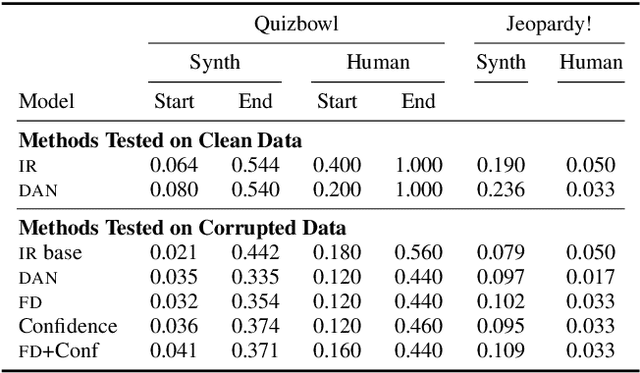

Natural language processing systems are often downstream of unreliable inputs: machine translation, optical character recognition, or speech recognition. For instance, virtual assistants can only answer your questions after understanding your speech. We investigate and mitigate the effects of noise from Automatic Speech Recognition systems on two factoid Question Answering (QA) tasks. Integrating confidences into the model and forced decoding of unknown words are empirically shown to improve the accuracy of downstream neural QA systems. We create and train models on a synthetic corpus of over 500,000 noisy sentences and evaluate on two human corpora from Quizbowl and Jeopardy! competitions.