 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexID: Training-Free Flexible Identity Injection via Intent-Aware Modulation for Text-to-Image Generation
Feb 07, 2026Personalized text-to-image generation aims to seamlessly integrate specific identities into textual descriptions. However, existing training-free methods often rely on rigid visual feature injection, creating a conflict between identity fidelity and textual adaptability. To address this, we propose FlexID, a novel training-free framework utilizing intent-aware modulation. FlexID orthogonally decouples identity into two dimensions: a Semantic Identity Projector (SIP) that injects high-level priors into the language space, and a Visual Feature Anchor (VFA) that ensures structural fidelity within the latent space. Crucially, we introduce a Context-Aware Adaptive Gating (CAG) mechanism that dynamically modulates the weights of these streams based on editing intent and diffusion timesteps. By automatically relaxing rigid visual constraints when strong editing intent is detected, CAG achieves synergy between identity preservation and semantic variation. Extensive experiments on IBench demonstrate that FlexID achieves a state-of-the-art balance between identity consistency and text adherence, offering an efficient solution for complex narrative generation.
DVI: Disentangling Semantic and Visual Identity for Training-Free Personalized Generation
Dec 22, 2025Recent tuning-free identity customization methods achieve high facial fidelity but often overlook visual context, such as lighting, skin texture, and environmental tone. This limitation leads to ``Semantic-Visual Dissonance,'' where accurate facial geometry clashes with the input's unique atmosphere, causing an unnatural ``sticker-like'' effect. We propose **DVI (Disentangled Visual-Identity)**, a zero-shot framework that orthogonally disentangles identity into fine-grained semantic and coarse-grained visual streams. Unlike methods relying solely on semantic vectors, DVI exploits the inherent statistical properties of the VAE latent space, utilizing mean and variance as lightweight descriptors for global visual atmosphere. We introduce a **Parameter-Free Feature Modulation** mechanism that adaptively modulates semantic embeddings with these visual statistics, effectively injecting the reference's ``visual soul'' without training. Furthermore, a **Dynamic Temporal Granularity Scheduler** aligns with the diffusion process, prioritizing visual atmosphere in early denoising stages while refining semantic details later. Extensive experiments demonstrate that DVI significantly enhances visual consistency and atmospheric fidelity without parameter fine-tuning, maintaining robust identity preservation and outperforming state-of-the-art methods in IBench evaluations.
Bounds on mutual information of mixture data for classification tasks
Jan 27, 2021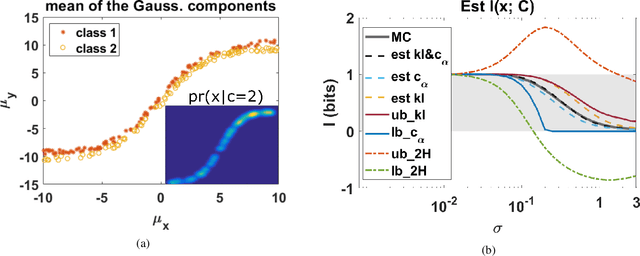
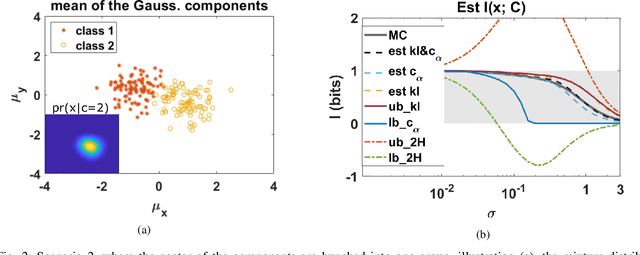
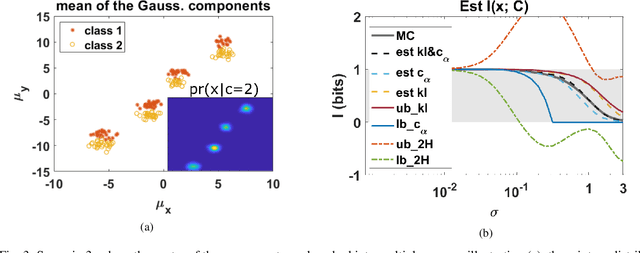
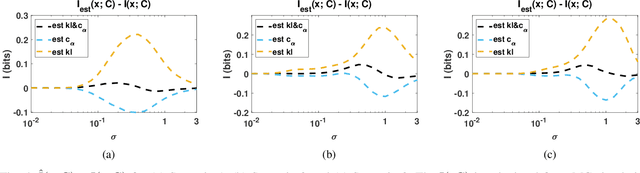
The data for many classification problems, such as pattern and speech recognition, follow mixture distributions. To quantify the optimum performance for classification tasks, the Shannon mutual information is a natural information-theoretic metric, as it is directly related to the probability of error. The mutual information between mixture data and the class label does not have an analytical expression, nor any efficient computational algorithms. We introduce a variational upper bound, a lower bound, and three estimators, all employing pair-wise divergences between mixture components. We compare the new bounds and estimators with Monte Carlo stochastic sampling and bounds derived from entropy bounds. To conclude, we evaluate the performance of the bounds and estimators through numerical simulations.