 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Model Hidden Representations for Heart Rate Estimation from Auscultation
May 29, 2025



Auscultation, particularly heart sound, is a non-invasive technique that provides essential vital sign information. Recently, self-supervised acoustic representation foundation models (FMs) have been proposed to offer insights into acoustics-based vital signs. However, there has been little exploration of the extent to which auscultation is encoded in these pre-trained FM representations. In this work, using a publicly available phonocardiogram (PCG) dataset and a heart rate (HR) estimation model, we conduct a layer-wise investigation of six acoustic representation FMs: HuBERT, wav2vec2, wavLM, Whisper, Contrastive Language-Audio Pretraining (CLAP), and an in-house CLAP model. Additionally, we implement the baseline method from Nie et al., 2024 (which relies on acoustic features) and show that overall, representation vectors from pre-trained foundation models (FMs) offer comparable performance to the baseline. Notably, HR estimation using the representations from the audio encoder of the in-house CLAP model outperforms the results obtained from the baseline, achieving a lower mean absolute error (MAE) across various train/validation/test splits despite the domain mismatch.
Voice Quality Dimensions as Interpretable Primitives for Speaking Style for Atypical Speech and Affect
May 27, 2025



Perceptual voice quality dimensions describe key characteristics of atypical speech and other speech modulations. Here we develop and evaluate voice quality models for seven voice and speech dimensions (intelligibility, imprecise consonants, harsh voice, naturalness, monoloudness, monopitch, and breathiness). Probes were trained on the public Speech Accessibility (SAP) project dataset with 11,184 samples from 434 speakers, using embeddings from frozen pre-trained models as features. We found that our probes had both strong performance and strong generalization across speech elicitation categories in the SAP dataset. We further validated zero-shot performance on additional datasets, encompassing unseen languages and tasks: Italian atypical speech, English atypical speech, and affective speech. The strong zero-shot performance and the interpretability of results across an array of evaluations suggests the utility of using voice quality dimensions in speaking style-related tasks.
Affect Models Have Weak Generalizability to Atypical Speech
Apr 22, 2025Speech and voice conditions can alter the acoustic properties of speech, which could impact the performance of paralinguistic models for affect for people with atypical speech. We evaluate publicly available models for recognizing categorical and dimensional affect from speech on a dataset of atypical speech, comparing results to datasets of typical speech. We investigate three dimensions of speech atypicality: intelligibility, which is related to pronounciation; monopitch, which is related to prosody, and harshness, which is related to voice quality. We look at (1) distributional trends of categorical affect predictions within the dataset, (2) distributional comparisons of categorical affect predictions to similar datasets of typical speech, and (3) correlation strengths between text and speech predictions for spontaneous speech for valence and arousal. We find that the output of affect models is significantly impacted by the presence and degree of speech atypicalities. For instance, the percentage of speech predicted as sad is significantly higher for all types and grades of atypical speech when compared to similar typical speech datasets. In a preliminary investigation on improving robustness for atypical speech, we find that fine-tuning models on pseudo-labeled atypical speech data improves performance on atypical speech without impacting performance on typical speech. Our results emphasize the need for broader training and evaluation datasets for speech emotion models, and for modeling approaches that are robust to voice and speech differences.
Model-driven Heart Rate Estimation and Heart Murmur Detection based on Phonocardiogram
Jul 25, 2024



Acoustic signals are crucial for health monitoring, particularly heart sounds which provide essential data like heart rate and detect cardiac anomalies such as murmurs. This study utilizes a publicly available phonocardiogram (PCG) dataset to estimate heart rate using model-driven methods and extends the best-performing model to a multi-task learning (MTL) framework for simultaneous heart rate estimation and murmur detection. Heart rate estimates are derived using a sliding window technique on heart sound snippets, analyzed with a combination of acoustic features (Mel spectrogram, cepstral coefficients, power spectral density, root mean square energy). Our findings indicate that a 2D convolutional neural network (\textbf{\texttt{2dCNN}}) is most effective for heart rate estimation, achieving a mean absolute error (MAE) of 1.312 bpm. We systematically investigate the impact of different feature combinations and find that utilizing all four features yields the best results. The MTL model (\textbf{\texttt{2dCNN-MTL}}) achieves accuracy over 95% in murmur detection, surpassing existing models, while maintaining an MAE of 1.636 bpm in heart rate estimation, satisfying the requirements stated by Association for the Advancement of Medical Instrumentation (AAMI).
Pre-Trained Foundation Model representations to uncover Breathing patterns in Speech
Jul 17, 2024



The process of human speech production involves coordinated respiratory action to elicit acoustic speech signals. Typically, speech is produced when air is forced from the lungs and is modulated by the vocal tract, where such actions are interspersed by moments of breathing in air (inhalation) to refill the lungs again. Respiratory rate (RR) is a vital metric that is used to assess the overall health, fitness, and general well-being of an individual. Existing approaches to measure RR (number of breaths one takes in a minute) are performed using specialized equipment or training. Studies have demonstrated that machine learning algorithms can be used to estimate RR using bio-sensor signals as input. Speech-based estimation of RR can offer an effective approach to measure the vital metric without requiring any specialized equipment or sensors. This work investigates a machine learning based approach to estimate RR from speech segments obtained from subjects speaking to a close-talking microphone device. Data were collected from N=26 individuals, where the groundtruth RR was obtained through commercial grade chest-belts and then manually corrected for any errors. A convolutional long-short term memory network (Conv-LSTM) is proposed to estimate respiration time-series data from the speech signal. We demonstrate that the use of pre-trained representations obtained from a foundation model, such as Wav2Vec2, can be used to estimate respiration-time-series with low root-mean-squared error and high correlation coefficient, when compared with the baseline. The model-driven time series can be used to estimate $RR$ with a low mean absolute error (MAE) ~ 1.6 breaths/min.
Investigating salient representations and label Variance in Dimensional Speech Emotion Analysis
Dec 17, 2023



Representations derived from models such as BERT (Bidirectional Encoder Representations from Transformers) and HuBERT (Hidden units BERT), have helped to achieve state-of-the-art performance in dimensional speech emotion recognition. Despite their large dimensionality, and even though these representations are not tailored for emotion recognition tasks, they are frequently used to train large speech emotion models with high memory and computational costs. In this work, we show that there exist lower-dimensional subspaces within the these pre-trained representational spaces that offer a reduction in downstream model complexity without sacrificing performance on emotion estimation. In addition, we model label uncertainty in the form of grader opinion variance, and demonstrate that such information can improve the models generalization capacity and robustness. Finally, we compare the robustness of the emotion models against acoustic degradations and observed that the reduced dimensional representations were able to retain the performance similar to the full-dimensional representations without significant regression in dimensional emotion performance.
* 5 pages
Pre-trained Model Representations and their Robustness against Noise for Speech Emotion Analysis
Mar 03, 2023



Pre-trained model representations have demonstrated state-of-the-art performance in speech recognition, natural language processing, and other applications. Speech models, such as Bidirectional Encoder Representations from Transformers (BERT) and Hidden units BERT (HuBERT), have enabled generating lexical and acoustic representations to benefit speech recognition applications. We investigated the use of pre-trained model representations for estimating dimensional emotions, such as activation, valence, and dominance, from speech. We observed that while valence may rely heavily on lexical representations, activation and dominance rely mostly on acoustic information. In this work, we used multi-modal fusion representations from pre-trained models to generate state-of-the-art speech emotion estimation, and we showed a 100% and 30% relative improvement in concordance correlation coefficient (CCC) on valence estimation compared to standard acoustic and lexical baselines. Finally, we investigated the robustness of pre-trained model representations against noise and reverberation degradation and noticed that lexical and acoustic representations are impacted differently. We discovered that lexical representations are more robust to distortions compared to acoustic representations, and demonstrated that knowledge distillation from a multi-modal model helps to improve the noise-robustness of acoustic-based models.
Speech Emotion: Investigating Model Representations, Multi-Task Learning and Knowledge Distillation
Jul 02, 2022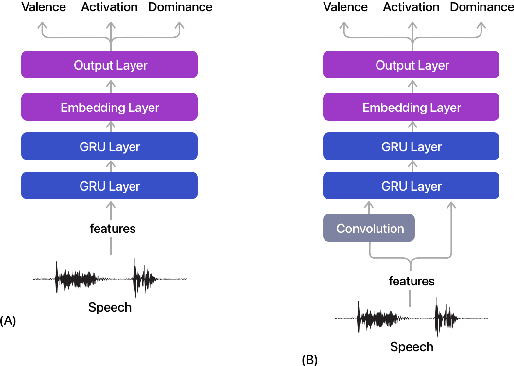
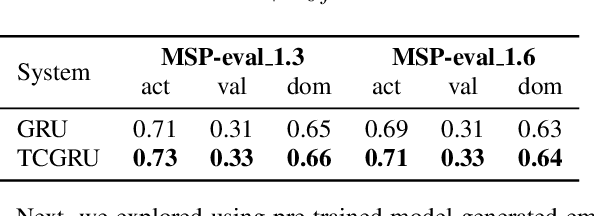
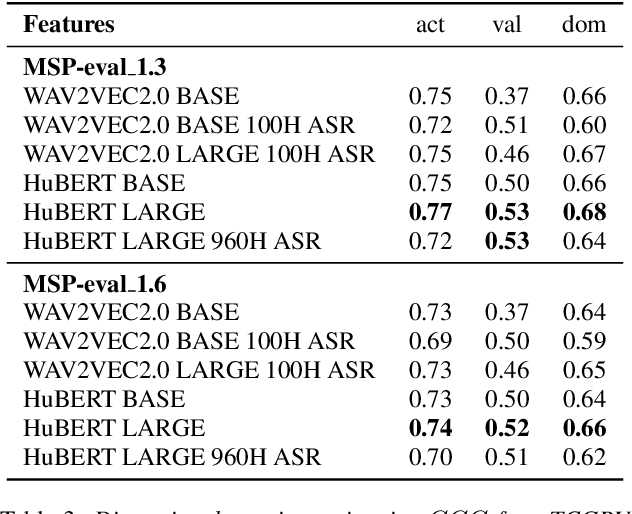
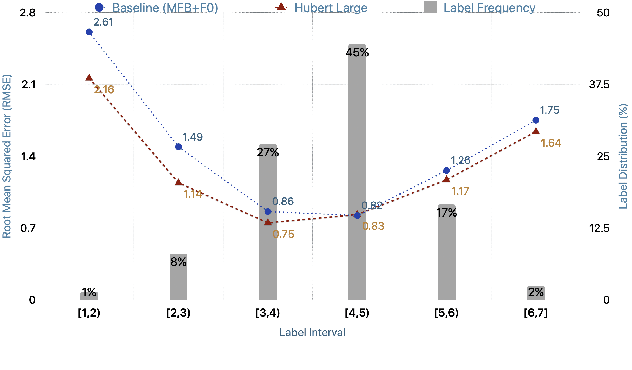
Estimating dimensional emotions, such as activation, valence and dominance, from acoustic speech signals has been widely explored over the past few years. While accurate estimation of activation and dominance from speech seem to be possible, the same for valence remains challenging. Previous research has shown that the use of lexical information can improve valence estimation performance. Lexical information can be obtained from pre-trained acoustic models, where the learned representations can improve valence estimation from speech. We investigate the use of pre-trained model representations to improve valence estimation from acoustic speech signal. We also explore fusion of representations to improve emotion estimation across all three emotion dimensions: activation, valence and dominance. Additionally, we investigate if representations from pre-trained models can be distilled into models trained with low-level features, resulting in models with a less number of parameters. We show that fusion of pre-trained model embeddings result in a 79% relative improvement in concordance correlation coefficient CCC on valence estimation compared to standard acoustic feature baseline (mel-filterbank energies), while distillation from pre-trained model embeddings to lower-dimensional representations yielded a relative 12% improvement. Such performance gains were observed over two evaluation sets, indicating that our proposed architecture generalizes across those evaluation sets. We report new state-of-the-art "text-free" acoustic-only dimensional emotion estimation $CCC$ values on two MSP-Podcast evaluation sets.
Estimating Respiratory Rate From Breath Audio Obtained Through Wearable Microphones
Jul 28, 2021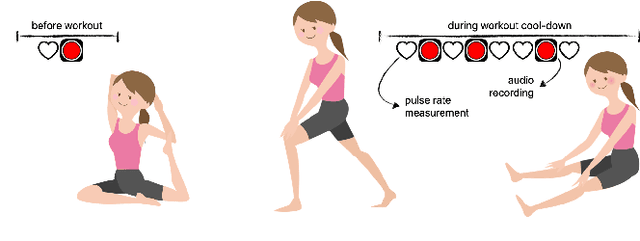
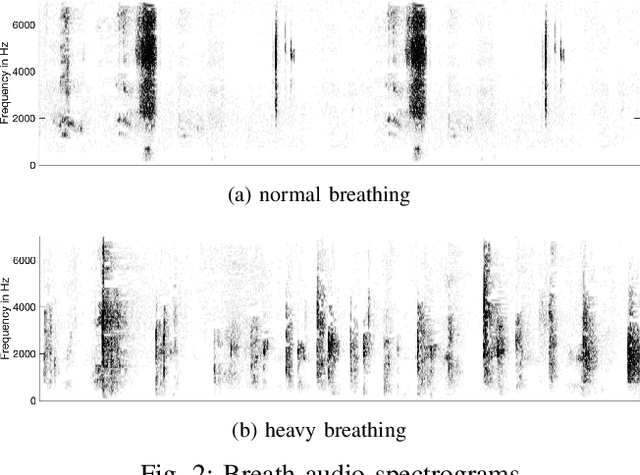
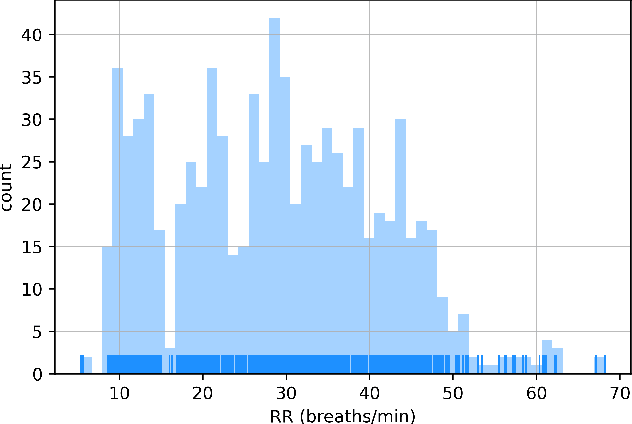
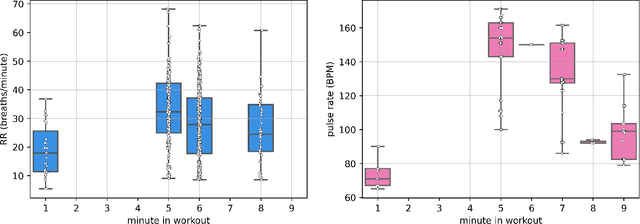
Respiratory rate (RR) is a clinical metric used to assess overall health and physical fitness. An individual's RR can change from their baseline due to chronic illness symptoms (e.g., asthma, congestive heart failure), acute illness (e.g., breathlessness due to infection), and over the course of the day due to physical exhaustion during heightened exertion. Remote estimation of RR can offer a cost-effective method to track disease progression and cardio-respiratory fitness over time. This work investigates a model-driven approach to estimate RR from short audio segments obtained after physical exertion in healthy adults. Data was collected from 21 individuals using microphone-enabled, near-field headphones before, during, and after strenuous exercise. RR was manually annotated by counting perceived inhalations and exhalations. A multi-task Long-Short Term Memory (LSTM) network with convolutional layers was implemented to process mel-filterbank energies, estimate RR in varying background noise conditions, and predict heavy breathing, indicated by an RR of more than 25 breaths per minute. The multi-task model performs both classification and regression tasks and leverages a mixture of loss functions. It was observed that RR can be estimated with a concordance correlation coefficient (CCC) of 0.76 and a mean squared error (MSE) of 0.2, demonstrating that audio can be a viable signal for approximating RR.
Analysis and Tuning of a Voice Assistant System for Dysfluent Speech
Jun 18, 2021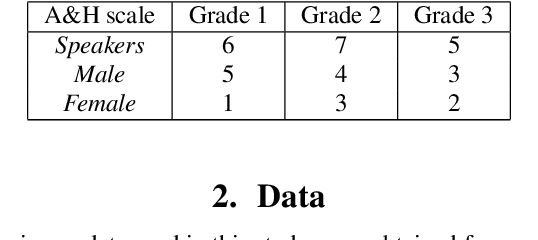
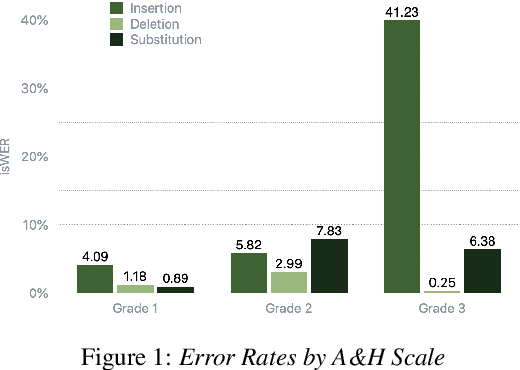
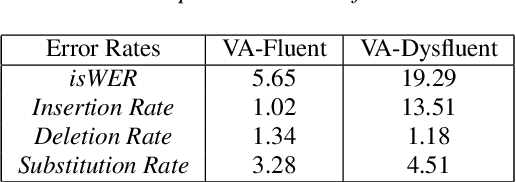
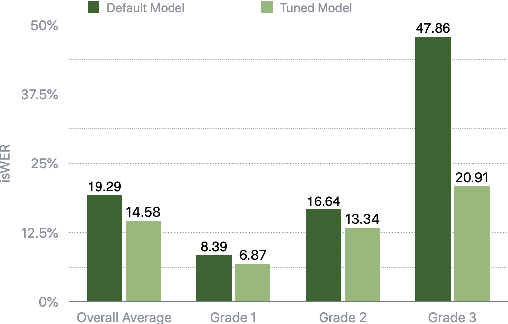
Dysfluencies and variations in speech pronunciation can severely degrade speech recognition performance, and for many individuals with moderate-to-severe speech disorders, voice operated systems do not work. Current speech recognition systems are trained primarily with data from fluent speakers and as a consequence do not generalize well to speech with dysfluencies such as sound or word repetitions, sound prolongations, or audible blocks. The focus of this work is on quantitative analysis of a consumer speech recognition system on individuals who stutter and production-oriented approaches for improving performance for common voice assistant tasks (i.e., "what is the weather?"). At baseline, this system introduces a significant number of insertion and substitution errors resulting in intended speech Word Error Rates (isWER) that are 13.64\% worse (absolute) for individuals with fluency disorders. We show that by simply tuning the decoding parameters in an existing hybrid speech recognition system one can improve isWER by 24\% (relative) for individuals with fluency disorders. Tuning these parameters translates to 3.6\% better domain recognition and 1.7\% better intent recognition relative to the default setup for the 18 study participants across all stuttering severities.