 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Deep Neural Mel-Subband Beamformer for In-car Speech Separation
Nov 22, 2022
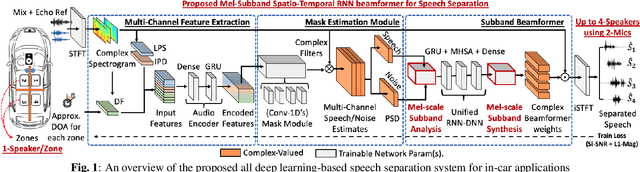
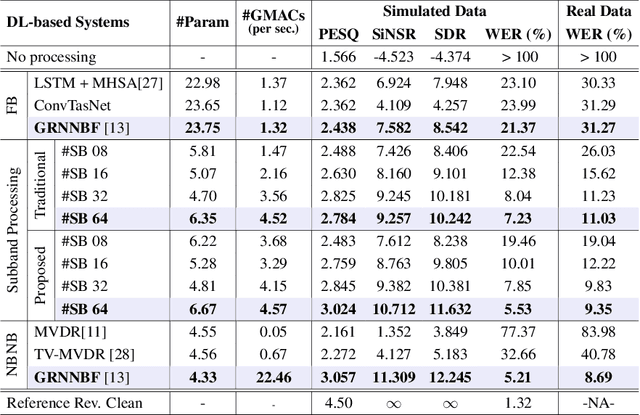
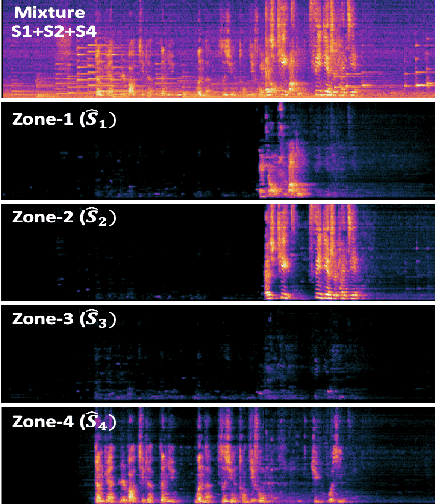
While current deep learning (DL)-based beamforming techniques have been proved effective in speech separation, they are often designed to process narrow-band (NB) frequencies independently which results in higher computational costs and inference times, making them unsuitable for real-world use. In this paper, we propose DL-based mel-subband spatio-temporal beamformer to perform speech separation in a car environment with reduced computation cost and inference time. As opposed to conventional subband (SB) approaches, our framework uses a mel-scale based subband selection strategy which ensures a fine-grained processing for lower frequencies where most speech formant structure is present, and coarse-grained processing for higher frequencies. In a recursive way, robust frame-level beamforming weights are determined for each speaker location/zone in a car from the estimated subband speech and noise covariance matrices. Furthermore, proposed framework also estimates and suppresses any echoes from the loudspeaker(s) by using the echo reference signals. We compare the performance of our proposed framework to several NB, SB, and full-band (FB) processing techniques in terms of speech quality and recognition metrics. Based on experimental evaluations on simulated and real-world recordings, we find that our proposed framework achieves better separation performance over all SB and FB approaches and achieves performance closer to NB processing techniques while requiring lower computing cost.
A Curriculum Learning Method for Improved Noise Robustness in Automatic Speech Recognition
Sep 16, 2016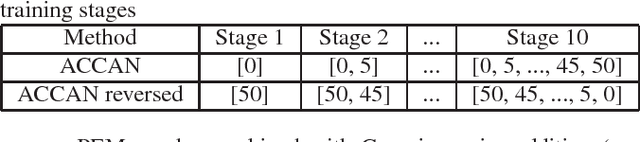
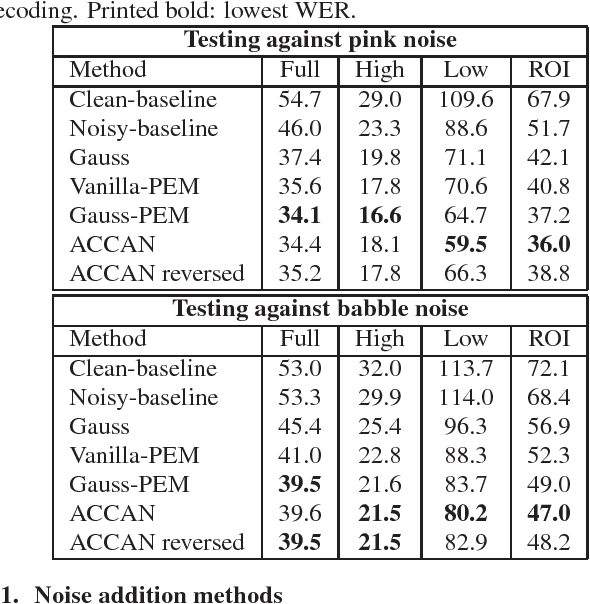
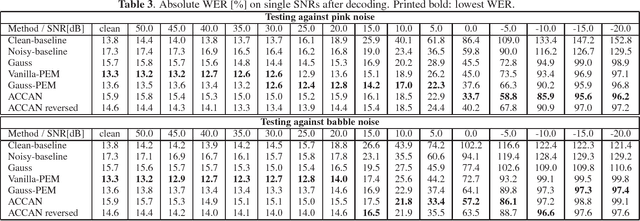
The performance of automatic speech recognition systems under noisy environments still leaves room for improvement. Speech enhancement or feature enhancement techniques for increasing noise robustness of these systems usually add components to the recognition system that need careful optimization. In this work, we propose the use of a relatively simple curriculum training strategy called accordion annealing (ACCAN). It uses a multi-stage training schedule where samples at signal-to-noise ratio (SNR) values as low as 0dB are first added and samples at increasing higher SNR values are gradually added up to an SNR value of 50dB. We also use a method called per-epoch noise mixing (PEM) that generates noisy training samples online during training and thus enables dynamically changing the SNR of our training data. Both the ACCAN and the PEM methods are evaluated on a end-to-end speech recognition pipeline on the Wall Street Journal corpus. ACCAN decreases the average word error rate (WER) on the 20dB to -10dB SNR range by up to 31.4% when compared to a conventional multi-condition training method.
Scaling ASR Improves Zero and Few Shot Learning
Nov 10, 2021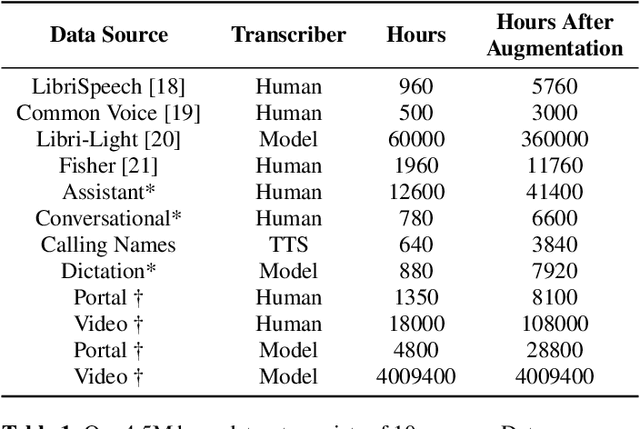
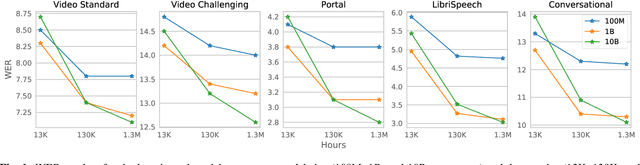
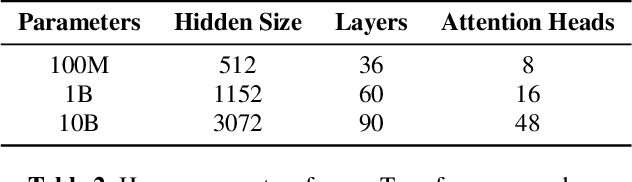
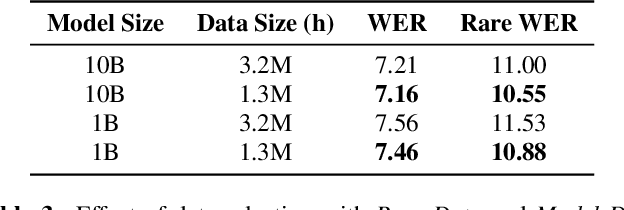
With 4.5 million hours of English speech from 10 different sources across 120 countries and models of up to 10 billion parameters, we explore the frontiers of scale for automatic speech recognition. We propose data selection techniques to efficiently scale training data to find the most valuable samples in massive datasets. To efficiently scale model sizes, we leverage various optimizations such as sparse transducer loss and model sharding. By training 1-10B parameter universal English ASR models, we push the limits of speech recognition performance across many domains. Furthermore, our models learn powerful speech representations with zero and few-shot capabilities on novel domains and styles of speech, exceeding previous results across multiple in-house and public benchmarks. For speakers with disorders due to brain damage, our best zero-shot and few-shot models achieve 22% and 60% relative improvement on the AphasiaBank test set, respectively, while realizing the best performance on public social media videos. Furthermore, the same universal model reaches equivalent performance with 500x less in-domain data on the SPGISpeech financial-domain dataset.
Robust and Complex Approach of Pathological Speech Signal Analysis
Mar 17, 2022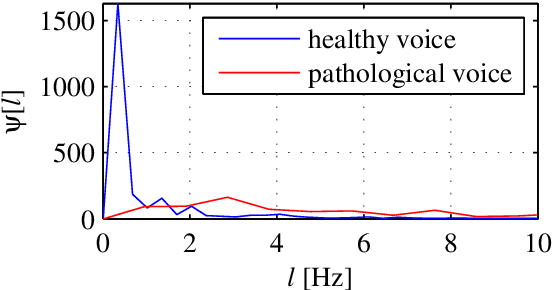
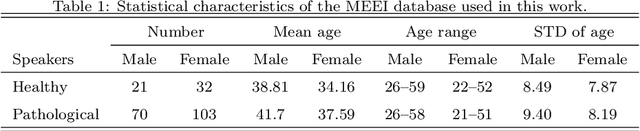
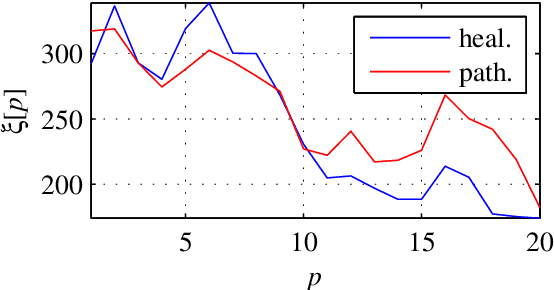
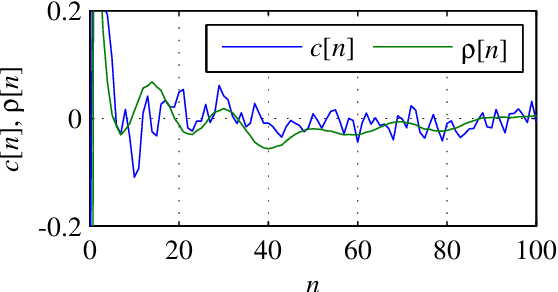
This paper presents a study of the approaches in the state-of-the-art in the field of pathological speech signal analysis with a special focus on parametrization techniques. It provides a description of 92 speech features where some of them are already widely used in this field of science and some of them have not been tried yet (they come from different areas of speech signal processing like speech recognition or coding). As an original contribution, this work introduces 36 completely new pathological voice measures based on modulation spectra, inferior colliculus coefficients, bicepstrum, sample and approximate entropy and empirical mode decomposition. The significance of these features was tested on 3 (English, Spanish and Czech) pathological voice databases with respect to classification accuracy, sensitivity and specificity.
* 41 pages, published in Neurocomputing, Volume 167, 2015, Pages 94-111, ISSN 0925-2312
Towards Unsupervised Automatic Speech Recognition Trained by Unaligned Speech and Text only
Aug 11, 2018



Automatic speech recognition (ASR) has been widely researched with supervised approaches, while many low-resourced languages lack audio-text aligned data, and supervised methods cannot be applied on them. In this work, we propose a framework to achieve unsupervised ASR on a read English speech dataset, where audio and text are unaligned. In the first stage, each word-level audio segment in the utterances is represented by a vector representation extracted by a sequence-of-sequence autoencoder, in which phonetic information and speaker information are disentangled. Secondly, semantic embeddings of audio segments are trained from the vector representations using a skip-gram model. Last but not the least, an unsupervised method is utilized to transform semantic embeddings of audio segments to text embedding space, and finally the transformed embeddings are mapped to words. With the above framework, we are towards unsupervised ASR trained by unaligned text and speech only.
End-to-end Speech Recognition with Adaptive Computation Steps
Sep 26, 2018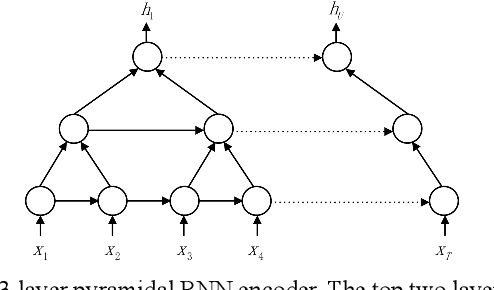

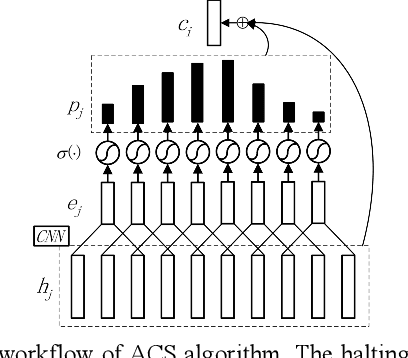
In this paper, we present Adaptive Computation Steps (ACS) algo-rithm, which enables end-to-end speech recognition models to dy-namically decide how many frames should be processed to predict a linguistic output. The model that applies ACS algorithm follows the encoder-decoder framework, while unlike the attention-based mod-els, it produces alignments independently at the encoder side using the correlation between adjacent frames. Thus, predictions can be made as soon as sufficient acoustic information is received, which makes the model applicable in online cases. Besides, a small change is made to the decoding stage of the encoder-decoder framework, which allows the prediction to exploit bidirectional contexts. We verify the ACS algorithm on a Mandarin speech corpus AIShell-1, and it achieves a 31.2% CER in the online occasion, compared to the 32.4% CER of the attention-based model. To fully demonstrate the advantage of ACS algorithm, offline experiments are conducted, in which our ACS model achieves an 18.7% CER, outperforming the attention-based counterpart with the CER of 22.0%.
Almost Unsupervised Text to Speech and Automatic Speech Recognition
May 22, 2019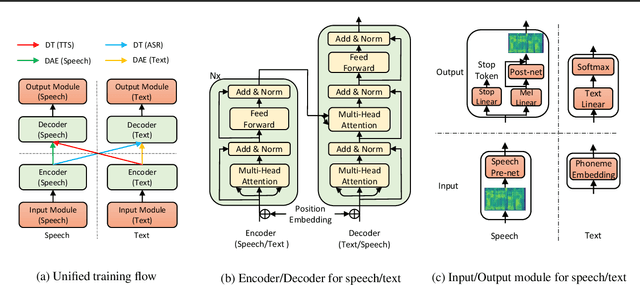
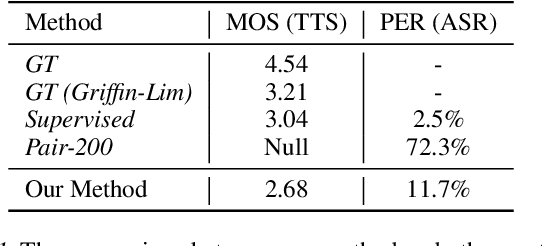
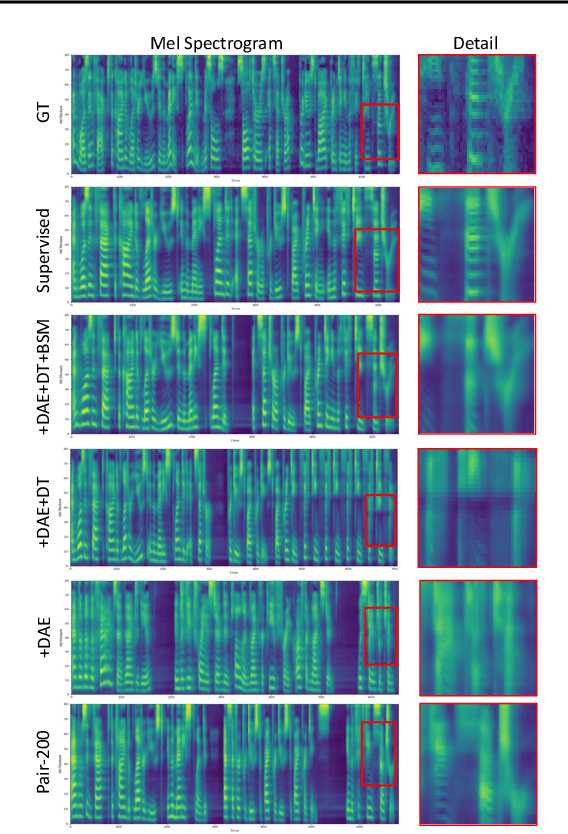

Text to speech (TTS) and automatic speech recognition (ASR) are two dual tasks in speech processing and both achieve impressive performance thanks to the recent advance in deep learning and large amount of aligned speech and text data. However, the lack of aligned data poses a major practical problem for TTS and ASR on low-resource languages. In this paper, by leveraging the dual nature of the two tasks, we propose an almost unsupervised learning method that only leverages few hundreds of paired data and extra unpaired data for TTS and ASR. Our method consists of the following components: (1) a denoising auto-encoder, which reconstructs speech and text sequences respectively to develop the capability of language modeling both in speech and text domain; (2) dual transformation, where the TTS model transforms the text $y$ into speech $\hat{x}$, and the ASR model leverages the transformed pair $(\hat{x},y)$ for training, and vice versa, to boost the accuracy of the two tasks; (3) bidirectional sequence modeling, which addresses error propagation especially in the long speech and text sequence when training with few paired data; (4) a unified model structure, which combines all the above components for TTS and ASR based on Transformer model. Our method achieves 99.84% in terms of word level intelligible rate and 2.68 MOS for TTS, and 11.7% PER for ASR on LJSpeech dataset, by leveraging only 200 paired speech and text data (about 20 minutes audio), together with extra unpaired speech and text data.
Thoughts on the potential to compensate a hearing loss in noise
Feb 24, 2021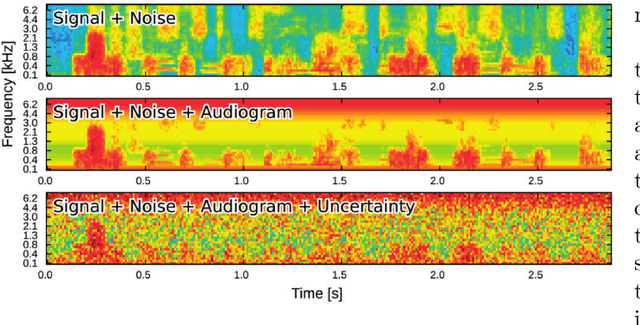
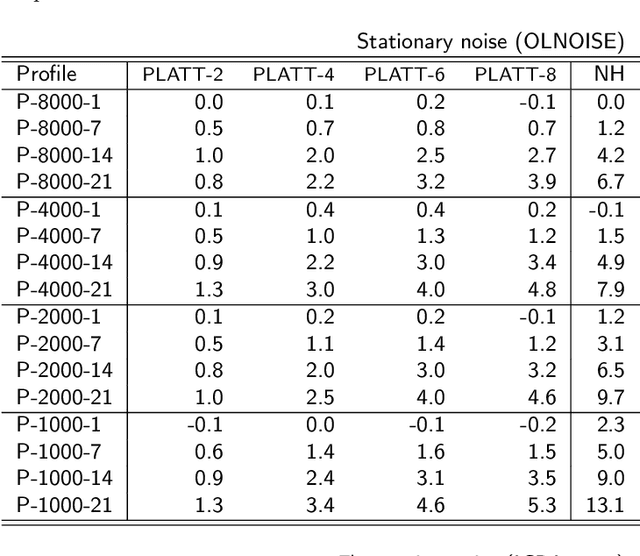
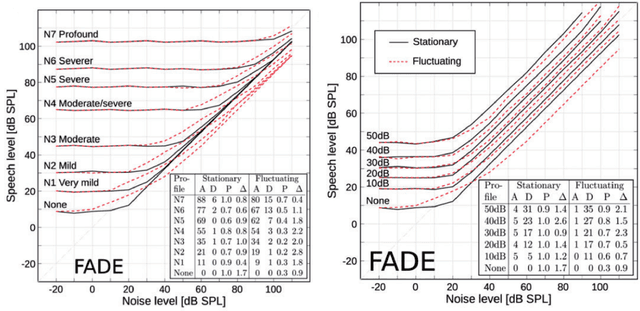
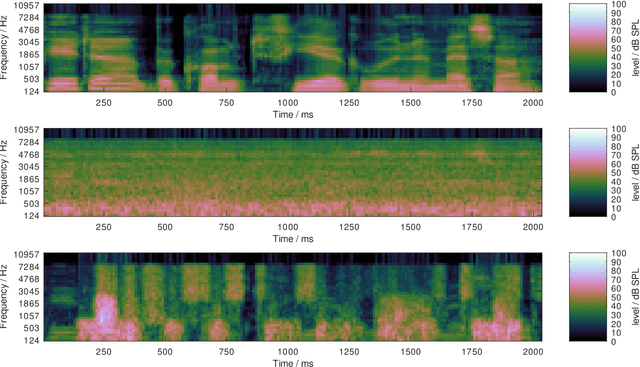
The effect of hearing impairment on speech perception was described by Plomp (1978) as a sum of a loss of class A, due to signal attenuation, and a loss of class D, due to signal distortion. While a loss of class A can be compensated by linear amplification, a loss of class D, which severely limits the benefit of hearing aids in noisy listening conditions, cannot. Not few users of hearing aids keep complaining about the limited benefit of their devices in noisy environments. Recently, in an approach to model human speech recognition by means of a re-purposed automatic speech recognition system, the loss of class D was explained by introducing a level uncertainty which reduces the individual accuracy of spectro-temporal signal levels. Based on this finding, an implementation of a patented dynamic range manipulation scheme (PLATT) is proposed, which aims to mitigate the effect of increased level uncertainty on speech recognition in noise by expanding spectral modulation patterns in the range of 2 to 4 ERB. An objective evaluation of the benefit in speech recognition thresholds in noise using an ASR-based speech recognition model suggests that more than half of the class D loss due to an increased level uncertainty might be compensable.
Integrating Whole Context to Sequence-to-sequence Speech Recognition
Dec 04, 2019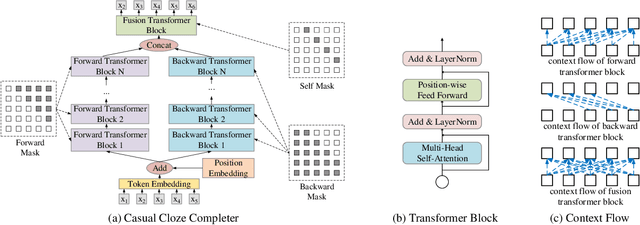
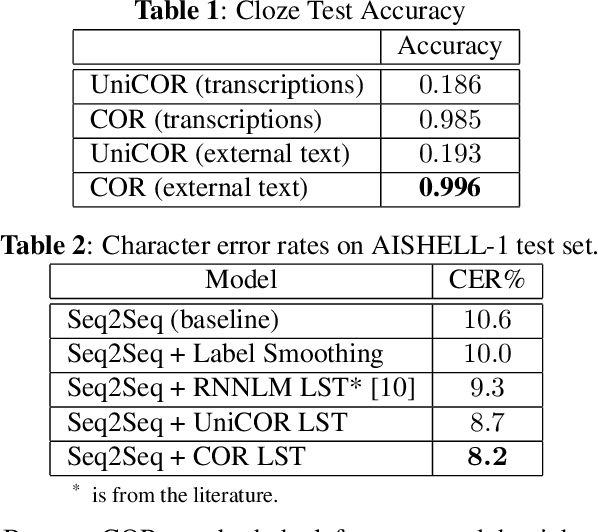
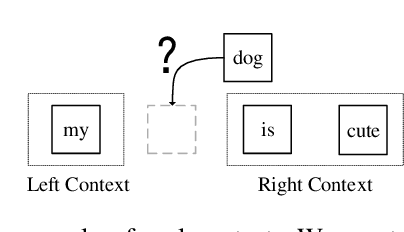
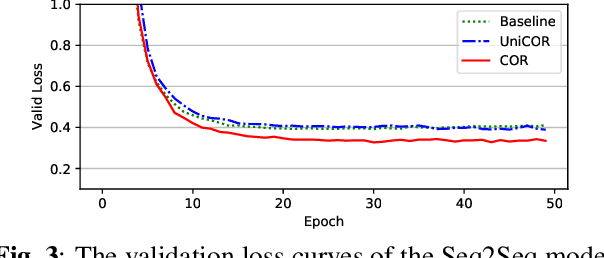
Because an attention based sequence-to-sequence speech (Seq2Seq) recognition model decodes a token sequence in a left-to-right manner, it is non-trivial for the decoder to leverage the whole context of the target sequence. In this paper, we propose a self-attention mechanism based language model called casual cloze completer (COR), which models the left context and the right context simultaneously. Then, we utilize our previously proposed "Learn Spelling from Teachers" approach to integrate the whole context knowledge from COR to the Seq2Seq model. We conduct the experiments on public Chinese dataset AISHELL-1. The experimental results show that leveraging whole context can improve the performance of the Seq2Seq model.
Speech Corpus of Ainu Folklore and End-to-end Speech Recognition for Ainu Language
Feb 19, 2020
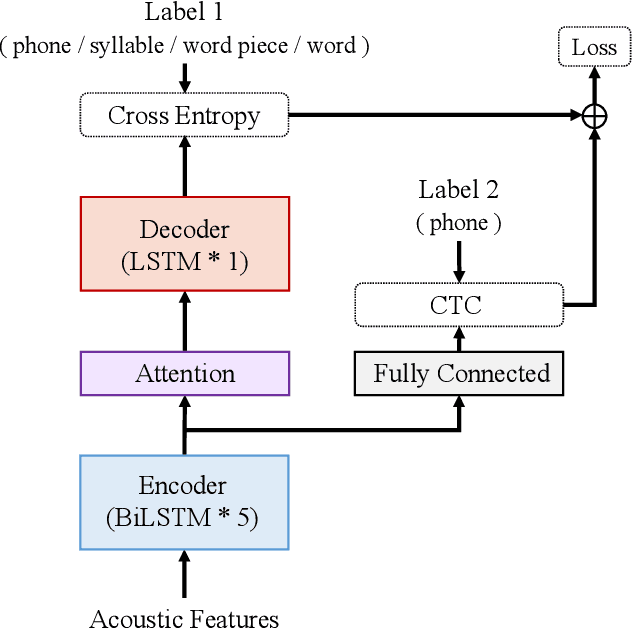
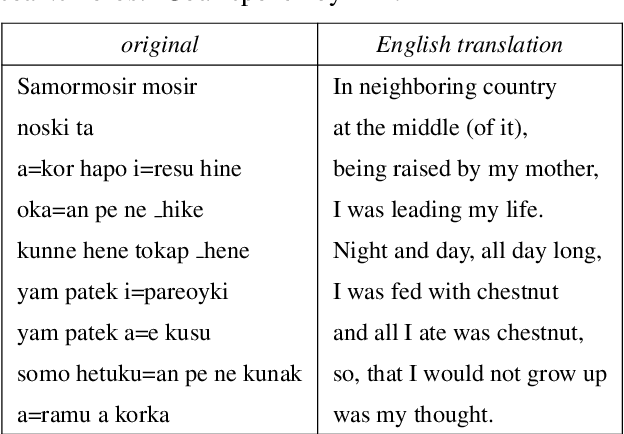
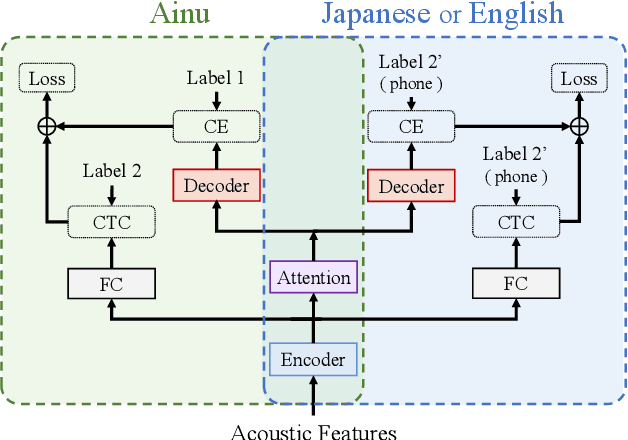
Ainu is an unwritten language that has been spoken by Ainu people who are one of the ethnic groups in Japan. It is recognized as critically endangered by UNESCO and archiving and documentation of its language heritage is of paramount importance. Although a considerable amount of voice recordings of Ainu folklore has been produced and accumulated to save their culture, only a quite limited parts of them are transcribed so far. Thus, we started a project of automatic speech recognition (ASR) for the Ainu language in order to contribute to the development of annotated language archives. In this paper, we report speech corpus development and the structure and performance of end-to-end ASR for Ainu. We investigated four modeling units (phone, syllable, word piece, and word) and found that the syllable-based model performed best in terms of both word and phone recognition accuracy, which were about 60% and over 85% respectively in speaker-open condition. Furthermore, word and phone accuracy of 80% and 90% has been achieved in a speaker-closed setting. We also found out that a multilingual ASR training with additional speech corpora of English and Japanese further improves the speaker-open test accuracy.