Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Whole Context to Sequence-to-sequence Speech Recognition
Paper and Code
Dec 04, 2019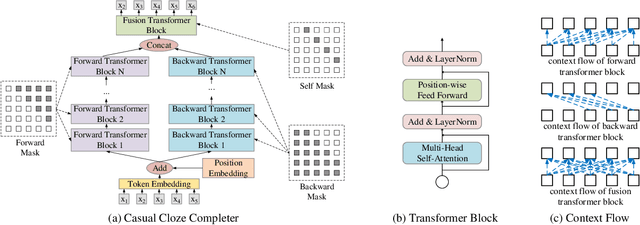
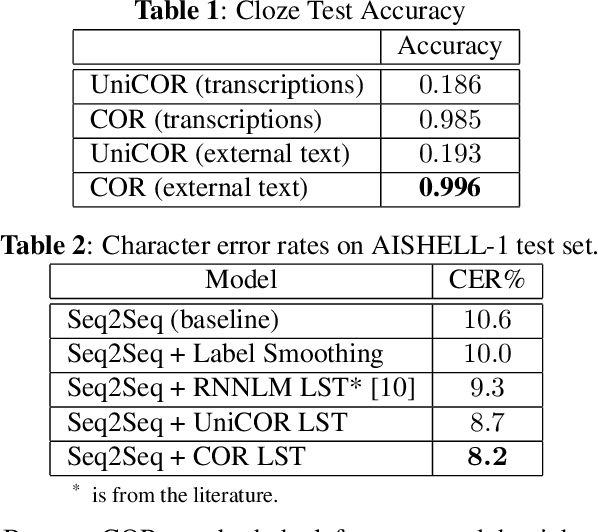
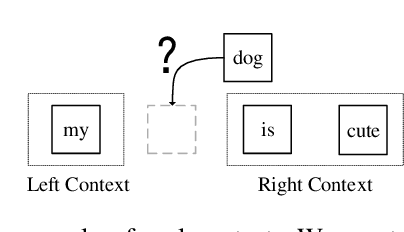
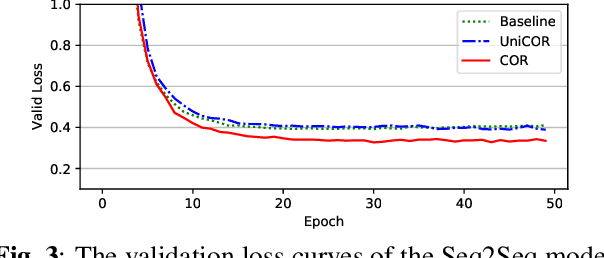
Because an attention based sequence-to-sequence speech (Seq2Seq) recognition model decodes a token sequence in a left-to-right manner, it is non-trivial for the decoder to leverage the whole context of the target sequence. In this paper, we propose a self-attention mechanism based language model called casual cloze completer (COR), which models the left context and the right context simultaneously. Then, we utilize our previously proposed "Learn Spelling from Teachers" approach to integrate the whole context knowledge from COR to the Seq2Seq model. We conduct the experiments on public Chinese dataset AISHELL-1. The experimental results show that leveraging whole context can improve the performance of the Seq2Seq model.
* 5 pages, 5 figures
View paper on