 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Learning linearly separable features for speech recognition using convolutional neural networks
Apr 16, 2015
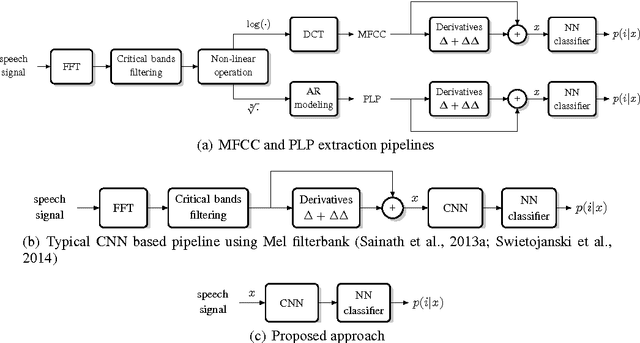
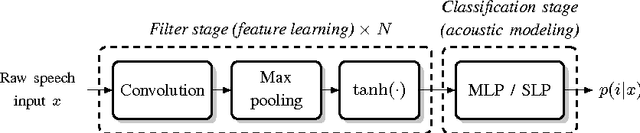
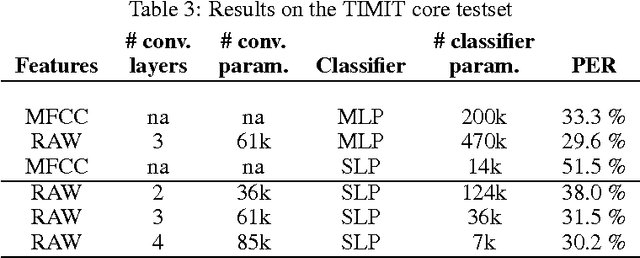
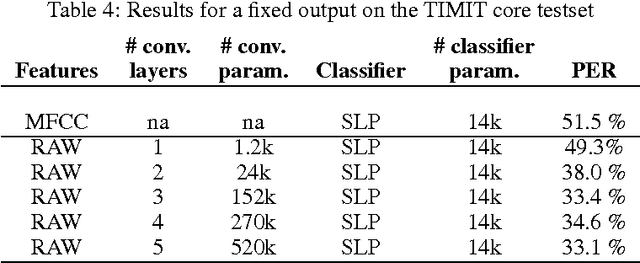
Automatic speech recognition systems usually rely on spectral-based features, such as MFCC of PLP. These features are extracted based on prior knowledge such as, speech perception or/and speech production. Recently, convolutional neural networks have been shown to be able to estimate phoneme conditional probabilities in a completely data-driven manner, i.e. using directly temporal raw speech signal as input. This system was shown to yield similar or better performance than HMM/ANN based system on phoneme recognition task and on large scale continuous speech recognition task, using less parameters. Motivated by these studies, we investigate the use of simple linear classifier in the CNN-based framework. Thus, the network learns linearly separable features from raw speech. We show that such system yields similar or better performance than MLP based system using cepstral-based features as input.
Leveraging Acoustic Contextual Representation by Audio-textual Cross-modal Learning for Conversational ASR
Jul 03, 2022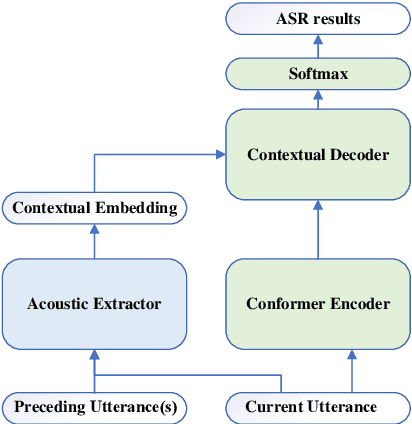
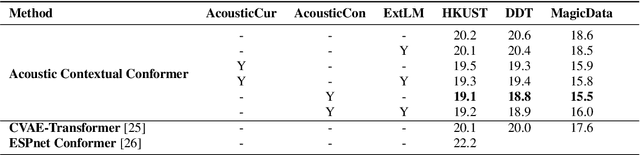
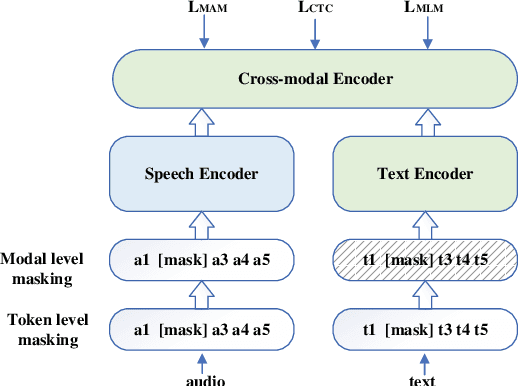

Leveraging context information is an intuitive idea to improve performance on conversational automatic speech recognition(ASR). Previous works usually adopt recognized hypotheses of historical utterances as preceding context, which may bias the current recognized hypothesis due to the inevitable historicalrecognition errors. To avoid this problem, we propose an audio-textual cross-modal representation extractor to learn contextual representations directly from preceding speech. Specifically, it consists of two modal-related encoders, extracting high-level latent features from speech and the corresponding text, and a cross-modal encoder, which aims to learn the correlation between speech and text. We randomly mask some input tokens and input sequences of each modality. Then a token-missing or modal-missing prediction with a modal-level CTC loss on the cross-modal encoder is performed. Thus, the model captures not only the bi-directional context dependencies in a specific modality but also relationships between different modalities. Then, during the training of the conversational ASR system, the extractor will be frozen to extract the textual representation of preceding speech, while such representation is used as context fed to the ASR decoder through attention mechanism. The effectiveness of the proposed approach is validated on several Mandarin conversation corpora and the highest character error rate (CER) reduction up to 16% is achieved on the MagicData dataset.
"How Robust r u?": Evaluating Task-Oriented Dialogue Systems on Spoken Conversations
Sep 28, 2021
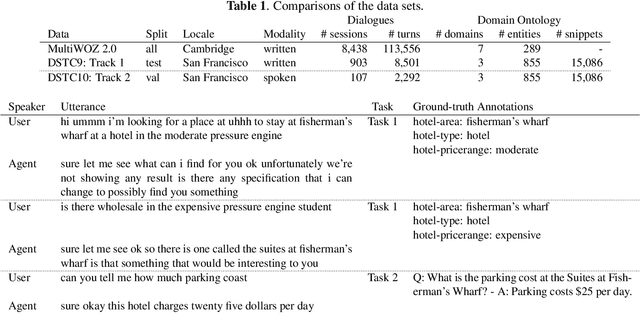
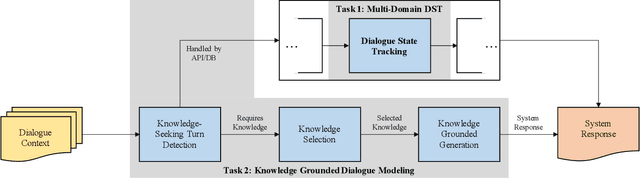

Most prior work in dialogue modeling has been on written conversations mostly because of existing data sets. However, written dialogues are not sufficient to fully capture the nature of spoken conversations as well as the potential speech recognition errors in practical spoken dialogue systems. This work presents a new benchmark on spoken task-oriented conversations, which is intended to study multi-domain dialogue state tracking and knowledge-grounded dialogue modeling. We report that the existing state-of-the-art models trained on written conversations are not performing well on our spoken data, as expected. Furthermore, we observe improvements in task performances when leveraging n-best speech recognition hypotheses such as by combining predictions based on individual hypotheses. Our data set enables speech-based benchmarking of task-oriented dialogue systems.
Variable-rate hierarchical CPC leads to acoustic unit discovery in speech
Jun 07, 2022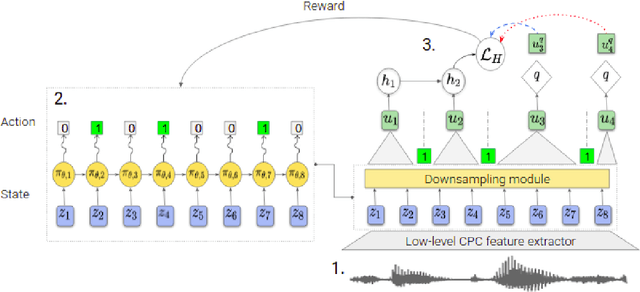
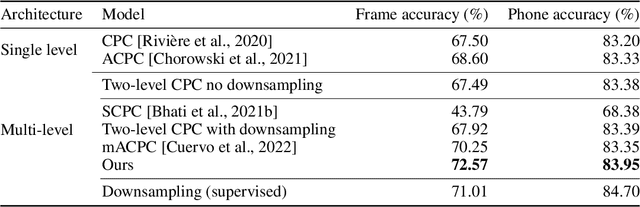

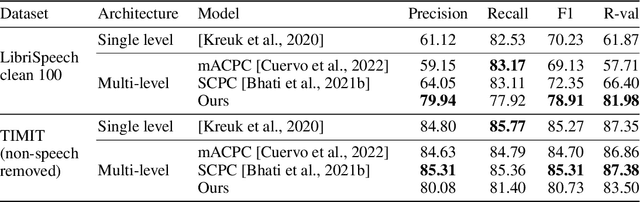
The success of deep learning comes from its ability to capture the hierarchical structure of data by learning high-level representations defined in terms of low-level ones. In this paper we explore self-supervised learning of hierarchical representations of speech by applying multiple levels of Contrastive Predictive Coding (CPC). We observe that simply stacking two CPC models does not yield significant improvements over single-level architectures. Inspired by the fact that speech is often described as a sequence of discrete units unevenly distributed in time, we propose a model in which the output of a low-level CPC module is non-uniformly downsampled to directly minimize the loss of a high-level CPC module. The latter is designed to also enforce a prior of separability and discreteness in its representations by enforcing dissimilarity of successive high-level representations through focused negative sampling, and by quantization of the prediction targets. Accounting for the structure of the speech signal improves upon single-level CPC features and enhances the disentanglement of the learned representations, as measured by downstream speech recognition tasks, while resulting in a meaningful segmentation of the signal that closely resembles phone boundaries.
Distilling Knowledge Using Parallel Data for Far-field Speech Recognition
Feb 20, 2018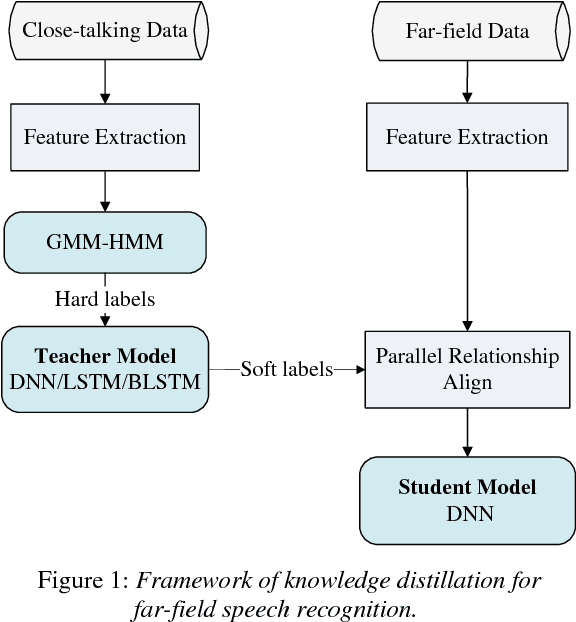

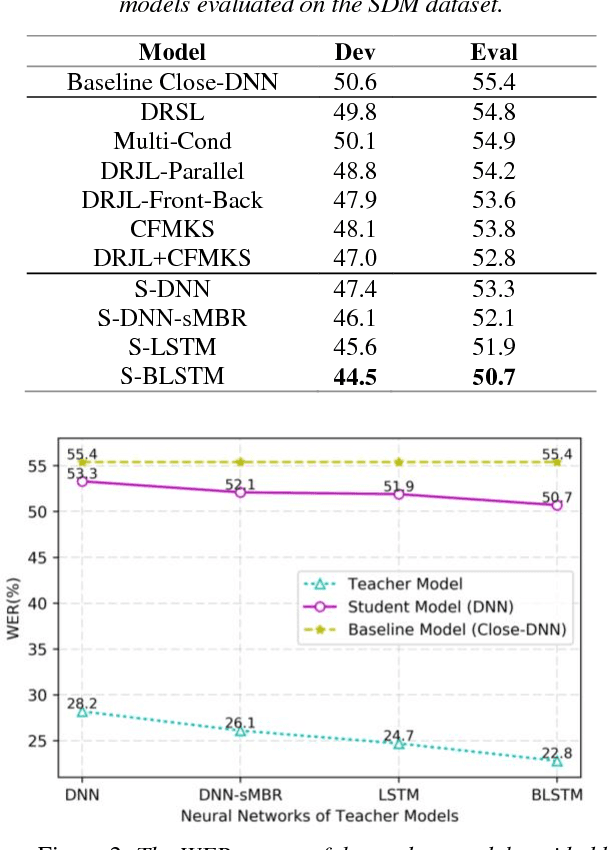
In order to improve the performance for far-field speech recognition, this paper proposes to distill knowledge from the close-talking model to the far-field model using parallel data. The close-talking model is called the teacher model. The far-field model is called the student model. The student model is trained to imitate the output distributions of the teacher model. This constraint can be realized by minimizing the Kullback-Leibler (KL) divergence between the output distribution of the student model and the teacher model. Experimental results on AMI corpus show that the best student model achieves up to 4.7% absolute word error rate (WER) reduction when compared with the conventionally-trained baseline models.
Analyzing Phonetic and Graphemic Representations in End-to-End Automatic Speech Recognition
Jul 09, 2019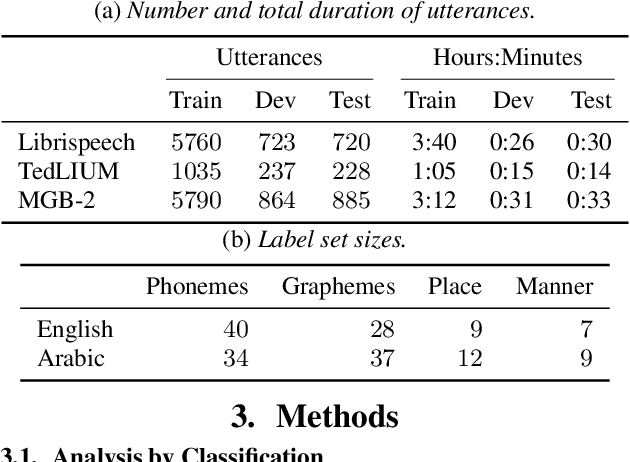
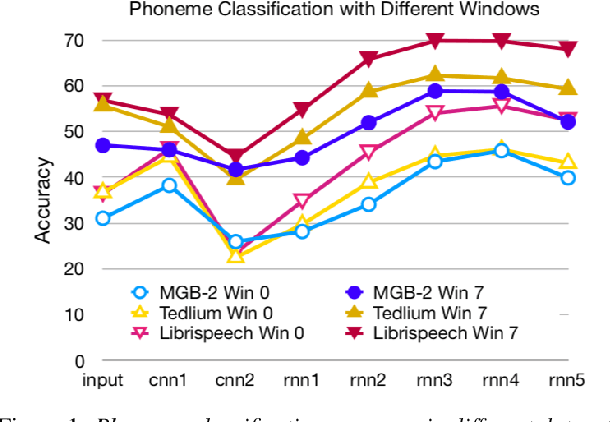

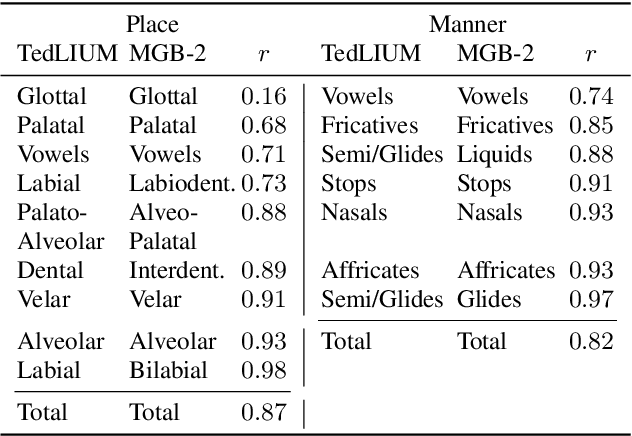
End-to-end neural network systems for automatic speech recognition (ASR) are trained from acoustic features to text transcriptions. In contrast to modular ASR systems, which contain separately-trained components for acoustic modeling, pronunciation lexicon, and language modeling, the end-to-end paradigm is both conceptually simpler and has the potential benefit of training the entire system on the end task. However, such neural network models are more opaque: it is not clear how to interpret the role of different parts of the network and what information it learns during training. In this paper, we analyze the learned internal representations in an end-to-end ASR model. We evaluate the representation quality in terms of several classification tasks, comparing phonemes and graphemes, as well as different articulatory features. We study two languages (English and Arabic) and three datasets, finding remarkable consistency in how different properties are represented in different layers of the deep neural network.
Transfer Learning for Robust Low-Resource Children's Speech ASR with Transformers and Source-Filter Warping
Jun 19, 2022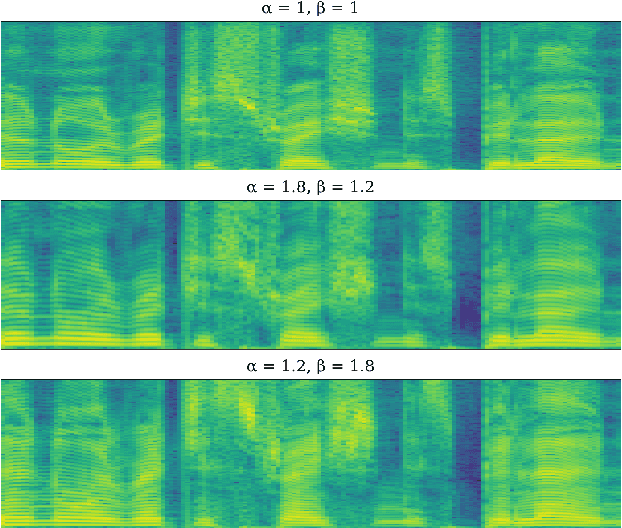
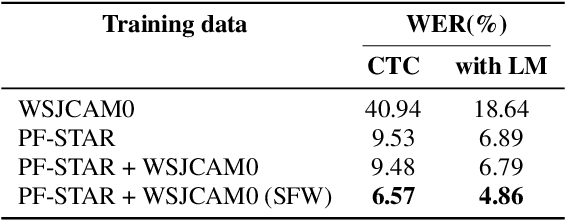
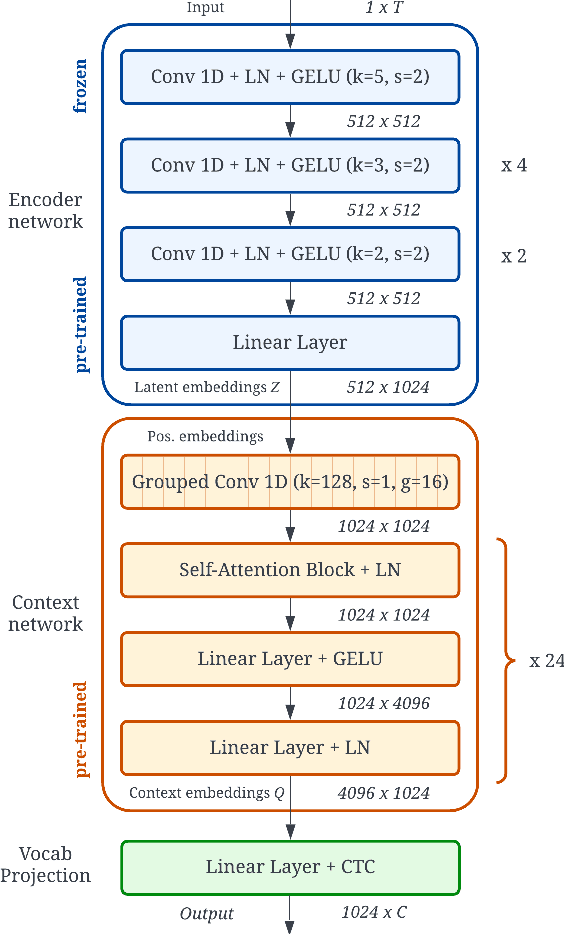
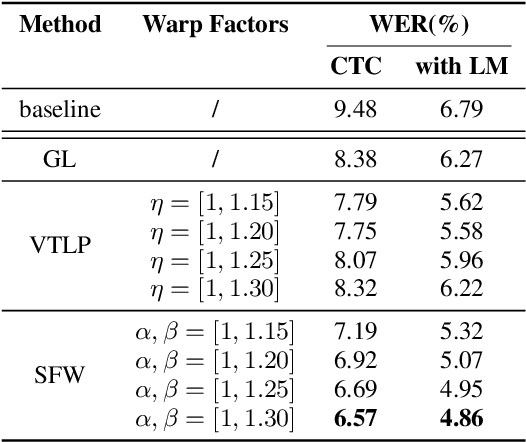
Automatic Speech Recognition (ASR) systems are known to exhibit difficulties when transcribing children's speech. This can mainly be attributed to the absence of large children's speech corpora to train robust ASR models and the resulting domain mismatch when decoding children's speech with systems trained on adult data. In this paper, we propose multiple enhancements to alleviate these issues. First, we propose a data augmentation technique based on the source-filter model of speech to close the domain gap between adult and children's speech. This enables us to leverage the data availability of adult speech corpora by making these samples perceptually similar to children's speech. Second, using this augmentation strategy, we apply transfer learning on a Transformer model pre-trained on adult data. This model follows the recently introduced XLS-R architecture, a wav2vec 2.0 model pre-trained on several cross-lingual adult speech corpora to learn general and robust acoustic frame-level representations. Adopting this model for the ASR task using adult data augmented with the proposed source-filter warping strategy and a limited amount of in-domain children's speech significantly outperforms previous state-of-the-art results on the PF-STAR British English Children's Speech corpus with a 4.86% WER on the official test set.
On the Impact of Word Error Rate on Acoustic-Linguistic Speech Emotion Recognition: An Update for the Deep Learning Era
Apr 20, 2021
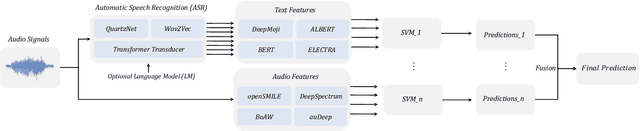
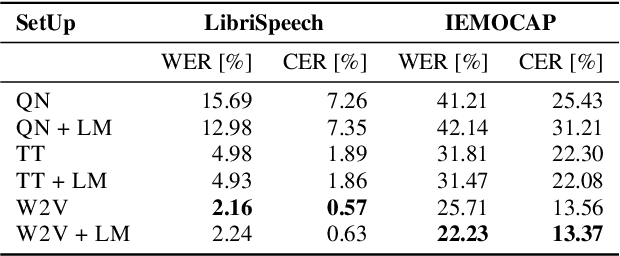

Text encodings from automatic speech recognition (ASR) transcripts and audio representations have shown promise in speech emotion recognition (SER) ever since. Yet, it is challenging to explain the effect of each information stream on the SER systems. Further, more clarification is required for analysing the impact of ASR's word error rate (WER) on linguistic emotion recognition per se and in the context of fusion with acoustic information exploitation in the age of deep ASR systems. In order to tackle the above issues, we create transcripts from the original speech by applying three modern ASR systems, including an end-to-end model trained with recurrent neural network-transducer loss, a model with connectionist temporal classification loss, and a wav2vec framework for self-supervised learning. Afterwards, we use pre-trained textual models to extract text representations from the ASR outputs and the gold standard. For extraction and learning of acoustic speech features, we utilise openSMILE, openXBoW, DeepSpectrum, and auDeep. Finally, we conduct decision-level fusion on both information streams -- acoustics and linguistics. Using the best development configuration, we achieve state-of-the-art unweighted average recall values of $73.6\,\%$ and $73.8\,\%$ on the speaker-independent development and test partitions of IEMOCAP, respectively.
Decoupled Federated Learning for ASR with Non-IID Data
Jun 18, 2022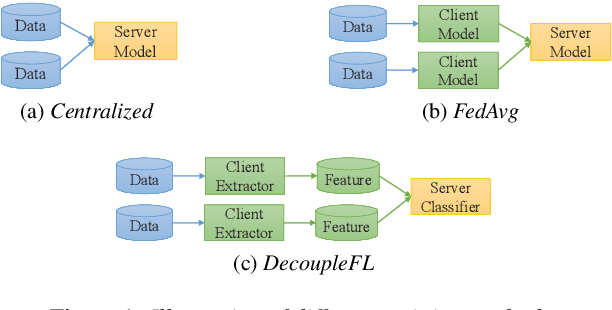
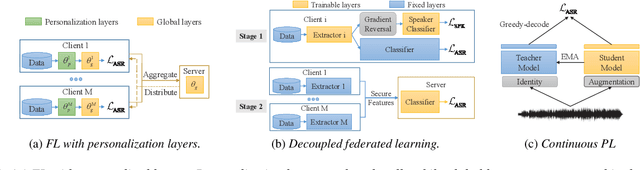
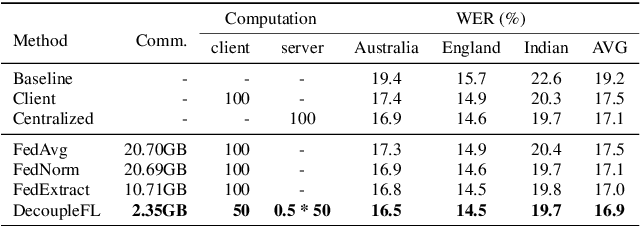
Automatic speech recognition (ASR) with federated learning (FL) makes it possible to leverage data from multiple clients without compromising privacy. The quality of FL-based ASR could be measured by recognition performance, communication and computation costs. When data among different clients are not independently and identically distributed (non-IID), the performance could degrade significantly. In this work, we tackle the non-IID issue in FL-based ASR with personalized FL, which learns personalized models for each client. Concretely, we propose two types of personalized FL approaches for ASR. Firstly, we adapt the personalization layer based FL for ASR, which keeps some layers locally to learn personalization models. Secondly, to reduce the communication and computation costs, we propose decoupled federated learning (DecoupleFL). On one hand, DecoupleFL moves the computation burden to the server, thus decreasing the computation on clients. On the other hand, DecoupleFL communicates secure high-level features instead of model parameters, thus reducing communication cost when models are large. Experiments demonstrate two proposed personalized FL-based ASR approaches could reduce WER by 2.3% - 3.4% compared with FedAvg. Among them, DecoupleFL has only 11.4% communication and 75% computation cost compared with FedAvg, which is also significantly less than the personalization layer based FL.
3M: Multi-loss, Multi-path and Multi-level Neural Networks for speech recognition
Apr 07, 2022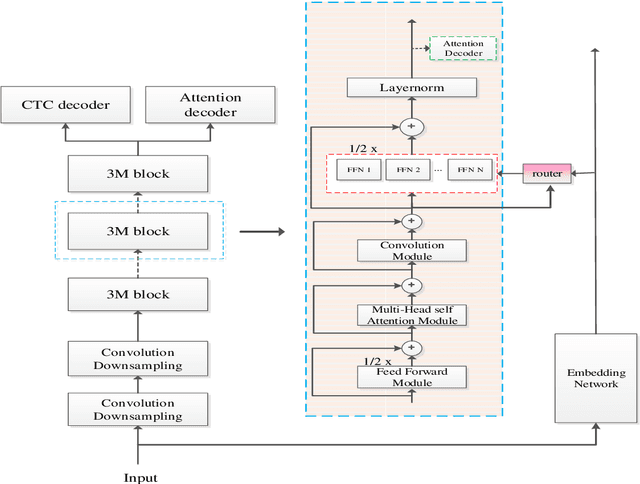
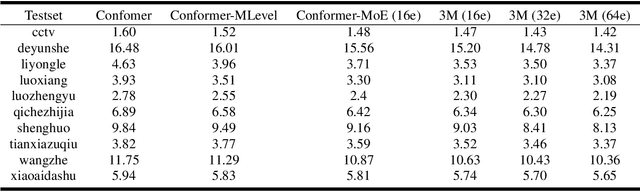
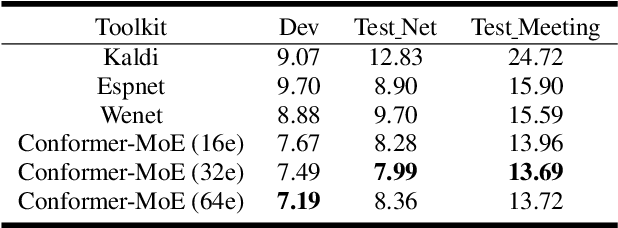
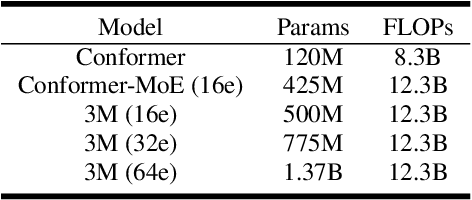
Recently, Conformer based CTC/AED model has become a mainstream architecture for ASR. In this paper, based on our prior work, we identify and integrate several approaches to achieve further improvements for ASR tasks, which we denote as multi-loss, multi-path and multi-level, summarized as "3M" model. Specifically, multi-loss refers to the joint CTC/AED loss and multi-path denotes the Mixture-of-Experts(MoE) architecture which can effectively increase the model capacity without remarkably increasing computation cost. Multi-level means that we introduce auxiliary loss at multiple level of a deep model to help training. We evaluate our proposed method on the public WenetSpeech dataset and experimental results show that the proposed method provides 12.2%-17.6% relative CER improvement over the baseline model trained by Wenet toolkit. On our large scale dataset of 150k hours corpus, the 3M model has also shown obvious superiority over the baseline Conformer model.