 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Self-Supervised Speech Representations for Cross-lingual Dysarthria Detection in Parkinson's Disease
Mar 23, 2026The limited availability of dysarthric speech data makes cross-lingual detection an important but challenging problem. A key difficulty is that speech representations often encode language-dependent structure that can confound dysarthria detection. We propose a representation-level language shift (LS) that aligns source-language self-supervised speech representations with the target-language distribution using centroid-based vector adaptation estimated from healthy-control speech. We evaluate the approach on oral DDK recordings from Parkinson's disease speech datasets in Czech, German, and Spanish under both cross-lingual and multilingual settings. LS substantially improves sensitivity and F1 in cross-lingual settings, while yielding smaller but consistent gains in multilingual settings. Representation analysis further shows that LS reduces language identity in the embedding space, supporting the interpretation that LS removes language-dependent structure.
Learning linearly separable features for speech recognition using convolutional neural networks
Apr 16, 2015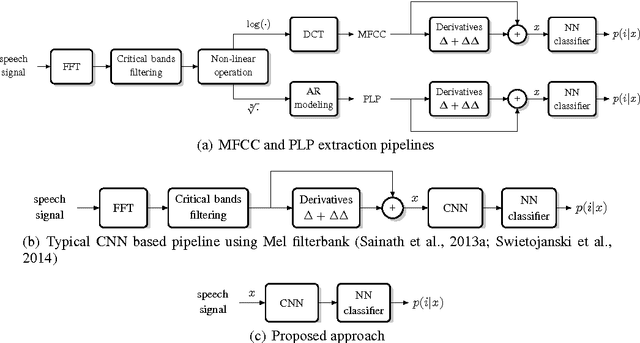
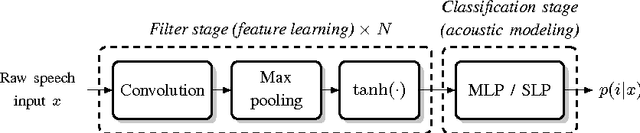
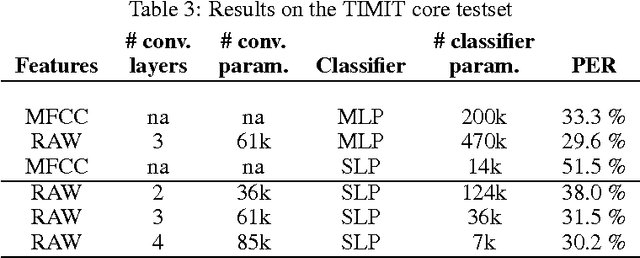
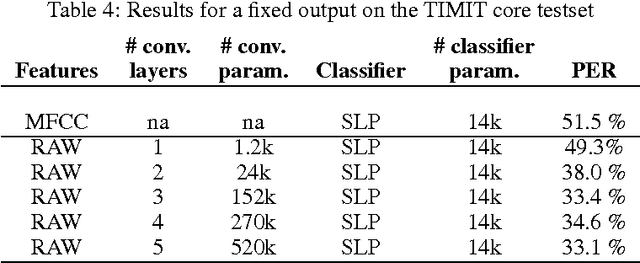
Automatic speech recognition systems usually rely on spectral-based features, such as MFCC of PLP. These features are extracted based on prior knowledge such as, speech perception or/and speech production. Recently, convolutional neural networks have been shown to be able to estimate phoneme conditional probabilities in a completely data-driven manner, i.e. using directly temporal raw speech signal as input. This system was shown to yield similar or better performance than HMM/ANN based system on phoneme recognition task and on large scale continuous speech recognition task, using less parameters. Motivated by these studies, we investigate the use of simple linear classifier in the CNN-based framework. Thus, the network learns linearly separable features from raw speech. We show that such system yields similar or better performance than MLP based system using cepstral-based features as input.