 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Acoustic Contextual Representation by Audio-textual Cross-modal Learning for Conversational ASR
Paper and Code
Jul 03, 2022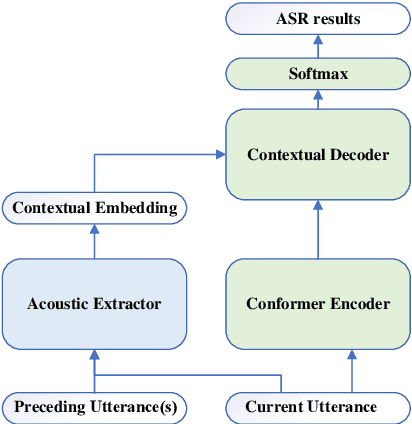
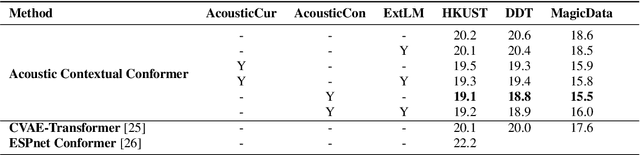
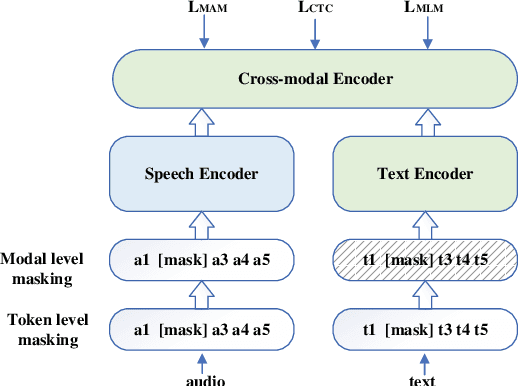

Leveraging context information is an intuitive idea to improve performance on conversational automatic speech recognition(ASR). Previous works usually adopt recognized hypotheses of historical utterances as preceding context, which may bias the current recognized hypothesis due to the inevitable historicalrecognition errors. To avoid this problem, we propose an audio-textual cross-modal representation extractor to learn contextual representations directly from preceding speech. Specifically, it consists of two modal-related encoders, extracting high-level latent features from speech and the corresponding text, and a cross-modal encoder, which aims to learn the correlation between speech and text. We randomly mask some input tokens and input sequences of each modality. Then a token-missing or modal-missing prediction with a modal-level CTC loss on the cross-modal encoder is performed. Thus, the model captures not only the bi-directional context dependencies in a specific modality but also relationships between different modalities. Then, during the training of the conversational ASR system, the extractor will be frozen to extract the textual representation of preceding speech, while such representation is used as context fed to the ASR decoder through attention mechanism. The effectiveness of the proposed approach is validated on several Mandarin conversation corpora and the highest character error rate (CER) reduction up to 16% is achieved on the MagicData dataset.