 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Efficient Speech Emotion Recognition Using Multi-Scale CNN and Attention
Jun 08, 2021
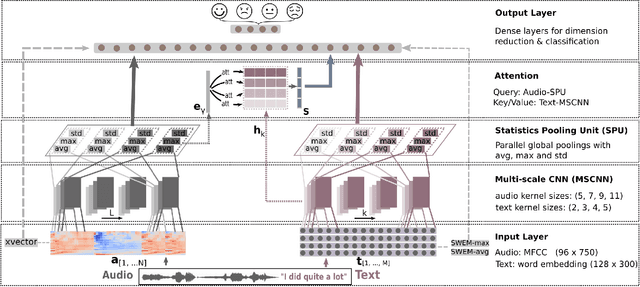
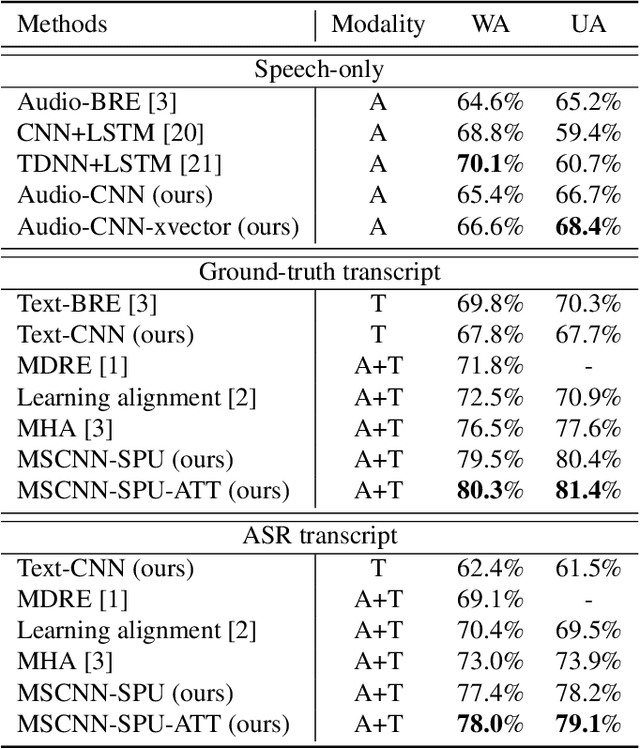

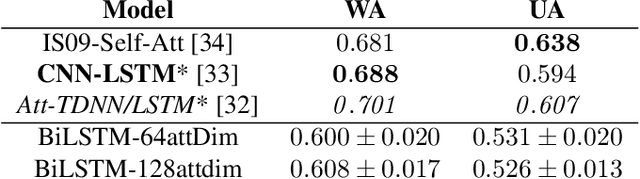
Emotion recognition from speech is a challenging task. Re-cent advances in deep learning have led bi-directional recur-rent neural network (Bi-RNN) and attention mechanism as astandard method for speech emotion recognition, extractingand attending multi-modal features - audio and text, and thenfusing them for downstream emotion classification tasks. Inthis paper, we propose a simple yet efficient neural networkarchitecture to exploit both acoustic and lexical informationfrom speech. The proposed framework using multi-scale con-volutional layers (MSCNN) to obtain both audio and text hid-den representations. Then, a statistical pooling unit (SPU)is used to further extract the features in each modality. Be-sides, an attention module can be built on top of the MSCNN-SPU (audio) and MSCNN (text) to further improve the perfor-mance. Extensive experiments show that the proposed modeloutperforms previous state-of-the-art methods on IEMOCAPdataset with four emotion categories (i.e., angry, happy, sadand neutral) in both weighted accuracy (WA) and unweightedaccuracy (UA), with an improvement of 5.0% and 5.2% respectively under the ASR setting.
* First two authors contributed equally.Accepted by ICASSP 2021
Self-Supervised Speech Representations Preserve Speech Characteristics while Anonymizing Voices
Apr 04, 2022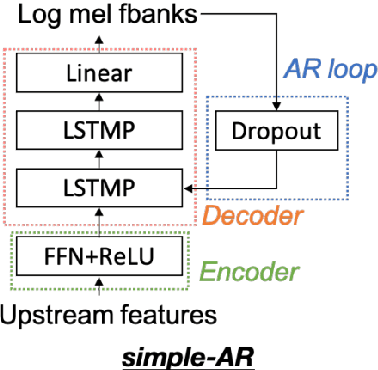
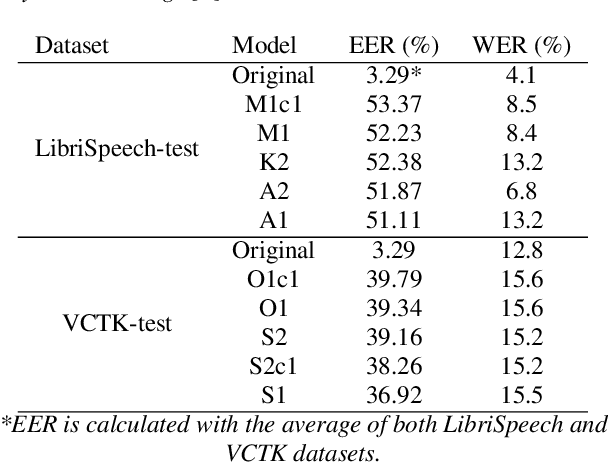

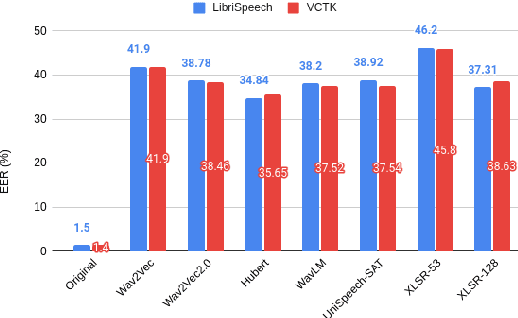
Collecting speech data is an important step in training speech recognition systems and other speech-based machine learning models. However, the issue of privacy protection is an increasing concern that must be addressed. The current study investigates the use of voice conversion as a method for anonymizing voices. In particular, we train several voice conversion models using self-supervised speech representations including Wav2Vec2.0, Hubert and UniSpeech. Converted voices retain a low word error rate within 1% of the original voice. Equal error rate increases from 1.52% to 46.24% on the LibriSpeech test set and from 3.75% to 45.84% on speakers from the VCTK corpus which signifies degraded performance on speaker verification. Lastly, we conduct experiments on dysarthric speech data to show that speech features relevant to articulation, prosody, phonation and phonology can be extracted from anonymized voices for discriminating between healthy and pathological speech.
Automatic Spoken Language Identification using a Time-Delay Neural Network
May 19, 2022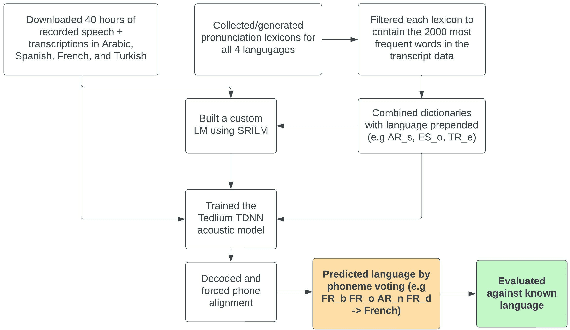



Closed-set spoken language identification is the task of recognizing the language being spoken in a recorded audio clip from a set of known languages. In this study, a language identification system was built and trained to distinguish between Arabic, Spanish, French, and Turkish based on nothing more than recorded speech. A pre-existing multilingual dataset was used to train a series of acoustic models based on the Tedlium TDNN model to perform automatic speech recognition. The system was provided with a custom multilingual language model and a specialized pronunciation lexicon with language names prepended to phones. The trained model was used to generate phone alignments to test data from all four languages, and languages were predicted based on a voting scheme choosing the most common language prepend in an utterance. Accuracy was measured by comparing predicted languages to known languages, and was determined to be very high in identifying Spanish and Arabic, and somewhat lower in identifying Turkish and French.
Multi-layer Attention Mechanism for Speech Keyword Recognition
Jul 10, 2019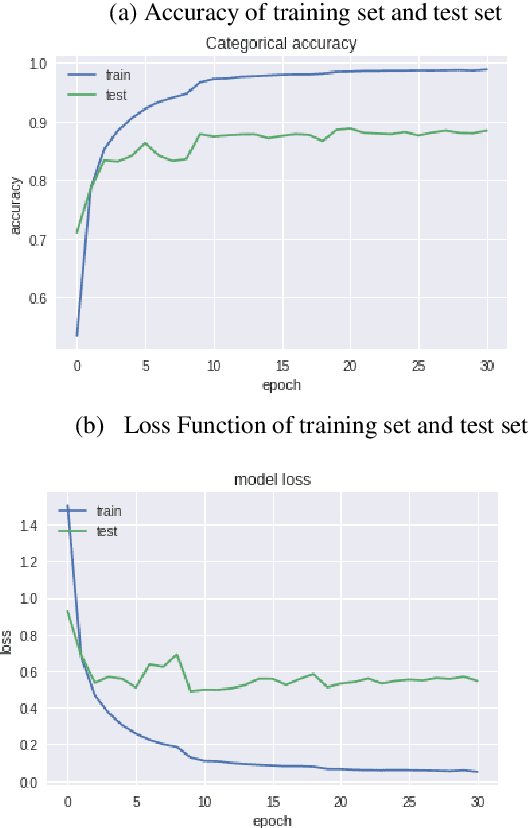
As an important part of speech recognition technology, automatic speech keyword recognition has been intensively studied in recent years. Such technology becomes especially pivotal under situations with limited infrastructures and computational resources, such as voice command recognition in vehicles and robot interaction. At present, the mainstream methods in automatic speech keyword recognition are based on long short-term memory (LSTM) networks with attention mechanism. However, due to inevitable information losses for the LSTM layer caused during feature extraction, the calculated attention weights are biased. In this paper, a novel approach, namely Multi-layer Attention Mechanism, is proposed to handle the inaccurate attention weights problem. The key idea is that, in addition to the conventional attention mechanism, information of layers prior to feature extraction and LSTM are introduced into attention weights calculations. Therefore, the attention weights are more accurate because the overall model can have more precise and focused areas. We conduct a comprehensive comparison and analysis on the keyword spotting performances on convolution neural network, bi-directional LSTM cyclic neural network, and cyclic neural network with the proposed attention mechanism on Google Speech Command datasets V2 datasets. Experimental results indicate favorable results for the proposed method and demonstrate the validity of the proposed method. The proposed multi-layer attention methods can be useful for other researches related to object spotting.
Privacy against Real-Time Speech Emotion Detection via Acoustic Adversarial Evasion of Machine Learning
Nov 17, 2022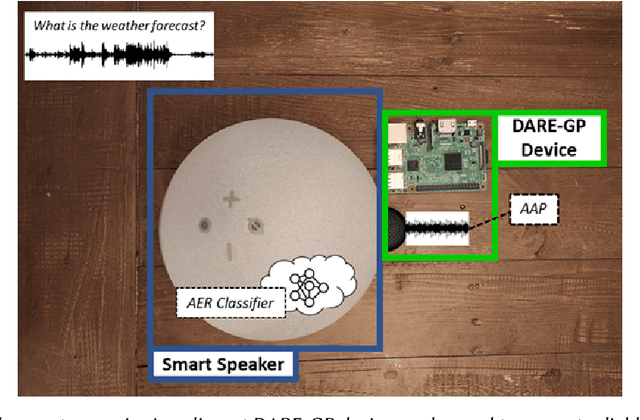
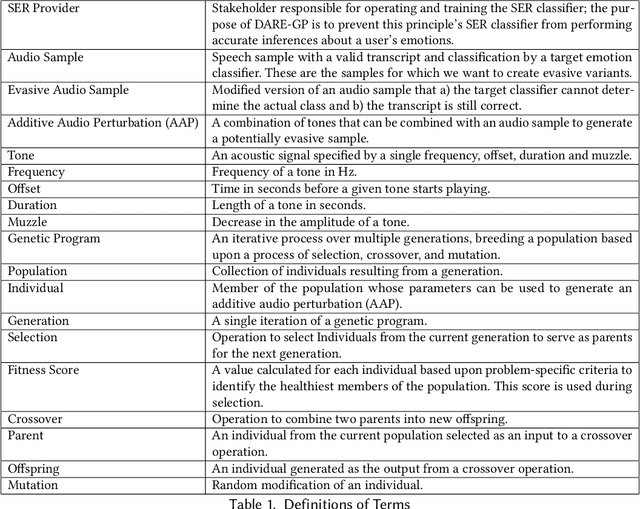
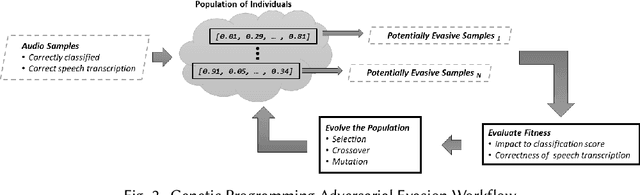

Emotional Surveillance is an emerging area with wide-reaching privacy concerns. These concerns are exacerbated by ubiquitous IoT devices with multiple sensors that can support these surveillance use cases. The work presented here considers one such use case: the use of a speech emotion recognition (SER) classifier tied to a smart speaker. This work demonstrates the ability to evade black-box SER classifiers tied to a smart speaker without compromising the utility of the smart speaker. This privacy concern is considered through the lens of adversarial evasion of machine learning. Our solution, Defeating Acoustic Recognition of Emotion via Genetic Programming (DARE-GP), uses genetic programming to generate non-invasive additive audio perturbations (AAPs). By constraining the evolution of these AAPs, transcription accuracy can be protected while simultaneously degrading SER classifier performance. The additive nature of these AAPs, along with an approach that generates these AAPs for a fixed set of users in an utterance and user location-independent manner, supports real-time, real-world evasion of SER classifiers. DARE-GP's use of spectral features, which underlay the emotional content of speech, allows the transferability of AAPs to previously unseen black-box SER classifiers. Further, DARE-GP outperforms state-of-the-art SER evasion techniques and is robust against defenses employed by a knowledgeable adversary. The evaluations in this work culminate with acoustic evaluations against two off-the-shelf commercial smart speakers, where a single AAP could evade a black box classifier over 70% of the time. The final evaluation deployed AAP playback on a small-form-factor system (raspberry pi) integrated with a wake-word system to evaluate the efficacy of a real-world, real-time deployment where DARE-GP is automatically invoked with the smart speaker's wake word.
Neural Speech Recognizer: Acoustic-to-Word LSTM Model for Large Vocabulary Speech Recognition
Oct 31, 2016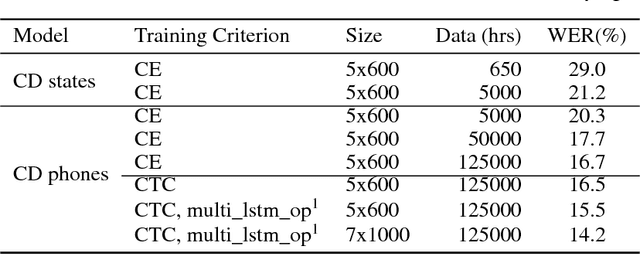
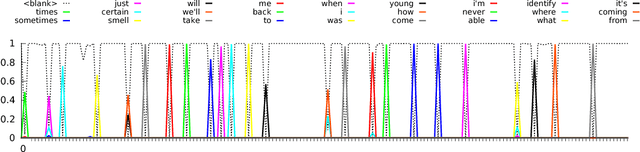
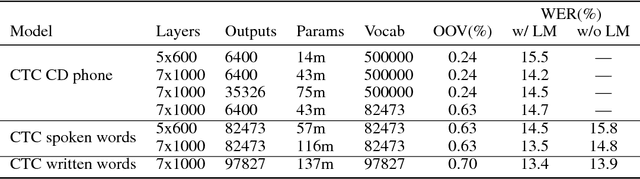

We present results that show it is possible to build a competitive, greatly simplified, large vocabulary continuous speech recognition system with whole words as acoustic units. We model the output vocabulary of about 100,000 words directly using deep bi-directional LSTM RNNs with CTC loss. The model is trained on 125,000 hours of semi-supervised acoustic training data, which enables us to alleviate the data sparsity problem for word models. We show that the CTC word models work very well as an end-to-end all-neural speech recognition model without the use of traditional context-dependent sub-word phone units that require a pronunciation lexicon, and without any language model removing the need to decode. We demonstrate that the CTC word models perform better than a strong, more complex, state-of-the-art baseline with sub-word units.
Improving RNN Transducer Modeling for End-to-End Speech Recognition
Sep 26, 2019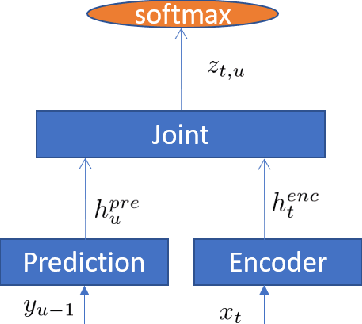
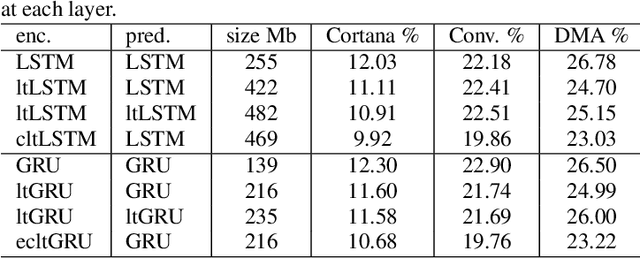
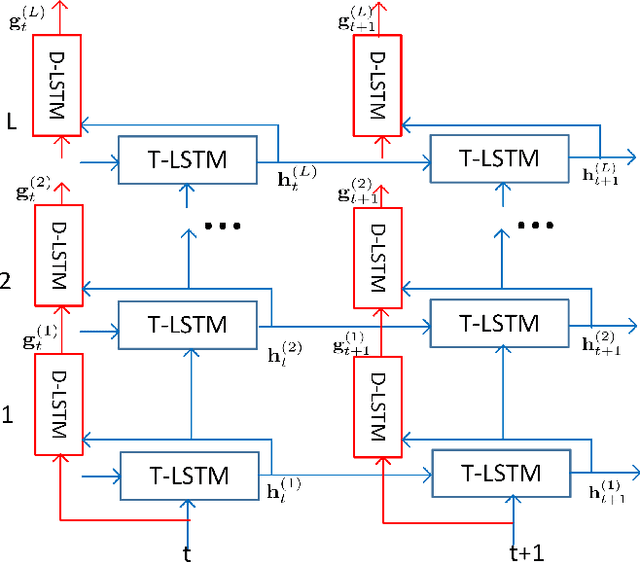
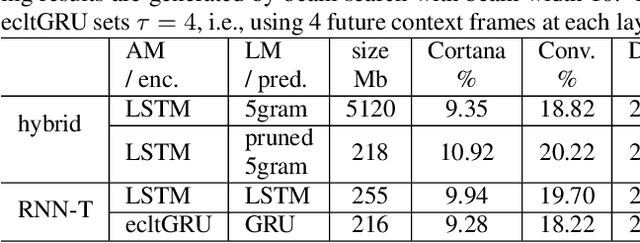
In the last few years, an emerging trend in automatic speech recognition research is the study of end-to-end (E2E) systems. Connectionist Temporal Classification (CTC), Attention Encoder-Decoder (AED), and RNN Transducer (RNN-T) are the most popular three methods. Among these three methods, RNN-T has the advantages to do online streaming which is challenging to AED and it doesn't have CTC's frame-independence assumption. In this paper, we improve the RNN-T training in two aspects. First, we optimize the training algorithm of RNN-T to reduce the memory consumption so that we can have larger training minibatch for faster training speed. Second, we propose better model structures so that we obtain RNN-T models with the very good accuracy but small footprint. Trained with 30 thousand hours anonymized and transcribed Microsoft production data, the best RNN-T model with even smaller model size (216 Megabytes) achieves up-to 11.8% relative word error rate (WER) reduction from the baseline RNN-T model. This best RNN-T model is significantly better than the device hybrid model with similar size by achieving up-to 15.0% relative WER reduction, and obtains similar WERs as the server hybrid model of 5120 Megabytes in size.
Speaker-adaptive Lip Reading with User-dependent Padding
Aug 09, 2022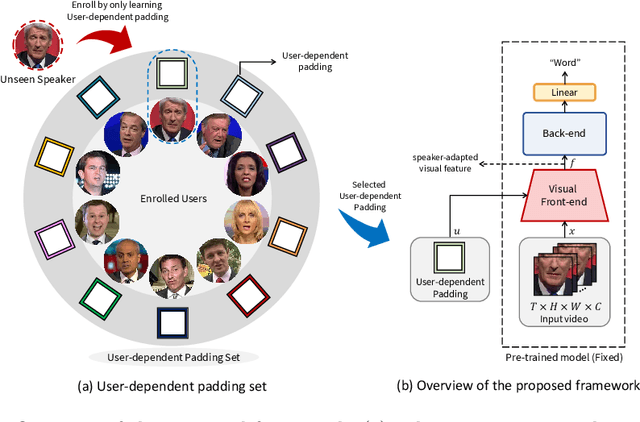
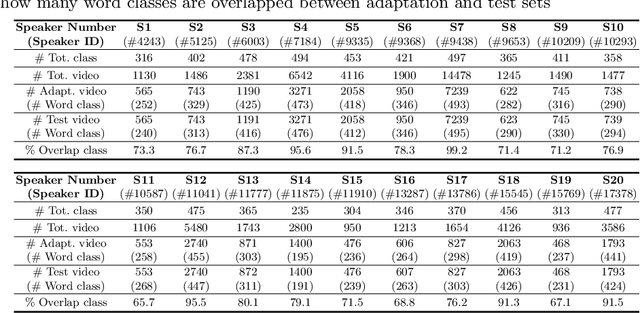
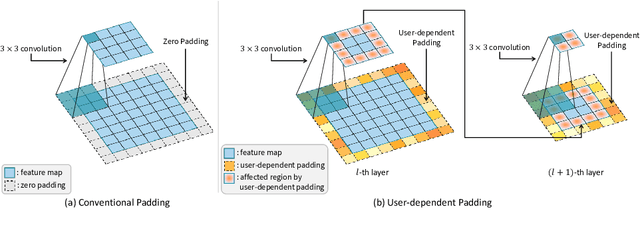

Lip reading aims to predict speech based on lip movements alone. As it focuses on visual information to model the speech, its performance is inherently sensitive to personal lip appearances and movements. This makes the lip reading models show degraded performance when they are applied to unseen speakers due to the mismatch between training and testing conditions. Speaker adaptation technique aims to reduce this mismatch between train and test speakers, thus guiding a trained model to focus on modeling the speech content without being intervened by the speaker variations. In contrast to the efforts made in audio-based speech recognition for decades, the speaker adaptation methods have not well been studied in lip reading. In this paper, to remedy the performance degradation of lip reading model on unseen speakers, we propose a speaker-adaptive lip reading method, namely user-dependent padding. The user-dependent padding is a speaker-specific input that can participate in the visual feature extraction stage of a pre-trained lip reading model. Therefore, the lip appearances and movements information of different speakers can be considered during the visual feature encoding, adaptively for individual speakers. Moreover, the proposed method does not need 1) any additional layers, 2) to modify the learned weights of the pre-trained model, and 3) the speaker label of train data used during pre-train. It can directly adapt to unseen speakers by learning the user-dependent padding only, in a supervised or unsupervised manner. Finally, to alleviate the speaker information insufficiency in public lip reading databases, we label the speaker of a well-known audio-visual database, LRW, and design an unseen-speaker lip reading scenario named LRW-ID.
Bimodal Speech Emotion Recognition Using Pre-Trained Language Models
Nov 29, 2019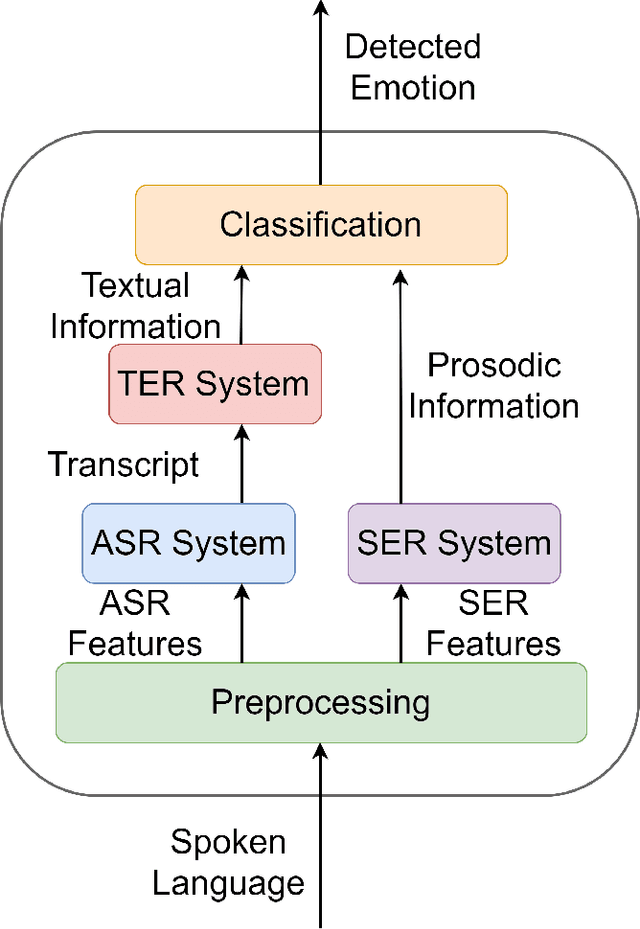
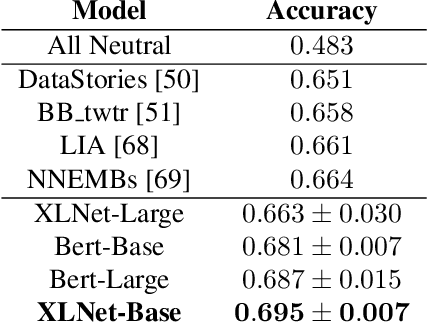

Speech emotion recognition is a challenging task and an important step towards more natural human-machine interaction. We show that pre-trained language models can be fine-tuned for text emotion recognition, achieving an accuracy of 69.5% on Task 4A of SemEval 2017, improving upon the previous state of the art by over 3% absolute. We combine these language models with speech emotion recognition, achieving results of 73.5% accuracy when using provided transcriptions and speech data on a subset of four classes of the IEMOCAP dataset. The use of noise-induced transcriptions and speech data results in an accuracy of 71.4%. For our experiments, we created IEmoNet, a modular and adaptable bimodal framework for speech emotion recognition based on pre-trained language models. Lastly, we discuss the idea of using an emotional classifier as a reward for reinforcement learning as a step towards more successful and convenient human-machine interaction.
Should we hard-code the recurrence concept or learn it instead ? Exploring the Transformer architecture for Audio-Visual Speech Recognition
May 19, 2020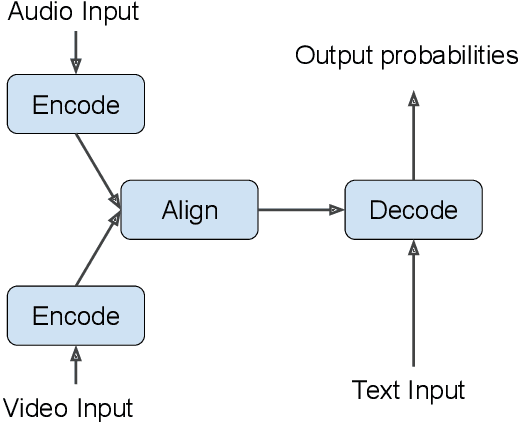
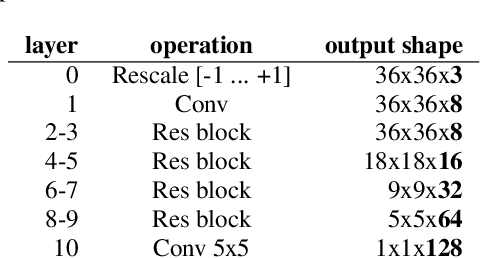
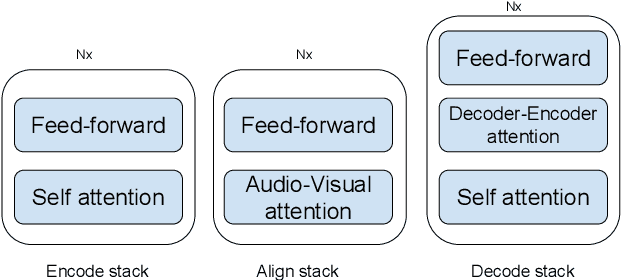
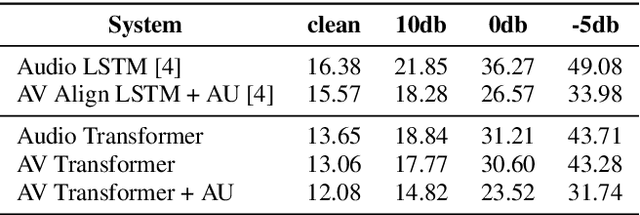
The audio-visual speech fusion strategy AV Align has shown significant performance improvements in audio-visual speech recognition (AVSR) on the challenging LRS2 dataset. Performance improvements range between 7% and 30% depending on the noise level when leveraging the visual modality of speech in addition to the auditory one. This work presents a variant of AV Align where the recurrent Long Short-term Memory (LSTM) computation block is replaced by the more recently proposed Transformer block. We compare the two methods, discussing in greater detail their strengths and weaknesses. We find that Transformers also learn cross-modal monotonic alignments, but suffer from the same visual convergence problems as the LSTM model, calling for a deeper investigation into the dominant modality problem in machine learning.