 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank-Aware Negative Training for Semi-Supervised Text Classification
Jun 13, 2023Semi-supervised text classification-based paradigms (SSTC) typically employ the spirit of self-training. The key idea is to train a deep classifier on limited labeled texts and then iteratively predict the unlabeled texts as their pseudo-labels for further training. However, the performance is largely affected by the accuracy of pseudo-labels, which may not be significant in real-world scenarios. This paper presents a Rank-aware Negative Training (RNT) framework to address SSTC in learning with noisy label manner. To alleviate the noisy information, we adapt a reasoning with uncertainty-based approach to rank the unlabeled texts based on the evidential support received from the labeled texts. Moreover, we propose the use of negative training to train RNT based on the concept that ``the input instance does not belong to the complementary label''. A complementary label is randomly selected from all labels except the label on-target. Intuitively, the probability of a true label serving as a complementary label is low and thus provides less noisy information during the training, resulting in better performance on the test data. Finally, we evaluate the proposed solution on various text classification benchmark datasets. Our extensive experiments show that it consistently overcomes the state-of-the-art alternatives in most scenarios and achieves competitive performance in the others. The code of RNT is publicly available at:https://github.com/amurtadha/RNT.
Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition
Aug 05, 2022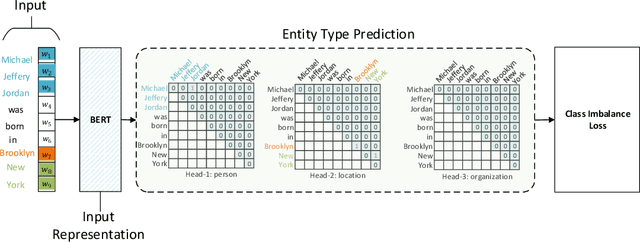
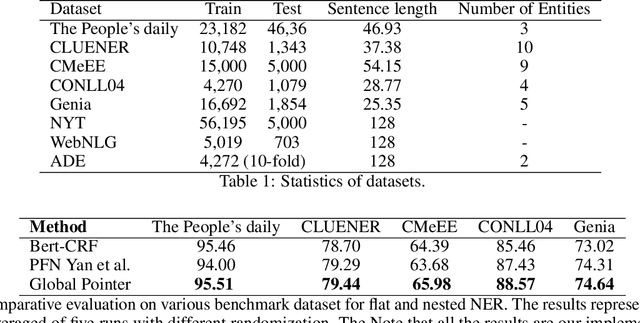
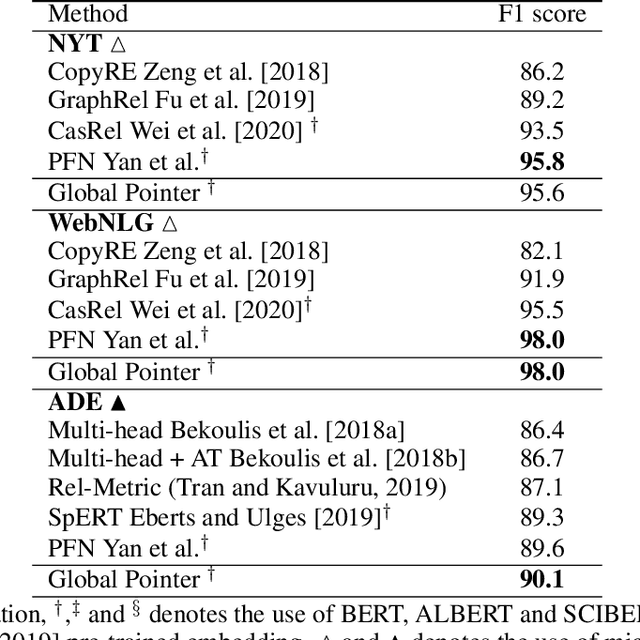

Named entity recognition (NER) task aims at identifying entities from a piece of text that belong to predefined semantic types such as person, location, organization, etc. The state-of-the-art solutions for flat entities NER commonly suffer from capturing the fine-grained semantic information in underlying texts. The existing span-based approaches overcome this limitation, but the computation time is still a concern. In this work, we propose a novel span-based NER framework, namely Global Pointer (GP), that leverages the relative positions through a multiplicative attention mechanism. The ultimate goal is to enable a global view that considers the beginning and the end positions to predict the entity. To this end, we design two modules to identify the head and the tail of a given entity to enable the inconsistency between the training and inference processes. Moreover, we introduce a novel classification loss function to address the imbalance label problem. In terms of parameters, we introduce a simple but effective approximate method to reduce the training parameters. We extensively evaluate GP on various benchmark datasets. Our extensive experiments demonstrate that GP can outperform the existing solution. Moreover, the experimental results show the efficacy of the introduced loss function compared to softmax and entropy alternatives.
ZLPR: A Novel Loss for Multi-label Classification
Aug 05, 2022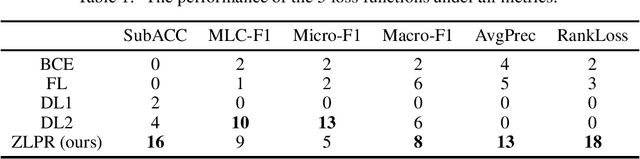
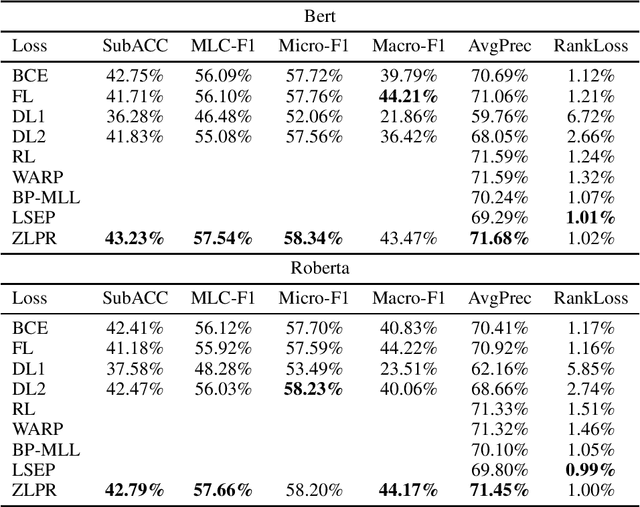
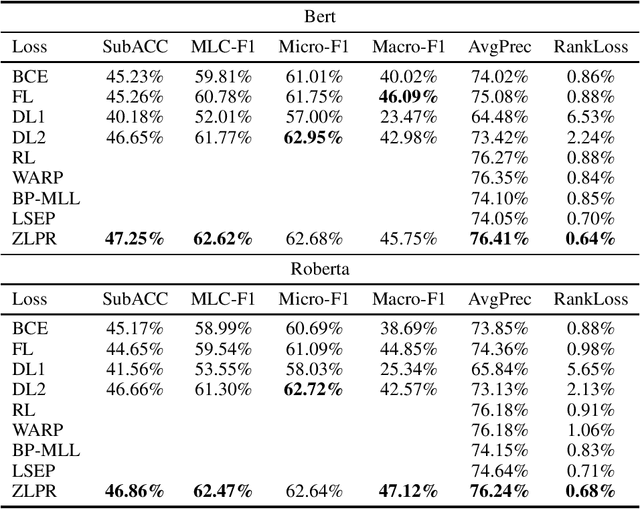
In the era of deep learning, loss functions determine the range of tasks available to models and algorithms. To support the application of deep learning in multi-label classification (MLC) tasks, we propose the ZLPR (zero-bounded log-sum-exp \& pairwise rank-based) loss in this paper. Compared to other rank-based losses for MLC, ZLPR can handel problems that the number of target labels is uncertain, which, in this point of view, makes it equally capable with the other two strategies often used in MLC, namely the binary relevance (BR) and the label powerset (LP). Additionally, ZLPR takes the corelation between labels into consideration, which makes it more comprehensive than the BR methods. In terms of computational complexity, ZLPR can compete with the BR methods because its prediction is also label-independent, which makes it take less time and memory than the LP methods. Our experiments demonstrate the effectiveness of ZLPR on multiple benchmark datasets and multiple evaluation metrics. Moreover, we propose the soft version and the corresponding KL-divergency calculation method of ZLPR, which makes it possible to apply some regularization tricks such as label smoothing to enhance the generalization of models.
BERT-ASC: Auxiliary-Sentence Construction for Implicit Aspect Learning in Sentiment Analysis
Mar 22, 2022
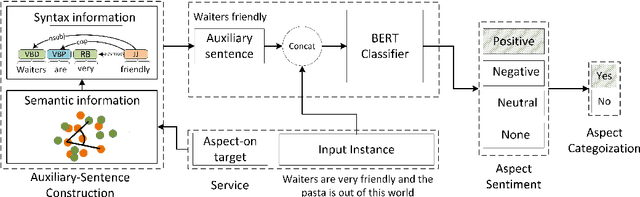
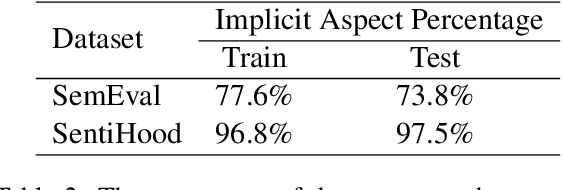

Aspect-based sentiment analysis (ABSA) task aims to associate a piece of text with a set of aspects and meanwhile infer their respective sentimental polarities. Up to now, the state-of-the-art approaches are built upon fine-tuning of various pre-trained language models. They commonly aim to learn the aspect-specific representation in the corpus. Unfortunately, the aspect is often expressed implicitly through a set of representatives and thus renders implicit mapping process unattainable unless sufficient labeled examples. In this paper, we propose to jointly address aspect categorization and aspect-based sentiment subtasks in a unified framework. Specifically, we first introduce a simple but effective mechanism that collaborates the semantic and syntactic information to construct auxiliary-sentences for the implicit aspect. Then, we encourage BERT to learn the aspect-specific representation in response to the automatically constructed auxiliary-sentence instead of the aspect itself. Finally, we empirically evaluate the performance of the proposed solution by a comparative study on real benchmark datasets for both ABSA and Targeted-ABSA tasks. Our extensive experiments show that it consistently achieves state-of-the-art performance in terms of aspect categorization and aspect-based sentiment across all datasets and the improvement margins are considerable.
Sparse-softmax: A Simpler and Faster Alternative Softmax Transformation
Dec 23, 2021
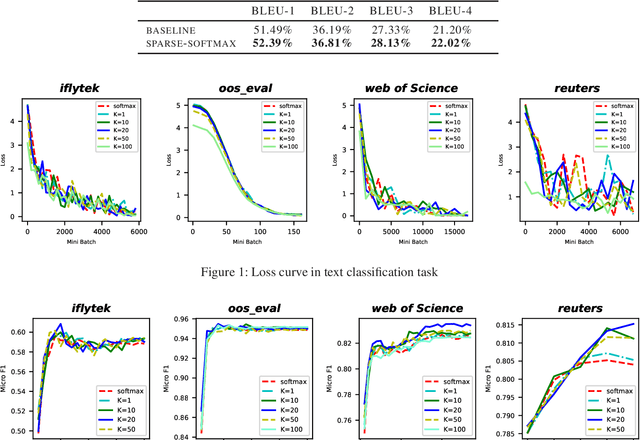
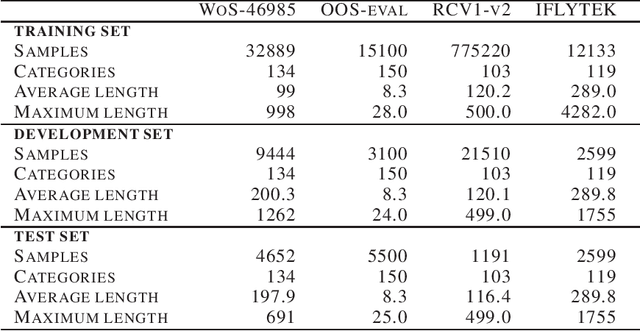
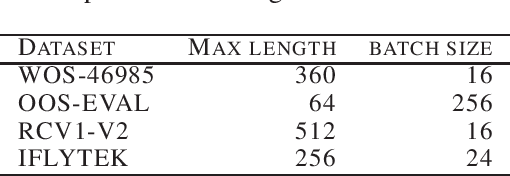
The softmax function is widely used in artificial neural networks for the multiclass classification problems, where the softmax transformation enforces the output to be positive and sum to one, and the corresponding loss function allows to use maximum likelihood principle to optimize the model. However, softmax leaves a large margin for loss function to conduct optimizing operation when it comes to high-dimensional classification, which results in low-performance to some extent. In this paper, we provide an empirical study on a simple and concise softmax variant, namely sparse-softmax, to alleviate the problem that occurred in traditional softmax in terms of high-dimensional classification problems. We evaluate our approach in several interdisciplinary tasks, the experimental results show that sparse-softmax is simpler, faster, and produces better results than the baseline models.
BioCopy: A Plug-And-Play Span Copy Mechanism in Seq2Seq Models
Sep 26, 2021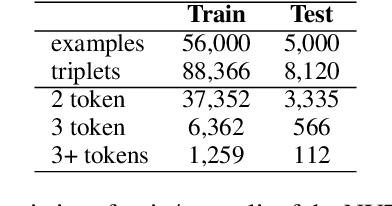
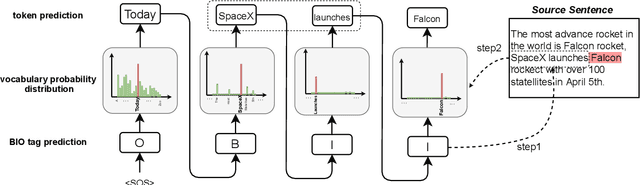
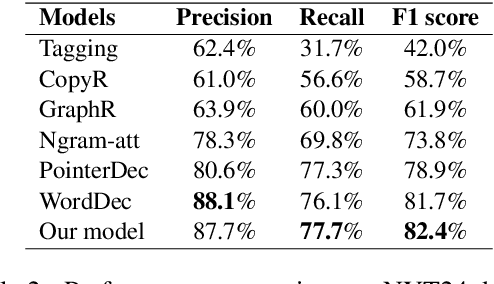
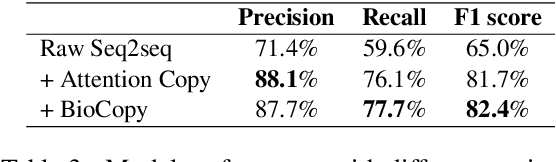
Copy mechanisms explicitly obtain unchanged tokens from the source (input) sequence to generate the target (output) sequence under the neural seq2seq framework. However, most of the existing copy mechanisms only consider single word copying from the source sentences, which results in losing essential tokens while copying long spans. In this work, we propose a plug-and-play architecture, namely BioCopy, to alleviate the problem aforementioned. Specifically, in the training stage, we construct a BIO tag for each token and train the original model with BIO tags jointly. In the inference stage, the model will firstly predict the BIO tag at each time step, then conduct different mask strategies based on the predicted BIO label to diminish the scope of the probability distributions over the vocabulary list. Experimental results on two separate generative tasks show that they all outperform the baseline models by adding our BioCopy to the original model structure.
Efficient Speech Emotion Recognition Using Multi-Scale CNN and Attention
Jun 08, 2021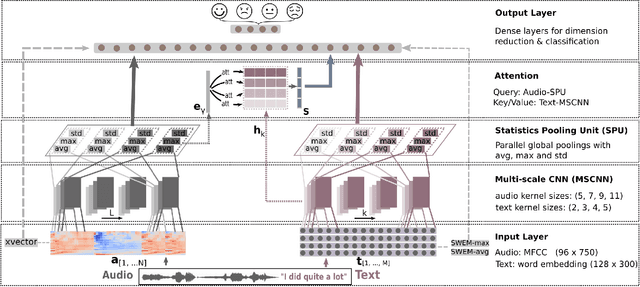
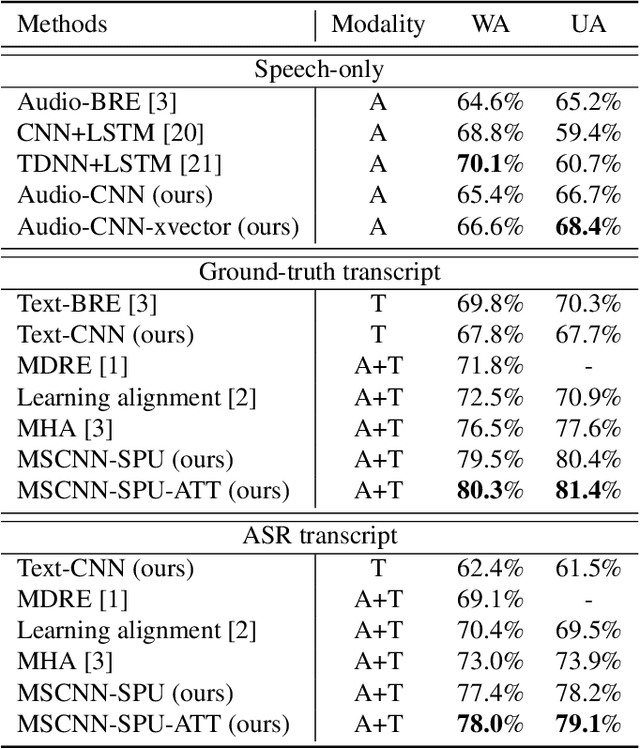

Emotion recognition from speech is a challenging task. Re-cent advances in deep learning have led bi-directional recur-rent neural network (Bi-RNN) and attention mechanism as astandard method for speech emotion recognition, extractingand attending multi-modal features - audio and text, and thenfusing them for downstream emotion classification tasks. Inthis paper, we propose a simple yet efficient neural networkarchitecture to exploit both acoustic and lexical informationfrom speech. The proposed framework using multi-scale con-volutional layers (MSCNN) to obtain both audio and text hid-den representations. Then, a statistical pooling unit (SPU)is used to further extract the features in each modality. Be-sides, an attention module can be built on top of the MSCNN-SPU (audio) and MSCNN (text) to further improve the perfor-mance. Extensive experiments show that the proposed modeloutperforms previous state-of-the-art methods on IEMOCAPdataset with four emotion categories (i.e., angry, happy, sadand neutral) in both weighted accuracy (WA) and unweightedaccuracy (UA), with an improvement of 5.0% and 5.2% respectively under the ASR setting.
* First two authors contributed equally.Accepted by ICASSP 2021
RoFormer: Enhanced Transformer with Rotary Position Embedding
Apr 20, 2021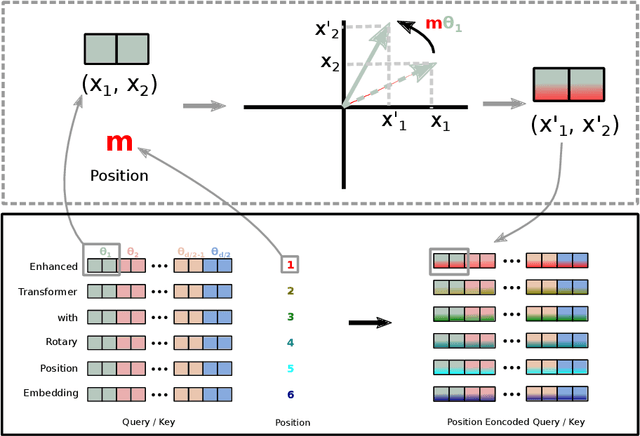
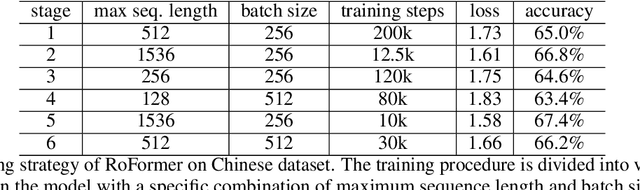
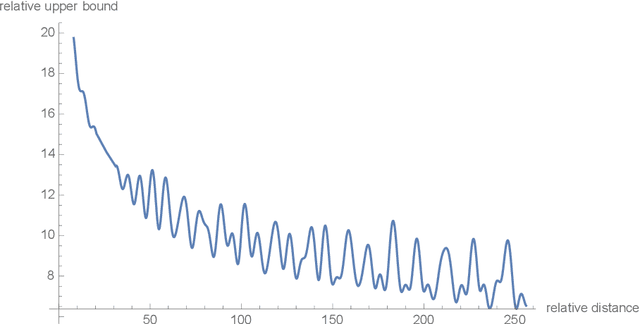
Position encoding in transformer architecture provides supervision for dependency modeling between elements at different positions in the sequence. We investigate various methods to encode positional information in transformer-based language models and propose a novel implementation named Rotary Position Embedding(RoPE). The proposed RoPE encodes absolute positional information with rotation matrix and naturally incorporates explicit relative position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and capability of equipping the linear self-attention with relative position encoding. As a result, the enhanced transformer with rotary position embedding, or RoFormer, achieves superior performance in tasks with long texts. We release the theoretical analysis along with some preliminary experiment results on Chinese data. The undergoing experiment for English benchmark will soon be updated.