 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Speech Representations Preserve Speech Characteristics while Anonymizing Voices
Paper and Code
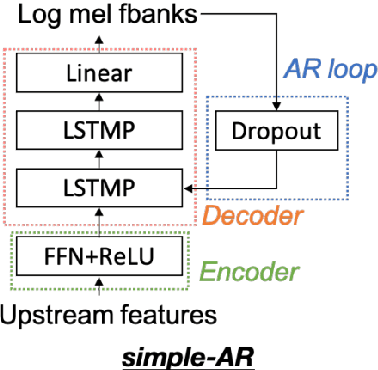
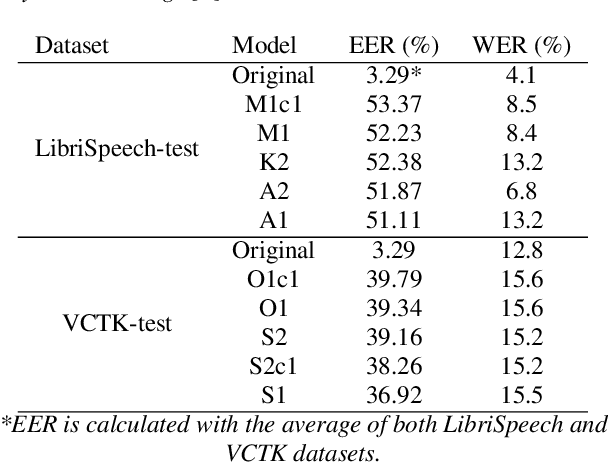

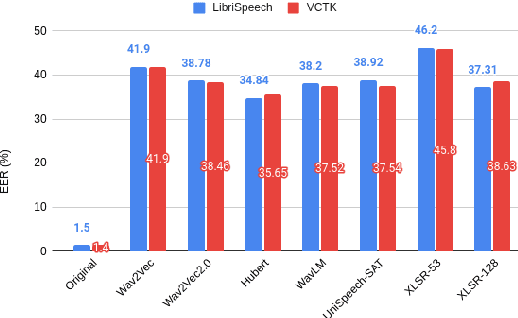
Collecting speech data is an important step in training speech recognition systems and other speech-based machine learning models. However, the issue of privacy protection is an increasing concern that must be addressed. The current study investigates the use of voice conversion as a method for anonymizing voices. In particular, we train several voice conversion models using self-supervised speech representations including Wav2Vec2.0, Hubert and UniSpeech. Converted voices retain a low word error rate within 1% of the original voice. Equal error rate increases from 1.52% to 46.24% on the LibriSpeech test set and from 3.75% to 45.84% on speakers from the VCTK corpus which signifies degraded performance on speaker verification. Lastly, we conduct experiments on dysarthric speech data to show that speech features relevant to articulation, prosody, phonation and phonology can be extracted from anonymized voices for discriminating between healthy and pathological speech.