 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
End-to-End Rich Transcription-Style Automatic Speech Recognition with Semi-Supervised Learning
Jul 07, 2021
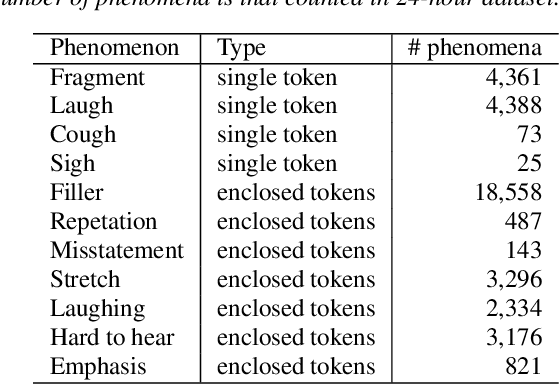
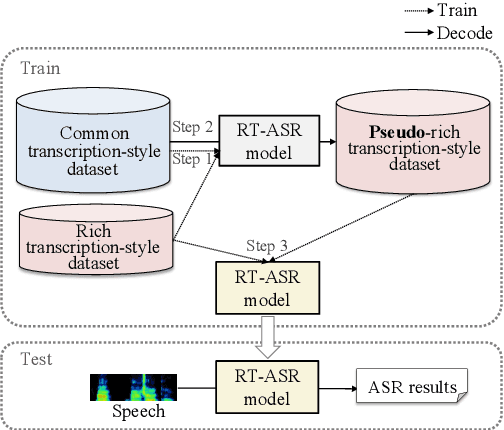
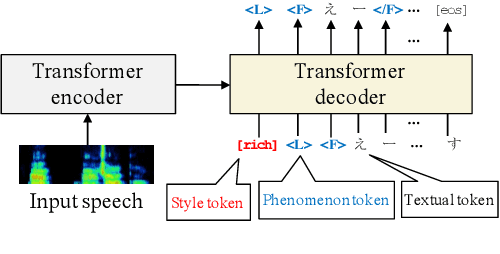
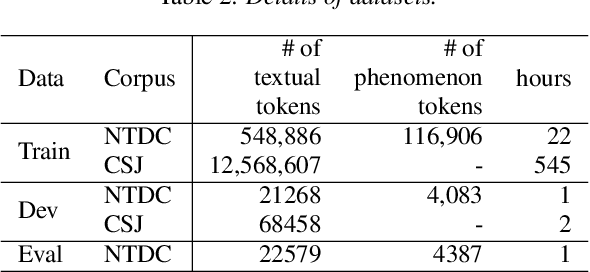
We propose a semi-supervised learning method for building end-to-end rich transcription-style automatic speech recognition (RT-ASR) systems from small-scale rich transcription-style and large-scale common transcription-style datasets. In spontaneous speech tasks, various speech phenomena such as fillers, word fragments, laughter and coughs, etc. are often included. While common transcriptions do not give special awareness to these phenomena, rich transcriptions explicitly convert them into special phenomenon tokens as well as textual tokens. In previous studies, the textual and phenomenon tokens were simultaneously estimated in an end-to-end manner. However, it is difficult to build accurate RT-ASR systems because large-scale rich transcription-style datasets are often unavailable. To solve this problem, our training method uses a limited rich transcription-style dataset and common transcription-style dataset simultaneously. The Key process in our semi-supervised learning is to convert the common transcription-style dataset into a pseudo-rich transcription-style dataset. To this end, we introduce style tokens which control phenomenon tokens are generated or not into transformer-based autoregressive modeling. We use this modeling for generating the pseudo-rich transcription-style datasets and for building RT-ASR system from the pseudo and original datasets. Our experiments on spontaneous ASR tasks showed the effectiveness of the proposed method.
Comparison of Soft and Hard Target RNN-T Distillation for Large-scale ASR
Oct 11, 2022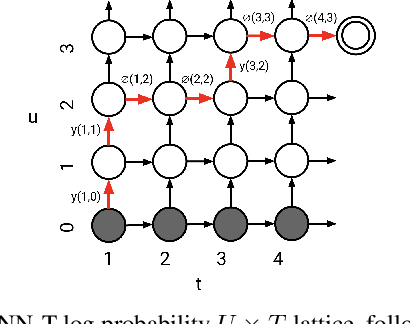
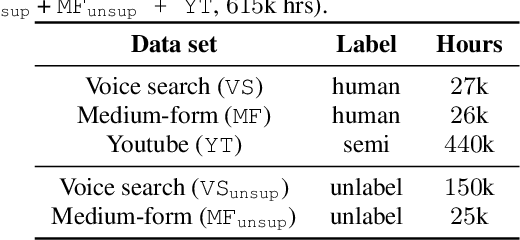

Knowledge distillation is an effective machine learning technique to transfer knowledge from a teacher model to a smaller student model, especially with unlabeled data. In this paper, we focus on knowledge distillation for the RNN-T model, which is widely used in state-of-the-art (SoTA) automatic speech recognition (ASR). Specifically, we compared using soft and hard target distillation to train large-scaleRNN-T models on the LibriSpeech/LibriLight public dataset (60k hours) and our in-house data (600k hours). We found that hard tar-gets are more effective when the teacher and student have different architecture, such as large teacher and small streaming student. On the other hand, soft target distillation works better in self-training scenario like iterative large teacher training. For a large model with0.6B weights, we achieve a new SoTA word error rate (WER) on LibriSpeech (8% relative improvement on dev-other) using Noisy Student Training with soft target distillation. It also allows our production teacher to adapt new data domain continuously.
Transformer-based Online CTC/attention End-to-End Speech Recognition Architecture
Jan 15, 2020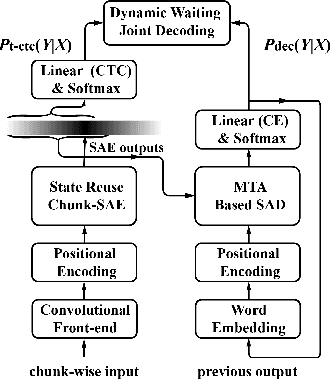

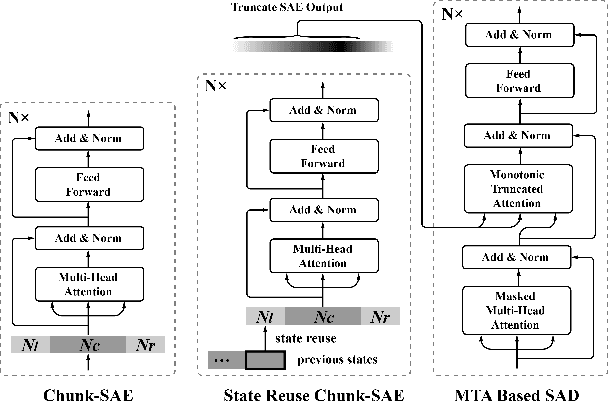
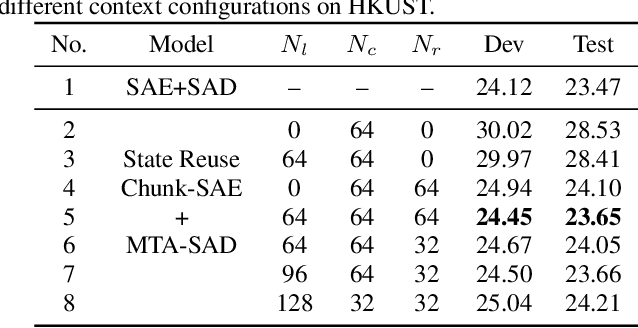
Recently, Transformer has gained success in automatic speech recognition (ASR) field. However, it is challenging to deploy a Transformer-based end-to-end (E2E) model for online speech recognition. In this paper, we propose the Transformer-based online CTC/attention E2E ASR architecture, which contains the chunk self-attention encoder (chunk-SAE) and the monotonic truncated attention (MTA) based self-attention decoder (SAD). Firstly, the chunk-SAE splits the speech into isolated chunks. To reduce the computational cost and improve the performance, we propose the state reuse chunk-SAE. Sencondly, the MTA based SAD truncates the speech features monotonically and performs attention on the truncated features. To support the online recognition, we integrate the state reuse chunk-SAE and the MTA based SAD into online CTC/attention architecture. We evaluate the proposed online models on the HKUST Mandarin ASR benchmark and achieve a 23.66% character error rate (CER) with a 320 ms latency. Our online model yields as little as $0.19\%$ absolute CER degradation compared with the offline baseline, and achieves significant improvement over our prior work on Long Short-Term Memory (LSTM) based online E2E models.
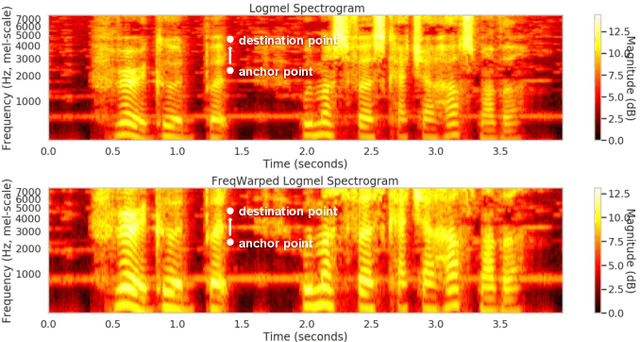
Spectral Modification Based Data Augmentation For Improving End-to-End ASR For Children's Speech
Mar 13, 2022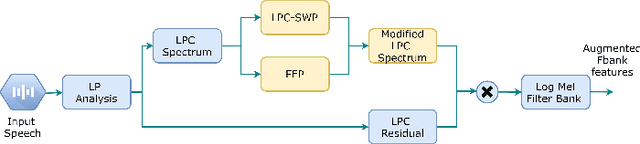
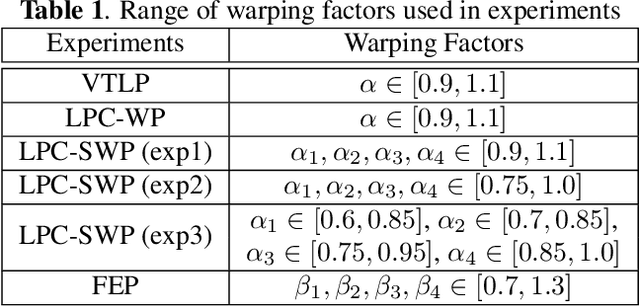
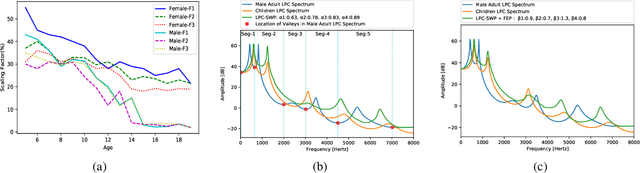
Training a robust Automatic Speech Recognition (ASR) system for children's speech recognition is a challenging task due to inherent differences in acoustic attributes of adult and child speech and scarcity of publicly available children's speech dataset. In this paper, a novel segmental spectrum warping and perturbations in formant energy are introduced, to generate a children-like speech spectrum from that of an adult's speech spectrum. Then, this modified adult spectrum is used as augmented data to improve end-to-end ASR systems for children's speech recognition. The proposed data augmentation methods give 6.5% and 6.1% relative reduction in WER on children dev and test sets respectively, compared to the vocal tract length perturbation (VTLP) baseline system trained on Librispeech 100 hours adult speech dataset. When children's speech data is added in training with Librispeech set, it gives a 3.7 % and 5.1% relative reduction in WER, compared to the VTLP baseline system.
Data Augmentation Methods for End-to-end Speech Recognition on Distant-Talk Scenarios
Jun 07, 2021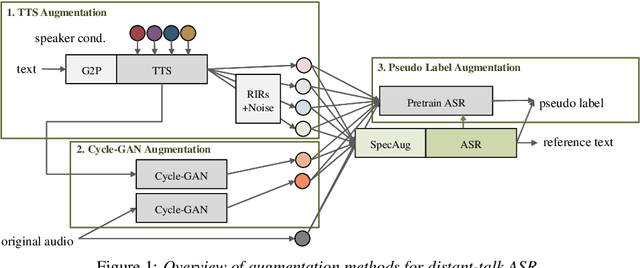
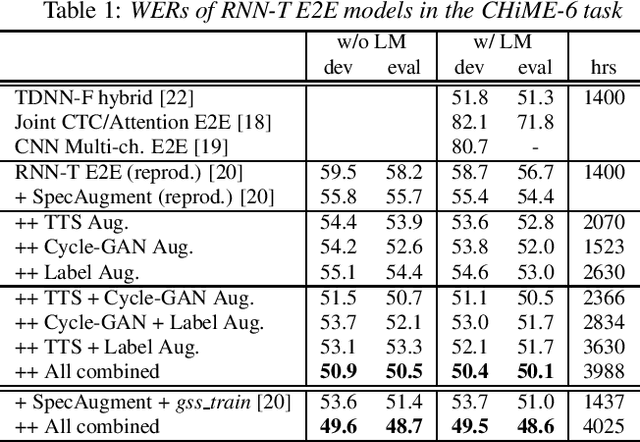
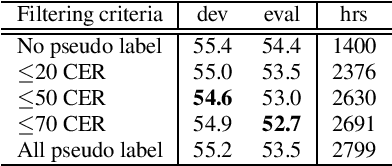
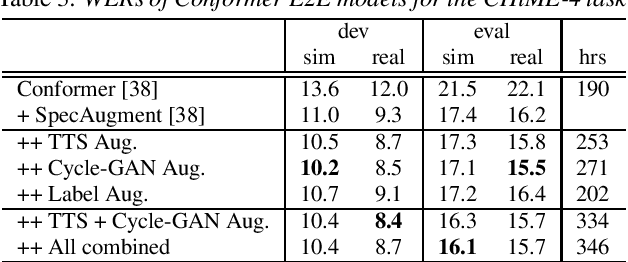
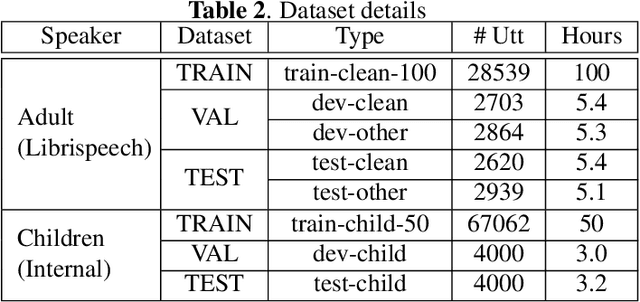
Although end-to-end automatic speech recognition (E2E ASR) has achieved great performance in tasks that have numerous paired data, it is still challenging to make E2E ASR robust against noisy and low-resource conditions. In this study, we investigated data augmentation methods for E2E ASR in distant-talk scenarios. E2E ASR models are trained on the series of CHiME challenge datasets, which are suitable tasks for studying robustness against noisy and spontaneous speech. We propose to use three augmentation methods and thier combinations: 1) data augmentation using text-to-speech (TTS) data, 2) cycle-consistent generative adversarial network (Cycle-GAN) augmentation trained to map two different audio characteristics, the one of clean speech and of noisy recordings, to match the testing condition, and 3) pseudo-label augmentation provided by the pretrained ASR module for smoothing label distributions. Experimental results using the CHiME-6/CHiME-4 datasets show that each augmentation method individually improves the accuracy on top of the conventional SpecAugment; further improvements are obtained by combining these approaches. We achieved 4.3\% word error rate (WER) reduction, which was more significant than that of the SpecAugment, when we combine all three augmentations for the CHiME-6 task.
Delay-penalized transducer for low-latency streaming ASR
Oct 31, 2022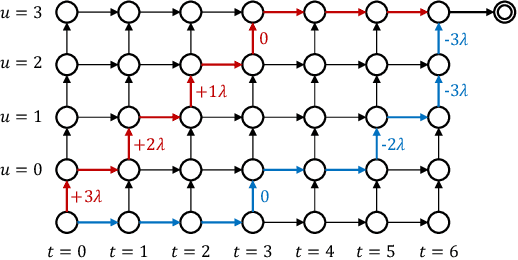
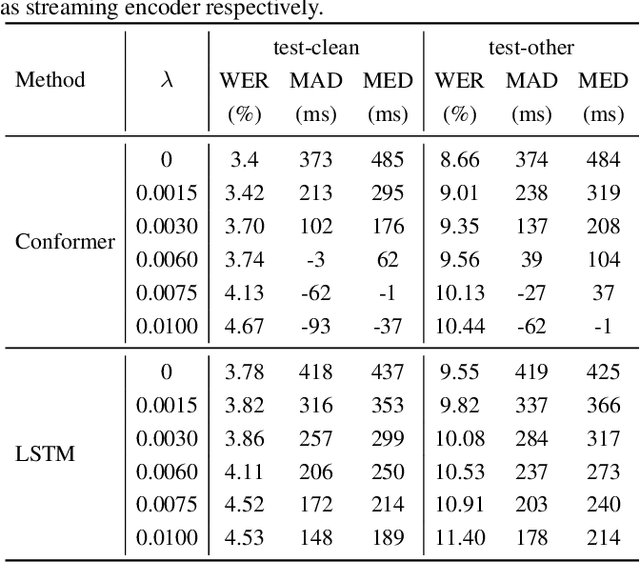
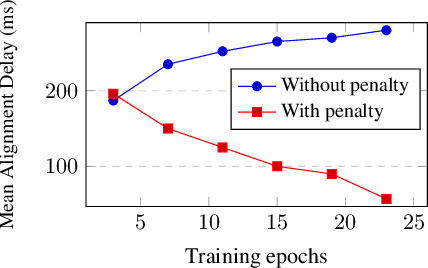
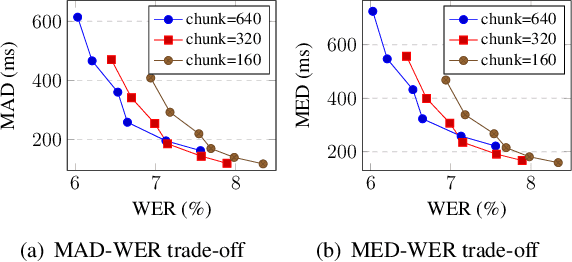
In streaming automatic speech recognition (ASR), it is desirable to reduce latency as much as possible while having minimum impact on recognition accuracy. Although a few existing methods are able to achieve this goal, they are difficult to implement due to their dependency on external alignments. In this paper, we propose a simple way to penalize symbol delay in transducer model, so that we can balance the trade-off between symbol delay and accuracy for streaming models without external alignments. Specifically, our method adds a small constant times (T/2 - t), where T is the number of frames and t is the current frame, to all the non-blank log-probabilities (after normalization) that are fed into the two dimensional transducer recursion. For both streaming Conformer models and unidirectional long short-term memory (LSTM) models, experimental results show that it can significantly reduce the symbol delay with an acceptable performance degradation. Our method achieves similar delay-accuracy trade-off to the previously published FastEmit, but we believe our method is preferable because it has a better justification: it is equivalent to penalizing the average symbol delay. Our work is open-sourced and publicly available (https://github.com/k2-fsa/k2).
Unsupervised Cross-lingual Representation Learning for Speech Recognition
Jun 24, 2020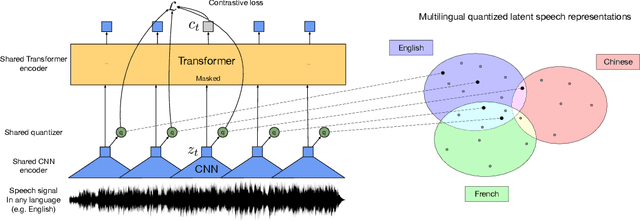
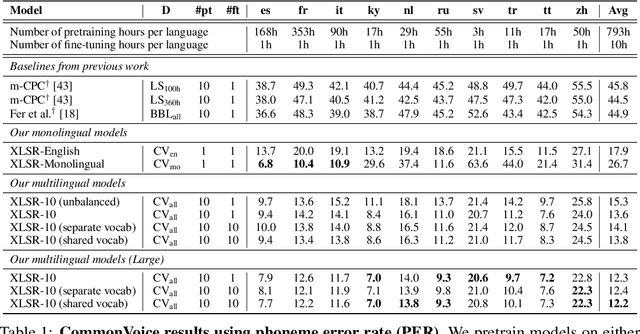
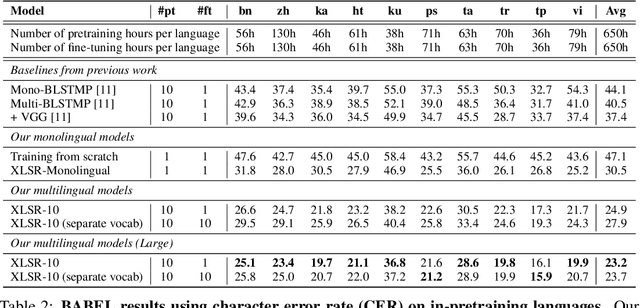
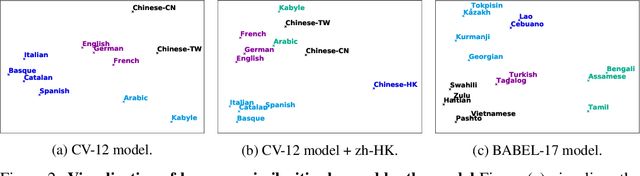
This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw waveform of speech in multiple languages. We build on a concurrently introduced self-supervised model which is trained by solving a contrastive task over masked latent speech representations and jointly learns a quantization of the latents shared across languages. The resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to the strongest comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong individual models. Analysis shows that the latent discrete speech representations are shared across languages with increased sharing for related languages.
AHD ConvNet for Speech Emotion Classification
Jun 21, 2022
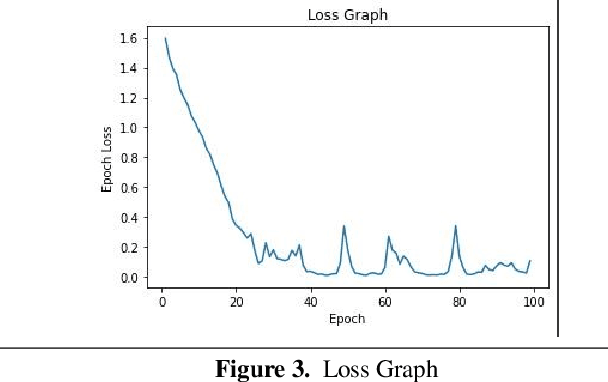
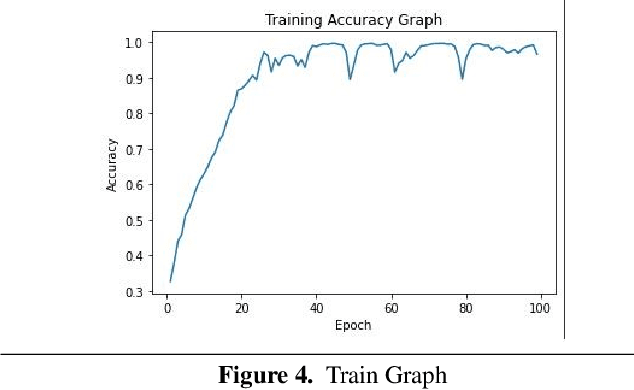
Accomplishments in the field of artificial intelligence are utilized in the advancement of computing and making of intelligent machines for facilitating mankind and improving user experience. Emotions are rudimentary for people, affecting thinking and ordinary exercises like correspondence, learning and direction. Speech emotion recognition is domain of interest in this regard and in this work, we propose a novel mel spectrogram learning approach in which our model uses the datapoints to learn emotions from the given wav form voice notes in the popular CREMA-D dataset. Our model uses log mel-spectrogram as feature with number of mels = 64. It took less training time compared to other approaches used to address the problem of emotion speech recognition.
Robust Unstructured Knowledge Access in Conversational Dialogue with ASR Errors
Nov 08, 2022
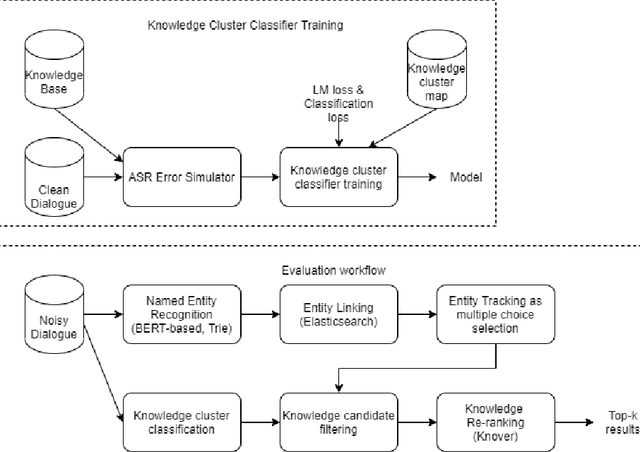

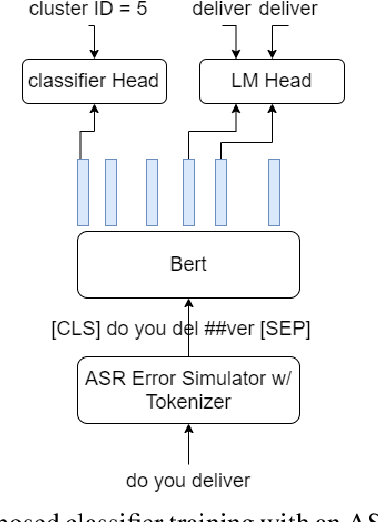
Performance of spoken language understanding (SLU) can be degraded with automatic speech recognition (ASR) errors. We propose a novel approach to improve SLU robustness by randomly corrupting clean training text with an ASR error simulator, followed by self-correcting the errors and minimizing the target classification loss in a joint manner. In the proposed error simulator, we leverage confusion networks generated from an ASR decoder without human transcriptions to generate a variety of error patterns for model training. We evaluate our approach on the DSTC10 challenge targeted for knowledge-grounded task-oriented conversational dialogues with ASR errors. Experimental results show the effectiveness of our proposed approach, boosting the knowledge-seeking turn detection (KTD) F1 significantly from 0.9433 to 0.9904. Knowledge cluster classification is boosted from 0.7924 to 0.9333 in Recall@1. After knowledge document re-ranking, our approach shows significant improvement in all knowledge selection metrics, from 0.7358 to 0.7806 in Recall@1, from 0.8301 to 0.9333 in Recall@5, and from 0.7798 to 0.8460 in MRR@5 on the test set. In the recent DSTC10 evaluation, our approach demonstrates significant improvement in knowledge selection, boosting Recall@1 from 0.495 to 0.7144 compared to the official baseline. Our source code is released in GitHub https://github.com/yctam/dstc10_track2_task2.git.
* 7 pages, 2 figures. Accepted at ICASSP 2022
PARP: Prune, Adjust and Re-Prune for Self-Supervised Speech Recognition
Jun 10, 2021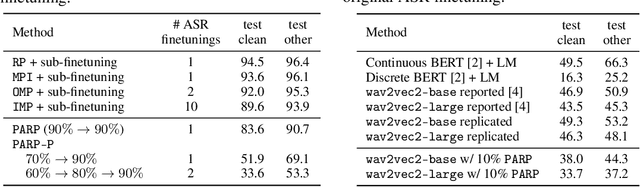
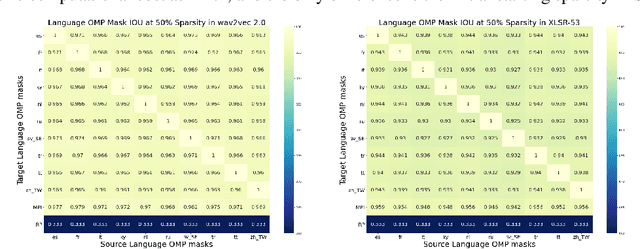
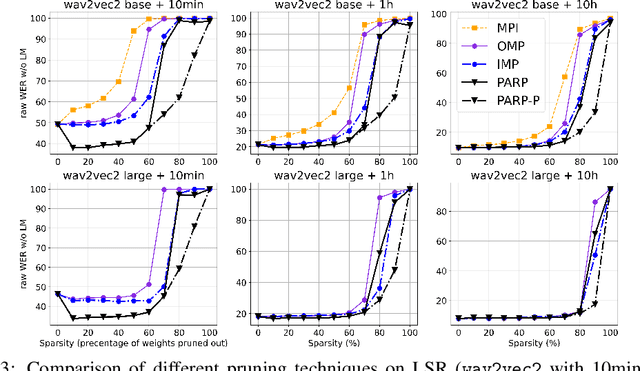
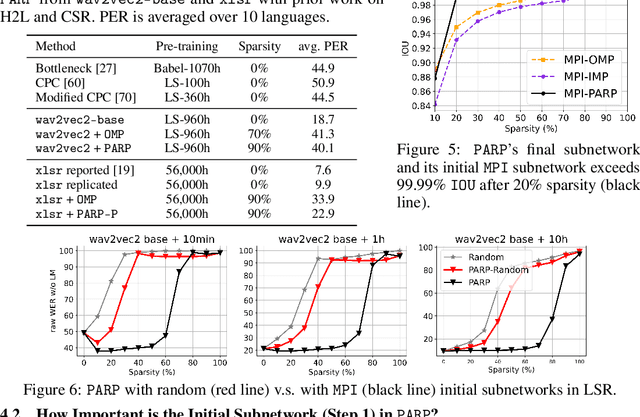
Recent work on speech self-supervised learning (speech SSL) demonstrated the benefits of scale in learning rich and transferable representations for Automatic Speech Recognition (ASR) with limited parallel data. It is then natural to investigate the existence of sparse and transferrable subnetworks in pre-trained speech SSL models that can achieve even better low-resource ASR performance. However, directly applying widely adopted pruning methods such as the Lottery Ticket Hypothesis (LTH) is suboptimal in the computational cost needed. Moreover, contrary to what LTH predicts, the discovered subnetworks yield minimal performance gain compared to the original dense network. In this work, we propose Prune-Adjust- Re-Prune (PARP), which discovers and finetunes subnetworks for much better ASR performance, while only requiring a single downstream finetuning run. PARP is inspired by our surprising observation that subnetworks pruned for pre-training tasks only needed to be slightly adjusted to achieve a sizeable performance boost in downstream ASR tasks. Extensive experiments on low-resource English and multi-lingual ASR show (1) sparse subnetworks exist in pre-trained speech SSL, and (2) the computational advantage and performance gain of PARP over baseline pruning methods. On the 10min Librispeech split without LM decoding, PARP discovers subnetworks from wav2vec 2.0 with an absolute 10.9%/12.6% WER decrease compared to the full model. We demonstrate PARP mitigates performance degradation in cross-lingual mask transfer, and investigate the possibility of discovering a single subnetwork for 10 spoken languages in one run.