 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Cross-lingual Representation Learning for Speech Recognition
Paper and Code
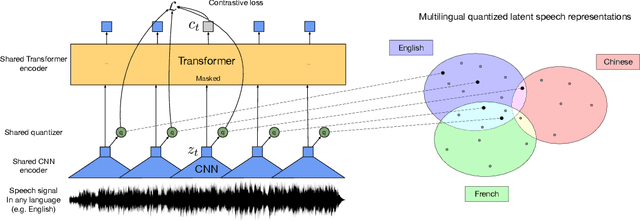
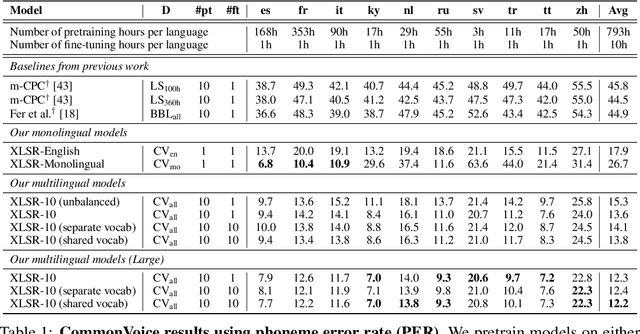
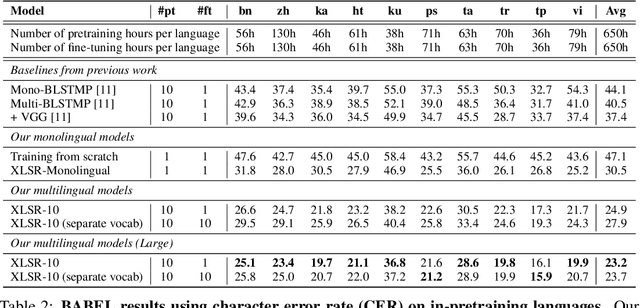
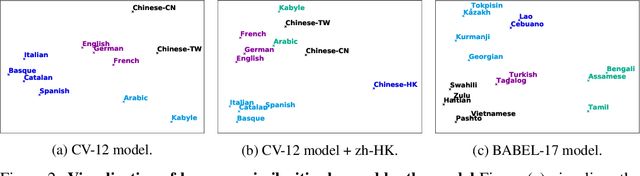
This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw waveform of speech in multiple languages. We build on a concurrently introduced self-supervised model which is trained by solving a contrastive task over masked latent speech representations and jointly learns a quantization of the latents shared across languages. The resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to the strongest comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong individual models. Analysis shows that the latent discrete speech representations are shared across languages with increased sharing for related languages.