 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Massively Multilingual Shallow Fusion with Large Language Models
Feb 17, 2023
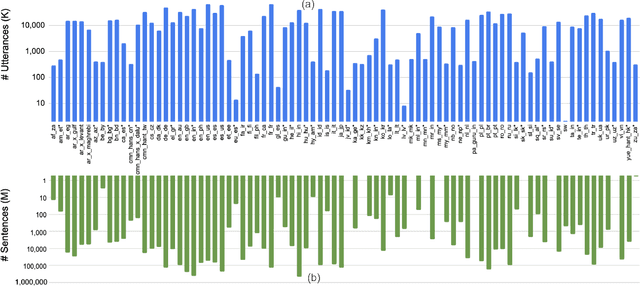
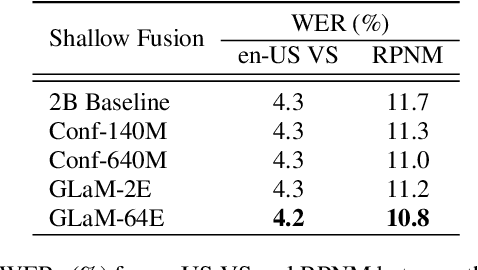
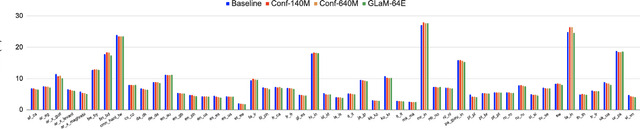

While large language models (LLM) have made impressive progress in natural language processing, it remains unclear how to utilize them in improving automatic speech recognition (ASR). In this work, we propose to train a single multilingual language model (LM) for shallow fusion in multiple languages. We push the limits of the multilingual LM to cover up to 84 languages by scaling up using a mixture-of-experts LLM, i.e., generalist language model (GLaM). When the number of experts increases, GLaM dynamically selects only two at each decoding step to keep the inference computation roughly constant. We then apply GLaM to a multilingual shallow fusion task based on a state-of-the-art end-to-end model. Compared to a dense LM of similar computation during inference, GLaM reduces the WER of an English long-tail test set by 4.4% relative. In a multilingual shallow fusion task, GLaM improves 41 out of 50 languages with an average relative WER reduction of 3.85%, and a maximum reduction of 10%. Compared to the baseline model, GLaM achieves an average WER reduction of 5.53% over 43 languages.
Improving EEG based Continuous Speech Recognition
Nov 30, 2019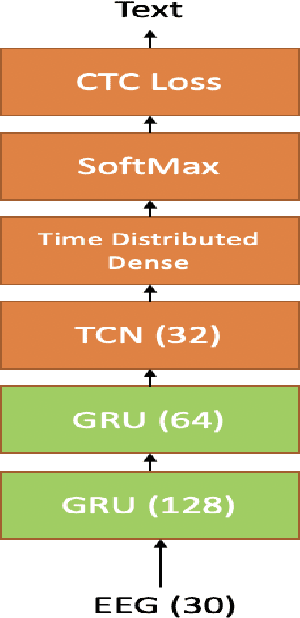
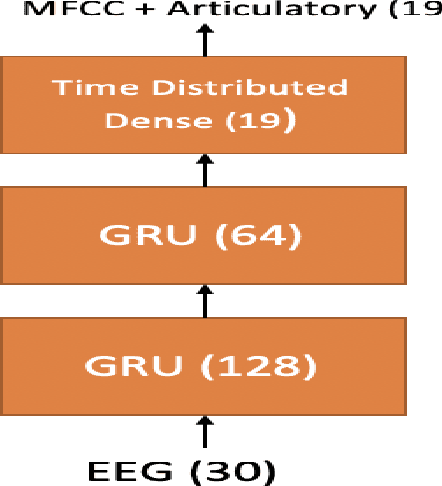
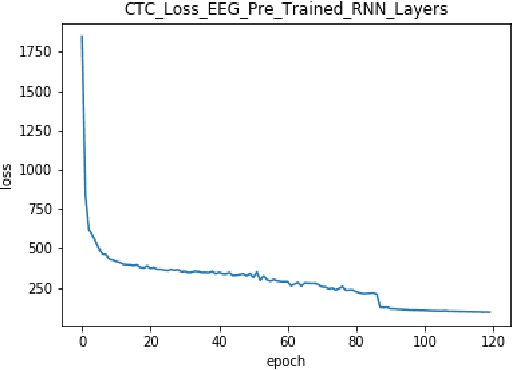
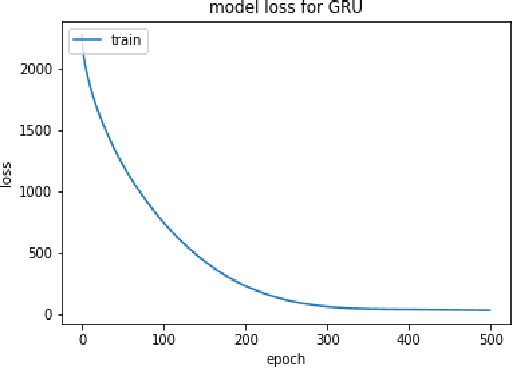
In this paper we introduce various techniques to improve the performance of electroencephalography (EEG) features based continuous speech recognition (CSR) systems. A connectionist temporal classification (CTC) based automatic speech recognition (ASR) system was implemented for performing recognition. We introduce techniques to initialize the weights of the recurrent layers in the encoder of the CTC model with more meaningful weights rather than with random weights and we make use of an external language model to improve the beam search during decoding time. We finally study the problem of predicting articulatory features from EEG features in this paper.
Conformer-based End-to-end Speech Recognition With Rotary Position Embedding
Jul 13, 2021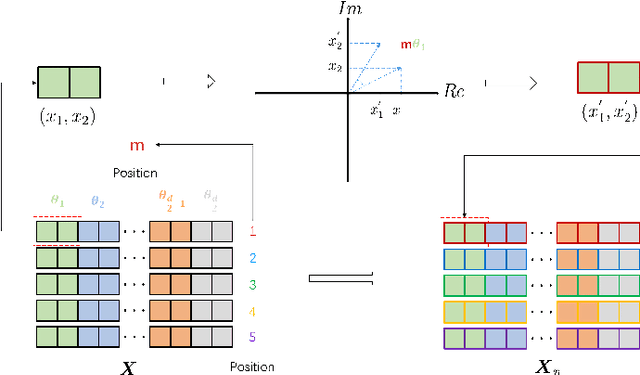
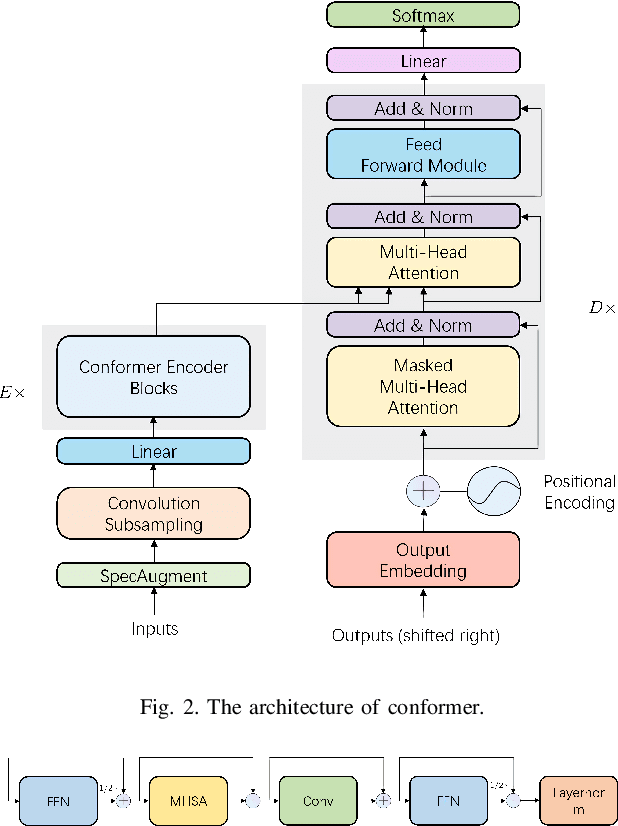
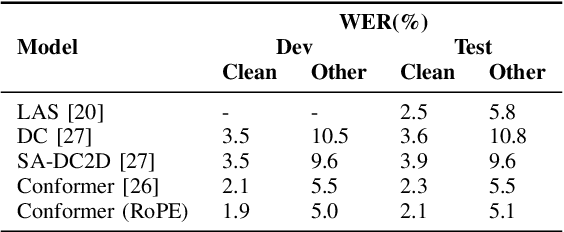
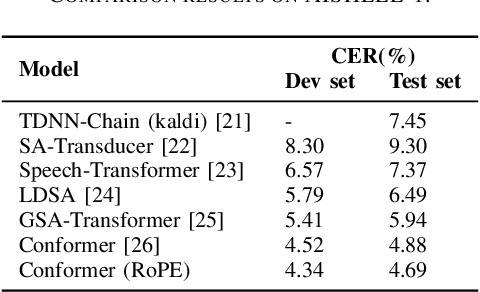
Transformer-based end-to-end speech recognition models have received considerable attention in recent years due to their high training speed and ability to model a long-range global context. Position embedding in the transformer architecture is indispensable because it provides supervision for dependency modeling between elements at different positions in the input sequence. To make use of the time order of the input sequence, many works inject some information about the relative or absolute position of the element into the input sequence. In this work, we investigate various position embedding methods in the convolution-augmented transformer (conformer) and adopt a novel implementation named rotary position embedding (RoPE). RoPE encodes absolute positional information into the input sequence by a rotation matrix, and then naturally incorporates explicit relative position information into a self-attention module. To evaluate the effectiveness of the RoPE method, we conducted experiments on AISHELL-1 and LibriSpeech corpora. Results show that the conformer enhanced with RoPE achieves superior performance in the speech recognition task. Specifically, our model achieves a relative word error rate reduction of 8.70% and 7.27% over the conformer on test-clean and test-other sets of the LibriSpeech corpus respectively.
DeepGD: A Multi-Objective Black-Box Test Selection Approach for Deep Neural Networks
Mar 08, 2023
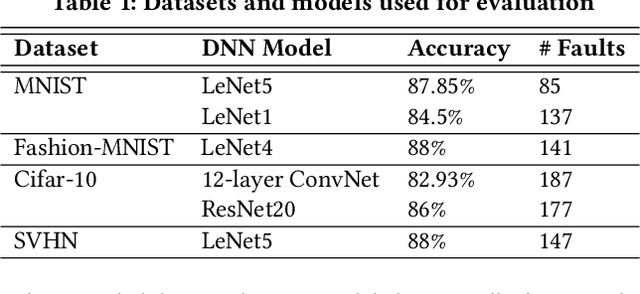
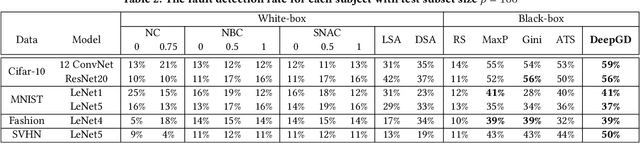
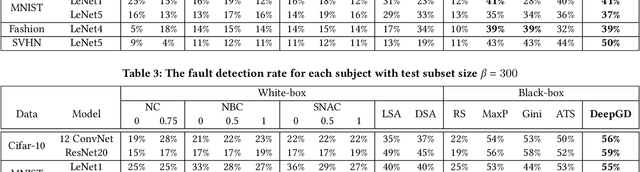
Deep neural networks (DNNs) are widely used in various application domains such as image processing, speech recognition, and natural language processing. However, testing DNN models may be challenging due to the complexity and size of their input domain. Particularly, testing DNN models often requires generating or exploring large unlabeled datasets. In practice, DNN test oracles, which identify the correct outputs for inputs, often require expensive manual effort to label test data, possibly involving multiple experts to ensure labeling correctness. In this paper, we propose DeepGD, a black-box multi-objective test selection approach for DNN models. It reduces the cost of labeling by prioritizing the selection of test inputs with high fault revealing power from large unlabeled datasets. DeepGD not only selects test inputs with high uncertainty scores to trigger as many mispredicted inputs as possible but also maximizes the probability of revealing distinct faults in the DNN model by selecting diverse mispredicted inputs. The experimental results conducted on four widely used datasets and five DNN models show that in terms of fault-revealing ability: (1) White-box, coverage-based approaches fare poorly, (2) DeepGD outperforms existing black-box test selection approaches in terms of fault detection, and (3) DeepGD also leads to better guidance for DNN model retraining when using selected inputs to augment the training set.
Learning to Enhance or Not: Neural Network-Based Switching of Enhanced and Observed Signals for Overlapping Speech Recognition
Jan 11, 2022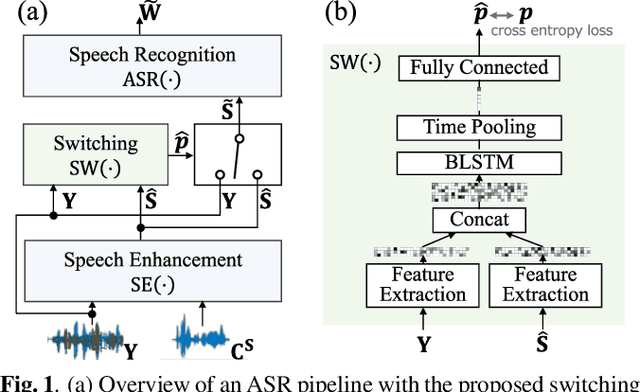
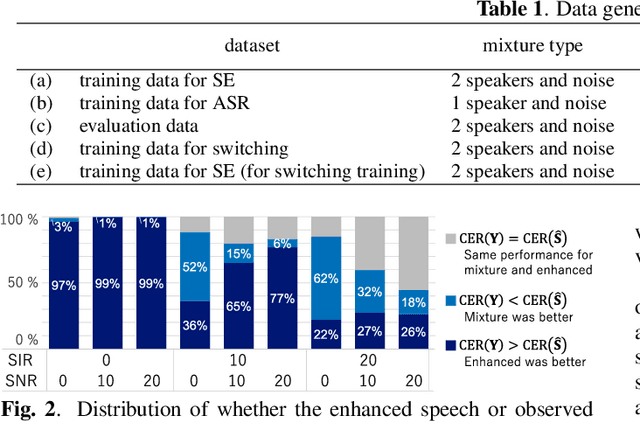
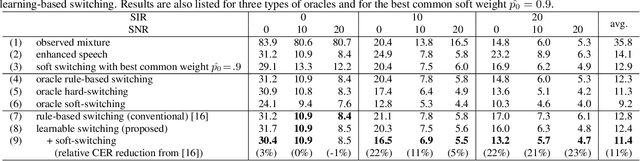
The combination of a deep neural network (DNN) -based speech enhancement (SE) front-end and an automatic speech recognition (ASR) back-end is a widely used approach to implement overlapping speech recognition. However, the SE front-end generates processing artifacts that can degrade the ASR performance. We previously found that such performance degradation can occur even under fully overlapping conditions, depending on the signal-to-interference ratio (SIR) and signal-to-noise ratio (SNR). To mitigate the degradation, we introduced a rule-based method to switch the ASR input between the enhanced and observed signals, which showed promising results. However, the rule's optimality was unclear because it was heuristically designed and based only on SIR and SNR values. In this work, we propose a DNN-based switching method that directly estimates whether ASR will perform better on the enhanced or observed signals. We also introduce soft-switching that computes a weighted sum of the enhanced and observed signals for ASR input, with weights given by the switching model's output posteriors. The proposed learning-based switching showed performance comparable to that of rule-based oracle switching. The soft-switching further improved the ASR performance and achieved a relative character error rate reduction of up to 23 % as compared with the conventional method.
Jointly Learning Visual and Auditory Speech Representations from Raw Data
Dec 12, 2022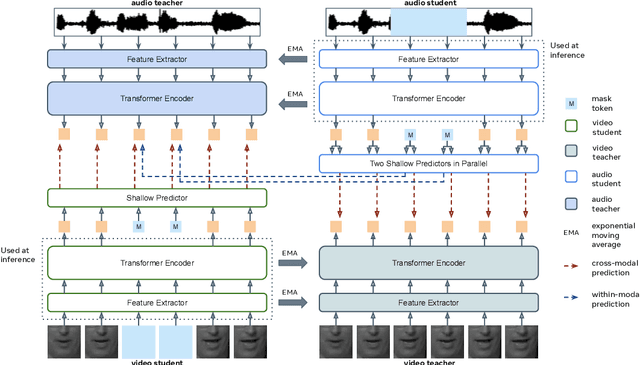
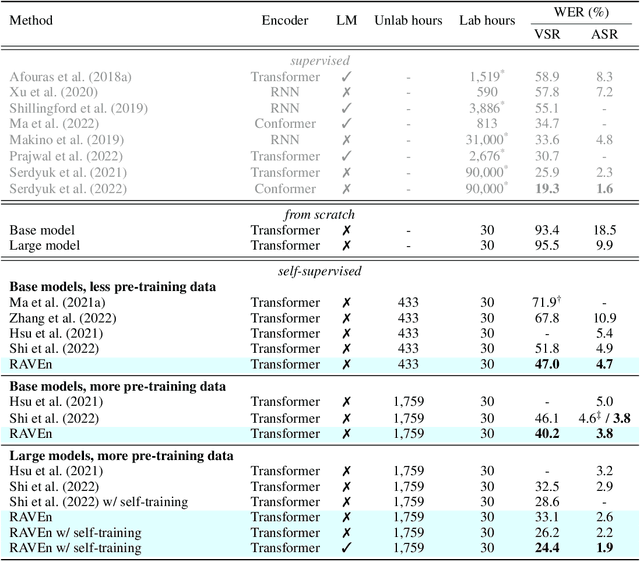
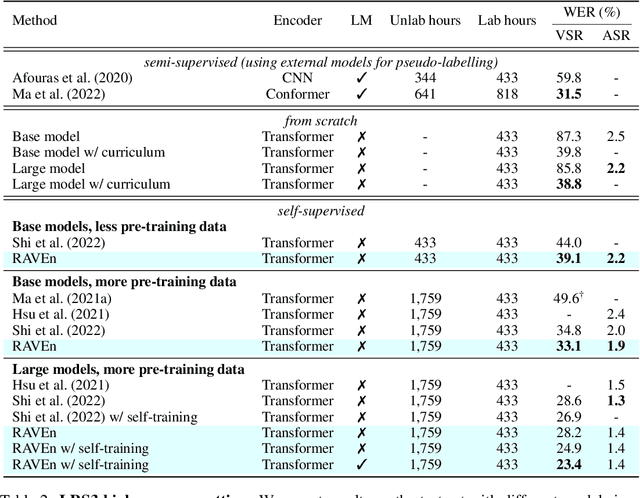
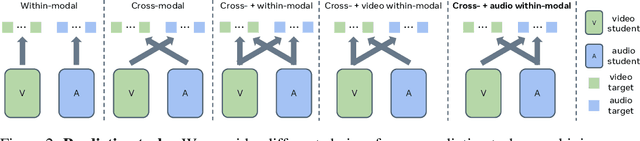
We present RAVEn, a self-supervised multi-modal approach to jointly learn visual and auditory speech representations. Our pre-training objective involves encoding masked inputs, and then predicting contextualised targets generated by slowly-evolving momentum encoders. Driven by the inherent differences between video and audio, our design is asymmetric w.r.t. the two modalities' pretext tasks: Whereas the auditory stream predicts both the visual and auditory targets, the visual one predicts only the auditory targets. We observe strong results in low- and high-resource labelled data settings when fine-tuning the visual and auditory encoders resulting from a single pre-training stage, in which the encoders are jointly trained. Notably, RAVEn surpasses all self-supervised methods on visual speech recognition (VSR) on LRS3, and combining RAVEn with self-training using only 30 hours of labelled data even outperforms a recent semi-supervised method trained on 90,000 hours of non-public data. At the same time, we achieve state-of-the-art results in the LRS3 low-resource setting for auditory speech recognition (as well as for VSR). Our findings point to the viability of learning powerful speech representations entirely from raw video and audio, i.e., without relying on handcrafted features. Code and models will be made public.
Fillers in Spoken Language Understanding: Computational and Psycholinguistic Perspectives
Jan 25, 2023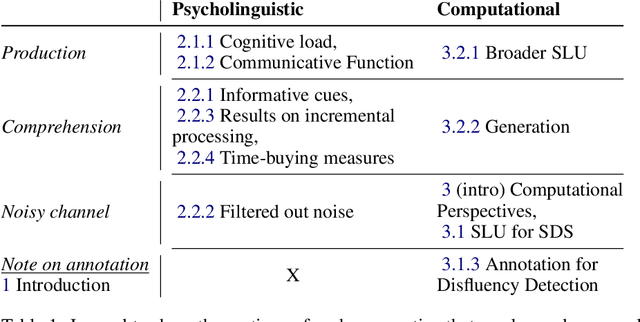
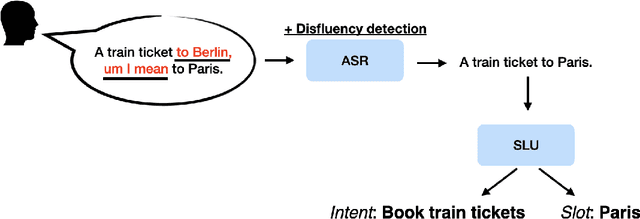
Disfluencies (i.e. interruptions in the regular flow of speech), are ubiquitous to spoken discourse. Fillers ("uh", "um") are disfluencies that occur the most frequently compared to other kinds of disfluencies. Yet, to the best of our knowledge, there isn't a resource that brings together the research perspectives influencing Spoken Language Understanding (SLU) on these speech events. This aim of this article is to synthesise a breadth of perspectives in a holistic way; i.e. from considering underlying (psycho)linguistic theory, to their annotation and consideration in Automatic Speech Recognition (ASR) and SLU systems, to lastly, their study from a generation standpoint. This article aims to present the perspectives in an approachable way to the SLU and Conversational AI community, and discuss moving forward, what we believe are the trends and challenges in each area.
On Comparison of Encoders for Attention based End to End Speech Recognition in Standalone and Rescoring Mode
Jun 26, 2022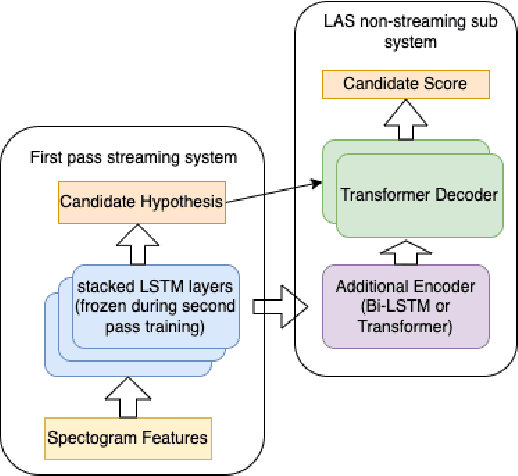
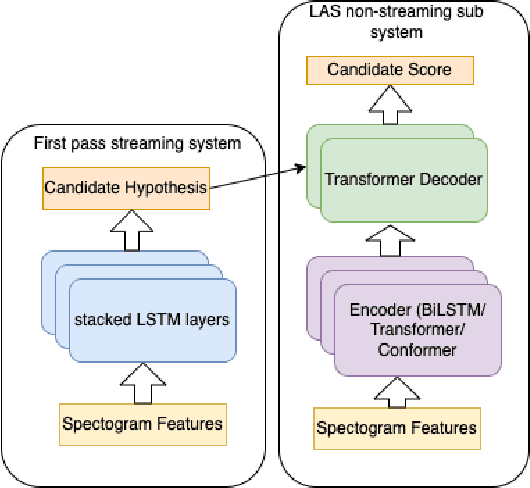

The streaming automatic speech recognition (ASR) models are more popular and suitable for voice-based applications. However, non-streaming models provide better performance as they look at the entire audio context. To leverage the benefits of the non-streaming model in streaming applications like voice search, it is commonly used in second pass re-scoring mode. The candidate hypothesis generated using steaming models is re-scored using a non-streaming model. In this work, we evaluate the non-streaming attention-based end-to-end ASR models on the Flipkart voice search task in both standalone and re-scoring modes. These models are based on Listen-Attend-Spell (LAS) encoder-decoder architecture. We experiment with different encoder variations based on LSTM, Transformer, and Conformer. We compare the latency requirements of these models along with their performance. Overall we show that the Transformer model offers acceptable WER with the lowest latency requirements. We report a relative WER improvement of around 16% with the second pass LAS re-scoring with latency overhead under 5ms. We also highlight the importance of CNN front-end with Transformer architecture to achieve comparable word error rates (WER). Moreover, we observe that in the second pass re-scoring mode all the encoders provide similar benefits whereas the difference in performance is prominent in standalone text generation mode.
Self-Supervised Learning for speech recognition with Intermediate layer supervision
Dec 16, 2021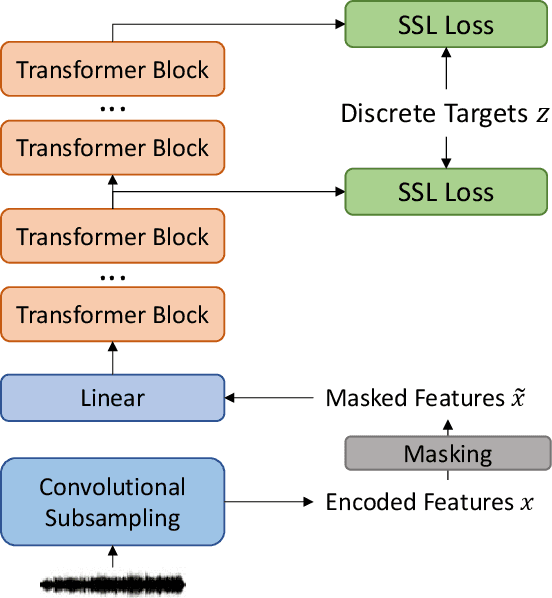
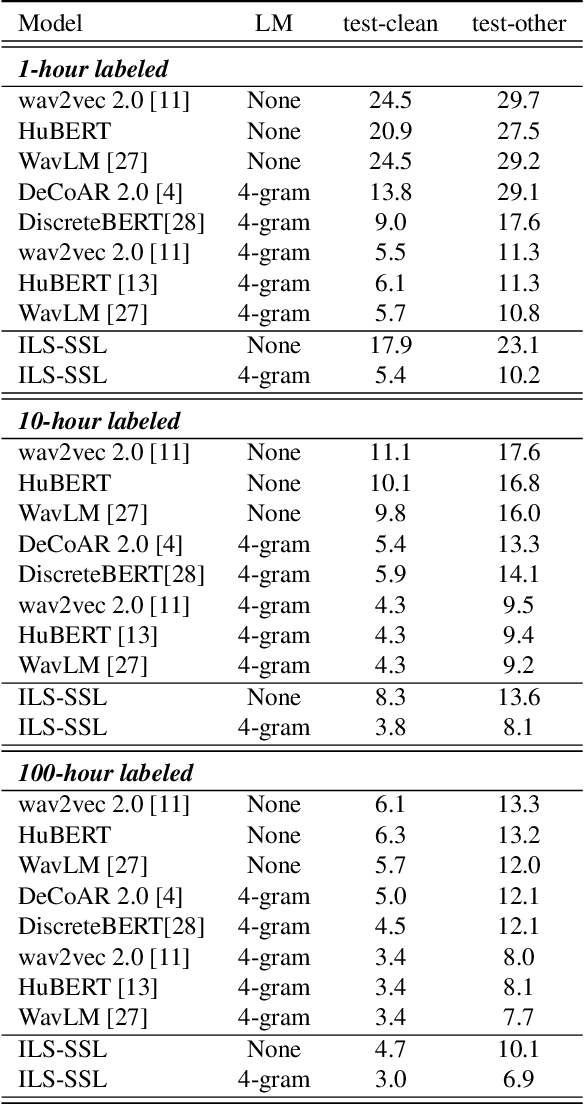
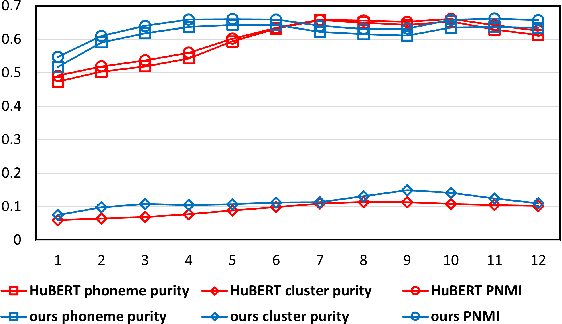
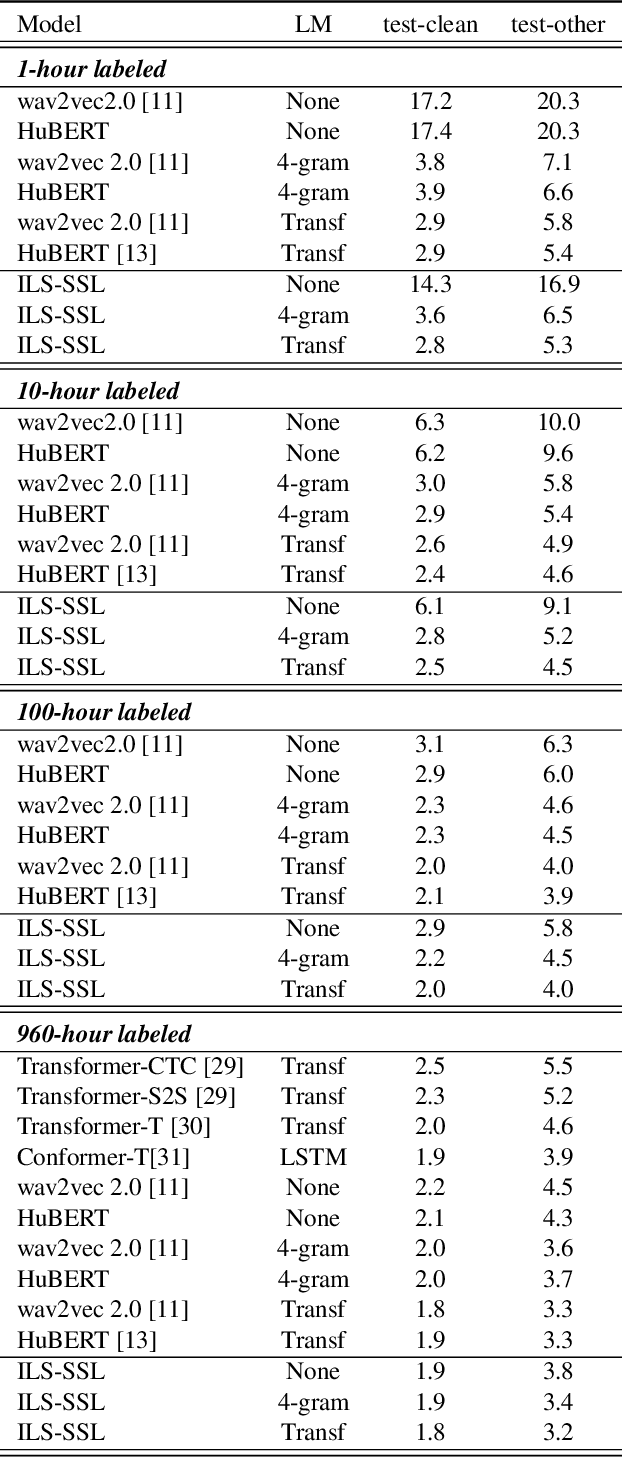
Recently, pioneer work finds that speech pre-trained models can solve full-stack speech processing tasks, because the model utilizes bottom layers to learn speaker-related information and top layers to encode content-related information. Since the network capacity is limited, we believe the speech recognition performance could be further improved if the model is dedicated to audio content information learning. To this end, we propose Intermediate Layer Supervision for Self-Supervised Learning (ILS-SSL), which forces the model to concentrate on content information as much as possible by adding an additional SSL loss on the intermediate layers. Experiments on LibriSpeech test-other set show that our method outperforms HuBERT significantly, which achieves a 23.5%/11.6% relative word error rate reduction in the w/o language model setting for base/large models. Detailed analysis shows the bottom layers of our model have a better correlation with phonetic units, which is consistent with our intuition and explains the success of our method for ASR.