 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSPulse: Dual Space Tiny Pre-Trained Models for Rapid Time-Series Analysis
May 19, 2025



The rise of time-series pre-trained models has advanced temporal representation learning, but current state-of-the-art models are often large-scale, requiring substantial compute. We introduce TSPulse, ultra-compact time-series pre-trained models with only 1M parameters, specialized to perform strongly across classification, anomaly detection, imputation, and retrieval tasks. TSPulse introduces innovations at both the architecture and task levels. At the architecture level, it employs a dual-space masked reconstruction, learning from both time and frequency domains to capture complementary signals. This is further enhanced by a dual-embedding disentanglement, generating both detailed embeddings for fine-grained analysis and high-level semantic embeddings for broader task understanding. Notably, TSPulse's semantic embeddings are robust to shifts in time, magnitude, and noise, which is important for robust retrieval. At the task level, TSPulse incorporates TSLens, a fine-tuning component enabling task-specific feature attention. It also introduces a multi-head triangulation technique that correlates deviations from multiple prediction heads, enhancing anomaly detection by fusing complementary model outputs. Additionally, a hybrid mask pretraining is proposed to improves zero-shot imputation by reducing pre-training bias. These architecture and task innovations collectively contribute to TSPulse's significant performance gains: 5-16% on the UEA classification benchmarks, +20% on the TSB-AD anomaly detection leaderboard, +50% in zero-shot imputation, and +25% in time-series retrieval. Remarkably, these results are achieved with just 1M parameters, making TSPulse 10-100X smaller than existing pre-trained models. Its efficiency enables GPU-free inference and rapid pre-training, setting a new standard for efficient time-series pre-trained models. Models will be open-sourced soon.
On Comparison of Encoders for Attention based End to End Speech Recognition in Standalone and Rescoring Mode
Jun 26, 2022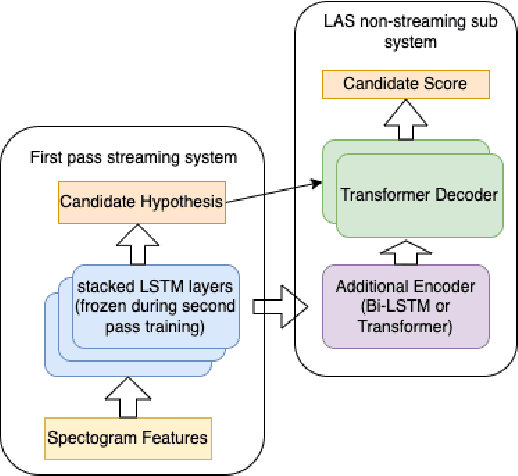
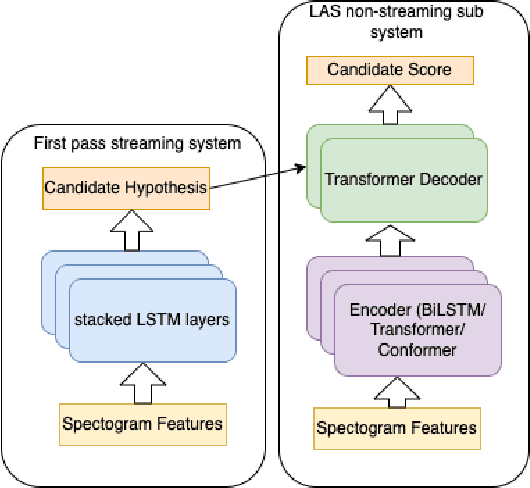

The streaming automatic speech recognition (ASR) models are more popular and suitable for voice-based applications. However, non-streaming models provide better performance as they look at the entire audio context. To leverage the benefits of the non-streaming model in streaming applications like voice search, it is commonly used in second pass re-scoring mode. The candidate hypothesis generated using steaming models is re-scored using a non-streaming model. In this work, we evaluate the non-streaming attention-based end-to-end ASR models on the Flipkart voice search task in both standalone and re-scoring modes. These models are based on Listen-Attend-Spell (LAS) encoder-decoder architecture. We experiment with different encoder variations based on LSTM, Transformer, and Conformer. We compare the latency requirements of these models along with their performance. Overall we show that the Transformer model offers acceptable WER with the lowest latency requirements. We report a relative WER improvement of around 16% with the second pass LAS re-scoring with latency overhead under 5ms. We also highlight the importance of CNN front-end with Transformer architecture to achieve comparable word error rates (WER). Moreover, we observe that in the second pass re-scoring mode all the encoders provide similar benefits whereas the difference in performance is prominent in standalone text generation mode.