 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Multi-Camera Visual-Inertial Simultaneous Localization and Mapping for Autonomous Valet Parking
Apr 27, 2023

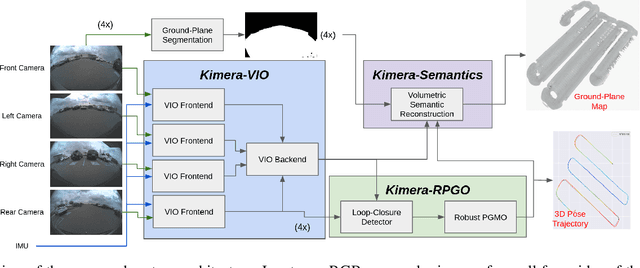
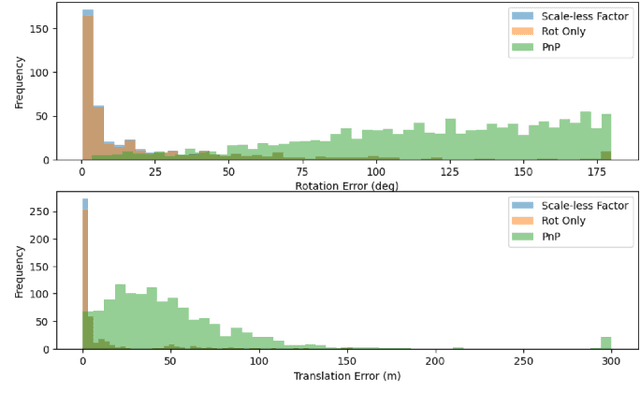
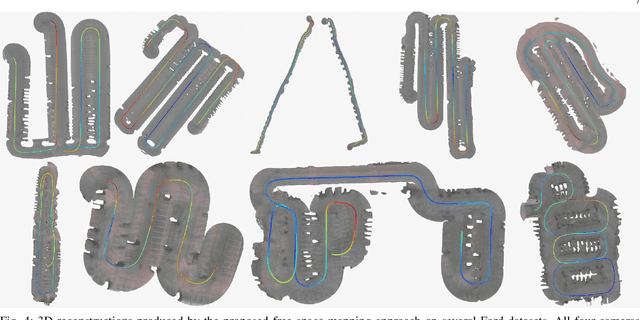
Localization and mapping are key capabilities for self-driving vehicles. This paper describes a visual-inertial SLAM system that estimates an accurate and globally consistent trajectory of the vehicle and reconstructs a dense model of the free space surrounding the car. Towards this goal, we build on Kimera and extend it to use multiple cameras as well as external (e.g. wheel) odometry sensors, to obtain accurate and robust odometry estimates in real-world problems. Additionally, we propose an effective scheme for closing loops that circumvents the drawbacks of common alternatives based on the Perspective-n-Point method and also works with a single monocular camera. Finally, we develop a method for dense 3D mapping of the free space that combines a segmentation network for free-space detection with a homography-based dense mapping technique. We test our system on photo-realistic simulations and on several real datasets collected by a car prototype developed by the Ford Motor Company, spanning both indoor and outdoor parking scenarios. Our multi-camera system is shown to outperform state-of-the art open-source visual-inertial-SLAM pipelines (Vins-Fusion, ORB-SLAM3), and exhibits an average trajectory error under 1% of the trajectory length across more than 8 km of distance traveled (combined across all datasets). A video showcasing the system is available here: youtu.be/H8CpzDpXOI8
Foundations of Spatial Perception for Robotics: Hierarchical Representations and Real-time Systems
May 11, 2023
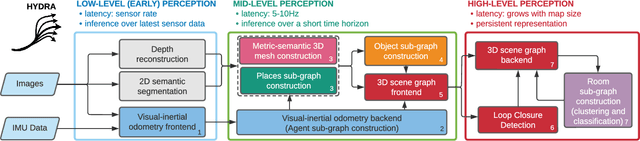

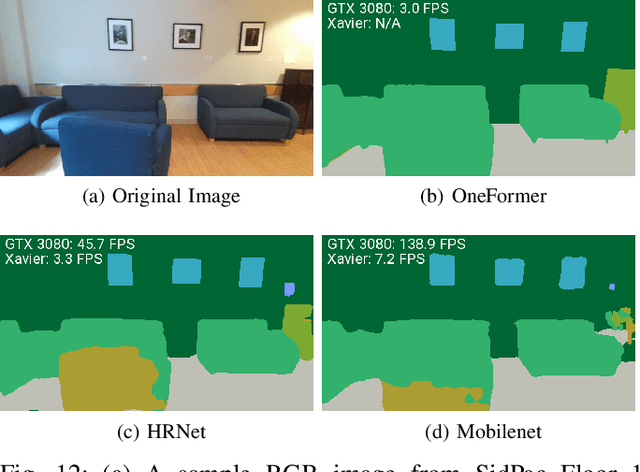
3D spatial perception is the problem of building and maintaining an actionable and persistent representation of the environment in real-time using sensor data and prior knowledge. Despite the fast-paced progress in robot perception, most existing methods either build purely geometric maps (as in traditional SLAM) or flat metric-semantic maps that do not scale to large environments or large dictionaries of semantic labels. The first part of this paper is concerned with representations: we show that scalable representations for spatial perception need to be hierarchical in nature. Hierarchical representations are efficient to store, and lead to layered graphs with small treewidth, which enable provably efficient inference. We then introduce an example of hierarchical representation for indoor environments, namely a 3D scene graph, and discuss its structure and properties. The second part of the paper focuses on algorithms to incrementally construct a 3D scene graph as the robot explores the environment. Our algorithms combine 3D geometry, topology (to cluster the places into rooms), and geometric deep learning (e.g., to classify the type of rooms the robot is moving across). The third part of the paper focuses on algorithms to maintain and correct 3D scene graphs during long-term operation. We propose hierarchical descriptors for loop closure detection and describe how to correct a scene graph in response to loop closures, by solving a 3D scene graph optimization problem. We conclude the paper by combining the proposed perception algorithms into Hydra, a real-time spatial perception system that builds a 3D scene graph from visual-inertial data in real-time. We showcase Hydra's performance in photo-realistic simulations and real data collected by a Clearpath Jackal robots and a Unitree A1 robot. We release an open-source implementation of Hydra at https://github.com/MIT-SPARK/Hydra.
Face Animation with an Attribute-Guided Diffusion Model
Apr 06, 2023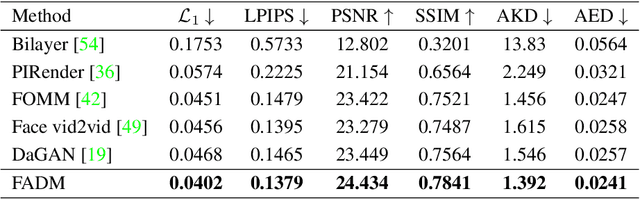
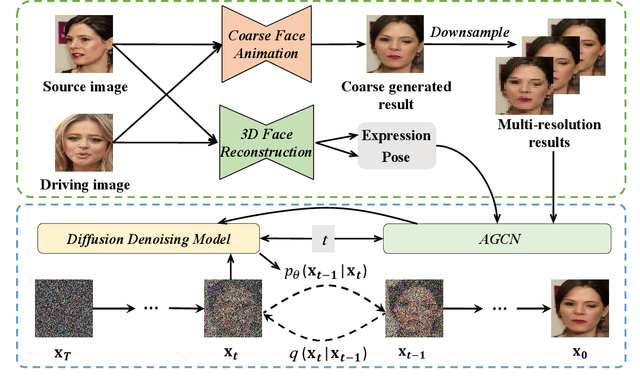
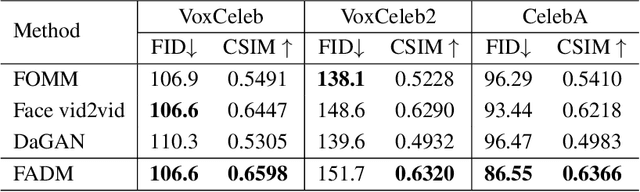
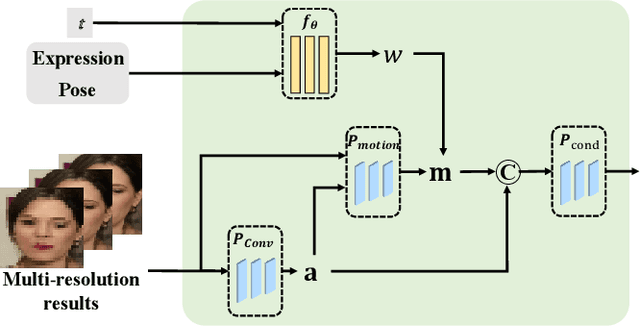
Face animation has achieved much progress in computer vision. However, prevailing GAN-based methods suffer from unnatural distortions and artifacts due to sophisticated motion deformation. In this paper, we propose a Face Animation framework with an attribute-guided Diffusion Model (FADM), which is the first work to exploit the superior modeling capacity of diffusion models for photo-realistic talking-head generation. To mitigate the uncontrollable synthesis effect of the diffusion model, we design an Attribute-Guided Conditioning Network (AGCN) to adaptively combine the coarse animation features and 3D face reconstruction results, which can incorporate appearance and motion conditions into the diffusion process. These specific designs help FADM rectify unnatural artifacts and distortions, and also enrich high-fidelity facial details through iterative diffusion refinements with accurate animation attributes. FADM can flexibly and effectively improve existing animation videos. Extensive experiments on widely used talking-head benchmarks validate the effectiveness of FADM over prior arts.
Sketch Less Face Image Retrieval: A New Challenge
Feb 11, 2023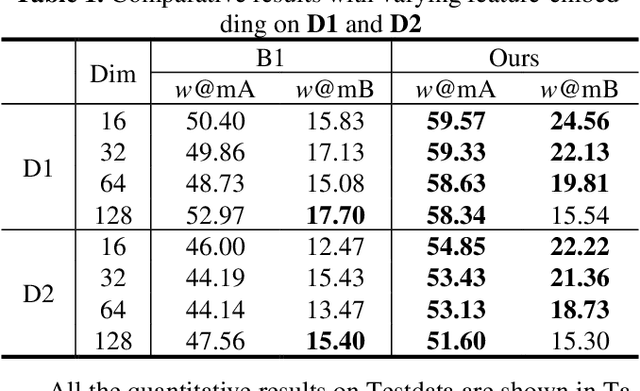
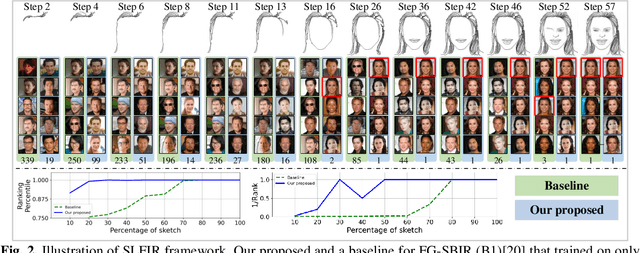
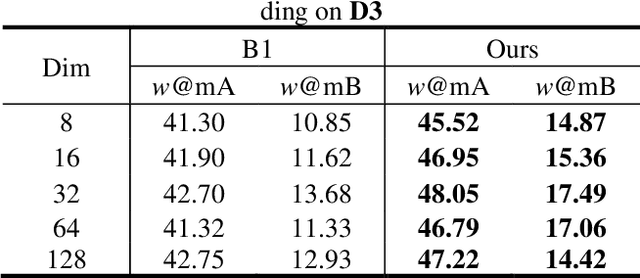
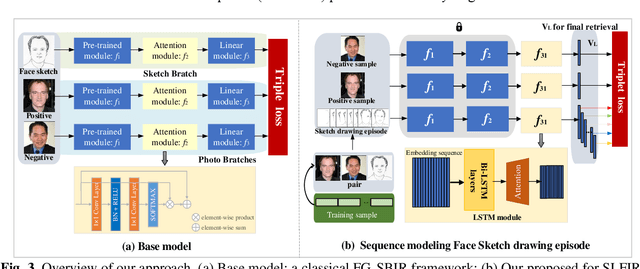
In some specific scenarios, face sketch was used to identify a person. However, drawing a complete face sketch often needs skills and takes time, which hinder its widespread applicability in the practice. In this study, we proposed a new task named sketch less face image retrieval (SLFIR), in which the retrieval was carried out at each stroke and aim to retrieve the target face photo using a partial sketch with as few strokes as possible (see Fig.1). Firstly, we developed a method to generate the data of sketch with drawing process, and opened such dataset; Secondly, we proposed a two-stage method as the baseline for SLFIR that (1) A triplet network, was first adopt to learn the joint embedding space shared between the complete sketch and its target face photo; (2) Regarding the sketch drawing episode as a sequence, we designed a LSTM module to optimize the representation of the incomplete face sketch. Experiments indicate that the new framework can finish the retrieval using a partial or pool drawing sketch.
CherryPicker: Semantic Skeletonization and Topological Reconstruction of Cherry Trees
Apr 10, 2023

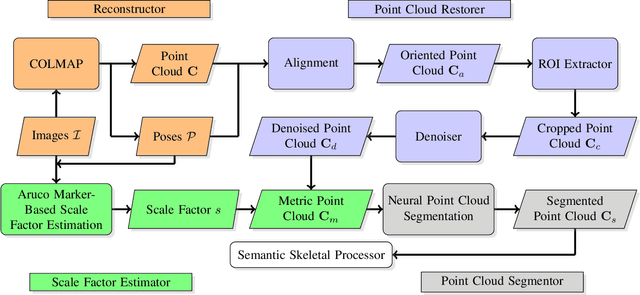
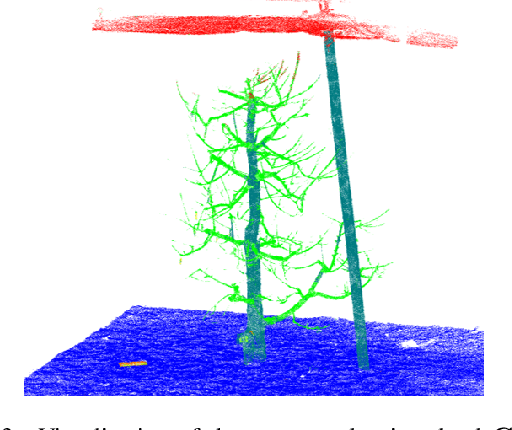
In plant phenotyping, accurate trait extraction from 3D point clouds of trees is still an open problem. For automatic modeling and trait extraction of tree organs such as blossoms and fruits, the semantically segmented point cloud of a tree and the tree skeleton are necessary. Therefore, we present CherryPicker, an automatic pipeline that reconstructs photo-metric point clouds of trees, performs semantic segmentation and extracts their topological structure in form of a skeleton. Our system combines several state-of-the-art algorithms to enable automatic processing for further usage in 3D-plant phenotyping applications. Within this pipeline, we present a method to automatically estimate the scale factor of a monocular reconstruction to overcome scale ambiguity and obtain metrically correct point clouds. Furthermore, we propose a semantic skeletonization algorithm build up on Laplacian-based contraction. We also show by weighting different tree organs semantically, our approach can effectively remove artifacts induced by occlusion and structural size variations. CherryPicker obtains high-quality topology reconstructions of cherry trees with precise details.
APRNet: Attention-based Pixel-wise Rendering Network for Photo-Realistic Text Image Generation
Mar 15, 2022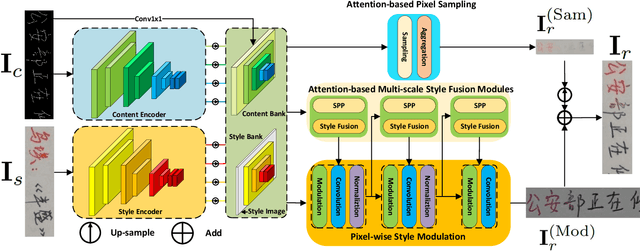

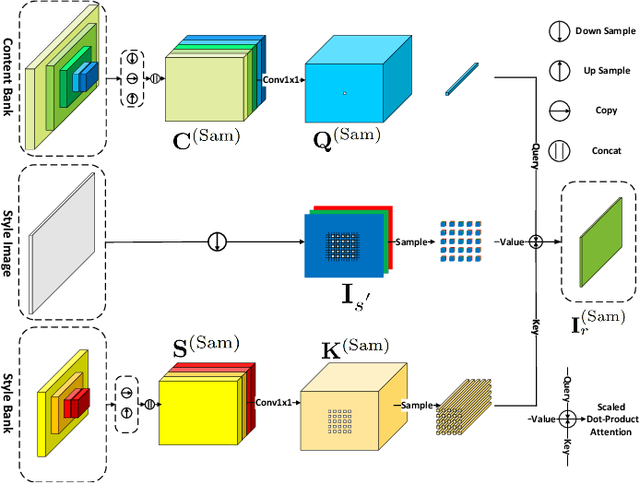
Style-guided text image generation tries to synthesize text image by imitating reference image's appearance while keeping text content unaltered. The text image appearance includes many aspects. In this paper, we focus on transferring style image's background and foreground color patterns to the content image to generate photo-realistic text image. To achieve this goal, we propose 1) a content-style cross attention based pixel sampling approach to roughly mimicking the style text image's background; 2) a pixel-wise style modulation technique to transfer varying color patterns of the style image to the content image spatial-adaptively; 3) a cross attention based multi-scale style fusion approach to solving text foreground misalignment issue between style and content images; 4) an image patch shuffling strategy to create style, content and ground truth image tuples for training. Experimental results on Chinese handwriting text image synthesis with SCUT-HCCDoc and CASIA-OLHWDB datasets demonstrate that the proposed method can improve the quality of synthetic text images and make them more photo-realistic.
Face sketch to photo translation using generative adversarial networks
Oct 23, 2021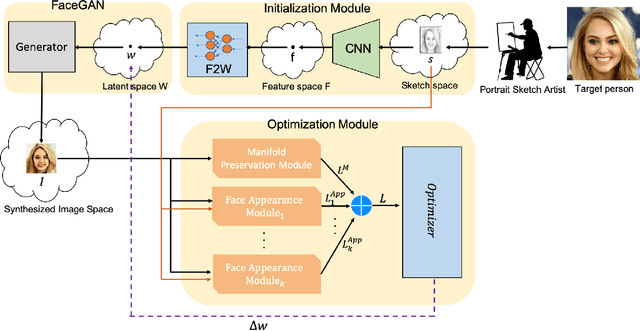
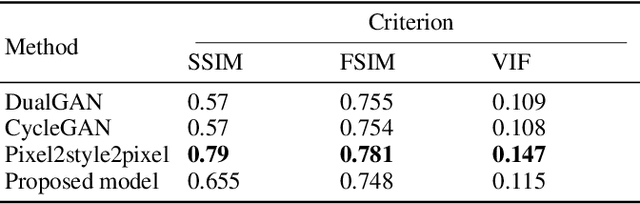
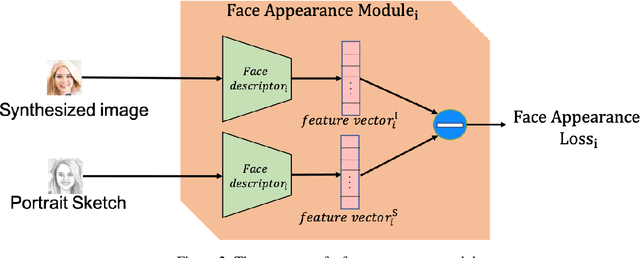
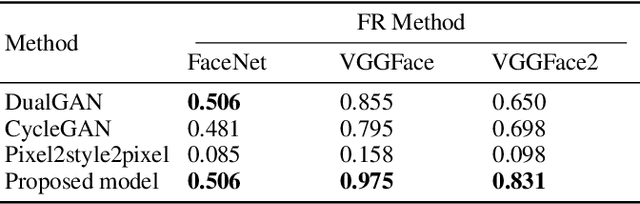
Translating face sketches to photo-realistic faces is an interesting and essential task in many applications like law enforcement and the digital entertainment industry. One of the most important challenges of this task is the inherent differences between the sketch and the real image such as the lack of color and details of the skin tissue in the sketch. With the advent of adversarial generative models, an increasing number of methods have been proposed for sketch-to-image synthesis. However, these models still suffer from limitations such as the large number of paired data required for training, the low resolution of the produced images, or the unrealistic appearance of the generated images. In this paper, we propose a method for converting an input facial sketch to a colorful photo without the need for any paired dataset. To do so, we use a pre-trained face photo generating model to synthesize high-quality natural face photos and employ an optimization procedure to keep high-fidelity to the input sketch. We train a network to map the facial features extracted from the input sketch to a vector in the latent space of the face generating model. Also, we study different optimization criteria and compare the results of the proposed model with those of the state-of-the-art models quantitatively and qualitatively. The proposed model achieved 0.655 in the SSIM index and 97.59% rank-1 face recognition rate with higher quality of the produced images.
Evaluation of a Canonical Image Representation for Sidescan Sonar
Apr 18, 2023
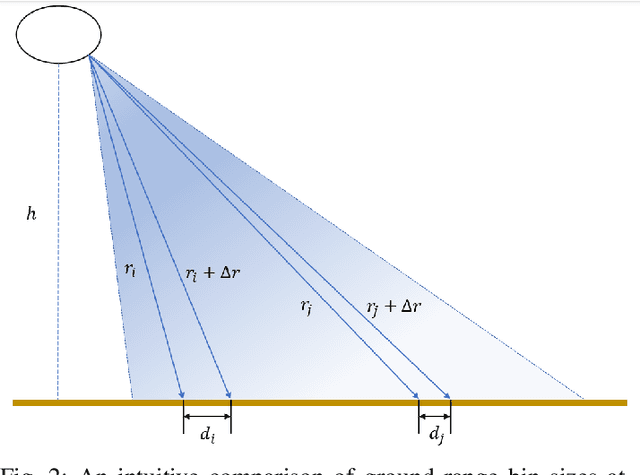
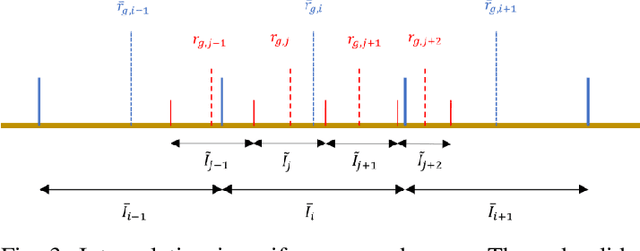
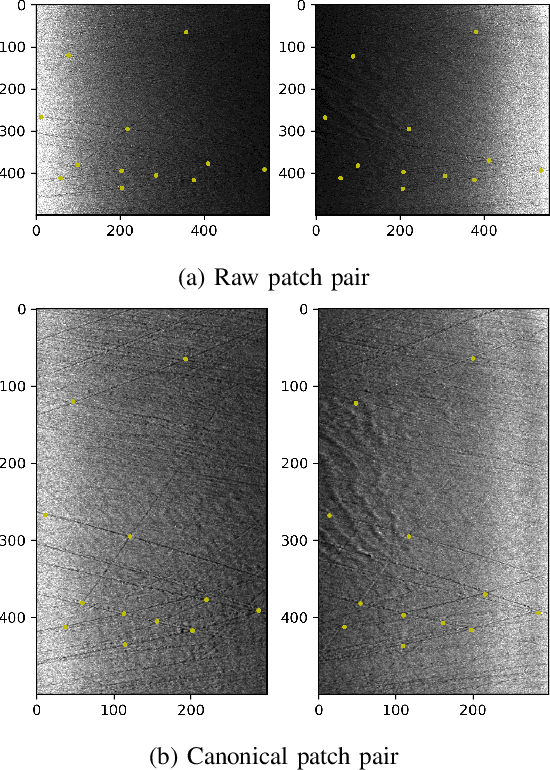
Acoustic sensors play an important role in autonomous underwater vehicles (AUVs). Sidescan sonar (SSS) detects a wide range and provides photo-realistic images in high resolution. However, SSS projects the 3D seafloor to 2D images, which are distorted by the AUV's altitude, target's range and sensor's resolution. As a result, the same physical area can show significant visual differences in SSS images from different survey lines, causing difficulties in tasks such as pixel correspondence and template matching. In this paper, a canonical transformation method consisting of intensity correction and slant range correction is proposed to decrease the above distortion. The intensity correction includes beam pattern correction and incident angle correction using three different Lambertian laws (cos, cos2, cot), whereas the slant range correction removes the nadir zone and projects the position of SSS elements into equally horizontally spaced, view-point independent bins. The proposed method is evaluated on real data collected by a HUGIN AUV, with manually-annotated pixel correspondence as ground truth reference. Experimental results on patch pairs compare similarity measures and keypoint descriptor matching. The results show that the canonical transformation can improve the patch similarity, as well as SIFT descriptor matching accuracy in different images where the same physical area was ensonified.
PG-VTON: A Novel Image-Based Virtual Try-On Method via Progressive Inference Paradigm
Apr 18, 2023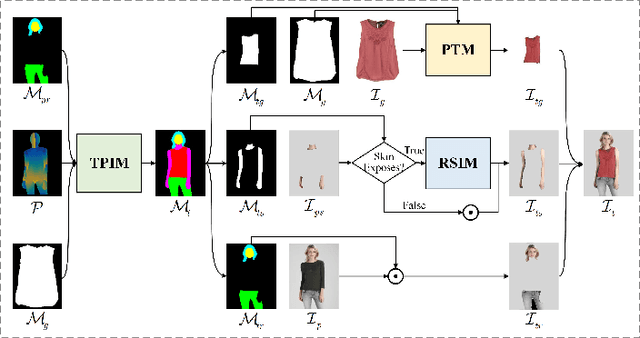


Virtual try-on is a promising computer vision topic with a high commercial value wherein a new garment is visually worn on a person with a photo-realistic effect. Previous studies conduct their shape and content inference at one stage, employing a single-scale warping mechanism and a relatively unsophisticated content inference mechanism. These approaches have led to suboptimal results in terms of garment warping and skin reservation under challenging try-on scenarios. To address these limitations, we propose a novel virtual try-on method via progressive inference paradigm (PGVTON) that leverages a top-down inference pipeline and a general garment try-on strategy. Specifically, we propose a robust try-on parsing inference method by disentangling semantic categories and introducing consistency. Exploiting the try-on parsing as the shape guidance, we implement the garment try-on via warping-mapping-composition. To facilitate adaptation to a wide range of try-on scenarios, we adopt a covering more and selecting one warping strategy and explicitly distinguish tasks based on alignment. Additionally, we regulate StyleGAN2 to implement re-naked skin inpainting, conditioned on the target skin shape and spatial-agnostic skin features. Experiments demonstrate that our method has state-of-the-art performance under two challenging scenarios. The code will be available at https://github.com/NerdFNY/PGVTON.
HM3D-ABO: A Photo-realistic Dataset for Object-centric Multi-view 3D Reconstruction
Jun 24, 2022



Reconstructing 3D objects is an important computer vision task that has wide application in AR/VR. Deep learning algorithm developed for this task usually relies on an unrealistic synthetic dataset, such as ShapeNet and Things3D. On the other hand, existing real-captured object-centric datasets usually do not have enough annotation to enable supervised training or reliable evaluation. In this technical report, we present a photo-realistic object-centric dataset HM3D-ABO. It is constructed by composing realistic indoor scene and realistic object. For each configuration, we provide multi-view RGB observations, a water-tight mesh model for the object, ground truth depth map and object mask. The proposed dataset could also be useful for tasks such as camera pose estimation and novel-view synthesis. The dataset generation code is released at https://github.com/zhenpeiyang/HM3D-ABO.