 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Soft-IntroVAE for Continuous Latent space Image Super-Resolution
Jul 18, 2023
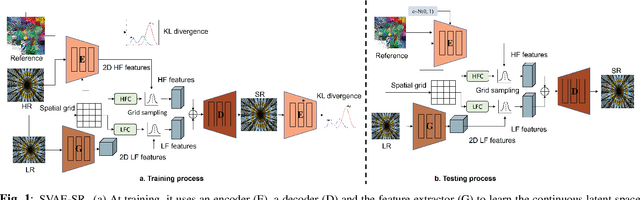
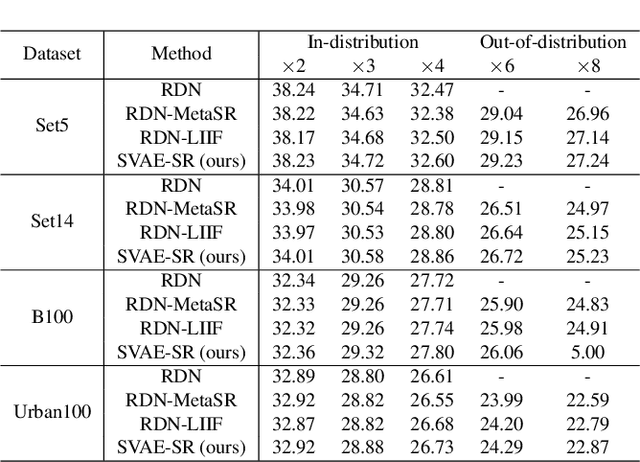
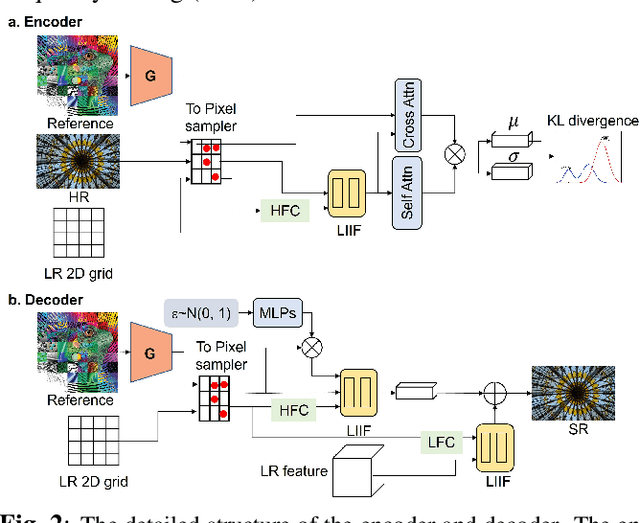
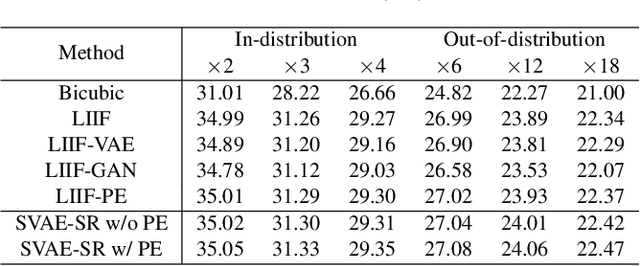
Continuous image super-resolution (SR) recently receives a lot of attention from researchers, for its practical and flexible image scaling for various displays. Local implicit image representation is one of the methods that can map the coordinates and 2D features for latent space interpolation. Inspired by Variational AutoEncoder, we propose a Soft-introVAE for continuous latent space image super-resolution (SVAE-SR). A novel latent space adversarial training is achieved for photo-realistic image restoration. To further improve the quality, a positional encoding scheme is used to extend the original pixel coordinates by aggregating frequency information over the pixel areas. We show the effectiveness of the proposed SVAE-SR through quantitative and qualitative comparisons, and further, illustrate its generalization in denoising and real-image super-resolution.
* 5 pages, 4 figures
Factorized and Controllable Neural Re-Rendering of Outdoor Scene for Photo Extrapolation
Jul 14, 2022
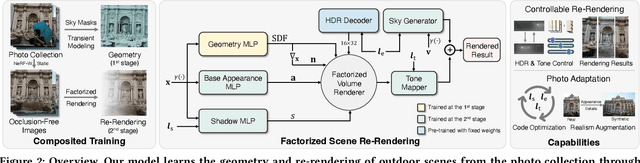
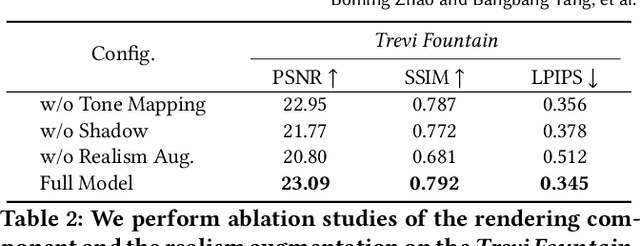
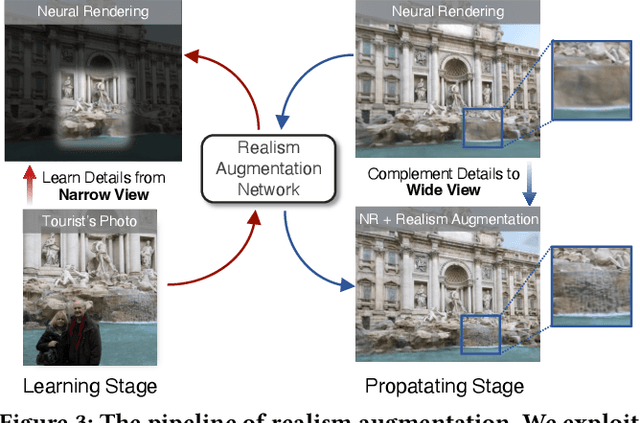
Expanding an existing tourist photo from a partially captured scene to a full scene is one of the desired experiences for photography applications. Although photo extrapolation has been well studied, it is much more challenging to extrapolate a photo (i.e., selfie) from a narrow field of view to a wider one while maintaining a similar visual style. In this paper, we propose a factorized neural re-rendering model to produce photorealistic novel views from cluttered outdoor Internet photo collections, which enables the applications including controllable scene re-rendering, photo extrapolation and even extrapolated 3D photo generation. Specifically, we first develop a novel factorized re-rendering pipeline to handle the ambiguity in the decomposition of geometry, appearance and illumination. We also propose a composited training strategy to tackle the unexpected occlusion in Internet images. Moreover, to enhance photo-realism when extrapolating tourist photographs, we propose a novel realism augmentation process to complement appearance details, which automatically propagates the texture details from a narrow captured photo to the extrapolated neural rendered image. The experiments and photo editing examples on outdoor scenes demonstrate the superior performance of our proposed method in both photo-realism and downstream applications.
Web Photo Source Identification based on Neural Enhanced Camera Fingerprint
Feb 18, 2023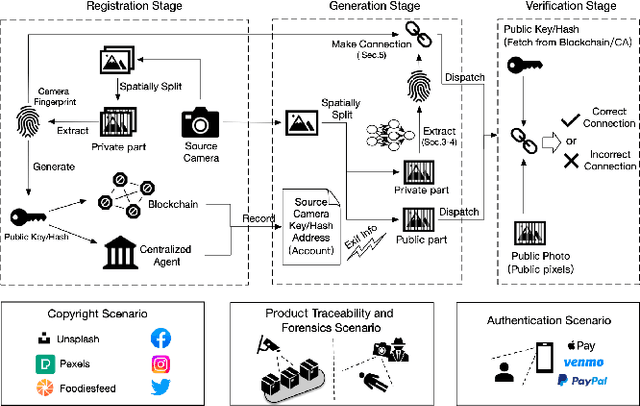
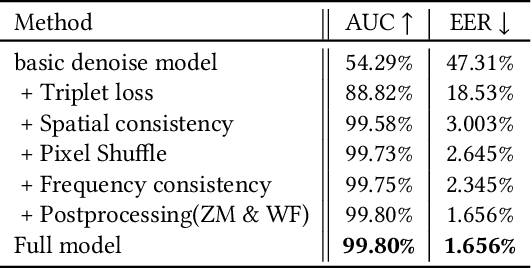
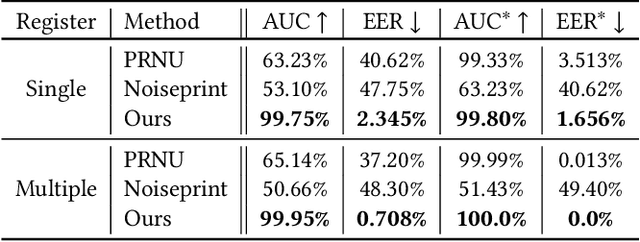
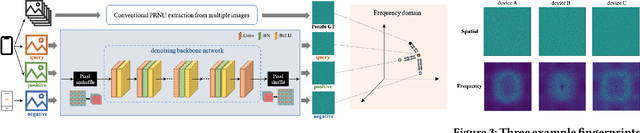
With the growing popularity of smartphone photography in recent years, web photos play an increasingly important role in all walks of life. Source camera identification of web photos aims to establish a reliable linkage from the captured images to their source cameras, and has a broad range of applications, such as image copyright protection, user authentication, investigated evidence verification, etc. This paper presents an innovative and practical source identification framework that employs neural-network enhanced sensor pattern noise to trace back web photos efficiently while ensuring security. Our proposed framework consists of three main stages: initial device fingerprint registration, fingerprint extraction and cryptographic connection establishment while taking photos, and connection verification between photos and source devices. By incorporating metric learning and frequency consistency into the deep network design, our proposed fingerprint extraction algorithm achieves state-of-the-art performance on modern smartphone photos for reliable source identification. Meanwhile, we also propose several optimization sub-modules to prevent fingerprint leakage and improve accuracy and efficiency. Finally for practical system design, two cryptographic schemes are introduced to reliably identify the correlation between registered fingerprint and verified photo fingerprint, i.e. fuzzy extractor and zero-knowledge proof (ZKP). The codes for fingerprint extraction network and benchmark dataset with modern smartphone cameras photos are all publicly available at https://github.com/PhotoNecf/PhotoNecf.
ChildGAN: Large Scale Synthetic Child Facial Data Using Domain Adaptation in StyleGAN
Jul 25, 2023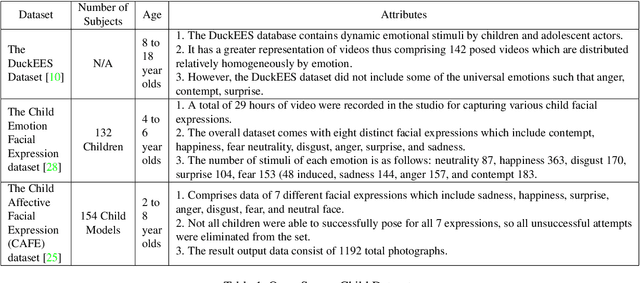
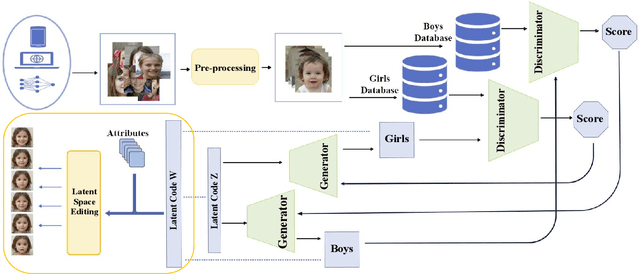
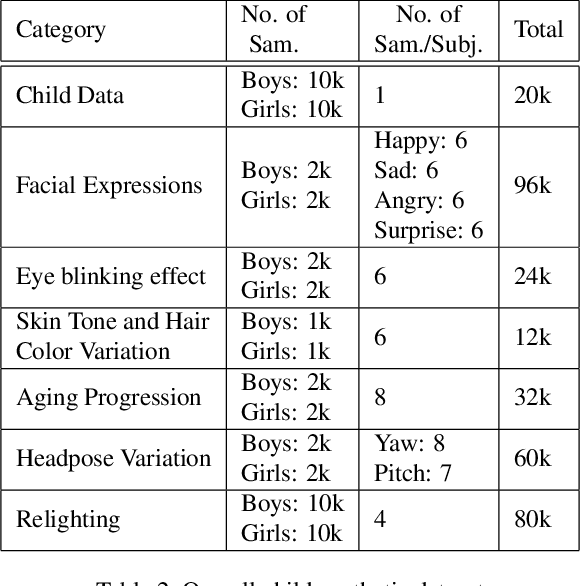

In this research work, we proposed a novel ChildGAN, a pair of GAN networks for generating synthetic boys and girls facial data derived from StyleGAN2. ChildGAN is built by performing smooth domain transfer using transfer learning. It provides photo-realistic, high-quality data samples. A large-scale dataset is rendered with a variety of smart facial transformations: facial expressions, age progression, eye blink effects, head pose, skin and hair color variations, and variable lighting conditions. The dataset comprises more than 300k distinct data samples. Further, the uniqueness and characteristics of the rendered facial features are validated by running different computer vision application tests which include CNN-based child gender classifier, face localization and facial landmarks detection test, identity similarity evaluation using ArcFace, and lastly running eye detection and eye aspect ratio tests. The results demonstrate that synthetic child facial data of high quality offers an alternative to the cost and complexity of collecting a large-scale dataset from real children.
Realistic Saliency Guided Image Enhancement
Jun 09, 2023

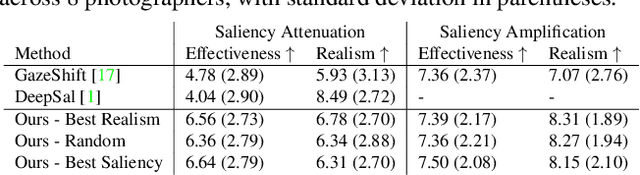
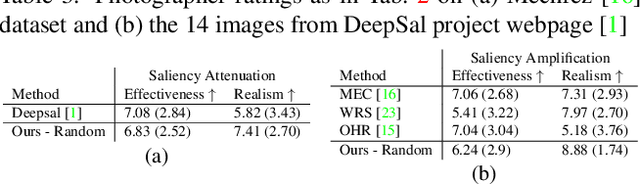
Common editing operations performed by professional photographers include the cleanup operations: de-emphasizing distracting elements and enhancing subjects. These edits are challenging, requiring a delicate balance between manipulating the viewer's attention while maintaining photo realism. While recent approaches can boast successful examples of attention attenuation or amplification, most of them also suffer from frequent unrealistic edits. We propose a realism loss for saliency-guided image enhancement to maintain high realism across varying image types, while attenuating distractors and amplifying objects of interest. Evaluations with professional photographers confirm that we achieve the dual objective of realism and effectiveness, and outperform the recent approaches on their own datasets, while requiring a smaller memory footprint and runtime. We thus offer a viable solution for automating image enhancement and photo cleanup operations.
* For more info visit http://yaksoy.github.io/realisticEditing/
BEVControl: Accurately Controlling Street-view Elements with Multi-perspective Consistency via BEV Sketch Layout
Aug 03, 2023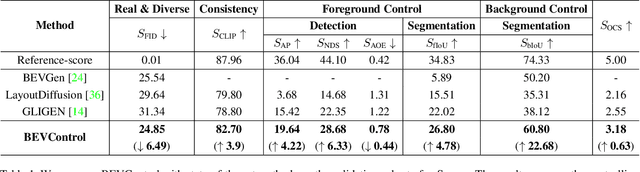
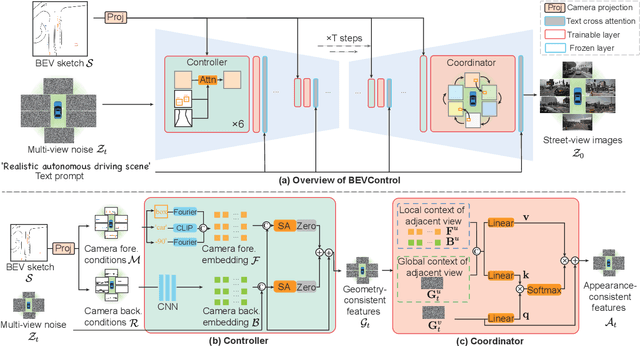
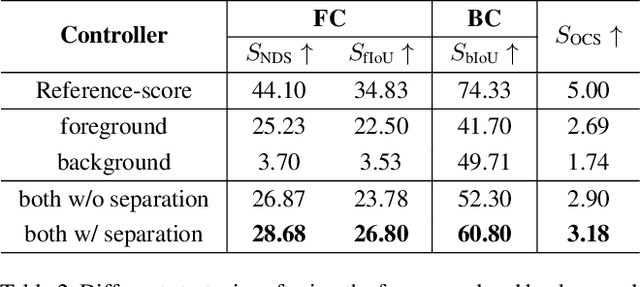
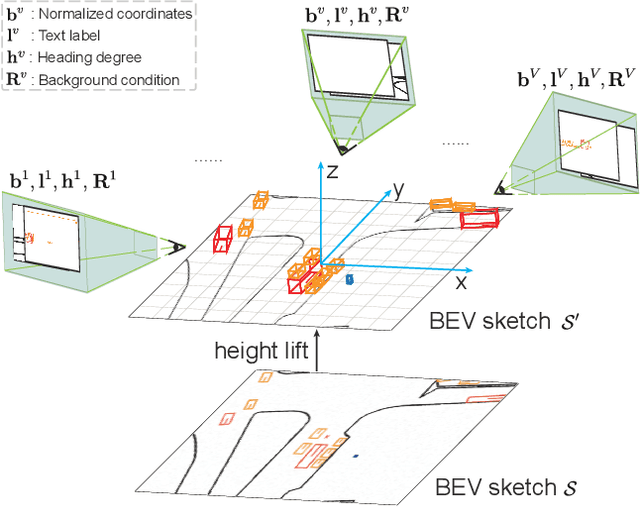
Using synthesized images to boost the performance of perception models is a long-standing research challenge in computer vision. It becomes more eminent in visual-centric autonomous driving systems with multi-view cameras as some long-tail scenarios can never be collected. Guided by the BEV segmentation layouts, the existing generative networks seem to synthesize photo-realistic street-view images when evaluated solely on scene-level metrics. However, once zoom-in, they usually fail to produce accurate foreground and background details such as heading. To this end, we propose a two-stage generative method, dubbed BEVControl, that can generate accurate foreground and background contents. In contrast to segmentation-like input, it also supports sketch style input, which is more flexible for humans to edit. In addition, we propose a comprehensive multi-level evaluation protocol to fairly compare the quality of the generated scene, foreground object, and background geometry. Our extensive experiments show that our BEVControl surpasses the state-of-the-art method, BEVGen, by a significant margin, from 5.89 to 26.80 on foreground segmentation mIoU. In addition, we show that using images generated by BEVControl to train the downstream perception model, it achieves on average 1.29 improvement in NDS score.
PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization
Jul 27, 2023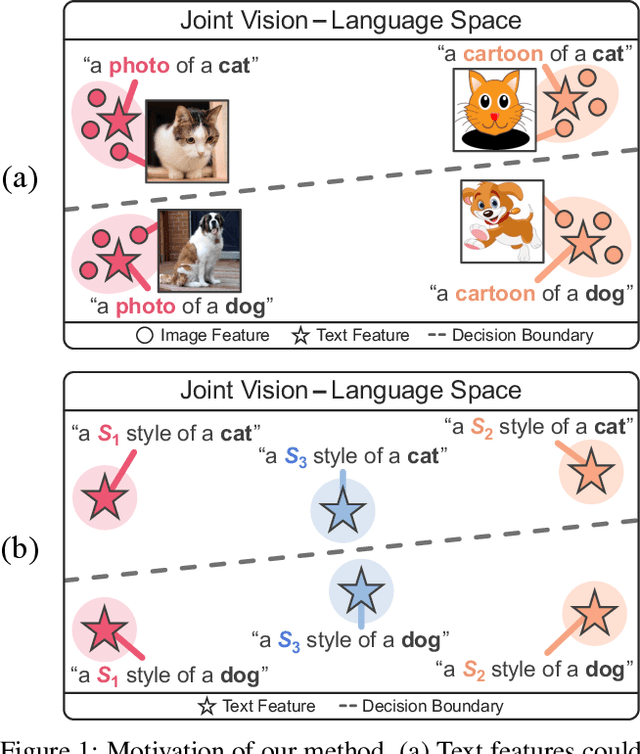
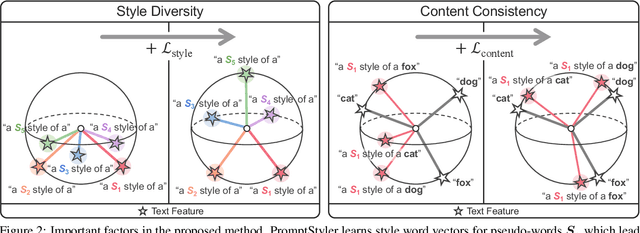
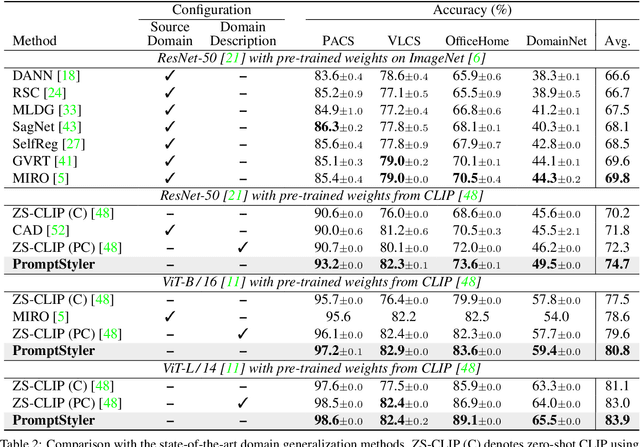
In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Inspired by this, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. Our method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, although it does not require any images and takes just ~30 minutes for training using a single GPU.
Car-Driver Drowsiness Assessment through 1D Temporal Convolutional Networks
Jul 27, 2023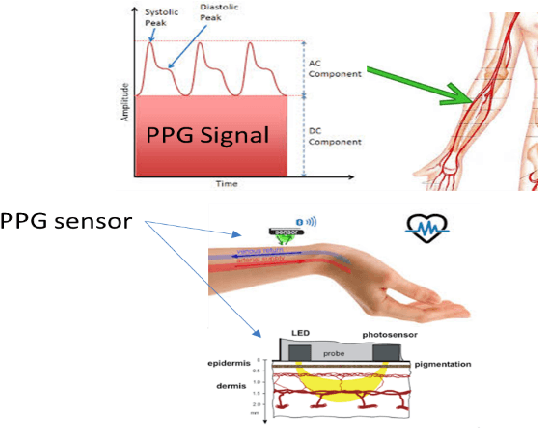
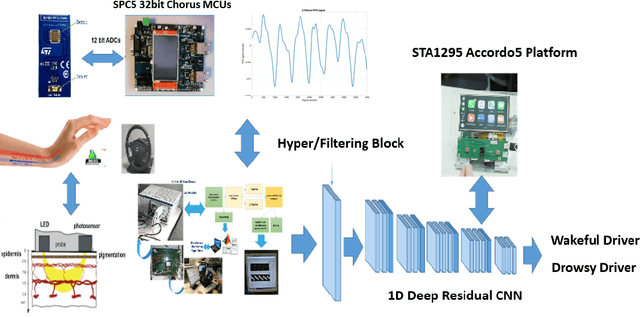
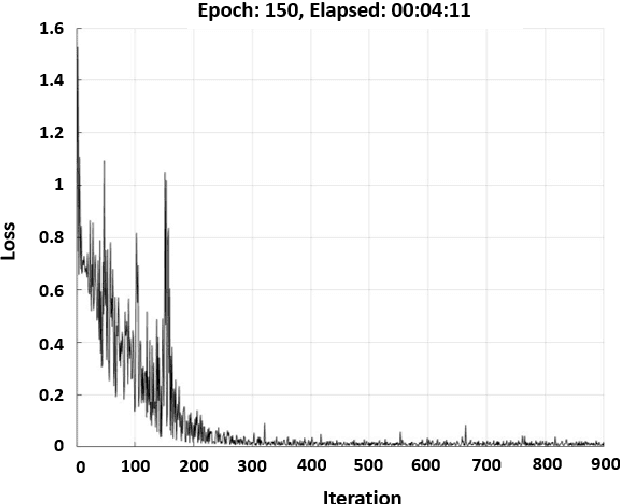
Recently, the scientific progress of Advanced Driver Assistance System solutions (ADAS) has played a key role in enhancing the overall safety of driving. ADAS technology enables active control of vehicles to prevent potentially risky situations. An important aspect that researchers have focused on is the analysis of the driver attention level, as recent reports confirmed a rising number of accidents caused by drowsiness or lack of attentiveness. To address this issue, various studies have suggested monitoring the driver physiological state, as there exists a well-established connection between the Autonomic Nervous System (ANS) and the level of attention. For our study, we designed an innovative bio-sensor comprising near-infrared LED emitters and photo-detectors, specifically a Silicon PhotoMultiplier device. This allowed us to assess the driver physiological status by analyzing the associated PhotoPlethysmography (PPG) signal.Furthermore, we developed an embedded time-domain hyper-filtering technique in conjunction with a 1D Temporal Convolutional architecture that embdes a progressive dilation setup. This integrated system enables near real-time classification of driver drowsiness, yielding remarkable accuracy levels of approximately 96%.
Pegasus Simulator: An Isaac Sim Framework for Multiple Aerial Vehicles Simulation
Jul 11, 2023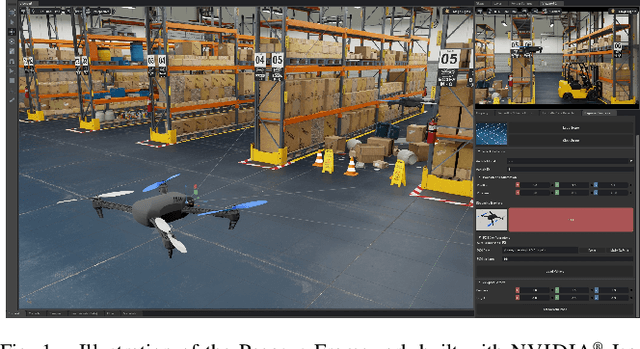
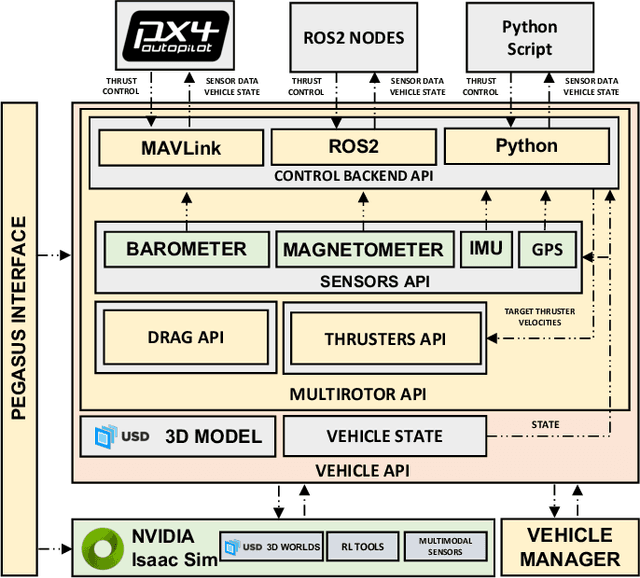
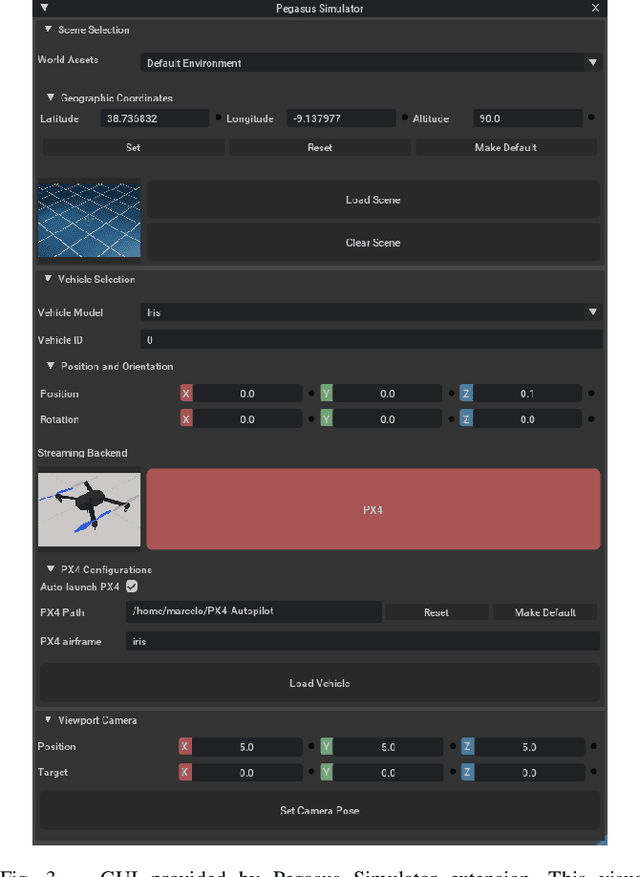
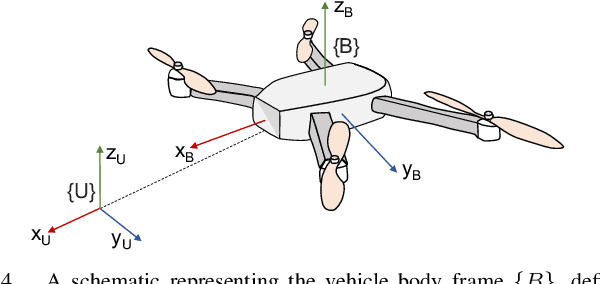
Developing and testing novel control and motion planning algorithms for aerial vehicles can be a challenging task, with the robotics community relying more than ever on 3D simulation technologies to evaluate the performance of new algorithms in a variety of conditions and environments. In this work, we introduce the Pegasus Simulator, a modular framework implemented as an NVIDIA Isaac Sim extension that enables real-time simulation of multiple multirotor vehicles in photo-realistic environments, while providing out-of-the-box integration with the widely adopted PX4-Autopilot and ROS2 through its modular implementation and intuitive graphical user interface. To demonstrate some of its capabilities, a nonlinear controller was implemented and simulation results for two drones performing aggressive flight maneuvers are presented. Code and documentation for this framework are also provided as supplementary material.
Scaling Data Generation in Vision-and-Language Navigation
Jul 28, 2023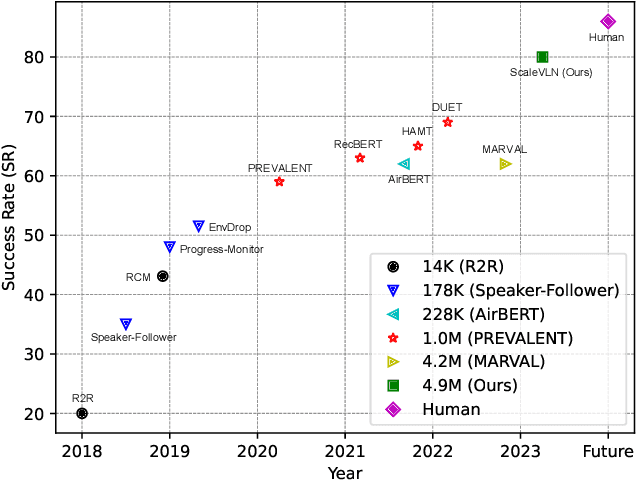
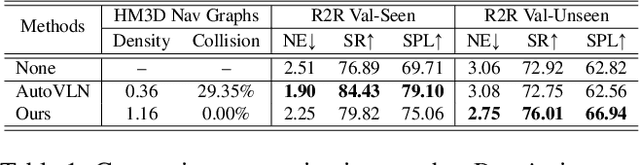
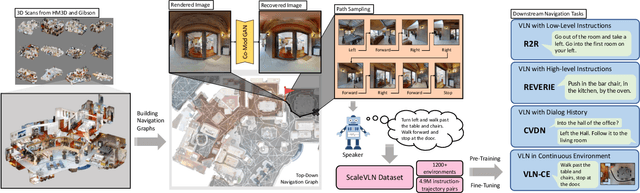
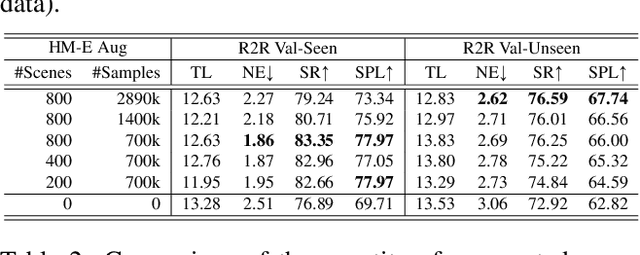
Recent research in language-guided visual navigation has demonstrated a significant demand for the diversity of traversable environments and the quantity of supervision for training generalizable agents. To tackle the common data scarcity issue in existing vision-and-language navigation datasets, we propose an effective paradigm for generating large-scale data for learning, which applies 1200+ photo-realistic environments from HM3D and Gibson datasets and synthesizes 4.9 million instruction trajectory pairs using fully-accessible resources on the web. Importantly, we investigate the influence of each component in this paradigm on the agent's performance and study how to adequately apply the augmented data to pre-train and fine-tune an agent. Thanks to our large-scale dataset, the performance of an existing agent can be pushed up (+11% absolute with regard to previous SoTA) to a significantly new best of 80% single-run success rate on the R2R test split by simple imitation learning. The long-lasting generalization gap between navigating in seen and unseen environments is also reduced to less than 1% (versus 8% in the previous best method). Moreover, our paradigm also facilitates different models to achieve new state-of-the-art navigation results on CVDN, REVERIE, and R2R in continuous environments.