 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Beyond Photo Realism for Domain Adaptation from Synthetic Data
Sep 04, 2019

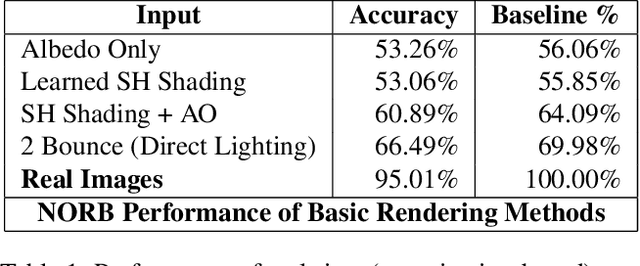
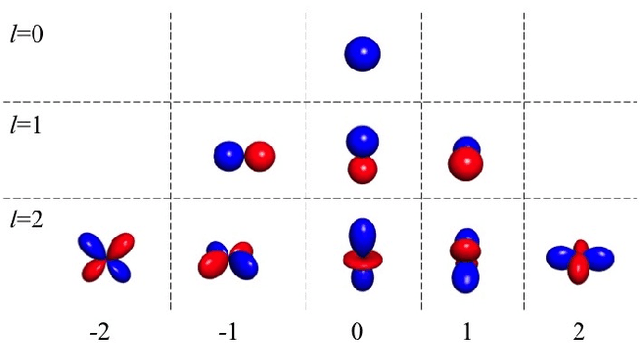
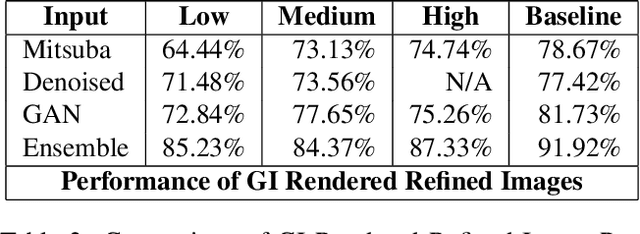
As synthetic imagery is used more frequently in training deep models, it is important to understand how different synthesis techniques impact the performance of such models. In this work, we perform a thorough evaluation of the effectiveness of several different synthesis techniques and their impact on the complexity of classifier domain adaptation to the "real" underlying data distribution that they seek to replicate. In addition, we propose a novel learned synthesis technique to better train classifier models than state-of-the-art offline graphical methods, while using significantly less computational resources. We accomplish this by learning a generative model to perform shading of synthetic geometry conditioned on a "g-buffer" representation of the scene to render, as well as a low sample Monte Carlo rendered image. The major contributions are (i) a dataset that allows comparison of real and synthetic versions of the same scene, (ii) an augmented data representation that boosts the stability of learning and improves the datasets accuracy, (iii) three different partially differentiable rendering techniques where lighting, denoising and shading are learned, and (iv) we improve a state of the art generative adversarial network (GAN) approach by using an ensemble of trained models to generate datasets that approach the performance of training on real data and surpass the performance of the full global illumination rendering.
Photo-Sketching: Inferring Contour Drawings from Images
Jan 02, 2019

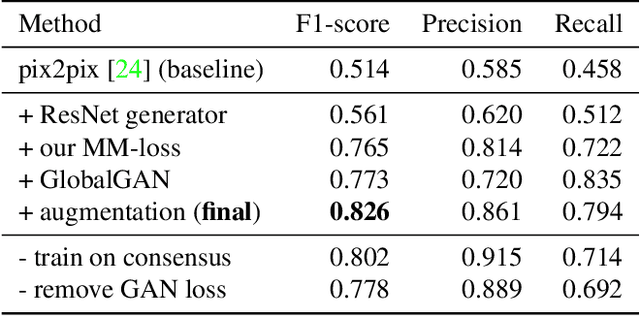

Edges, boundaries and contours are important subjects of study in both computer graphics and computer vision. On one hand, they are the 2D elements that convey 3D shapes, on the other hand, they are indicative of occlusion events and thus separation of objects or semantic concepts. In this paper, we aim to generate contour drawings, boundary-like drawings that capture the outline of the visual scene. Prior art often cast this problem as boundary detection. However, the set of visual cues presented in the boundary detection output are different from the ones in contour drawings, and also the artistic style is ignored. We address these issues by collecting a new dataset of contour drawings and proposing a learning-based method that resolves diversity in the annotation and, unlike boundary detectors, can work with imperfect alignment of the annotation and the actual ground truth. Our method surpasses previous methods quantitatively and qualitatively. Surprisingly, when our model fine-tunes on BSDS500, we achieve the state-of-the-art performance in salient boundary detection, suggesting contour drawing might be a scalable alternative to boundary annotation, which at the same time is easier and more interesting for annotators to draw.
Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
Jun 21, 2021


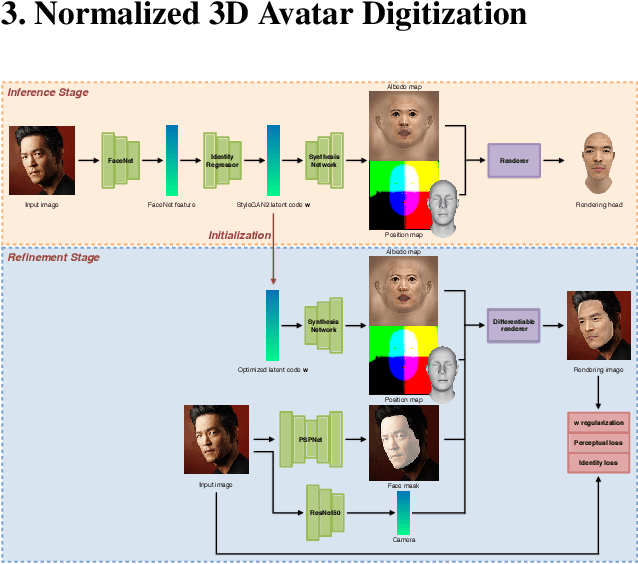
We introduce a highly robust GAN-based framework for digitizing a normalized 3D avatar of a person from a single unconstrained photo. While the input image can be of a smiling person or taken in extreme lighting conditions, our method can reliably produce a high-quality textured model of a person's face in neutral expression and skin textures under diffuse lighting condition. Cutting-edge 3D face reconstruction methods use non-linear morphable face models combined with GAN-based decoders to capture the likeness and details of a person but fail to produce neutral head models with unshaded albedo textures which is critical for creating relightable and animation-friendly avatars for integration in virtual environments. The key challenges for existing methods to work is the lack of training and ground truth data containing normalized 3D faces. We propose a two-stage approach to address this problem. First, we adopt a highly robust normalized 3D face generator by embedding a non-linear morphable face model into a StyleGAN2 network. This allows us to generate detailed but normalized facial assets. This inference is then followed by a perceptual refinement step that uses the generated assets as regularization to cope with the limited available training samples of normalized faces. We further introduce a Normalized Face Dataset, which consists of a combination photogrammetry scans, carefully selected photographs, and generated fake people with neutral expressions in diffuse lighting conditions. While our prepared dataset contains two orders of magnitude less subjects than cutting edge GAN-based 3D facial reconstruction methods, we show that it is possible to produce high-quality normalized face models for very challenging unconstrained input images, and demonstrate superior performance to the current state-of-the-art.
An Image Forensic Technique Based on JPEG Ghosts
Jun 19, 2021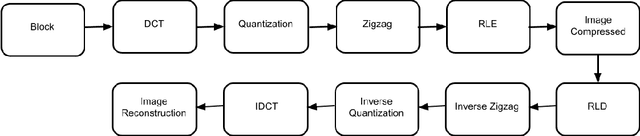
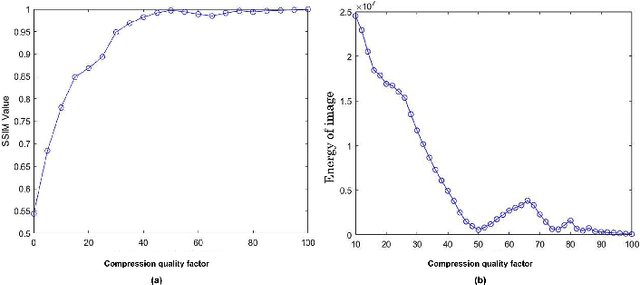


The unprecedented growth in the easy availability of photo-editing tools has endangered the power of digital images.An image was supposed to be worth more than a thousand words,but now this can be said only if it can be authenticated orthe integrity of the image can be proved to be intact. In thispaper, we propose a digital image forensic technique for JPEG images. It can detect any forgery in the image if the forged portion called a ghost image is having a compression quality different from that of the cover image. It is based on resaving the JPEG image at different JPEG qualities, and the detection of the forged portion is maximum when it is saved at the same JPEG quality as the cover image. Also, we can precisely predictthe JPEG quality of the cover image by analyzing the similarity using Structural Similarity Index Measure (SSIM) or the energyof the images. The first maxima in SSIM or the first minima inenergy correspond to the cover image JPEG quality. We created adataset for varying JPEG compression qualities of the ghost and the cover images and validated the scalability of the experimental results.We also, experimented with varied attack scenarios, e.g. high-quality ghost image embedded in low quality of cover image,low-quality ghost image embedded in high-quality of cover image,and ghost image and cover image both at the same quality.The proposed method is able to localize the tampered portions accurately even for forgeries as small as 10x10 sized pixel blocks.Our technique is also robust against other attack scenarios like copy-move forgery, inserting text into image, rescaling (zoom-out/zoom-in) ghost image and then pasting on cover image.
Preventing Personal Data Theft in Images with Adversarial ML
Oct 20, 2020
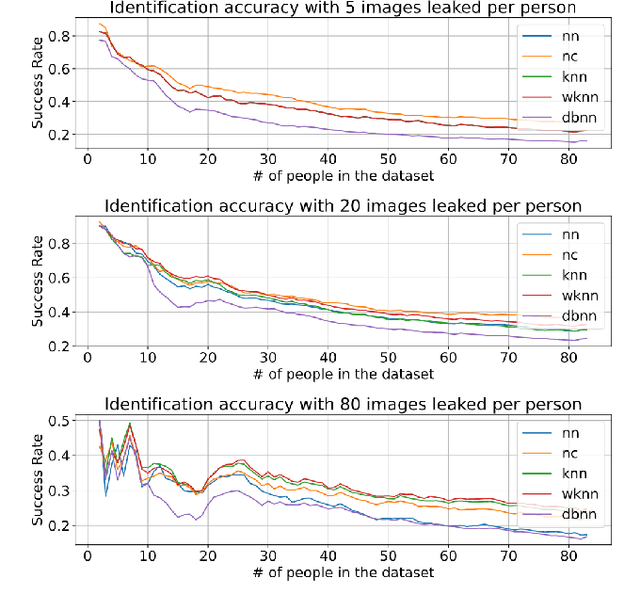
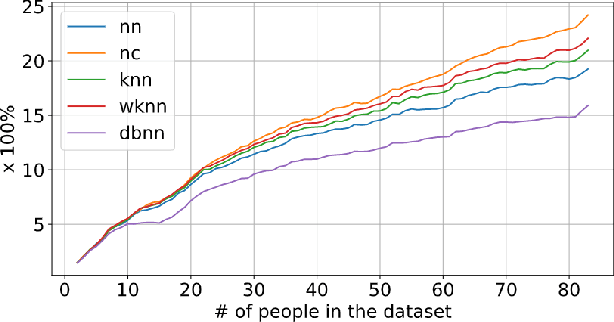

Facial recognition tools are becoming exceptionally accurate in identifying people from images. However, this comes at the cost of privacy for users of online services with photo management (e.g. social media platforms). Particularly troubling is the ability to leverage unsupervised learning to recognize faces even when the user has not labeled their images. This is made simpler by modern facial recognition tools, such as FaceNet, that use encoders to generate low dimensional embeddings that can be clustered to learn previously unknown faces. In this paper, we propose a strategy to generate non-invasive noise masks to apply to facial images for a newly introduced user, yielding adversarial examples and preventing the formation of identifiable clusters in the embedding space. We demonstrate the effectiveness of our method by showing that various classification and clustering methods cannot reliably cluster the adversarial examples we generate.
Automatic Image Stylization Using Deep Fully Convolutional Networks
Nov 27, 2018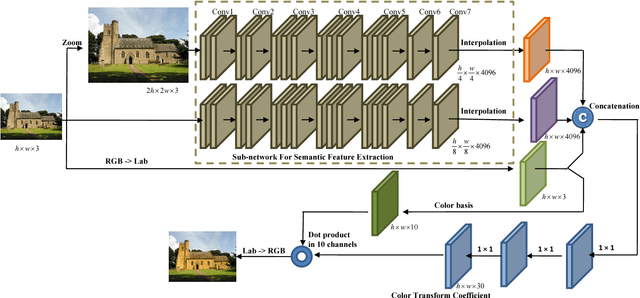
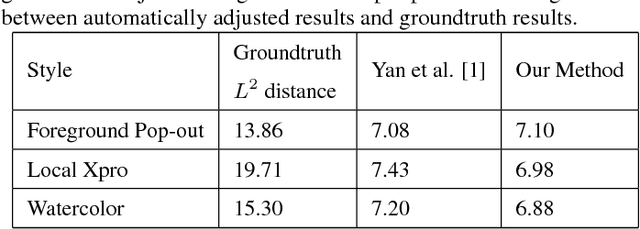


Color and tone stylization strives to enhance unique themes with artistic color and tone adjustments. It has a broad range of applications from professional image postprocessing to photo sharing over social networks. Mainstream photo enhancement softwares provide users with predefined styles, which are often hand-crafted through a trial-and-error process. Such photo adjustment tools lack a semantic understanding of image contents and the resulting global color transform limits the range of artistic styles it can represent. On the other hand, stylistic enhancement needs to apply distinct adjustments to various semantic regions. Such an ability enables a broader range of visual styles. In this paper, we propose a novel deep learning architecture for automatic image stylization, which learns local enhancement styles from image pairs. Our deep learning architecture is an end-to-end deep fully convolutional network performing semantics-aware feature extraction as well as automatic image adjustment prediction. Image stylization can be efficiently accomplished with a single forward pass through our deep network. Experiments on existing datasets for image stylization demonstrate the effectiveness of our deep learning architecture.
MUSE: Illustrating Textual Attributes by Portrait Generation
Nov 09, 2020
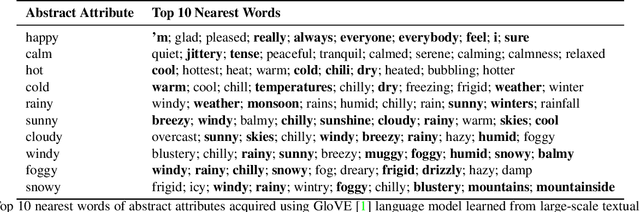

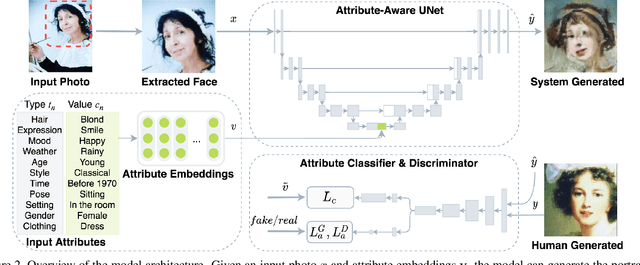
We propose a novel approach, MUSE, to illustrate textual attributes visually via portrait generation. MUSE takes a set of attributes written in text, in addition to facial features extracted from a photo of the subject as input. We propose 11 attribute types to represent inspirations from a subject's profile, emotion, story, and environment. We propose a novel stacked neural network architecture by extending an image-to-image generative model to accept textual attributes. Experiments show that our approach significantly outperforms several state-of-the-art methods without using textual attributes, with Inception Score score increased by 6% and Fr\'echet Inception Distance (FID) score decreased by 11%, respectively. We also propose a new attribute reconstruction metric to evaluate whether the generated portraits preserve the subject's attributes. Experiments show that our approach can accurately illustrate 78% textual attributes, which also help MUSE capture the subject in a more creative and expressive way.
Compressive lensless endoscopy with partial speckle scanning
Apr 22, 2021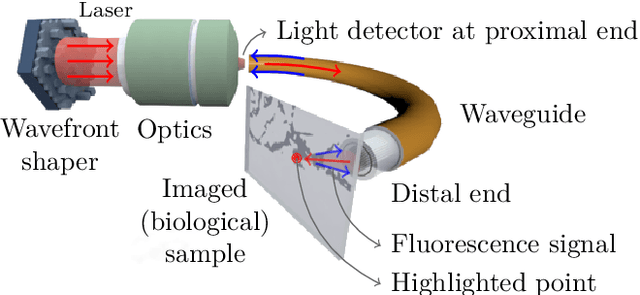
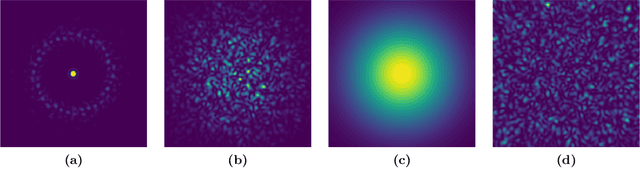
The lensless endoscope (LE) is a promising device to acquire in vivo images at a cellular scale. The tiny size of the probe enables a deep exploration of the tissues. Lensless endoscopy with a multicore fiber (MCF) commonly uses a spatial light modulator (SLM) to coherently combine, at the output of the MCF, few hundreds of beamlets into a focus spot. This spot is subsequently scanned across the sample to generate a fluorescent image. We propose here a novel scanning scheme, partial speckle scanning (PSS), inspired by compressive sensing theory, that avoids the use of an SLM to perform fluorescent imaging in LE with reduced acquisition time. Such a strategy avoids photo-bleaching while keeping high reconstruction quality. We develop our approach on two key properties of the LE: (i) the ability to easily generate speckles, and (ii) the memory effect in MCF that allows to use fast scan mirrors to shift light patterns. First, we show that speckles are sub-exponential random fields. Despite their granular structure, an appropriate choice of the reconstruction parameters makes them good candidates to build efficient sensing matrices. Then, we numerically validate our approach and apply it on experimental data. The proposed sensing technique outperforms conventional raster scanning: higher reconstruction quality is achieved with far fewer observations. For a fixed reconstruction quality, our speckle scanning approach is faster than compressive sensing schemes which require to change the speckle pattern for each observation.
AVA: Adversarial Vignetting Attack against Visual Recognition
May 12, 2021
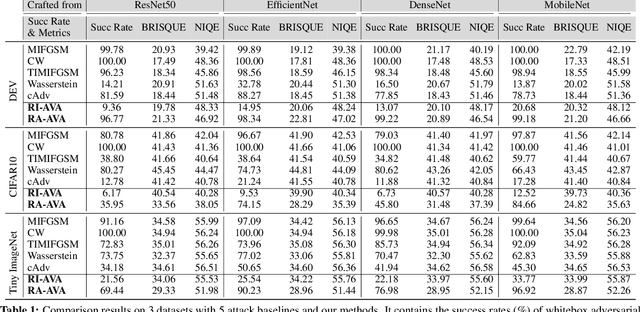
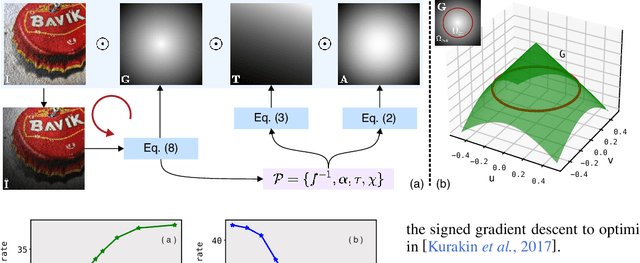
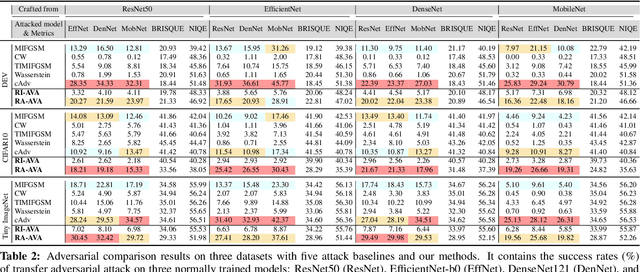
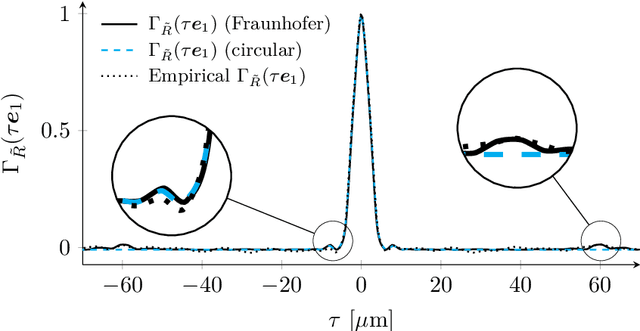
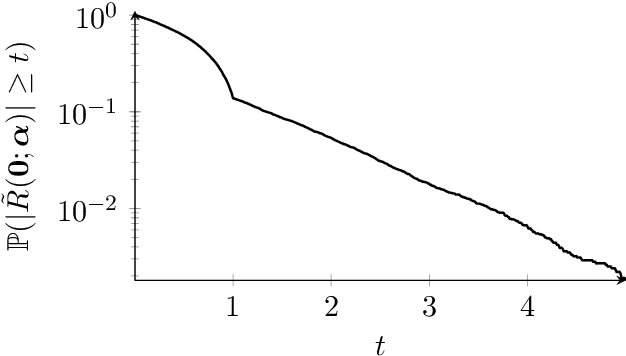
Vignetting is an inherited imaging phenomenon within almost all optical systems, showing as a radial intensity darkening toward the corners of an image. Since it is a common effect for photography and usually appears as a slight intensity variation, people usually regard it as a part of a photo and would not even want to post-process it. Due to this natural advantage, in this work, we study vignetting from a new viewpoint, i.e., adversarial vignetting attack (AVA), which aims to embed intentionally misleading information into vignetting and produce a natural adversarial example without noise patterns. This example can fool the state-of-the-art deep convolutional neural networks (CNNs) but is imperceptible to humans. To this end, we first propose the radial-isotropic adversarial vignetting attack (RI-AVA) based on the physical model of vignetting, where the physical parameters (e.g., illumination factor and focal length) are tuned through the guidance of target CNN models. To achieve higher transferability across different CNNs, we further propose radial-anisotropic adversarial vignetting attack (RA-AVA) by allowing the effective regions of vignetting to be radial-anisotropic and shape-free. Moreover, we propose the geometry-aware level-set optimization method to solve the adversarial vignetting regions and physical parameters jointly. We validate the proposed methods on three popular datasets, i.e., DEV, CIFAR10, and Tiny ImageNet, by attacking four CNNs, e.g., ResNet50, EfficientNet-B0, DenseNet121, and MobileNet-V2, demonstrating the advantages of our methods over baseline methods on both transferability and image quality.
Room-Across-Room: Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding
Oct 15, 2020
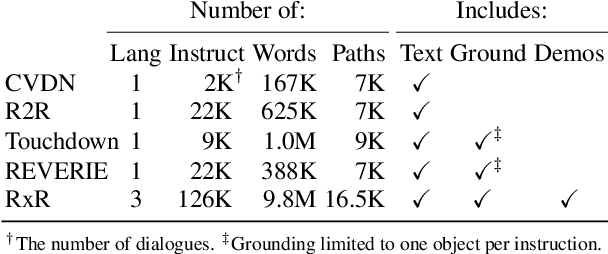
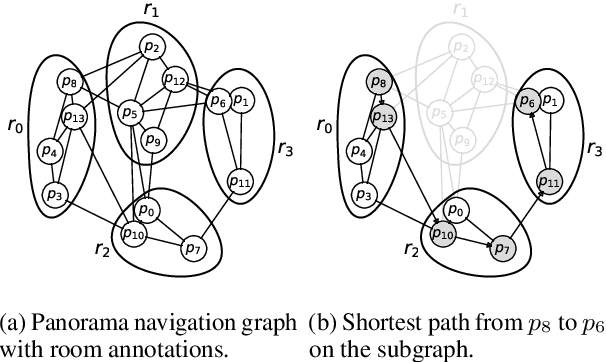
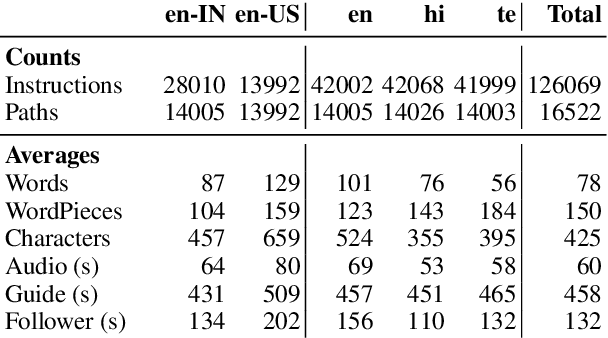
We introduce Room-Across-Room (RxR), a new Vision-and-Language Navigation (VLN) dataset. RxR is multilingual (English, Hindi, and Telugu) and larger (more paths and instructions) than other VLN datasets. It emphasizes the role of language in VLN by addressing known biases in paths and eliciting more references to visible entities. Furthermore, each word in an instruction is time-aligned to the virtual poses of instruction creators and validators. We establish baseline scores for monolingual and multilingual settings and multitask learning when including Room-to-Room annotations. We also provide results for a model that learns from synchronized pose traces by focusing only on portions of the panorama attended to in human demonstrations. The size, scope and detail of RxR dramatically expands the frontier for research on embodied language agents in simulated, photo-realistic environments.