 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Dixit: Interactive Visual Storytelling via Term Manipulation
Mar 11, 2019
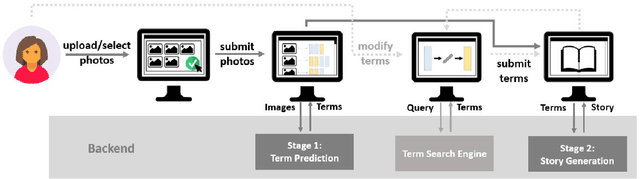

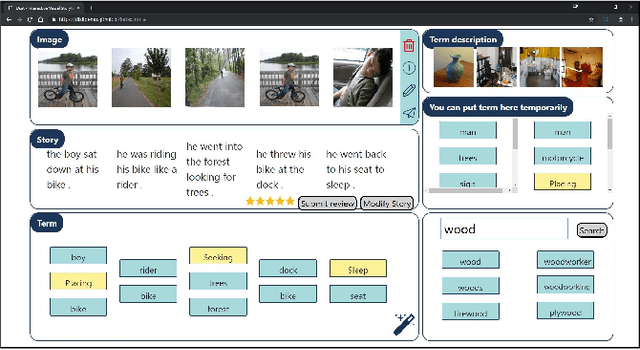
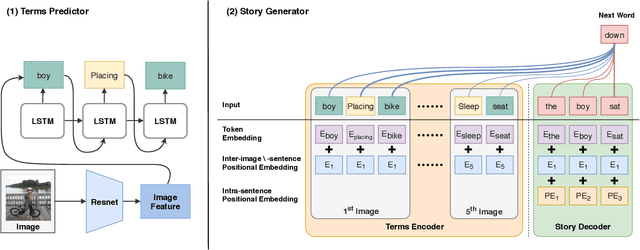
In this paper, we introduce Dixit, an interactive visual storytelling system that the user interacts with iteratively to compose a short story for a photo sequence. The user initiates the process by uploading a sequence of photos. Dixit first extracts text terms from each photo which describe the objects (e.g., boy, bike) or actions (e.g., sleep) in the photo, and then allows the user to add new terms or remove existing terms. Dixit then generates a short story based on these terms. Behind the scenes, Dixit uses an LSTM-based model trained on image caption data and FrameNet to distill terms from each image and utilizes a transformer decoder to compose a context-coherent story. Users change images or terms iteratively with Dixit to create the most ideal story. Dixit also allows users to manually edit and rate stories. The proposed procedure opens up possibilities for interpretable and controllable visual storytelling, allowing users to understand the story formation rationale and to intervene in the generation process.
Learning Semantic Person Image Generation by Region-Adaptive Normalization
Apr 14, 2021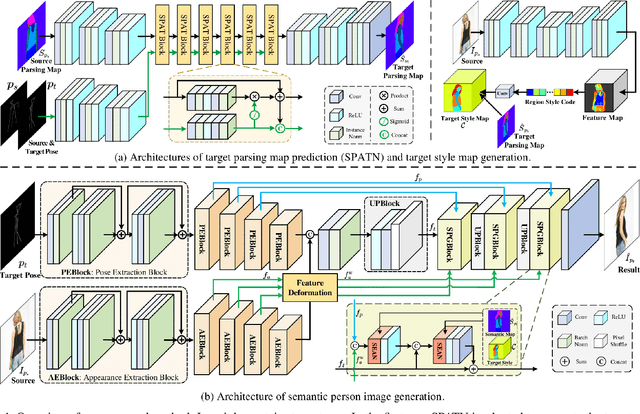
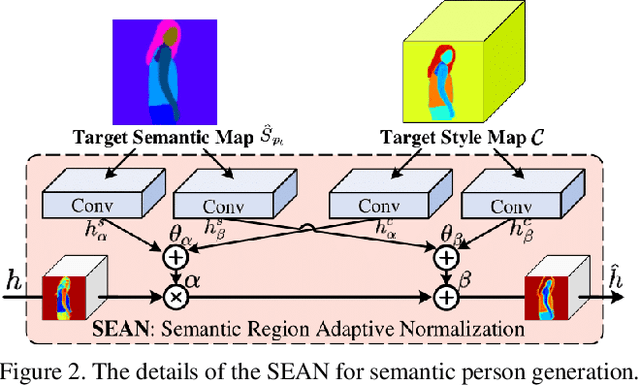

Human pose transfer has received great attention due to its wide applications, yet is still a challenging task that is not well solved. Recent works have achieved great success to transfer the person image from the source to the target pose. However, most of them cannot well capture the semantic appearance, resulting in inconsistent and less realistic textures on the reconstructed results. To address this issue, we propose a new two-stage framework to handle the pose and appearance translation. In the first stage, we predict the target semantic parsing maps to eliminate the difficulties of pose transfer and further benefit the latter translation of per-region appearance style. In the second one, with the predicted target semantic maps, we suggest a new person image generation method by incorporating the region-adaptive normalization, in which it takes the per-region styles to guide the target appearance generation. Extensive experiments show that our proposed SPGNet can generate more semantic, consistent, and photo-realistic results and perform favorably against the state of the art methods in terms of quantitative and qualitative evaluation. The source code and model are available at https://github.com/cszy98/SPGNet.git.
Active Bayesian Multi-class Mapping from Range and Semantic Segmentation Observation
Jan 06, 2021
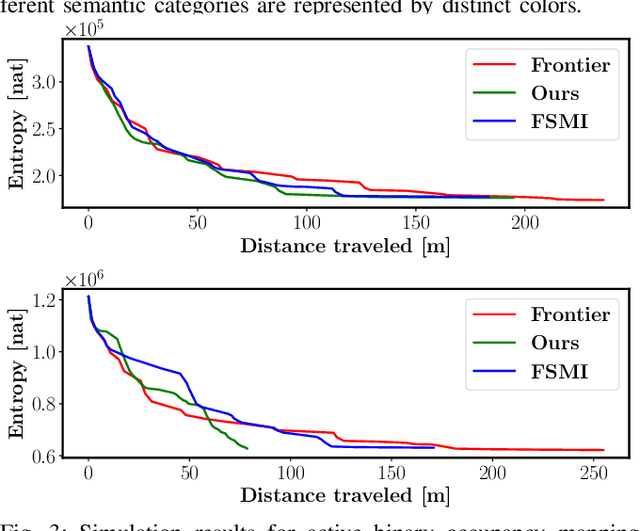
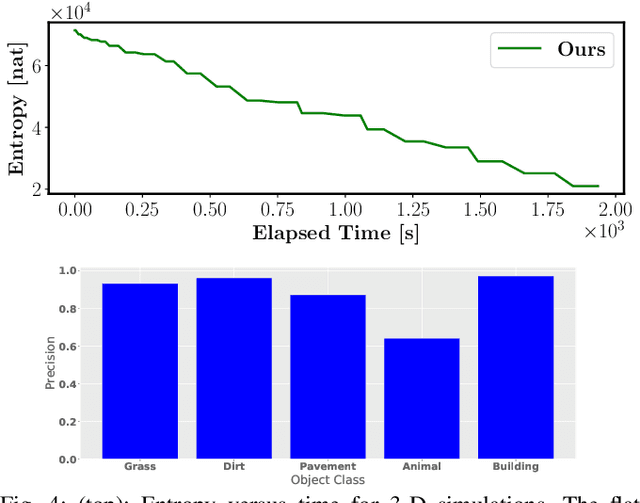
Many robot applications call for autonomous exploration and mapping of unknown and unstructured environments. Information-based exploration techniques, such as Cauchy-Schwarz quadratic mutual information (CSQMI) and fast Shannon mutual information (FSMI), have successfully achieved active binary occupancy mapping with range measurements. However, as we envision robots performing complex tasks specified with semantically meaningful objects, it is necessary to capture semantic categories in the measurements, map representation, and exploration objective. This work develops a Bayesian multi-class mapping algorithm utilizing range-category measurements. We derive a closed-form efficiently computable lower bound for the Shannon mutual information between the multi-class map and the measurements. The bound allows rapid evaluation of many potential robot trajectories for autonomous exploration and mapping. We compare our method against frontier-based and FSMI exploration and apply it in a 3-D photo-realistic simulation environment.
Estimating sex and age for forensic applications using machine learning based on facial measurements from frontal cephalometric landmarks
Aug 06, 2019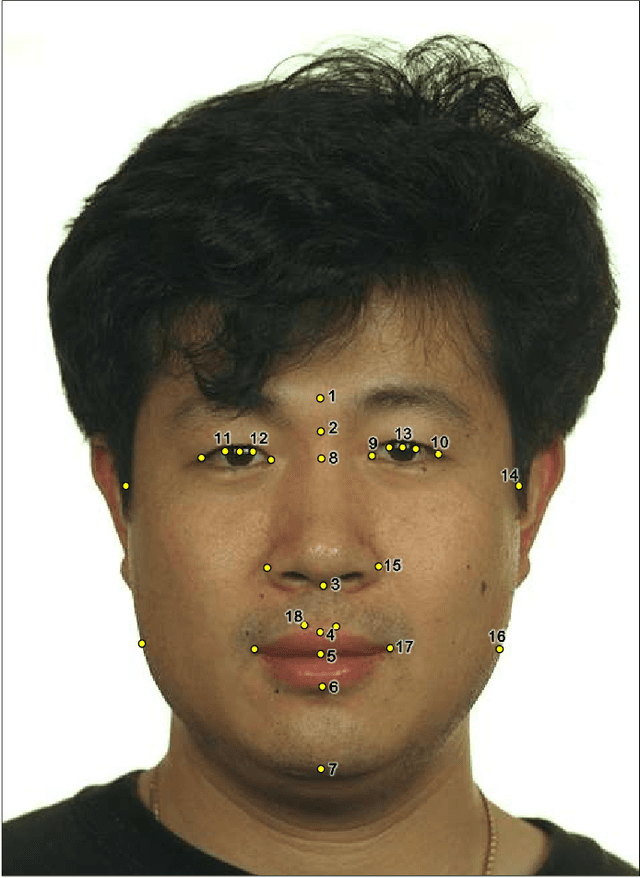
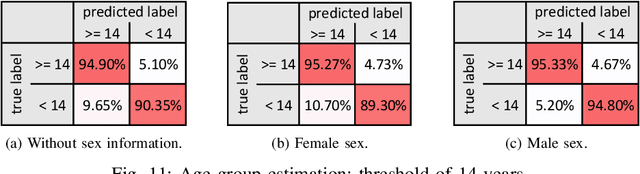
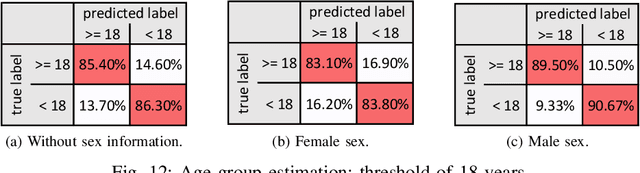
Facial analysis permits many investigations some of the most important of which are craniofacial identification, facial recognition, and age and sex estimation. In forensics, photo-anthropometry describes the study of facial growth and allows the identification of patterns in facial skull development by using a group of cephalometric landmarks to estimate anthropological information. In several areas, automation of manual procedures has achieved advantages over and similar measurement confidence as a forensic expert. This manuscript presents an approach using photo-anthropometric indexes, generated from frontal faces cephalometric landmarks, to create an artificial neural network classifier that allows the estimation of anthropological information, in this specific case age and sex. The work is focused on four tasks: i) sex estimation over ages from 5 to 22 years old, evaluating the interference of age on sex estimation; ii) age estimation from photo-anthropometric indexes for four age intervals (1 year, 2 years, 4 years and 5 years); iii) age group estimation for thresholds of over 14 and over 18 years old; and; iv) the provision of a new data set, available for academic purposes only, with a large and complete set of facial photo-anthropometric points marked and checked by forensic experts, measured from over 18,000 faces of individuals from Brazil over the last 4 years. The proposed classifier obtained significant results, using this new data set, for the sex estimation of individuals over 14 years old, achieving accuracy values greater than 0.85 by the F_1 measure. For age estimation, the accuracy results are 0.72 for measure with an age interval of 5 years. For the age group estimation, the measures of accuracy are greater than 0.93 and 0.83 for thresholds of 14 and 18 years, respectively.
cGANs for Cartoon to Real-life Images
Jan 24, 2021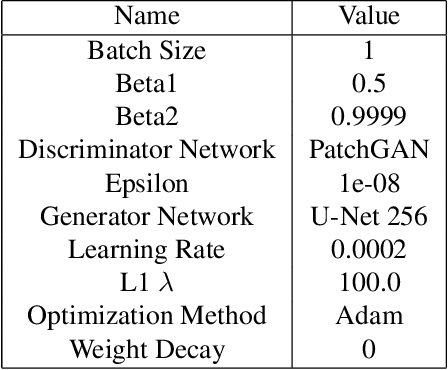


The image-to-image translation is a learning task to establish a visual mapping between an input and output image. The task has several variations differentiated based on the purpose of the translation, such as synthetic to real translation, photo to caricature translation, and many others. The problem has been tackled using different approaches, either through traditional computer vision methods, as well as deep learning approaches in recent trends. One approach currently deemed popular and effective is using the conditional generative adversarial network, also known shortly as cGAN. It is adapted to perform image-to-image translation tasks with typically two networks: a generator and a discriminator. This project aims to evaluate the robustness of the Pix2Pix model by applying the Pix2Pix model to datasets consisting of cartoonized images. Using the Pix2Pix model, it should be possible to train the network to generate real-life images from the cartoonized images.
Improving the Authentication with Built-in Camera Protocol Using Built-in Motion Sensors: A Deep Learning Solution
Jul 27, 2021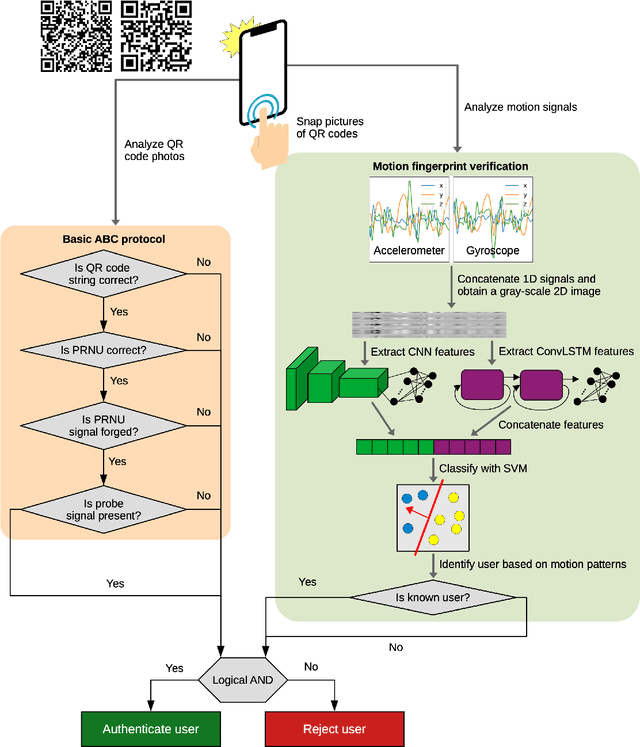
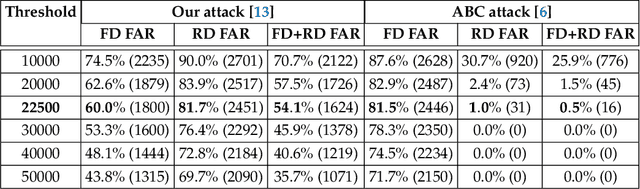
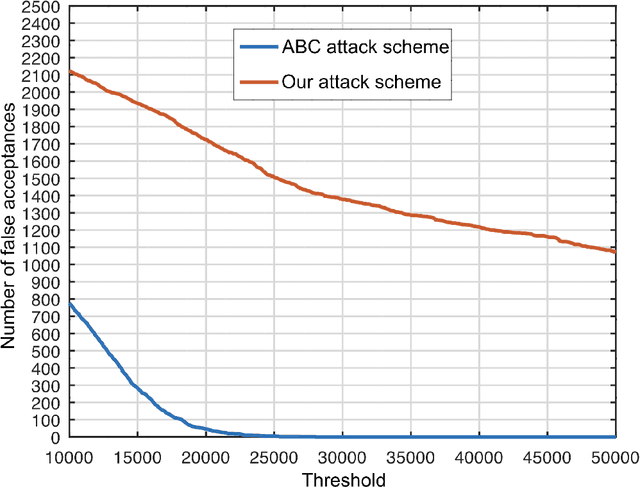
We propose an enhanced version of the Authentication with Built-in Camera (ABC) protocol by employing a deep learning solution based on built-in motion sensors. The standard ABC protocol identifies mobile devices based on the photo-response non-uniformity (PRNU) of the camera sensor, while also considering QR-code-based meta-information. During authentication, the user is required to take two photos that contain two QR codes presented on a screen. The presented QR code images also contain a unique probe signal, similar to a camera fingerprint, generated by the protocol. During verification, the server computes the fingerprint of the received photos and authenticates the user if (i) the probe signal is present, (ii) the metadata embedded in the QR codes is correct and (iii) the camera fingerprint is identified correctly. However, the protocol is vulnerable to forgery attacks when the attacker can compute the camera fingerprint from external photos, as shown in our preliminary work. In this context, we propose an enhancement for the ABC protocol based on motion sensor data, as an additional and passive authentication layer. Smartphones can be identified through their motion sensor data, which, unlike photos, is never posted by users on social media platforms, thus being more secure than using photographs alone. To this end, we transform motion signals into embedding vectors produced by deep neural networks, applying Support Vector Machines for the smartphone identification task. Our change to the ABC protocol results in a multi-modal protocol that lowers the false acceptance rate for the attack proposed in our previous work to a percentage as low as 0.07%.
Physical Adversarial Attack on Vehicle Detector in the Carla Simulator
Aug 07, 2020
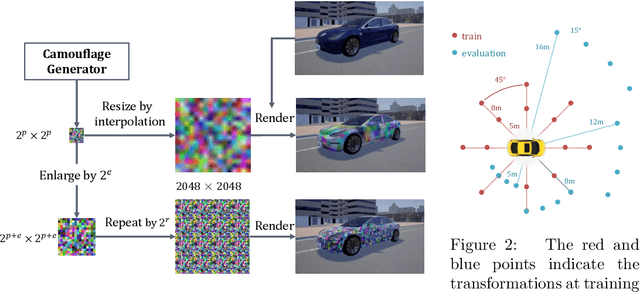
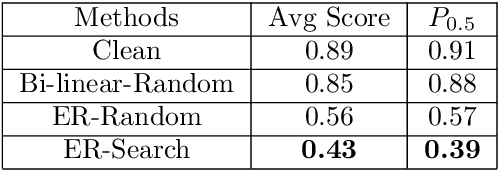
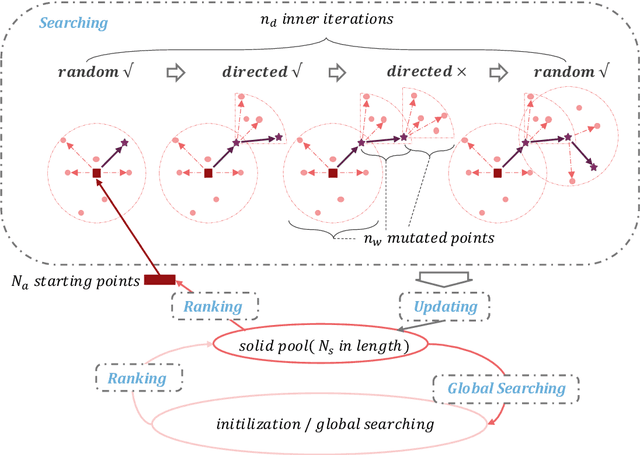
In this paper, we tackle the issue of physical adversarial examples for object detectors in the wild. Specifically, we proposed to generate adversarial patterns to be applied on vehicle surface so that it's not recognizable by detectors in the photo-realistic Carla simulator. Our approach contains two main techniques, an Enlarge-and-Repeat process and a Discrete Searching method, to craft mosaic-like adversarial vehicle textures without access to neither the model weight of the detector nor a differential rendering procedure. The experimental results demonstrate the effectiveness of our approach in the simulator.
Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation
May 07, 2021
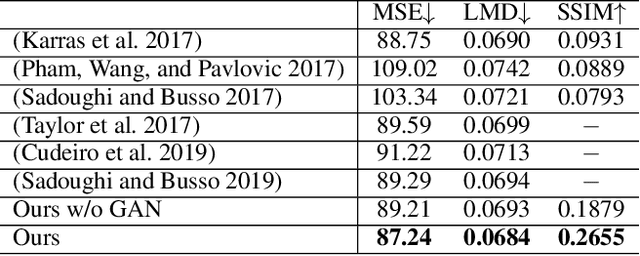
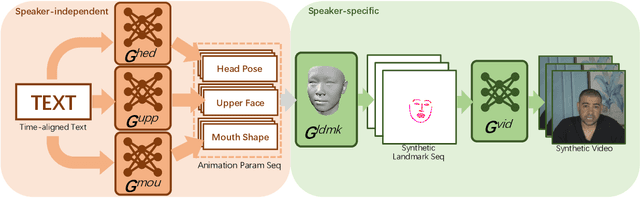
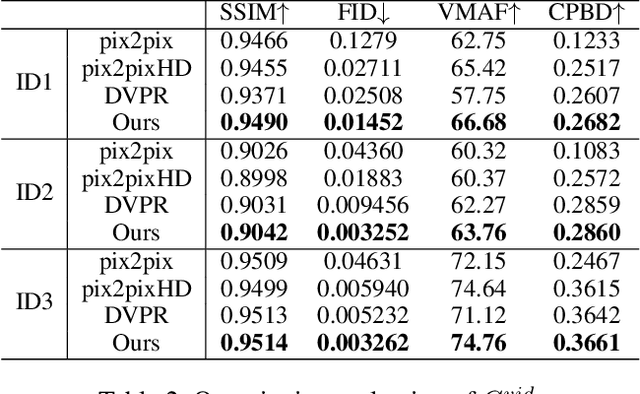
In this paper, we propose a novel text-based talking-head video generation framework that synthesizes high-fidelity facial expressions and head motions in accordance with contextual sentiments as well as speech rhythm and pauses. To be specific, our framework consists of a speaker-independent stage and a speaker-specific stage. In the speaker-independent stage, we design three parallel networks to generate animation parameters of the mouth, upper face, and head from texts, separately. In the speaker-specific stage, we present a 3D face model guided attention network to synthesize videos tailored for different individuals. It takes the animation parameters as input and exploits an attention mask to manipulate facial expression changes for the input individuals. Furthermore, to better establish authentic correspondences between visual motions (i.e., facial expression changes and head movements) and audios, we leverage a high-accuracy motion capture dataset instead of relying on long videos of specific individuals. After attaining the visual and audio correspondences, we can effectively train our network in an end-to-end fashion. Extensive experiments on qualitative and quantitative results demonstrate that our algorithm achieves high-quality photo-realistic talking-head videos including various facial expressions and head motions according to speech rhythms and outperforms the state-of-the-art.
MW-GAN: Multi-Warping GAN for Caricature Generation with Multi-Style Geometric Exaggeration
Jan 07, 2020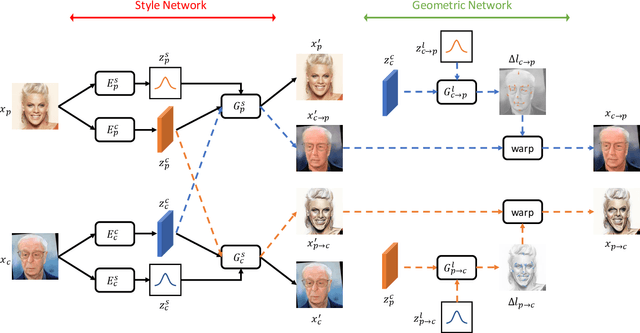
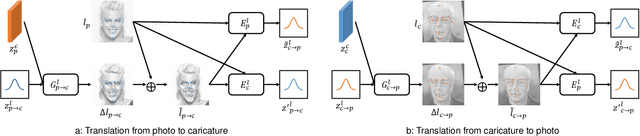
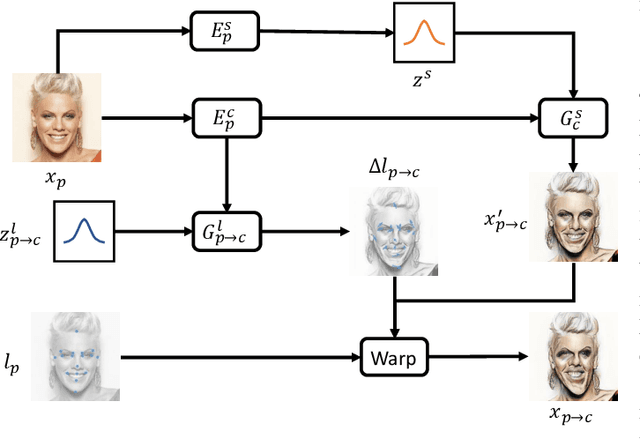

Given an input face photo, the goal of caricature generation is to produce stylized, exaggerated caricatures that share the same identity as the photo. It requires simultaneous style transfer and shape exaggeration with rich diversity, and meanwhile preserving the identity of the input. To address this challenging problem, we propose a novel framework called Multi-Warping GAN (MW-GAN), including a style network and a geometric network that are designed to conduct style transfer and geometric exaggeration respectively. We bridge the gap between the style and landmarks of an image with corresponding latent code spaces by a dual way design, so as to generate caricatures with arbitrary styles and geometric exaggeration, which can be specified either through random sampling of latent code or from a given caricature sample. Besides, we apply identity preserving loss to both image space and landmark space, leading to a great improvement in quality of generated caricatures. Experiments show that caricatures generated by MW-GAN have better quality than existing methods.