 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Authentication with Built-in Camera Protocol Using Built-in Motion Sensors: A Deep Learning Solution
Jul 27, 2021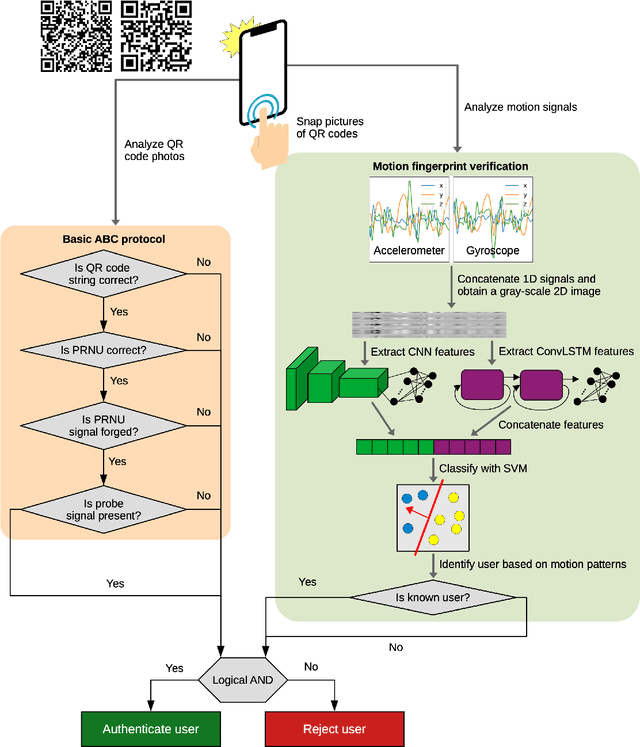
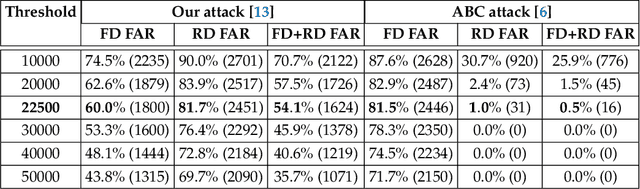
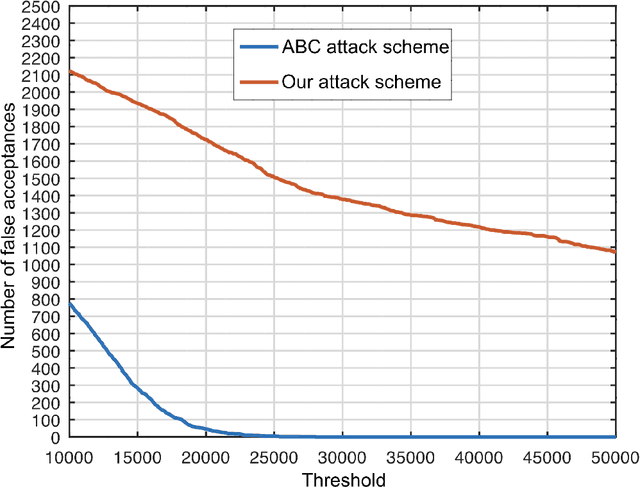
We propose an enhanced version of the Authentication with Built-in Camera (ABC) protocol by employing a deep learning solution based on built-in motion sensors. The standard ABC protocol identifies mobile devices based on the photo-response non-uniformity (PRNU) of the camera sensor, while also considering QR-code-based meta-information. During authentication, the user is required to take two photos that contain two QR codes presented on a screen. The presented QR code images also contain a unique probe signal, similar to a camera fingerprint, generated by the protocol. During verification, the server computes the fingerprint of the received photos and authenticates the user if (i) the probe signal is present, (ii) the metadata embedded in the QR codes is correct and (iii) the camera fingerprint is identified correctly. However, the protocol is vulnerable to forgery attacks when the attacker can compute the camera fingerprint from external photos, as shown in our preliminary work. In this context, we propose an enhancement for the ABC protocol based on motion sensor data, as an additional and passive authentication layer. Smartphones can be identified through their motion sensor data, which, unlike photos, is never posted by users on social media platforms, thus being more secure than using photographs alone. To this end, we transform motion signals into embedding vectors produced by deep neural networks, applying Support Vector Machines for the smartphone identification task. Our change to the ABC protocol results in a multi-modal protocol that lowers the false acceptance rate for the attack proposed in our previous work to a percentage as low as 0.07%.
Adversarial Attacks on Deep Learning Systems for User Identification based on Motion Sensors
Sep 02, 2020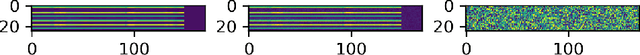
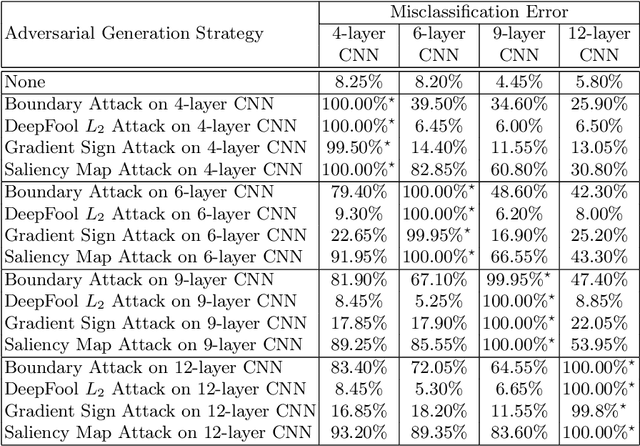
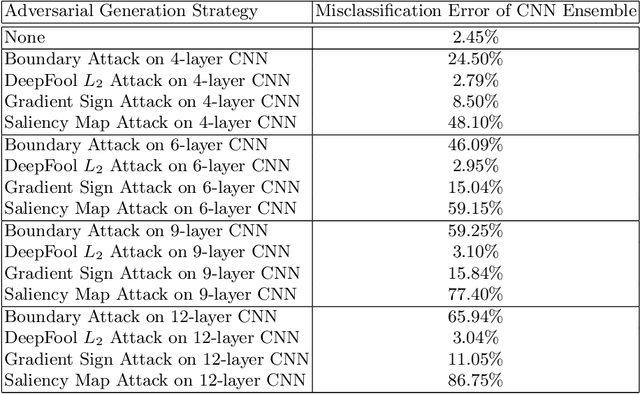
For the time being, mobile devices employ implicit authentication mechanisms, namely, unlock patterns, PINs or biometric-based systems such as fingerprint or face recognition. While these systems are prone to well-known attacks, the introduction of an explicit and unobtrusive authentication layer can greatly enhance security. In this study, we focus on deep learning methods for explicit authentication based on motion sensor signals. In this scenario, attackers could craft adversarial examples with the aim of gaining unauthorized access and even restraining a legitimate user to access his mobile device. To our knowledge, this is the first study that aims at quantifying the impact of adversarial attacks on machine learning models used for user identification based on motion sensors. To accomplish our goal, we study multiple methods for generating adversarial examples. We propose three research questions regarding the impact and the universality of adversarial examples, conducting relevant experiments in order to answer our research questions. Our empirical results demonstrate that certain adversarial example generation methods are specific to the attacked classification model, while others tend to be generic. We thus conclude that deep neural networks trained for user identification tasks based on motion sensors are subject to a high percentage of misclassification when given adversarial input.
To augment or not to augment? Data augmentation in user identification based on motion sensors
Sep 01, 2020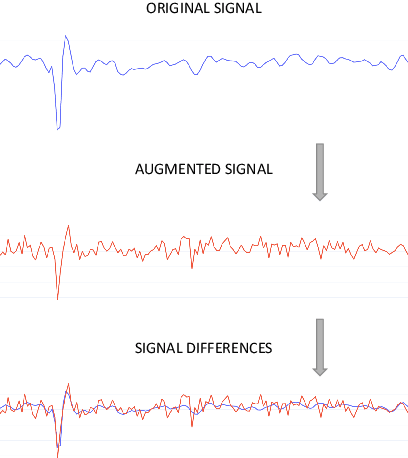
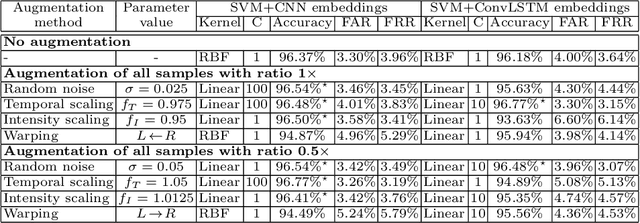
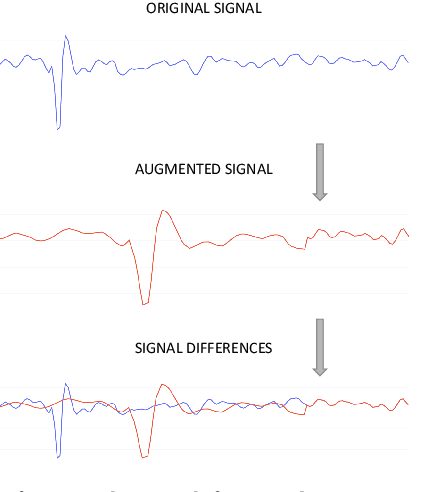
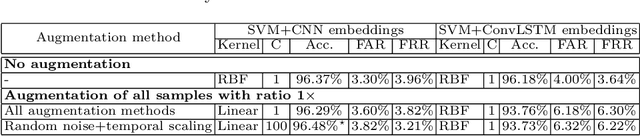
Nowadays, commonly-used authentication systems for mobile device users, e.g. password checking, face recognition or fingerprint scanning, are susceptible to various kinds of attacks. In order to prevent some of the possible attacks, these explicit authentication systems can be enhanced by considering a two-factor authentication scheme, in which the second factor is an implicit authentication system based on analyzing motion sensor data captured by accelerometers or gyroscopes. In order to avoid any additional burdens to the user, the registration process of the implicit authentication system must be performed quickly, i.e. the number of data samples collected from the user is typically small. In the context of designing a machine learning model for implicit user authentication based on motion signals, data augmentation can play an important role. In this paper, we study several data augmentation techniques in the quest of finding useful augmentation methods for motion sensor data. We propose a set of four research questions related to data augmentation in the context of few-shot user identification based on motion sensor signals. We conduct experiments on a benchmark data set, using two deep learning architectures, convolutional neural networks and Long Short-Term Memory networks, showing which and when data augmentation methods bring accuracy improvements. Interestingly, we find that data augmentation is not very helpful, most likely because the signal patterns useful to discriminate users are too sensitive to the transformations brought by certain data augmentation techniques. This result is somewhat contradictory to the common belief that data augmentation is expected to increase the accuracy of machine learning models.
A Convolutional Neural Network for User Identification based on Motion Sensors
Dec 08, 2019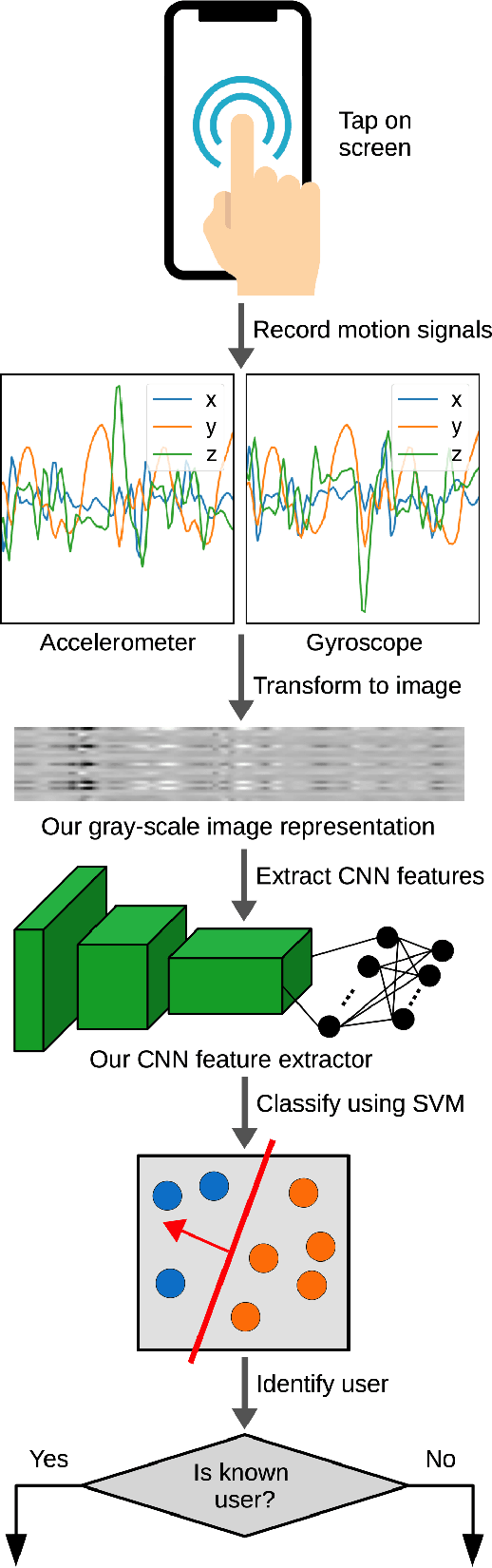
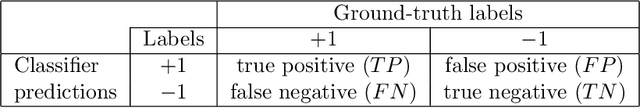

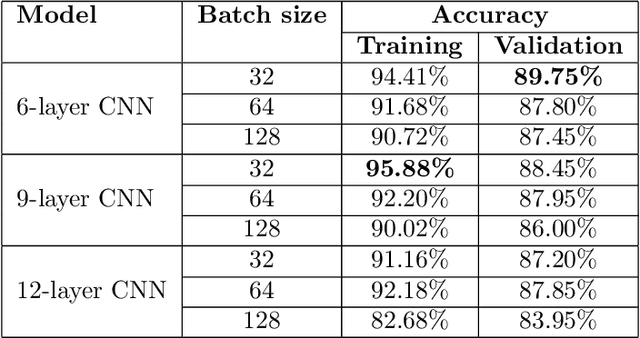
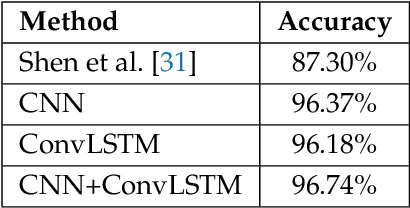
In this paper, we propose a deep learning approach for smartphone user identification based on analyzing motion signals recorded by the accelerometer and the gyroscope, during a single tap gesture performed by the user on the screen. We transform the discrete 3-axis signals from the motion sensors into a gray-scale image representation which is provided as input to a convolutional neural network (CNN) that is pre-trained for multi-class user classification. In the pre-training stage, we benefit from different users and multiple samples per user. After pre-training, we use our CNN as feature extractor, generating an embedding associated to each single tap on the screen. The resulting embeddings are used to train a Support Vector Machines (SVM) model in a few-shot user identification setting, i.e. requiring only 20 taps on the screen during the registration phase. We compare our identification system based on CNN features with two baseline systems, one that employs handcrafted features and another that employs recurrent neural network (RNN) features. All systems are based on the same classifier, namely SVM. To pre-train the CNN and the RNN models for multi-class user classification, we use a different set of users than the set used for few-shot user identification, ensuring a realistic scenario. The empirical results demonstrate that our CNN model yields a top accuracy of 89.75% in multi-class user classification and a top accuracy of 96.72% in few-shot user identification. In conclusion, we believe that our system is ready for practical use, having a better generalization capacity than both baselines.