 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Bootstrapping Contrastive Learning Enhanced Music Cold-Start Matching
Aug 05, 2023
We study a particular matching task we call Music Cold-Start Matching. In short, given a cold-start song request, we expect to retrieve songs with similar audiences and then fastly push the cold-start song to the audiences of the retrieved songs to warm up it. However, there are hardly any studies done on this task. Therefore, in this paper, we will formalize the problem of Music Cold-Start Matching detailedly and give a scheme. During the offline training, we attempt to learn high-quality song representations based on song content features. But, we find supervision signals typically follow power-law distribution causing skewed representation learning. To address this issue, we propose a novel contrastive learning paradigm named Bootstrapping Contrastive Learning (BCL) to enhance the quality of learned representations by exerting contrastive regularization. During the online serving, to locate the target audiences more accurately, we propose Clustering-based Audience Targeting (CAT) that clusters audience representations to acquire a few cluster centroids and then locate the target audiences by measuring the relevance between the audience representations and the cluster centroids. Extensive experiments on the offline dataset and online system demonstrate the effectiveness and efficiency of our method. Currently, we have deployed it on NetEase Cloud Music, affecting millions of users. Code will be released in the future.
* Accepted by WWW'2023
Adapting pretrained speech model for Mandarin lyrics transcription and alignment
Nov 21, 2023The tasks of automatic lyrics transcription and lyrics alignment have witnessed significant performance improvements in the past few years. However, most of the previous works only focus on English in which large-scale datasets are available. In this paper, we address lyrics transcription and alignment of polyphonic Mandarin pop music in a low-resource setting. To deal with the data scarcity issue, we adapt pretrained Whisper model and fine-tune it on a monophonic Mandarin singing dataset. With the use of data augmentation and source separation model, results show that the proposed method achieves a character error rate of less than 18% on a Mandarin polyphonic dataset for lyrics transcription, and a mean absolute error of 0.071 seconds for lyrics alignment. Our results demonstrate the potential of adapting a pretrained speech model for lyrics transcription and alignment in low-resource scenarios.
PortfolioMentor: Multimodal Generative AI Companion for Learning and Crafting Interactive Digital Art Portfolios
Nov 23, 2023Digital art portfolios serve as impactful mediums for artists to convey their visions, weaving together visuals, audio, interactions, and narratives. However, without technical backgrounds, design students often find it challenging to translate creative ideas into tangible codes and designs, given the lack of tailored resources for the non-technical, academic support in art schools, and a comprehensive guiding tool throughout the mentally demanding process. Recognizing the role of companionship in code learning and leveraging generative AI models' capabilities in supporting creative tasks, we present PortfolioMentor, a coding companion chatbot for IDEs. This tool guides and collaborates with students through proactive suggestions and responsible Q&As for learning, inspiration, and support. In detail, the system starts with the understanding of the task and artist's visions, follows the co-creation of visual illustrations, audio or music suggestions and files, click-scroll effects for interactions, and creative vision conceptualization, and finally synthesizes these facets into a polished interactive digital portfolio.
Emotion-Guided Music Accompaniment Generation Based on Variational Autoencoder
Jul 08, 2023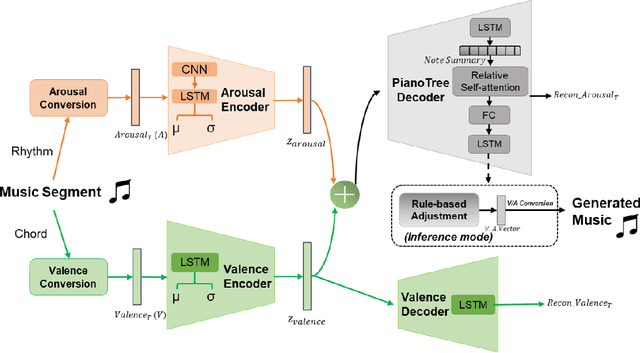
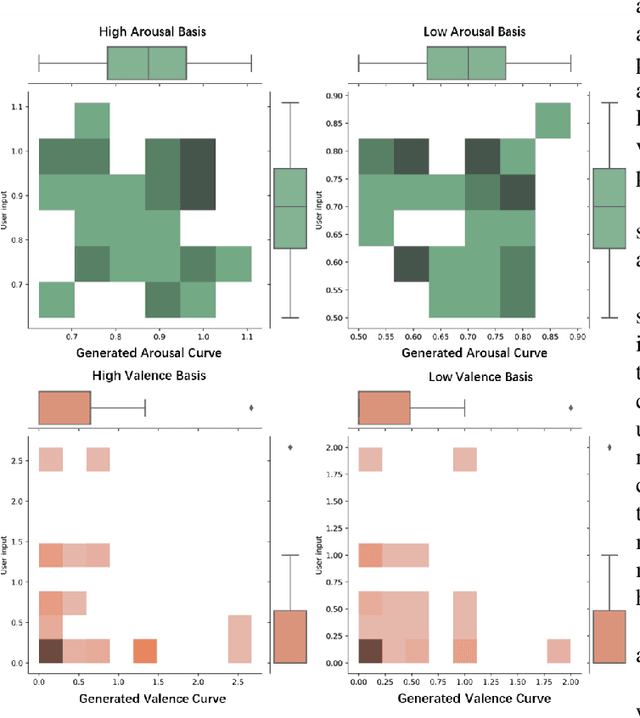
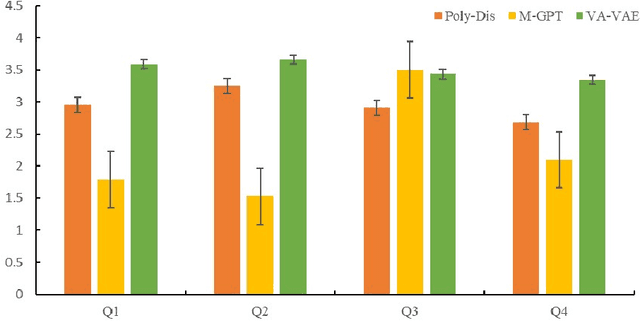
Music accompaniment generation is a crucial aspect in the composition process. Deep neural networks have made significant strides in this field, but it remains a challenge for AI to effectively incorporate human emotions to create beautiful accompaniments. Existing models struggle to effectively characterize human emotions within neural network models while composing music. To address this issue, we propose the use of an easy-to-represent emotion flow model, the Valence/Arousal Curve, which allows for the compatibility of emotional information within the model through data transformation and enhances interpretability of emotional factors by utilizing a Variational Autoencoder as the model structure. Further, we used relative self-attention to maintain the structure of the music at music phrase level and to generate a richer accompaniment when combined with the rules of music theory.
Controllable Group Choreography using Contrastive Diffusion
Oct 29, 2023Music-driven group choreography poses a considerable challenge but holds significant potential for a wide range of industrial applications. The ability to generate synchronized and visually appealing group dance motions that are aligned with music opens up opportunities in many fields such as entertainment, advertising, and virtual performances. However, most of the recent works are not able to generate high-fidelity long-term motions, or fail to enable controllable experience. In this work, we aim to address the demand for high-quality and customizable group dance generation by effectively governing the consistency and diversity of group choreographies. In particular, we utilize a diffusion-based generative approach to enable the synthesis of flexible number of dancers and long-term group dances, while ensuring coherence to the input music. Ultimately, we introduce a Group Contrastive Diffusion (GCD) strategy to enhance the connection between dancers and their group, presenting the ability to control the consistency or diversity level of the synthesized group animation via the classifier-guidance sampling technique. Through intensive experiments and evaluation, we demonstrate the effectiveness of our approach in producing visually captivating and consistent group dance motions. The experimental results show the capability of our method to achieve the desired levels of consistency and diversity, while maintaining the overall quality of the generated group choreography.
On the Effectiveness of Speech Self-supervised Learning for Music
Jul 11, 2023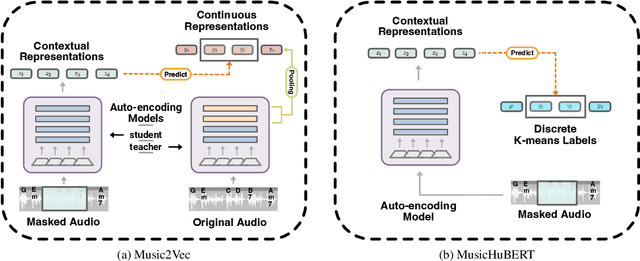
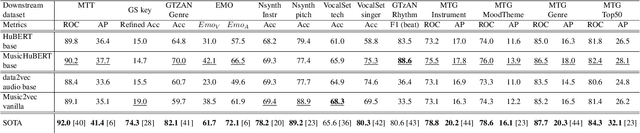

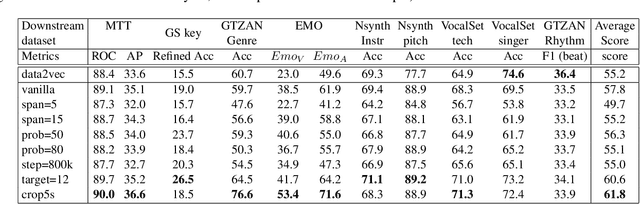
Self-supervised learning (SSL) has shown promising results in various speech and natural language processing applications. However, its efficacy in music information retrieval (MIR) still remains largely unexplored. While previous SSL models pre-trained on music recordings may have been mostly closed-sourced, recent speech models such as wav2vec2.0 have shown promise in music modelling. Nevertheless, research exploring the effectiveness of applying speech SSL models to music recordings has been limited. We explore the music adaption of SSL with two distinctive speech-related models, data2vec1.0 and Hubert, and refer to them as music2vec and musicHuBERT, respectively. We train $12$ SSL models with 95M parameters under various pre-training configurations and systematically evaluate the MIR task performances with 13 different MIR tasks. Our findings suggest that training with music data can generally improve performance on MIR tasks, even when models are trained using paradigms designed for speech. However, we identify the limitations of such existing speech-oriented designs, especially in modelling polyphonic information. Based on the experimental results, empirical suggestions are also given for designing future musical SSL strategies and paradigms.
Optimizing Feature Extraction for Symbolic Music
Jul 11, 2023
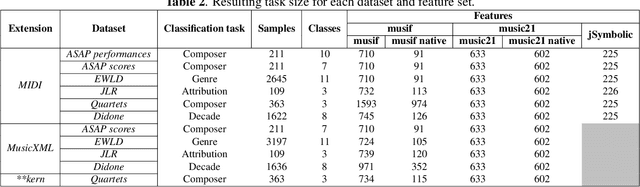
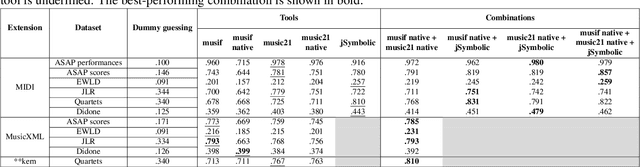
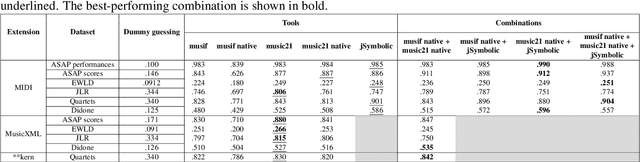
This paper presents a comprehensive investigation of existing feature extraction tools for symbolic music and contrasts their performance to determine the set of features that best characterizes the musical style of a given music score. In this regard, we propose a novel feature extraction tool, named musif, and evaluate its efficacy on various repertoires and file formats, including MIDI, MusicXML, and **kern. Musif approximates existing tools such as jSymbolic and music21 in terms of computational efficiency while attempting to enhance the usability for custom feature development. The proposed tool also enhances classification accuracy when combined with other sets of features. We demonstrate the contribution of each set of features and the computational resources they require. Our findings indicate that the optimal tool for feature extraction is a combination of the best features from each tool rather than those of a single one. To facilitate future research in music information retrieval, we release the source code of the tool and benchmarks.
Performance Analysis of Integrated Sensing and Communications Under Gain-Phase Imperfections
Nov 30, 2023This paper evaluates the performance of uplink integrated sensing and communication systems in the presence of gain and phase imperfections. Specifically, we consider multiple unmanned aerial vehicles (UAVs) transmitting data to a multiple-input-multiple-output base-station (BS) that is responsible for estimating the transmitted information in addition to localising the transmitting UAVs. The signal processing at the BS is divided into two consecutive stages: localisation and communication. A maximum likelihood (ML) algorithm is introduced for the localisation stage to jointly estimate the azimuth-elevation angles and Doppler frequency of the UAVs under gain-phase defects, which are then compared to the estimation of signal parameters via rotational invariance techniques (ESPRIT) and multiple signal classification (MUSIC). Furthermore, the Cramer-Rao lower bound (CRLB) is derived to evaluate the asymptotic performance and quantify the influence of the gain-phase imperfections which are modelled using Rician and von Mises distributions, respectively. Thereafter, in the communication stage, the location parameters estimated in the first stage are employed to estimate the communication channels which are fed into a maximum ratio combiner to preprocess the received communication signal. An accurate closed-form approximation of the achievable average sum data rate (SDR) for all UAVs is derived. The obtained results show that gain-phase imperfections have a significant influence on both localisation and communication, however, the proposed ML is less sensitive when compared to other algorithms. The derived analysis is concurred with simulations.
Automatic Time Signature Determination for New Scores Using Lyrics for Latent Rhythmic Structure
Nov 27, 2023There has recently been a sharp increase in interest in Artificial Intelligence-Generated Content (AIGC). Despite this, musical components such as time signatures have not been studied sufficiently to form an algorithmic determination approach for new compositions, especially lyrical songs. This is likely because of the neglect of musical details, which is critical for constructing a robust framework. Specifically, time signatures establish the fundamental rhythmic structure for almost all aspects of a song, including the phrases and notes. In this paper, we propose a novel approach that only uses lyrics as input to automatically generate a fitting time signature for lyrical songs and uncover the latent rhythmic structure utilizing explainable machine learning models. In particular, we devise multiple methods that are associated with discovering lyrical patterns and creating new features that simultaneously contain lyrical, rhythmic, and statistical information. In this approach, the best of our experimental results reveal a 97.6% F1 score and a 0.996 Area Under the Curve (AUC) of the Receiver Operating Characteristic (ROC) score. In conclusion, our research directly generates time signatures from lyrics automatically for new scores utilizing machine learning, which is an innovative idea that approaches an understudied component of musicology and therefore contributes significantly to the future of Artificial Intelligence (AI) music generation.
Music Mode: Transforming Robot Movement into Music Increases Likability and Perceived Intelligence
Jun 05, 2023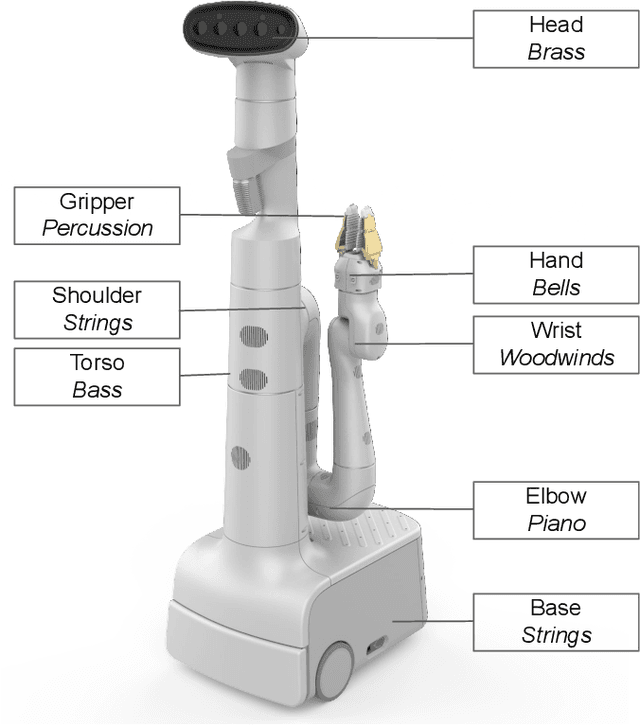
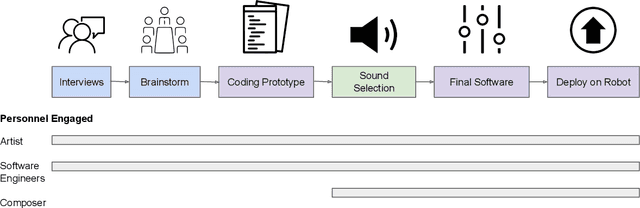
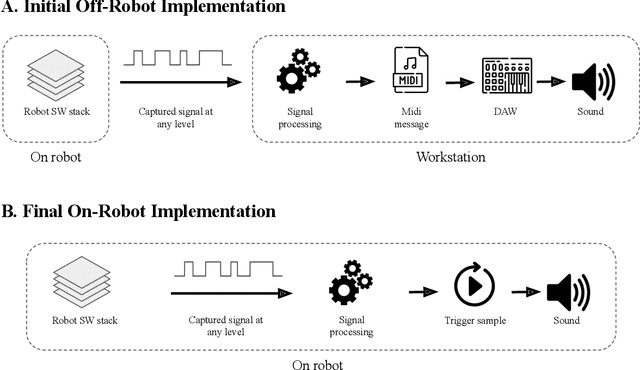
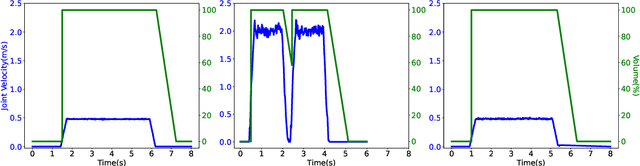
As robots enter everyday spaces like offices, the sounds they create affect how they are perceived. We present "Music Mode", a novel mapping between a robot's joint motions and sounds, programmed by artists and engineers to make the robot generate music as it moves. Two experiments were designed to characterize the effect of this musical augmentation on human users. In the first experiment, a robot performed three tasks while playing three different sound mappings. Results showed that participants observing the robot perceived it as more safe, animate, intelligent, anthropomorphic, and likable when playing the Music Mode Orchestral software. To test whether the results of the first experiment were due to the Music Mode algorithm, rather than music alone, we conducted a second experiment. Here the robot performed the same three tasks, while a participant observed via video, but the Orchestral music was either linked to its movement or random. Participants rated the robots as more intelligent when the music was linked to the movement. Robots using Music Mode logged approximately two hundred hours of operation while navigating, wiping tables, and sorting trash, and bystander comments made during this operating time served as an embedded case study. The contributions are: (1) an interdisciplinary choreographic, musical, and coding design process to develop a real-world robot sound feature, (2) a technical implementation for movement-based sound generation, and (3) two experiments and an embedded case study of robots running this feature during daily work activities that resulted in increased likeability and perceived intelligence of the robot.