 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrOCR for Medieval HTR: A Systematic Ablation Study with Cross-Dataset Validation
Jun 23, 2026Fine-tuning transformer-based handwritten text recognition (HTR) models on medieval manuscripts is challenging because these models are pre-trained on modern text and must adapt to a very different visual domain. This paper studies how three controllable fine-tuning choices (contrast normalization, data augmentation, and layer freezing) affect recognition accuracy when adapting TrOCR to small historical datasets. We run controlled experiments on a 13th-century Italian manuscript (I-CT 91 "Cortonese") and replicate the same experimental grid on the public READ-16 benchmark as robustness evidence. On Cortonese, our best configuration achieves 8.03% character error rate (CER). Statistical comparisons across 13 configurations show that freezing up to three encoder layers or six decoder layers does not significantly harm accuracy, while deeper freezing becomes progressively detrimental. Removing contrast normalization (CLAHE) yields 7.84% CER, comparable to a domain-specialized baseline, suggesting strong optimization can reduce reliance on image preprocessing. Cross-dataset validation on READ-16 shows that decoder freezing thresholds transfer more robustly than encoder thresholds, and combined freezing strategies require dataset-specific re-validation. Finally, we use Grad-CAM gradient attributions and decoder cross-attention maps to diagnose error patterns and failure modes revealed by the ablations. Source code is available at https://github.com/LaudareProject/TrOCR-analysis
Style-based Composer Identification and Attribution of Symbolic Music Scores: a Systematic Survey
Jun 14, 2025This paper presents the first comprehensive systematic review of literature on style-based composer identification and authorship attribution in symbolic music scores. Addressing the critical need for improved reliability and reproducibility in this field, the review rigorously analyzes 58 peer-reviewed papers published across various historical periods, with the search adapted to evolving terminology. The analysis critically assesses prevailing repertoires, computational approaches, and evaluation methodologies, highlighting significant challenges. It reveals that a substantial portion of existing research suffers from inadequate validation protocols and an over-reliance on simple accuracy metrics for often imbalanced datasets, which can undermine the credibility of attribution claims. The crucial role of robust metrics like Balanced Accuracy and rigorous cross-validation in ensuring trustworthy results is emphasized. The survey also details diverse feature representations and the evolution of machine learning models employed. Notable real-world authorship attribution cases, such as those involving works attributed to Bach, Josquin Desprez, and Lennon-McCartney, are specifically discussed, illustrating the opportunities and pitfalls of applying computational techniques to resolve disputed musical provenance. Based on these insights, a set of actionable guidelines for future research are proposed. These recommendations are designed to significantly enhance the reliability, reproducibility, and musicological validity of composer identification and authorship attribution studies, fostering more robust and interpretable computational stylistic analysis.
Optical Music Recognition in Manuscripts from the Ricordi Archive
Aug 14, 2024



The Ricordi archive, a prestigious collection of significant musical manuscripts from renowned opera composers such as Donizetti, Verdi and Puccini, has been digitized. This process has allowed us to automatically extract samples that represent various musical elements depicted on the manuscripts, including notes, staves, clefs, erasures, and composer's annotations, among others. To distinguish between digitization noise and actual music elements, a subset of these images was meticulously grouped and labeled by multiple individuals into several classes. After assessing the consistency of the annotations, we trained multiple neural network-based classifiers to differentiate between the identified music elements. The primary objective of this study was to evaluate the reliability of these classifiers, with the ultimate goal of using them for the automatic categorization of the remaining unannotated data set. The dataset, complemented by manual annotations, models, and source code used in these experiments are publicly accessible for replication purposes.
A Systematic Evaluation of Adversarial Attacks against Speech Emotion Recognition Models
Apr 29, 2024Speech emotion recognition (SER) is constantly gaining attention in recent years due to its potential applications in diverse fields and thanks to the possibility offered by deep learning technologies. However, recent studies have shown that deep learning models can be vulnerable to adversarial attacks. In this paper, we systematically assess this problem by examining the impact of various adversarial white-box and black-box attacks on different languages and genders within the context of SER. We first propose a suitable methodology for audio data processing, feature extraction, and CNN-LSTM architecture. The observed outcomes highlighted the significant vulnerability of CNN-LSTM models to adversarial examples (AEs). In fact, all the considered adversarial attacks are able to significantly reduce the performance of the constructed models. Furthermore, when assessing the efficacy of the attacks, minor differences were noted between the languages analyzed as well as between male and female speech. In summary, this work contributes to the understanding of the robustness of CNN-LSTM models, particularly in SER scenarios, and the impact of AEs. Interestingly, our findings serve as a baseline for a) developing more robust algorithms for SER, b) designing more effective attacks, c) investigating possible defenses, d) improved understanding of the vocal differences between different languages and genders, and e) overall, enhancing our comprehension of the SER task.
Optimizing Feature Extraction for Symbolic Music
Jul 11, 2023This paper presents a comprehensive investigation of existing feature extraction tools for symbolic music and contrasts their performance to determine the set of features that best characterizes the musical style of a given music score. In this regard, we propose a novel feature extraction tool, named musif, and evaluate its efficacy on various repertoires and file formats, including MIDI, MusicXML, and **kern. Musif approximates existing tools such as jSymbolic and music21 in terms of computational efficiency while attempting to enhance the usability for custom feature development. The proposed tool also enhances classification accuracy when combined with other sets of features. We demonstrate the contribution of each set of features and the computational resources they require. Our findings indicate that the optimal tool for feature extraction is a combination of the best features from each tool rather than those of a single one. To facilitate future research in music information retrieval, we release the source code of the tool and benchmarks.
musif: a Python package for symbolic music feature extraction
Jul 03, 2023

In this work, we introduce musif, a Python package that facilitates the automatic extraction of features from symbolic music scores. The package includes the implementation of a large number of features, which have been developed by a team of experts in musicology, music theory, statistics, and computer science. Additionally, the package allows for the easy creation of custom features using commonly available Python libraries. musif is primarily geared towards processing high-quality musicological data encoded in MusicXML format, but also supports other formats commonly used in music information retrieval tasks, including MIDI, MEI, Kern, and others. We provide comprehensive documentation and tutorials to aid in the extension of the framework and to facilitate the introduction of new and inexperienced users to its usage.
Deep Feature Learning for Medical Acoustics
Aug 05, 2022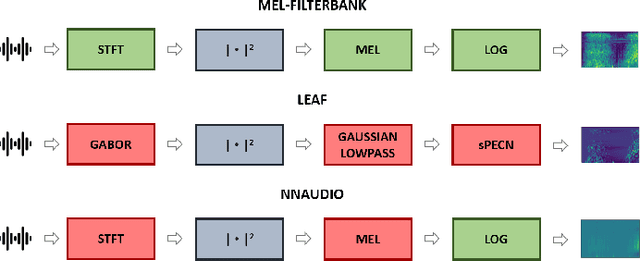
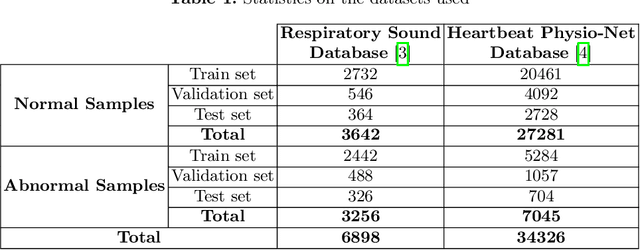
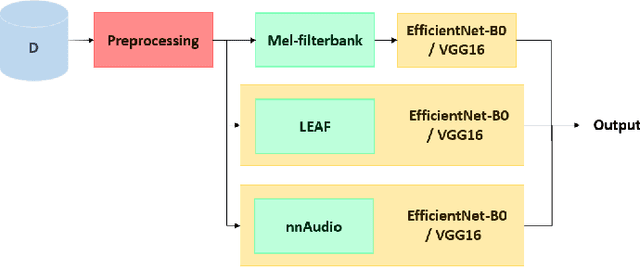
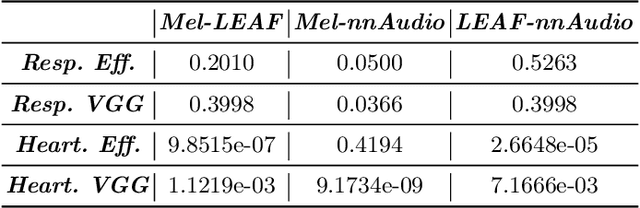
The purpose of this paper is to compare different learnable frontends in medical acoustics tasks. A framework has been implemented to classify human respiratory sounds and heartbeats in two categories, i.e. healthy or affected by pathologies. After obtaining two suitable datasets, we proceeded to classify the sounds using two learnable state-of-art frontends -- LEAF and nnAudio -- plus a non-learnable baseline frontend, i.e. Mel-filterbanks. The computed features are then fed into two different CNN models, namely VGG16 and EfficientNet. The frontends are carefully benchmarked in terms of the number of parameters, computational resources, and effectiveness. This work demonstrates how the integration of learnable frontends in neural audio classification systems may improve performance, especially in the field of medical acoustics. However, the usage of such frameworks makes the needed amount of data even larger. Consequently, they are useful if the amount of data available for training is adequately large to assist the feature learning process.
Variational Autoencoders for Anomaly Detection in Respiratory Sounds
Aug 05, 2022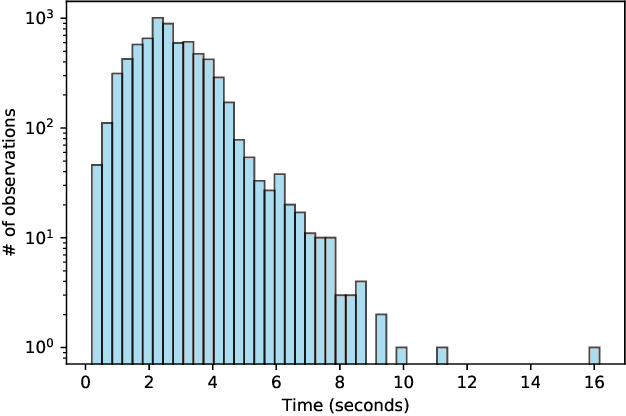
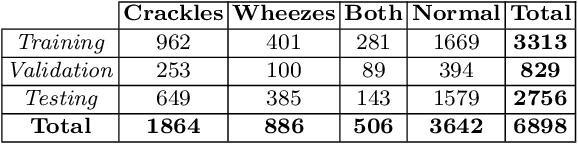
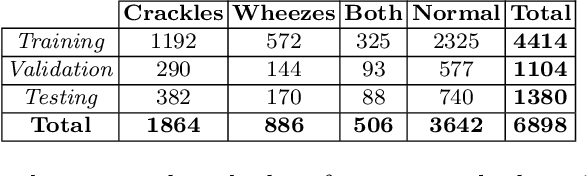
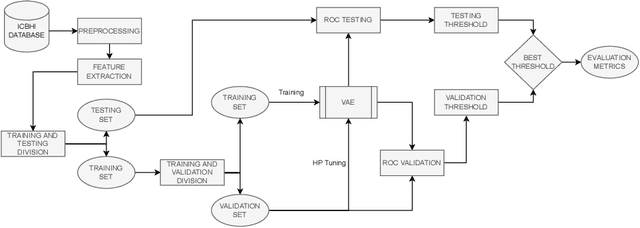
This paper proposes a weakly-supervised machine learning-based approach aiming at a tool to alert patients about possible respiratory diseases. Various types of pathologies may affect the respiratory system, potentially leading to severe diseases and, in certain cases, death. In general, effective prevention practices are considered as major actors towards the improvement of the patient's health condition. The proposed method strives to realize an easily accessible tool for the automatic diagnosis of respiratory diseases. Specifically, the method leverages Variational Autoencoder architectures permitting the usage of training pipelines of limited complexity and relatively small-sized datasets. Importantly, it offers an accuracy of 57 %, which is in line with the existing strongly-supervised approaches.
Music Interpretation Analysis. A Multimodal Approach To Score-Informed Resynthesis of Piano Recordings
May 02, 2022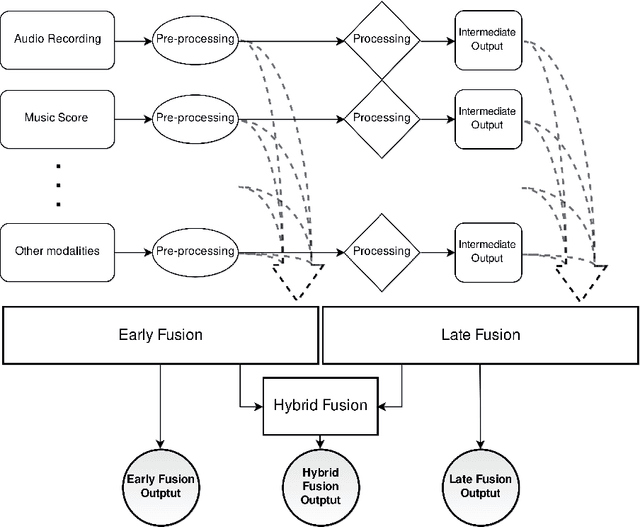
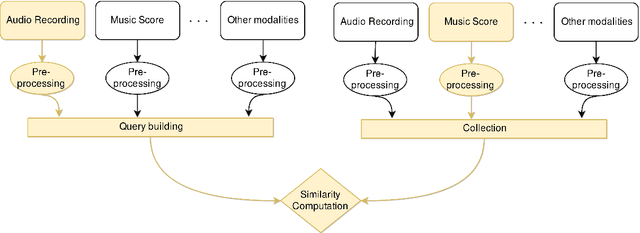
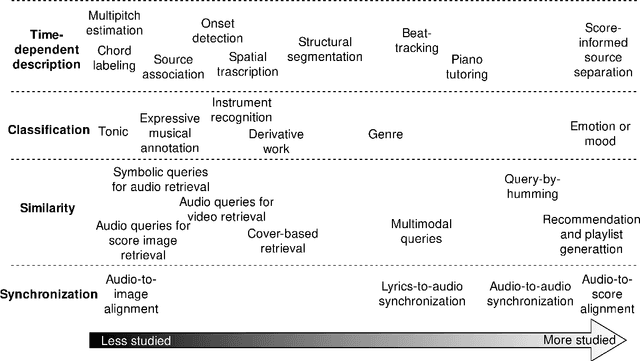
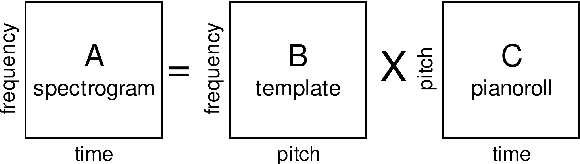
This Thesis discusses the development of technologies for the automatic resynthesis of music recordings using digital synthesizers. First, the main issue is identified in the understanding of how Music Information Processing (MIP) methods can take into consideration the influence of the acoustic context on the music performance. For this, a novel conceptual and mathematical framework named "Music Interpretation Analysis" (MIA) is presented. In the proposed framework, a distinction is made between the "performance" - the physical action of playing - and the "interpretation" - the action that the performer wishes to achieve. Second, the Thesis describes further works aiming at the democratization of music production tools via automatic resynthesis: 1) it elaborates software and file formats for historical music archiving and multimodal machine-learning datasets; 2) it explores and extends MIP technologies; 3) it presents the mathematical foundations of the MIA framework and shows preliminary evaluations to demonstrate the effectiveness of the approach
Context-aware Automatic Music Transcription
Mar 30, 2022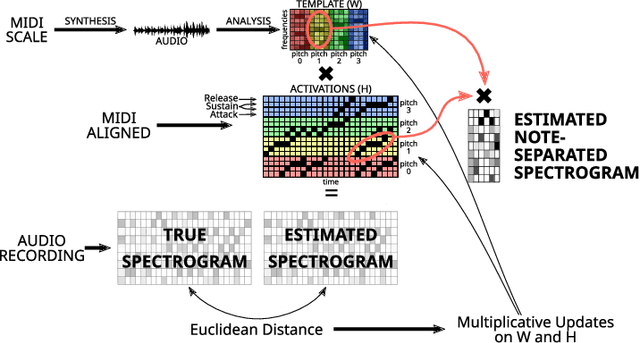
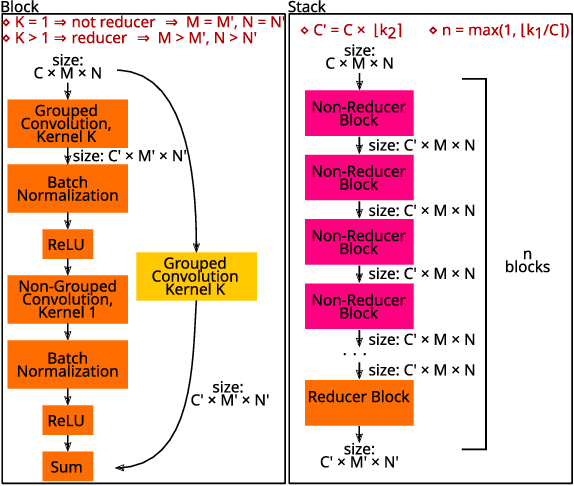
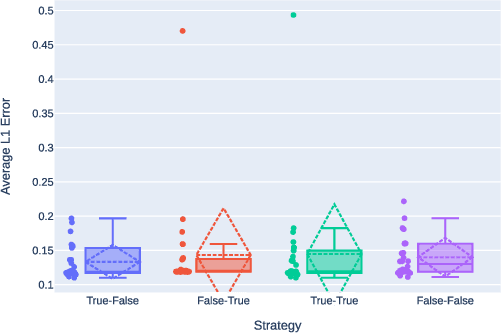
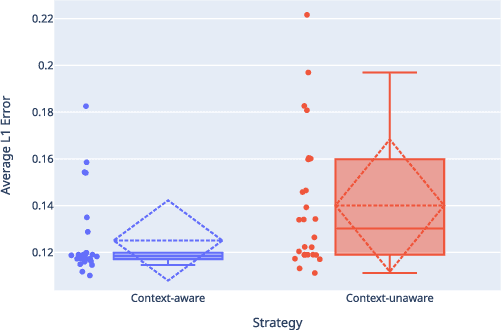
This paper presents an Automatic Music Transcription system that incorporates context-related information. Motivated by the state-of-art psychological research, we propose a methodology boosting the accuracy of AMT systems by modeling the adaptations that performers apply to successfully convey their interpretation in any acoustical context. In this work, we show that exploiting the knowledge of the source acoustical context allows reducing the error related to the inference of MIDI velocity. The proposed model structure first extracts the interpretation features and then applies the modeled performer adaptations. Interestingly, such a methodology is extensible in a straightforward way since only slight efforts are required to train completely context-aware AMT models.