 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Interpretation of Non-Destructive Evaluation Contour Maps Using Large Language Models for Bridge Condition Assessment
Jul 18, 2025Bridge maintenance and safety are essential for transportation authorities, and Non-Destructive Evaluation (NDE) techniques are critical to assessing structural integrity. However, interpreting NDE data can be time-consuming and requires expertise, potentially delaying decision-making. Recent advancements in Large Language Models (LLMs) offer new ways to automate and improve this analysis. This pilot study introduces a holistic assessment of LLM capabilities for interpreting NDE contour maps and demonstrates the effectiveness of LLMs in providing detailed bridge condition analyses. It establishes a framework for integrating LLMs into bridge inspection workflows, indicating that LLM-assisted analysis can enhance efficiency without compromising accuracy. In this study, several LLMs are explored with prompts specifically designed to enhance the quality of image descriptions, which are applied to interpret five different NDE contour maps obtained through technologies for assessing bridge conditions. Each LLM model is evaluated based on its ability to produce detailed descriptions, identify defects, provide actionable recommendations, and demonstrate overall accuracy. The research indicates that four of the nine models provide better image descriptions, effectively covering a wide range of topics related to the bridge's condition. The outputs from these four models are summarized using five different LLMs to form a comprehensive overview of the bridge. Notably, LLMs ChatGPT-4 and Claude 3.5 Sonnet generate more effective summaries. The findings suggest that LLMs have the potential to significantly improve efficiency and accuracy. This pilot study presents an innovative approach that leverages LLMs for image captioning in parallel and summarization, enabling faster decision-making in bridge maintenance and enhancing infrastructure management and safety assessments.
Adaptive Signal Analysis for Automated Subsurface Defect Detection Using Impact Echo in Concrete Slabs
Dec 23, 2024



This pilot study presents a novel, automated, and scalable methodology for detecting and evaluating subsurface defect-prone regions in concrete slabs using Impact Echo (IE) signal analysis. The approach integrates advanced signal processing, clustering, and visual analytics to identify subsurface anomalies. A unique adaptive thresholding method tailors frequency-based defect identification to the distinct material properties of each slab. The methodology generates frequency maps, binary masks, and k-means cluster maps to automatically classify defect and non-defect regions. Key visualizations, including 3D surface plots, cluster maps, and contour plots, are employed to analyze spatial frequency distributions and highlight structural anomalies. The study utilizes a labeled dataset constructed at the Federal Highway Administration (FHWA) Advanced Sensing Technology Nondestructive Evaluation Laboratory. Evaluations involve ground-truth masking, comparing the generated defect maps with top-view binary masks derived from the information provided by the FHWA. The performance metrics, specifically F1-scores and AUC-ROC, achieve values of up to 0.95 and 0.83, respectively. The results demonstrate the robustness of the methodology, consistently identifying defect-prone areas with minimal false positives and few missed defects. Adaptive frequency thresholding ensures flexibility in addressing variations across slabs, providing a scalable framework for detecting structural anomalies. Additionally, the methodology is adaptable to other frequency-based signals due to its generalizable thresholding mechanism and holds potential for integrating multimodal sensor fusion. This automated and scalable pipeline minimizes manual intervention, ensuring accurate and efficient defect detection, further advancing Non-Destructive Evaluation (NDE) techniques.
A Multimodal Fusion Framework for Bridge Defect Detection with Cross-Verification
Dec 23, 2024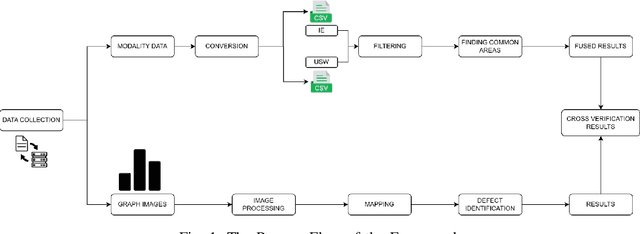
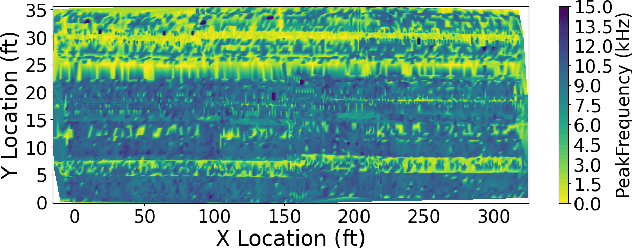
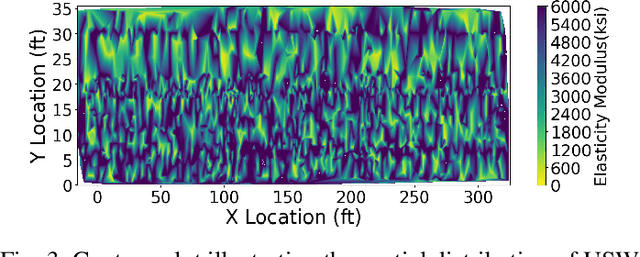
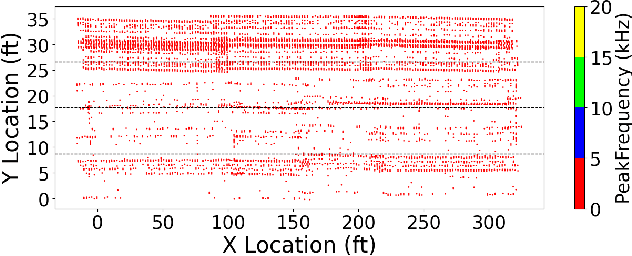
This paper presents a pilot study introducing a multimodal fusion framework for the detection and analysis of bridge defects, integrating Non-Destructive Evaluation (NDE) techniques with advanced image processing to enable precise structural assessment. By combining data from Impact Echo (IE) and Ultrasonic Surface Waves (USW) methods, this preliminary investigation focuses on identifying defect-prone regions within concrete structures, emphasizing critical indicators such as delamination and debonding. Using geospatial analysis with alpha shapes, fusion of defect points, and unified lane boundaries, the proposed framework consolidates disparate data sources to enhance defect localization and facilitate the identification of overlapping defect regions. Cross-verification with adaptive image processing further validates detected defects by aligning their coordinates with visual data, utilizing advanced contour-based mapping and bounding box techniques for precise defect identification. The experimental results, with an F1 score of 0.83, demonstrate the potential efficacy of the approach in improving defect localization, reducing false positives, and enhancing detection accuracy, which provides a foundation for future research and larger-scale validation. This preliminary exploration establishes the framework as a promising tool for efficient bridge health assessment, with implications for proactive structural monitoring and maintenance.
InfoTech Assistant : A Multimodal Conversational Agent for InfoTechnology Web Portal Queries
Dec 21, 2024This pilot study presents the development of the InfoTech Assistant, a domain-specific, multimodal chatbot engineered to address queries in bridge evaluation and infrastructure technology. By integrating web data scraping, large language models (LLMs), and Retrieval-Augmented Generation (RAG), the InfoTech Assistant provides accurate and contextually relevant responses. Data, including textual descriptions and images, are sourced from publicly available documents on the InfoTechnology website and organized in JSON format to facilitate efficient querying. The architecture of the system includes an HTML-based interface and a Flask back end connected to the Llama 3.1 model via LLM Studio. Evaluation results show approximately 95 percent accuracy on domain-specific tasks, with high similarity scores confirming the quality of response matching. This RAG-enhanced setup enables the InfoTech Assistant to handle complex, multimodal queries, offering both textual and visual information in its responses. The InfoTech Assistant demonstrates strong potential as a dependable tool for infrastructure professionals, delivering high accuracy and relevance in its domain-specific outputs.
Relationships between Keywords and Strong Beats in Lyrical Music
Dec 05, 2024Artificial Intelligence (AI) song generation has emerged as a popular topic, yet the focus on exploring the latent correlations between specific lyrical and rhythmic features remains limited. In contrast, this pilot study particularly investigates the relationships between keywords and rhythmically stressed features such as strong beats in songs. It focuses on several key elements: keywords or non-keywords, stressed or unstressed syllables, and strong or weak beats, with the aim of uncovering insightful correlations. Experimental results indicate that, on average, 80.8\% of keywords land on strong beats, whereas 62\% of non-keywords fall on weak beats. The relationship between stressed syllables and strong or weak beats is weak, revealing that keywords have the strongest relationships with strong beats. Additionally, the lyrics-rhythm matching score, a key matching metric measuring keywords on strong beats and non-keywords on weak beats across various time signatures, is 0.765, while the matching score for syllable types is 0.495. This study demonstrates that word types strongly align with their corresponding beat types, as evidenced by the distinct patterns, whereas syllable types exhibit a much weaker alignment. This disparity underscores the greater reliability of word types in capturing rhythmic structures in music, highlighting their crucial role in effective rhythmic matching and analysis. We also conclude that keywords that consistently align with strong beats are more reliable indicators of lyrics-rhythm associations, providing valuable insights for AI-driven song generation through enhanced structural analysis. Furthermore, our development of tailored Lyrics-Rhythm Matching (LRM) metrics maximizes lyrical alignments with corresponding beat stresses, and our novel LRM file format captures critical lyrical and rhythmic information without needing original sheet music.
Automatic Time Signature Determination for New Scores Using Lyrics for Latent Rhythmic Structure
Nov 27, 2023There has recently been a sharp increase in interest in Artificial Intelligence-Generated Content (AIGC). Despite this, musical components such as time signatures have not been studied sufficiently to form an algorithmic determination approach for new compositions, especially lyrical songs. This is likely because of the neglect of musical details, which is critical for constructing a robust framework. Specifically, time signatures establish the fundamental rhythmic structure for almost all aspects of a song, including the phrases and notes. In this paper, we propose a novel approach that only uses lyrics as input to automatically generate a fitting time signature for lyrical songs and uncover the latent rhythmic structure utilizing explainable machine learning models. In particular, we devise multiple methods that are associated with discovering lyrical patterns and creating new features that simultaneously contain lyrical, rhythmic, and statistical information. In this approach, the best of our experimental results reveal a 97.6% F1 score and a 0.996 Area Under the Curve (AUC) of the Receiver Operating Characteristic (ROC) score. In conclusion, our research directly generates time signatures from lyrics automatically for new scores utilizing machine learning, which is an innovative idea that approaches an understudied component of musicology and therefore contributes significantly to the future of Artificial Intelligence (AI) music generation.
Multimodal Lyrics-Rhythm Matching
Jan 06, 2023



Despite the recent increase in research on artificial intelligence for music, prominent correlations between key components of lyrics and rhythm such as keywords, stressed syllables, and strong beats are not frequently studied. Ths is likely due to challenges such as audio misalignment, inaccuracies in syllabic identification, and most importantly, the need for cross-disciplinary knowledge. To address this lack of research, we propose a novel multimodal lyrics-rhythm matching approach in this paper that specifically matches key components of lyrics and music with each other without any language limitations. We use audio instead of sheet music with readily available metadata, which creates more challenges yet increases the application flexibility of our method. Furthermore, our approach creatively generates several patterns involving various multimodalities, including music strong beats, lyrical syllables, auditory changes in a singer's pronunciation, and especially lyrical keywords, which are utilized for matching key lyrical elements with key rhythmic elements. This advantageous approach not only provides a unique way to study auditory lyrics-rhythm correlations including efficient rhythm-based audio alignment algorithms, but also bridges computational linguistics with music as well as music cognition. Our experimental results reveal an 0.81 probability of matching on average, and around 30% of the songs have a probability of 0.9 or higher of keywords landing on strong beats, including 12% of the songs with a perfect landing. Also, the similarity metrics are used to evaluate the correlation between lyrics and rhythm. It shows that nearly 50% of the songs have 0.70 similarity or higher. In conclusion, our approach contributes significantly to the lyrics-rhythm relationship by computationally unveiling insightful correlations.
Automated Generation of Interorganizational Disaster Response Networks through Information Extraction
Feb 27, 2021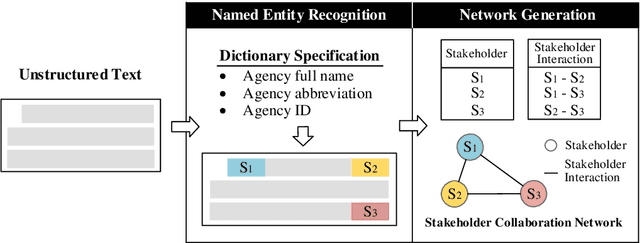


When a disaster occurs, maintaining and restoring community lifelines subsequently require collective efforts from various stakeholders. Aiming at reducing the efforts associated with generating Stakeholder Collaboration Networks (SCNs), this paper proposes a systematic approach to reliable information extraction for stakeholder collaboration and automated network generation. Specifically, stakeholders and their interactions are extracted from texts through Named Entity Recognition (NER), one of the techniques in natural language processing. Once extracted, the collaboration information is transformed into structured datasets to generate the SCNs automatically. A case study of stakeholder collaboration during Hurricane Harvey was investigated and it had demonstrated the feasibility and applicability of the proposed method. Hence, the proposed approach was proved to significantly reduce practitioners' interpretation and data collection workloads. In the end, discussions and future work are provided.