 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition
May 05, 2023
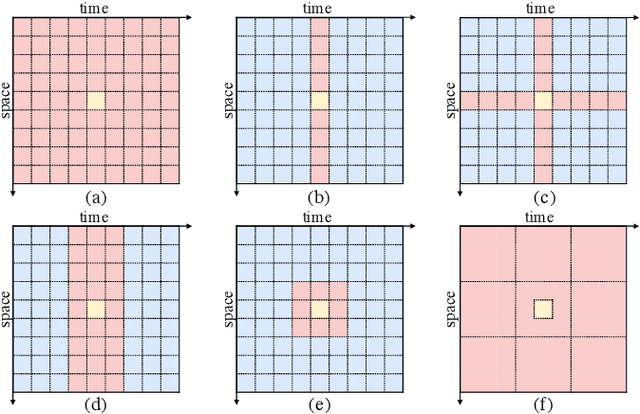
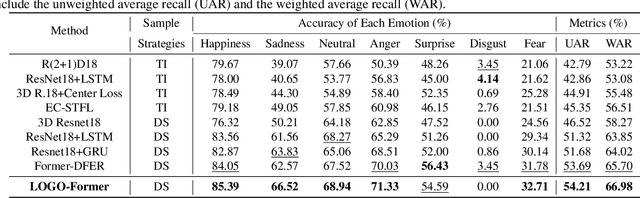
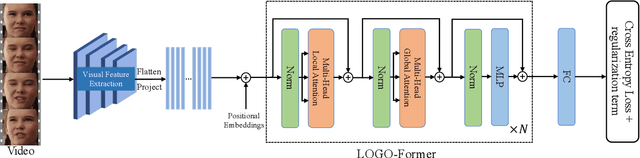
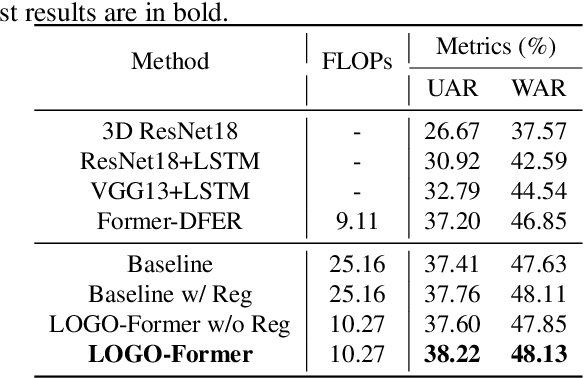
Previous methods for dynamic facial expression recognition (DFER) in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. Transformer-based methods for DFER can achieve better performances but result in higher FLOPs and computational costs. To solve these problems, the local-global spatio-temporal Transformer (LOGO-Former) is proposed to capture discriminative features within each frame and model contextual relationships among frames while balancing the complexity. Based on the priors that facial muscles move locally and facial expressions gradually change, we first restrict both the space attention and the time attention to a local window to capture local interactions among feature tokens. Furthermore, we perform the global attention by querying a token with features from each local window iteratively to obtain long-range information of the whole video sequence. In addition, we propose the compact loss regularization term to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39K) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for DFER.
Enhancing Mobile Privacy and Security: A Face Skin Patch-Based Anti-Spoofing Approach
Aug 09, 2023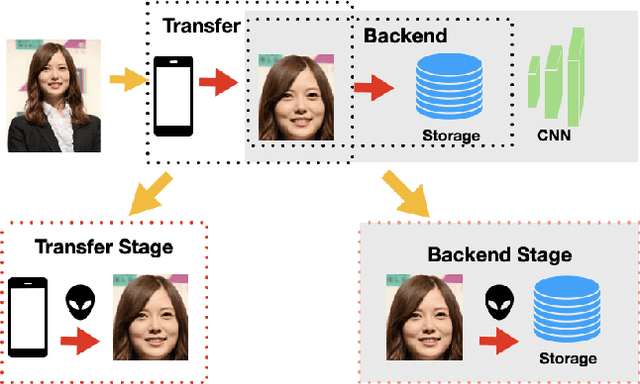
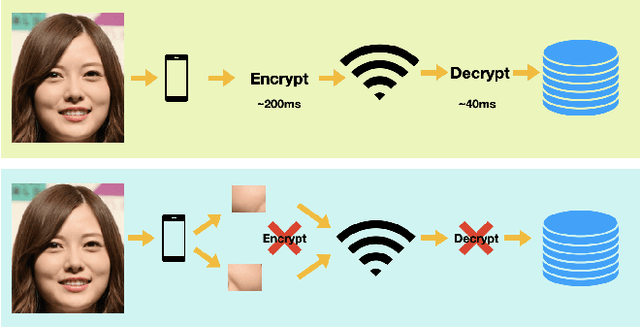
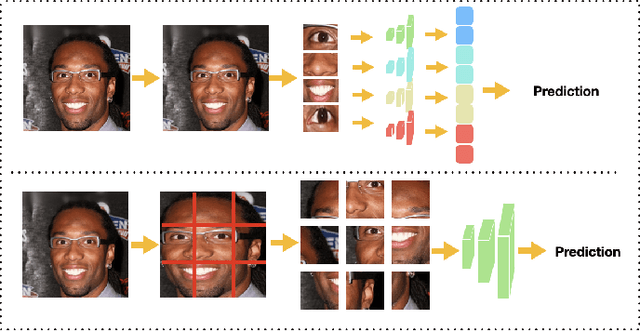
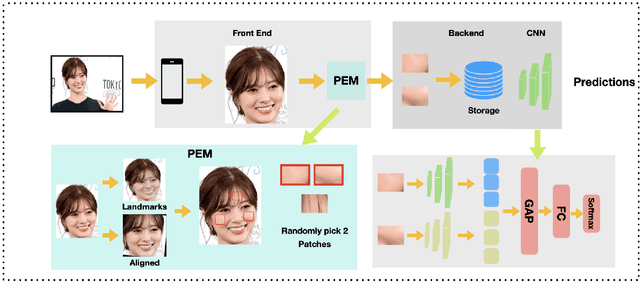
As Facial Recognition System(FRS) is widely applied in areas such as access control and mobile payments due to its convenience and high accuracy. The security of facial recognition is also highly regarded. The Face anti-spoofing system(FAS) for face recognition is an important component used to enhance the security of face recognition systems. Traditional FAS used images containing identity information to detect spoofing traces, however there is a risk of privacy leakage during the transmission and storage of these images. Besides, the encryption and decryption of these privacy-sensitive data takes too long compared to inference time by FAS model. To address the above issues, we propose a face anti-spoofing algorithm based on facial skin patches leveraging pure facial skin patch images as input, which contain no privacy information, no encryption or decryption is needed for these images. We conduct experiments on several public datasets, the results prove that our algorithm has demonstrated superiority in both accuracy and speed.
Learning Separable Hidden Unit Contributions for Speaker-Adaptive Lip-Reading
Oct 08, 2023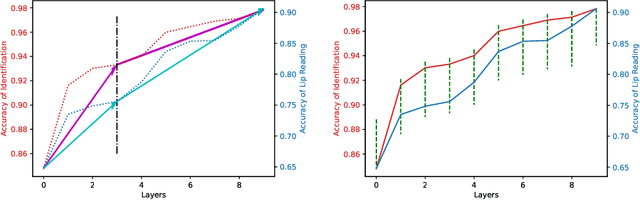
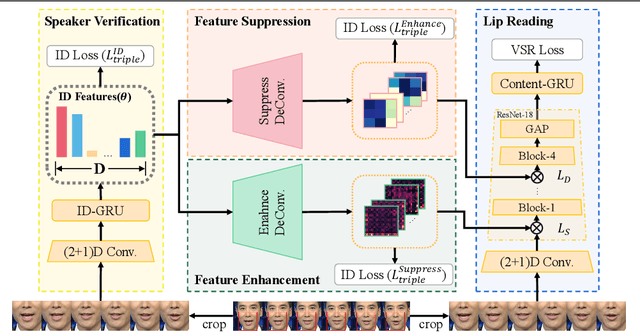
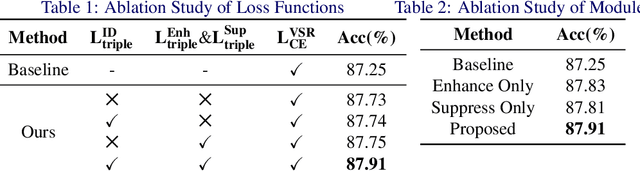
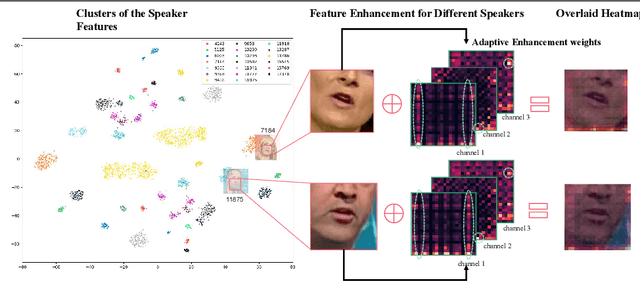
In this paper, we propose a novel method for speaker adaptation in lip reading, motivated by two observations. Firstly, a speaker's own characteristics can always be portrayed well by his/her few facial images or even a single image with shallow networks, while the fine-grained dynamic features associated with speech content expressed by the talking face always need deep sequential networks to represent accurately. Therefore, we treat the shallow and deep layers differently for speaker adaptive lip reading. Secondly, we observe that a speaker's unique characteristics ( e.g. prominent oral cavity and mandible) have varied effects on lip reading performance for different words and pronunciations, necessitating adaptive enhancement or suppression of the features for robust lip reading. Based on these two observations, we propose to take advantage of the speaker's own characteristics to automatically learn separable hidden unit contributions with different targets for shallow layers and deep layers respectively. For shallow layers where features related to the speaker's characteristics are stronger than the speech content related features, we introduce speaker-adaptive features to learn for enhancing the speech content features. For deep layers where both the speaker's features and the speech content features are all expressed well, we introduce the speaker-adaptive features to learn for suppressing the speech content irrelevant noise for robust lip reading. Our approach consistently outperforms existing methods, as confirmed by comprehensive analysis and comparison across different settings. Besides the evaluation on the popular LRW-ID and GRID datasets, we also release a new dataset for evaluation, CAS-VSR-S68h, to further assess the performance in an extreme setting where just a few speakers are available but the speech content covers a large and diversified range.
Interpretable Multimodal Emotion Recognition using Facial Features and Physiological Signals
Jun 05, 2023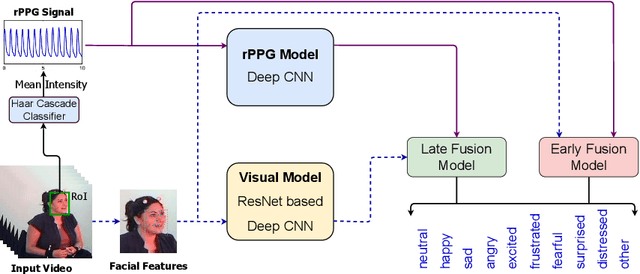


This paper aims to demonstrate the importance and feasibility of fusing multimodal information for emotion recognition. It introduces a multimodal framework for emotion understanding by fusing the information from visual facial features and rPPG signals extracted from the input videos. An interpretability technique based on permutation feature importance analysis has also been implemented to compute the contributions of rPPG and visual modalities toward classifying a given input video into a particular emotion class. The experiments on IEMOCAP dataset demonstrate that the emotion classification performance improves by combining the complementary information from multiple modalities.
MIS-AVioDD: Modality Invariant and Specific Representation for Audio-Visual Deepfake Detection
Oct 03, 2023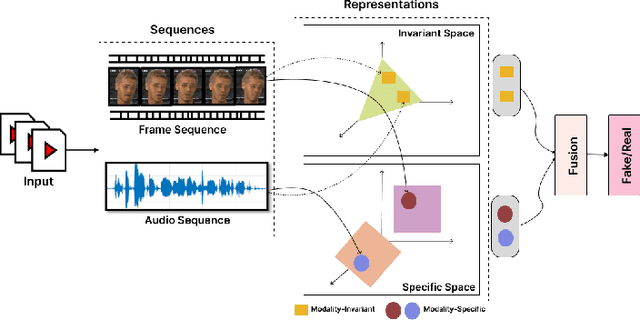
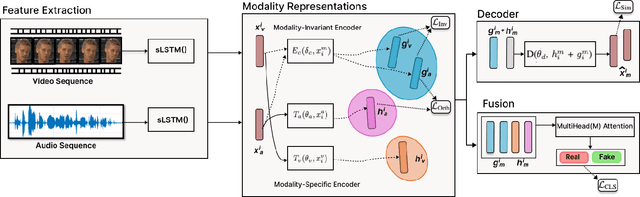

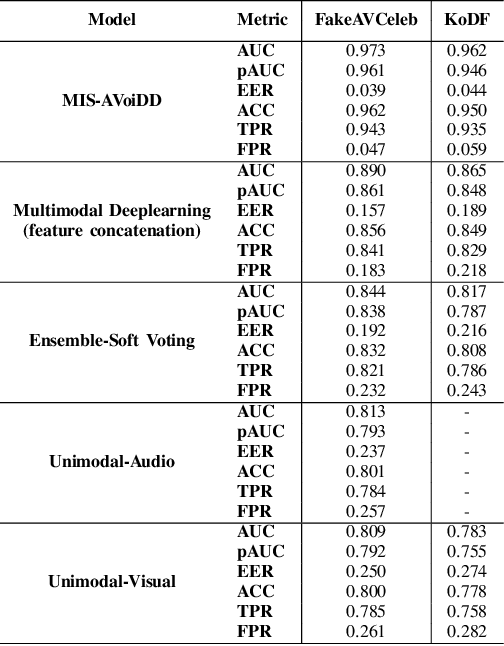
Deepfakes are synthetic media generated using deep generative algorithms and have posed a severe societal and political threat. Apart from facial manipulation and synthetic voice, recently, a novel kind of deepfakes has emerged with either audio or visual modalities manipulated. In this regard, a new generation of multimodal audio-visual deepfake detectors is being investigated to collectively focus on audio and visual data for multimodal manipulation detection. Existing multimodal (audio-visual) deepfake detectors are often based on the fusion of the audio and visual streams from the video. Existing studies suggest that these multimodal detectors often obtain equivalent performances with unimodal audio and visual deepfake detectors. We conjecture that the heterogeneous nature of the audio and visual signals creates distributional modality gaps and poses a significant challenge to effective fusion and efficient performance. In this paper, we tackle the problem at the representation level to aid the fusion of audio and visual streams for multimodal deepfake detection. Specifically, we propose the joint use of modality (audio and visual) invariant and specific representations. This ensures that the common patterns and patterns specific to each modality representing pristine or fake content are preserved and fused for multimodal deepfake manipulation detection. Our experimental results on FakeAVCeleb and KoDF audio-visual deepfake datasets suggest the enhanced accuracy of our proposed method over SOTA unimodal and multimodal audio-visual deepfake detectors by $17.8$% and $18.4$%, respectively. Thus, obtaining state-of-the-art performance.
SlowFast Network for Continuous Sign Language Recognition
Sep 21, 2023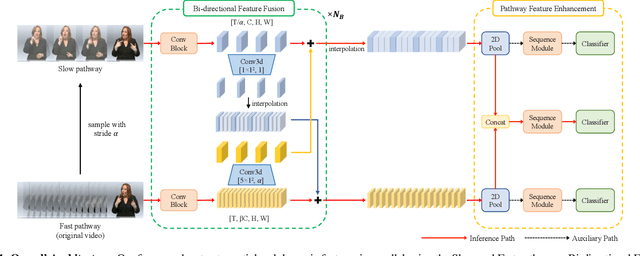
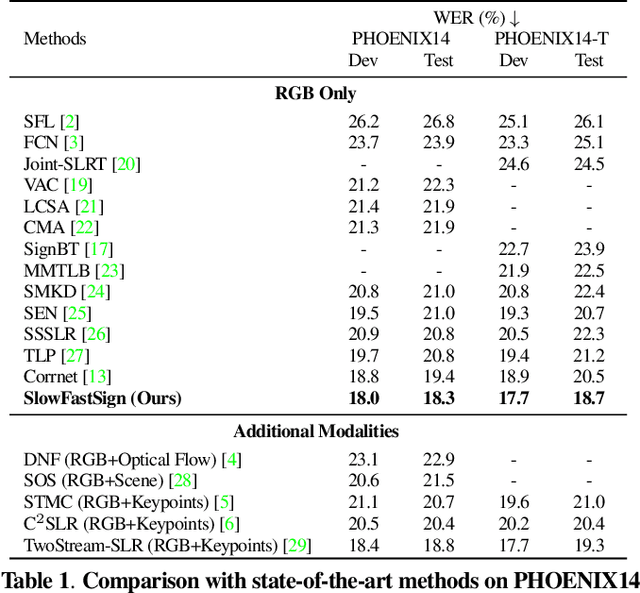


The objective of this work is the effective extraction of spatial and dynamic features for Continuous Sign Language Recognition (CSLR). To accomplish this, we utilise a two-pathway SlowFast network, where each pathway operates at distinct temporal resolutions to separately capture spatial (hand shapes, facial expressions) and dynamic (movements) information. In addition, we introduce two distinct feature fusion methods, carefully designed for the characteristics of CSLR: (1) Bi-directional Feature Fusion (BFF), which facilitates the transfer of dynamic semantics into spatial semantics and vice versa; and (2) Pathway Feature Enhancement (PFE), which enriches dynamic and spatial representations through auxiliary subnetworks, while avoiding the need for extra inference time. As a result, our model further strengthens spatial and dynamic representations in parallel. We demonstrate that the proposed framework outperforms the current state-of-the-art performance on popular CSLR datasets, including PHOENIX14, PHOENIX14-T, and CSL-Daily.
TalkNCE: Improving Active Speaker Detection with Talk-Aware Contrastive Learning
Sep 21, 2023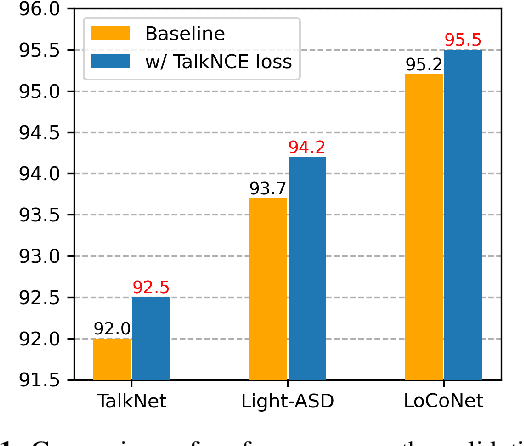
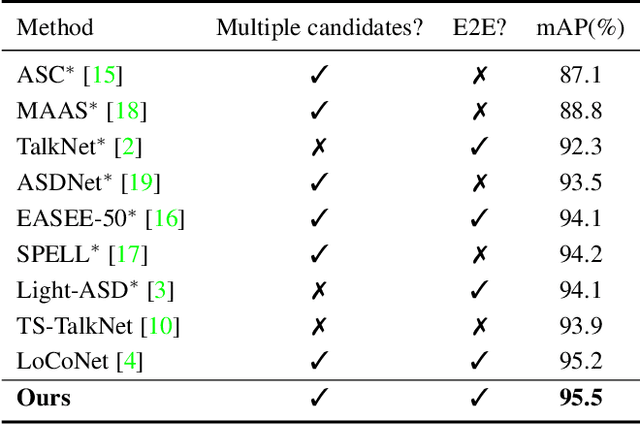
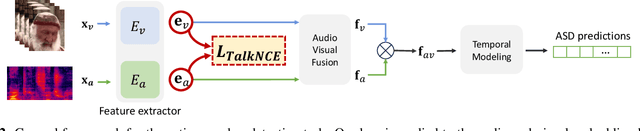
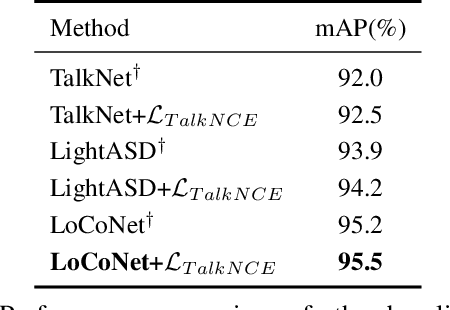
The goal of this work is Active Speaker Detection (ASD), a task to determine whether a person is speaking or not in a series of video frames. Previous works have dealt with the task by exploring network architectures while learning effective representations has been less explored. In this work, we propose TalkNCE, a novel talk-aware contrastive loss. The loss is only applied to part of the full segments where a person on the screen is actually speaking. This encourages the model to learn effective representations through the natural correspondence of speech and facial movements. Our loss can be jointly optimized with the existing objectives for training ASD models without the need for additional supervision or training data. The experiments demonstrate that our loss can be easily integrated into the existing ASD frameworks, improving their performance. Our method achieves state-of-the-art performances on AVA-ActiveSpeaker and ASW datasets.
Facial recognition technology can expose political orientation from facial images even when controlling for demographics and self-presentation
Mar 28, 2023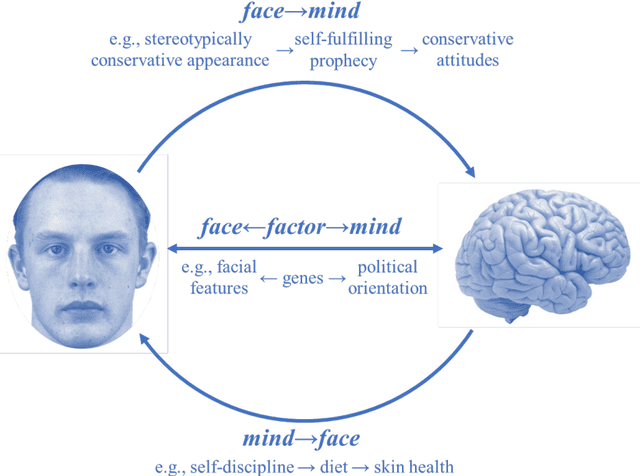
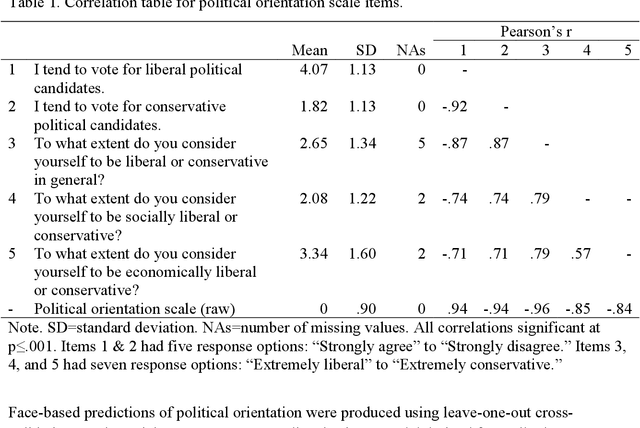
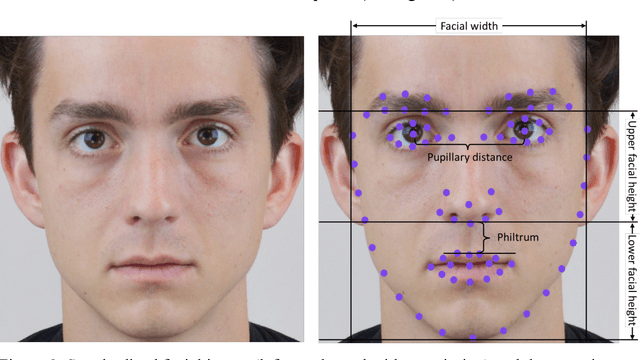
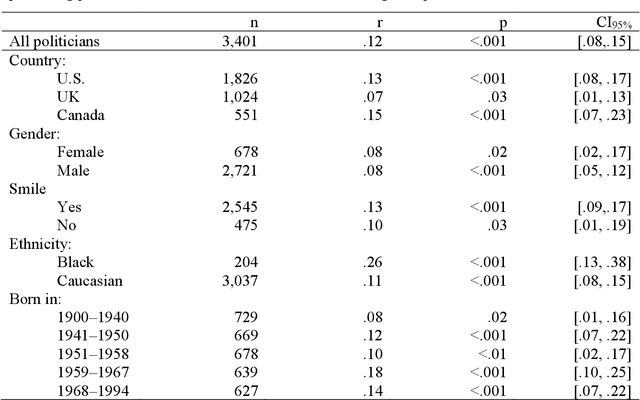
A facial recognition algorithm was used to extract face descriptors from carefully standardized images of 591 neutral faces taken in the laboratory setting. Face descriptors were entered into a cross-validated linear regression to predict participants' scores on a political orientation scale (Cronbach's alpha=.94) while controlling for age, gender, and ethnicity. The model's performance exceeded r=.20: much better than that of human raters and on par with how well job interviews predict job success, alcohol drives aggressiveness, or psychological therapy improves mental health. Moreover, the model derived from standardized images performed well (r=.12) in a sample of naturalistic images of 3,401 politicians from the U.S., UK, and Canada, suggesting that the associations between facial appearance and political orientation generalize beyond our sample. The analysis of facial features associated with political orientation revealed that conservatives had larger lower faces, although political orientation was only weakly associated with body mass index (BMI). The predictability of political orientation from standardized images has critical implications for privacy, regulation of facial recognition technology, as well as the understanding the origins and consequences of political orientation.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023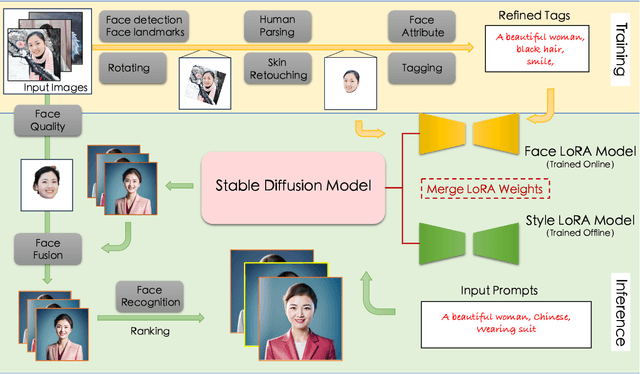

Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.
FACE-AUDITOR: Data Auditing in Facial Recognition Systems
Apr 05, 2023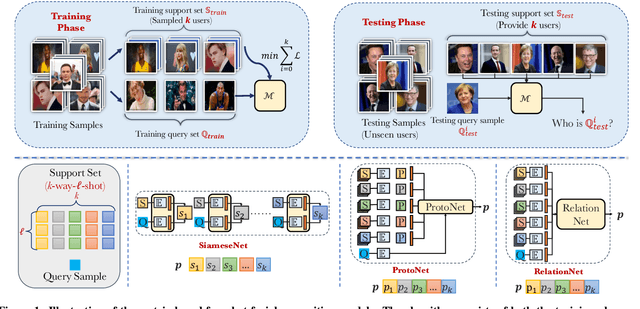

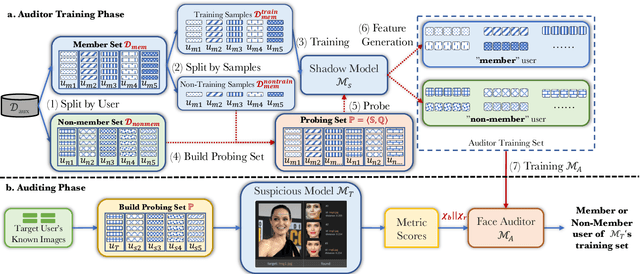
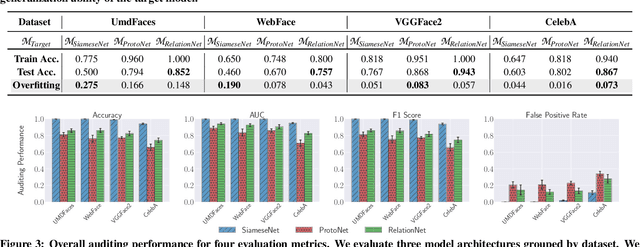
Few-shot-based facial recognition systems have gained increasing attention due to their scalability and ability to work with a few face images during the model deployment phase. However, the power of facial recognition systems enables entities with moderate resources to canvas the Internet and build well-performed facial recognition models without people's awareness and consent. To prevent the face images from being misused, one straightforward approach is to modify the raw face images before sharing them, which inevitably destroys the semantic information, increases the difficulty of retroactivity, and is still prone to adaptive attacks. Therefore, an auditing method that does not interfere with the facial recognition model's utility and cannot be quickly bypassed is urgently needed. In this paper, we formulate the auditing process as a user-level membership inference problem and propose a complete toolkit FACE-AUDITOR that can carefully choose the probing set to query the few-shot-based facial recognition model and determine whether any of a user's face images is used in training the model. We further propose to use the similarity scores between the original face images as reference information to improve the auditing performance. Extensive experiments on multiple real-world face image datasets show that FACE-AUDITOR can achieve auditing accuracy of up to $99\%$. Finally, we show that FACE-AUDITOR is robust in the presence of several perturbation mechanisms to the training images or the target models. The source code of our experiments can be found at \url{https://github.com/MinChen00/Face-Auditor}.