 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Learning to Augment Expressions for Few-shot Fine-grained Facial Expression Recognition
Jan 17, 2020
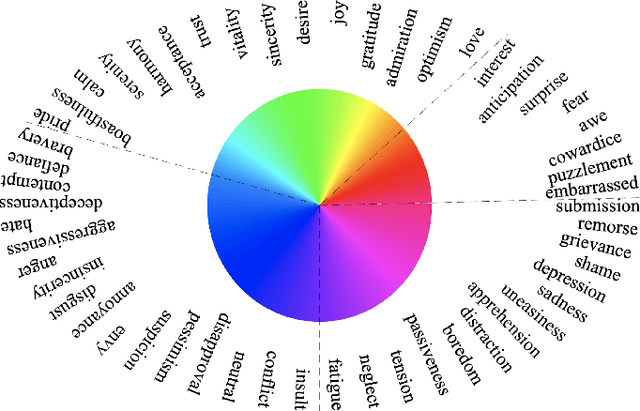
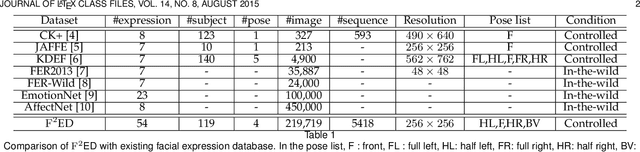
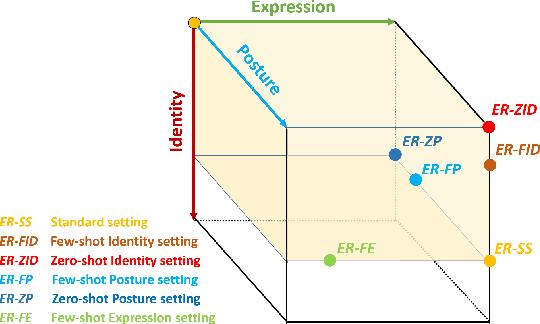
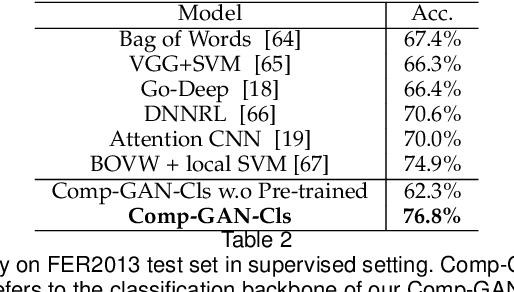
Affective computing and cognitive theory are widely used in modern human-computer interaction scenarios. Human faces, as the most prominent and easily accessible features, have attracted great attention from researchers. Since humans have rich emotions and developed musculature, there exist a lot of fine-grained expressions in real-world applications. However, it is extremely time-consuming to collect and annotate a large number of facial images, of which may even require psychologists to correctly categorize them. To the best of our knowledge, the existing expression datasets are only limited to several basic facial expressions, which are not sufficient to support our ambitions in developing successful human-computer interaction systems. To this end, a novel Fine-grained Facial Expression Database - F2ED is contributed in this paper, and it includes more than 200k images with 54 facial expressions from 119 persons. Considering the phenomenon of uneven data distribution and lack of samples is common in real-world scenarios, we further evaluate several tasks of few-shot expression learning by virtue of our F2ED, which are to recognize the facial expressions given only few training instances. These tasks mimic human performance to learn robust and general representation from few examples. To address such few-shot tasks, we propose a unified task-driven framework - Compositional Generative Adversarial Network (Comp-GAN) learning to synthesize facial images and thus augmenting the instances of few-shot expression classes. Extensive experiments are conducted on F2ED and existing facial expression datasets, i.e., JAFFE and FER2013, to validate the efficacy of our F2ED in pre-training facial expression recognition network and the effectiveness of our proposed approach Comp-GAN to improve the performance of few-shot recognition tasks.
Multiple Emotion Descriptors Estimation at the ABAW3 Challenge
Mar 29, 2022


To describe complex emotional states, psychologists have proposed multiple emotion descriptors: sparse descriptors like facial action units; continuous descriptors like valence and arousal; and discrete class descriptors like happiness and anger. According to Ekman and Friesen, 1969, facial action units are sign vehicles that convey the emotion message, while discrete or continuous emotion descriptors are the messages perceived and expressed by human. In this paper, we designed an architecture for multiple emotion descriptors estimation in participating the ABAW3 Challenge. Based on the theory of Ekman and Friesen, 1969, we designed distinct architectures to measure the sign vehicles (i.e., facial action units) and the message (i.e., discrete emotions, valence and arousal) given their different properties. The quantitative experiments on the ABAW3 challenge dataset has shown the superior performance of our approach over two baseline models.
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
Jul 18, 2022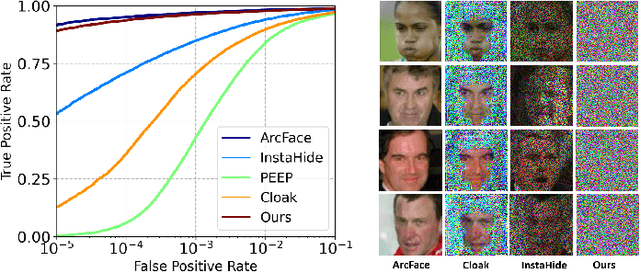

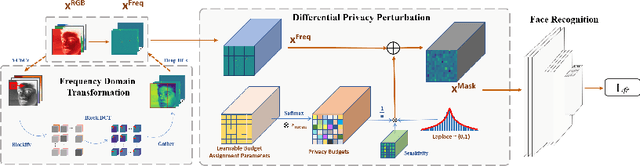
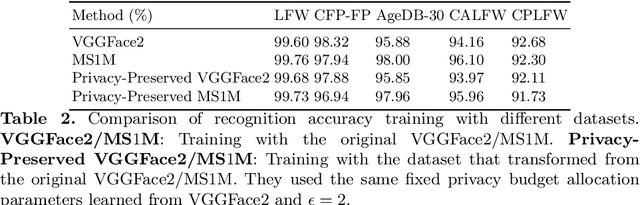
Face recognition technology has been used in many fields due to its high recognition accuracy, including the face unlocking of mobile devices, community access control systems, and city surveillance. As the current high accuracy is guaranteed by very deep network structures, facial images often need to be transmitted to third-party servers with high computational power for inference. However, facial images visually reveal the user's identity information. In this process, both untrusted service providers and malicious users can significantly increase the risk of a personal privacy breach. Current privacy-preserving approaches to face recognition are often accompanied by many side effects, such as a significant increase in inference time or a noticeable decrease in recognition accuracy. This paper proposes a privacy-preserving face recognition method using differential privacy in the frequency domain. Due to the utilization of differential privacy, it offers a guarantee of privacy in theory. Meanwhile, the loss of accuracy is very slight. This method first converts the original image to the frequency domain and removes the direct component termed DC. Then a privacy budget allocation method can be learned based on the loss of the back-end face recognition network within the differential privacy framework. Finally, it adds the corresponding noise to the frequency domain features. Our method performs very well with several classical face recognition test sets according to the extensive experiments.
Masked Linear Regression for Learning Local Receptive Fields for Facial Expression Synthesis
Nov 18, 2020

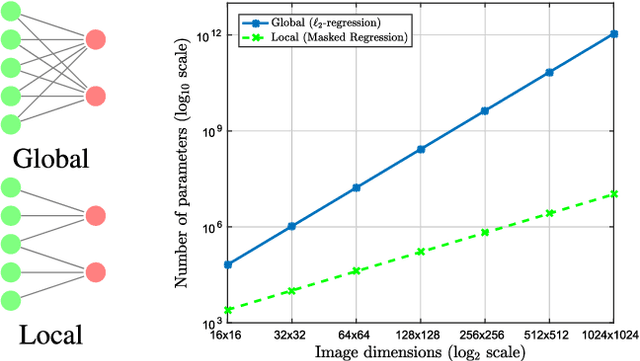
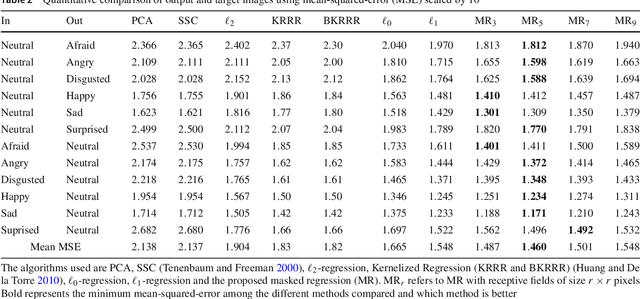
Compared to facial expression recognition, expression synthesis requires a very high-dimensional mapping. This problem exacerbates with increasing image sizes and limits existing expression synthesis approaches to relatively small images. We observe that facial expressions often constitute sparsely distributed and locally correlated changes from one expression to another. By exploiting this observation, the number of parameters in an expression synthesis model can be significantly reduced. Therefore, we propose a constrained version of ridge regression that exploits the local and sparse structure of facial expressions. We consider this model as masked regression for learning local receptive fields. In contrast to the existing approaches, our proposed model can be efficiently trained on larger image sizes. Experiments using three publicly available datasets demonstrate that our model is significantly better than $\ell_0, \ell_1$ and $\ell_2$-regression, SVD based approaches, and kernelized regression in terms of mean-squared-error, visual quality as well as computational and spatial complexities. The reduction in the number of parameters allows our method to generalize better even after training on smaller datasets. The proposed algorithm is also compared with state-of-the-art GANs including Pix2Pix, CycleGAN, StarGAN and GANimation. These GANs produce photo-realistic results as long as the testing and the training distributions are similar. In contrast, our results demonstrate significant generalization of the proposed algorithm over out-of-dataset human photographs, pencil sketches and even animal faces.
* IJCV Journal
FLNet: Landmark Driven Fetching and Learning Network for Faithful Talking Facial Animation Synthesis
Nov 21, 2019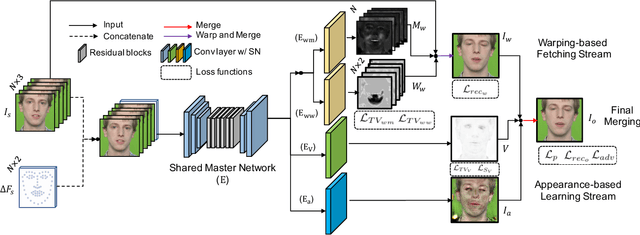
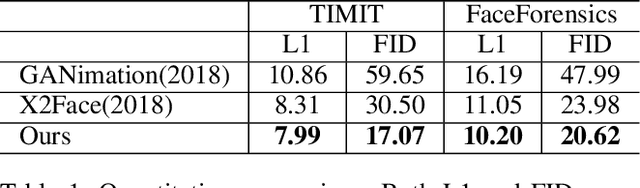


Talking face synthesis has been widely studied in either appearance-based or warping-based methods. Previous works mostly utilize single face image as a source, and generate novel facial animations by merging other person's facial features. However, some facial regions like eyes or teeth, which may be hidden in the source image, can not be synthesized faithfully and stably. In this paper, We present a landmark driven two-stream network to generate faithful talking facial animation, in which more facial details are created, preserved and transferred from multiple source images instead of a single one. Specifically, we propose a network consisting of a learning and fetching stream. The fetching sub-net directly learns to attentively warp and merge facial regions from five source images of distinctive landmarks, while the learning pipeline renders facial organs from the training face space to compensate. Compared to baseline algorithms, extensive experiments demonstrate that the proposed method achieves a higher performance both quantitatively and qualitatively. Codes are at https://github.com/kgu3/FLNet_AAAI2020.
LatentGaze: Cross-Domain Gaze Estimation through Gaze-Aware Analytic Latent Code Manipulation
Sep 21, 2022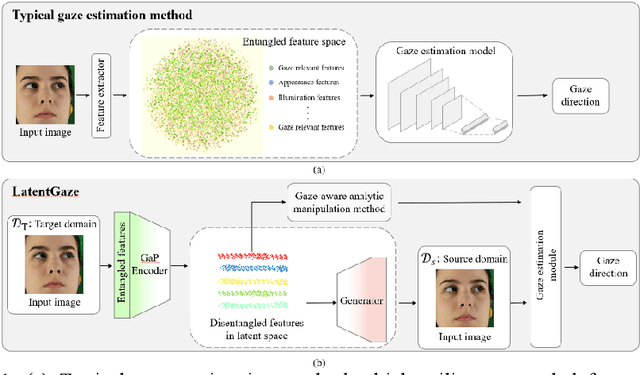
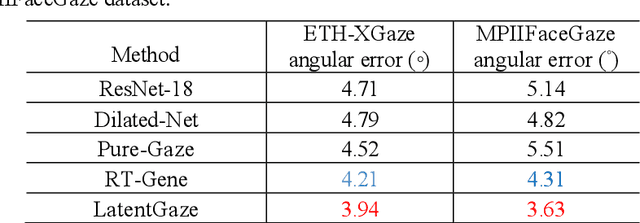
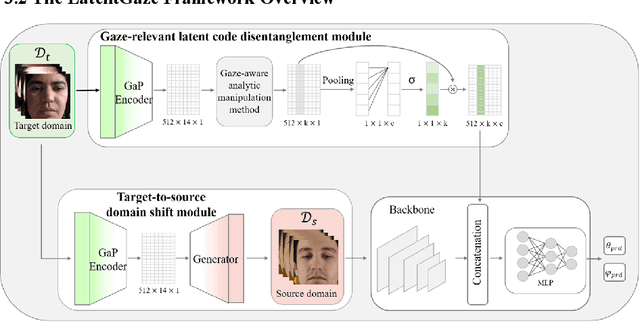
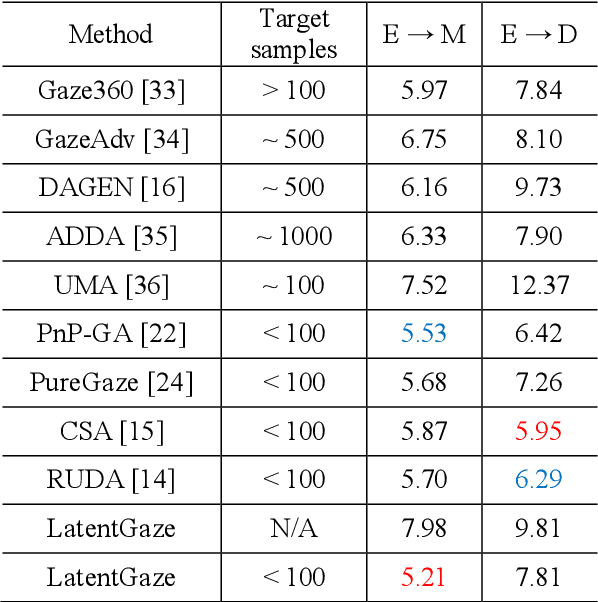
Although recent gaze estimation methods lay great emphasis on attentively extracting gaze-relevant features from facial or eye images, how to define features that include gaze-relevant components has been ambiguous. This obscurity makes the model learn not only gaze-relevant features but also irrelevant ones. In particular, it is fatal for the cross-dataset performance. To overcome this challenging issue, we propose a gaze-aware analytic manipulation method, based on a data-driven approach with generative adversarial network inversion's disentanglement characteristics, to selectively utilize gaze-relevant features in a latent code. Furthermore, by utilizing GAN-based encoder-generator process, we shift the input image from the target domain to the source domain image, which a gaze estimator is sufficiently aware. In addition, we propose gaze distortion loss in the encoder that prevents the distortion of gaze information. The experimental results demonstrate that our method achieves state-of-the-art gaze estimation accuracy in a cross-domain gaze estimation tasks. This code is available at https://github.com/leeisack/LatentGaze/.
Photo-Realistic Facial Details Synthesis from Single Immage
Mar 26, 2019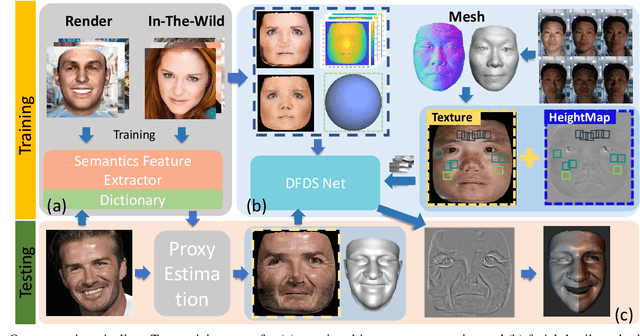
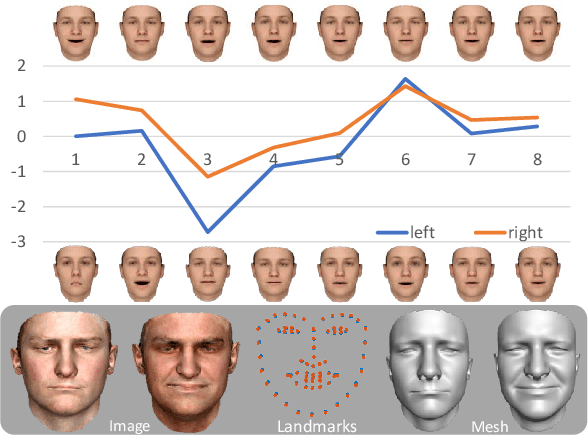
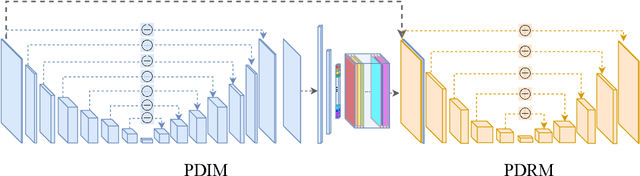

We present a single-image 3D face synthesis technique that can handle challenging facial expressions while recovering fine geometric details. Our technique employs expression analysis for proxy face geometry generation and combines supervised and unsupervised learning for facial detail synthesis. On proxy generation, we conduct emotion prediction to determine a new expression-informed proxy. On detail synthesis, we present a Deep Facial Detail Net (DFDN) based on Conditional Generative Adversarial Net (CGAN) that employs both geometry and appearance loss functions. For geometry, we capture 366 high-quality 3D scans from 122 different subjects under 3 facial expressions. For appearance, we use additional 20K in-the-wild face images and apply image-based rendering to accommodate lighting variations. Comprehensive experiments demonstrate that our framework can produce high-quality 3D faces with realistic details under challenging facial expressions.
Using Crowdsourcing to Train Facial Emotion Machine Learning Models with Ambiguous Labels
Jan 10, 2021
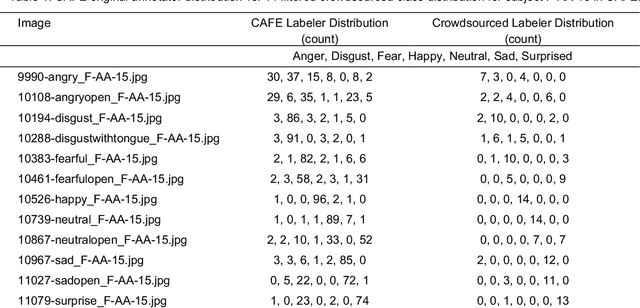
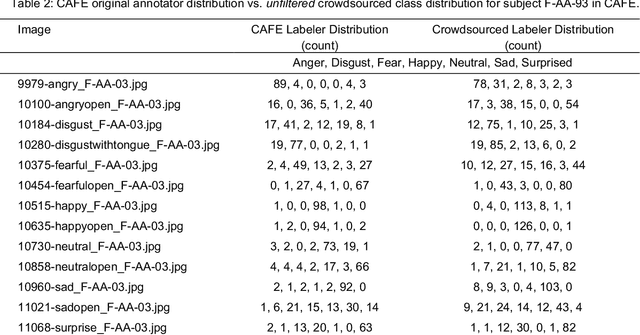
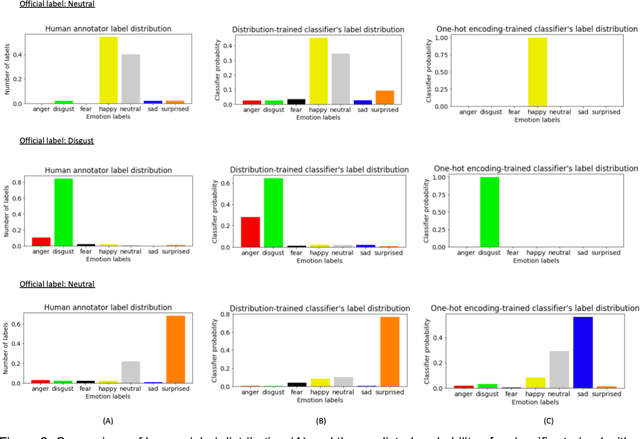
Current emotion detection classifiers predict discrete emotions. However, literature in psychology has documented that compound and ambiguous facial expressions are often evoked by humans. As a stride towards development of machine learning models that more accurately reflect compound and ambiguous emotions, we replace traditional one-hot encoded label representations with a crowd's distribution of labels. We center our study on the Child Affective Facial Expression (CAFE) dataset, a gold standard dataset of pediatric facial expressions which includes 100 human labels per image. We first acquire crowdsourced labels for 207 emotions from CAFE and demonstrate that the consensus labels from the crowd tend to match the consensus from the original CAFE raters, validating the utility of crowdsourcing. We then train two versions of a ResNet-152 classifier on CAFE images with two types of labels (1) traditional one-hot encoding and (2) vector labels representing the crowd distribution of responses. We compare the resulting output distributions of the two classifiers. While the traditional F1-score for the one-hot encoding classifier is much higher (94.33% vs. 78.68%), the output probability vector of the crowd-trained classifier much more closely resembles the distribution of human labels (t=3.2827, p=0.0014). For many applications of affective computing, reporting an emotion probability distribution that more closely resembles human interpretation can be more important than traditional machine learning metrics. This work is a first step for engineers of interactive systems to account for machine learning cases with ambiguous classes and we hope it will generate a discussion about machine learning with ambiguous labels and leveraging crowdsourcing as a potential solution.
Lagrangian Motion Magnification with Double Sparse Optical Flow Decomposition
Apr 15, 2022
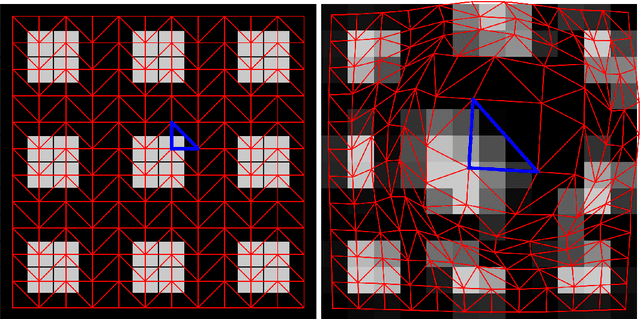
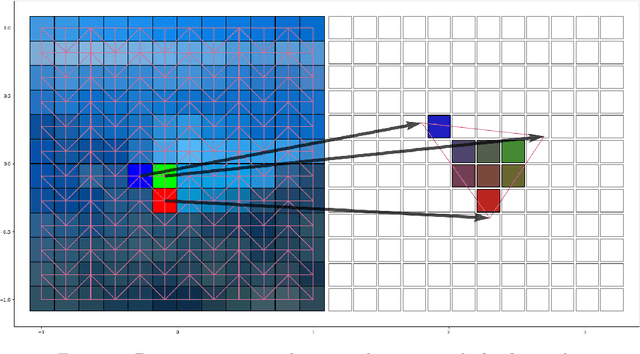
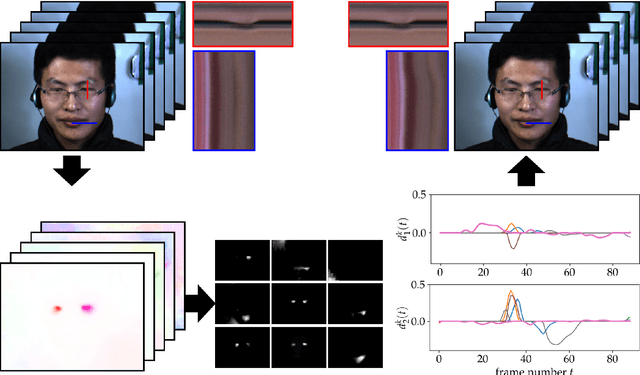
Motion magnification techniques aim at amplifying and hence revealing subtle motion in videos. There are basically two main approaches to reach this goal, namely via Eulerian or Lagrangian techniques. While the first one magnifies motion implicitly by operating directly on image pixels, the Lagrangian approach uses optical flow techniques to extract and amplify pixel trajectories. Microexpressions are fast and spatially small facial expressions that are difficult to detect. In this paper, we propose a novel approach for local Lagrangian motion magnification of facial micromovements. Our contribution is three-fold: first, we fine-tune the recurrent all-pairs field transforms for optical flows (RAFT) deep learning approach for faces by adding ground truth obtained from the variational dense inverse search (DIS) for optical flow algorithm applied to the CASME II video set of faces. This enables us to produce optical flows of facial videos in an efficient and sufficiently accurate way. Second, since facial micromovements are both local in space and time, we propose to approximate the optical flow field by sparse components both in space and time leading to a double sparse decomposition. Third, we use this decomposition to magnify micro-motions in specific areas of the face, where we introduce a new forward warping strategy using a triangular splitting of the image grid and barycentric interpolation of the RGB vectors at the corners of the transformed triangles. We demonstrate the very good performance of our approach by various examples.
Salient Facial Features from Humans and Deep Neural Networks
Mar 08, 2020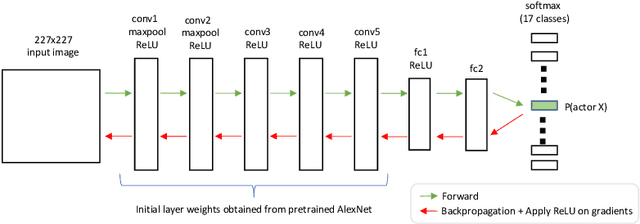


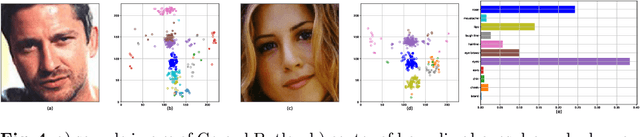
In this work, we explore the features that are used by humans and by convolutional neural networks (ConvNets) to classify faces. We use Guided Backpropagation (GB) to visualize the facial features that influence the output of a ConvNet the most when identifying specific individuals; we explore how to best use GB for that purpose. We use a human intelligence task to find out which facial features humans find to be the most important for identifying specific individuals. We explore the differences between the saliency information gathered from humans and from ConvNets. Humans develop biases in employing available information on facial features to discriminate across faces. Studies show these biases are influenced both by neurological development and by each individual's social experience. In recent years the computer vision community has achieved human-level performance in many face processing tasks with deep neural network-based models. These face processing systems are also subject to systematic biases due to model architectural choices and training data distribution.