 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Fairness Increases Adversarial Vulnerability
Nov 23, 2022
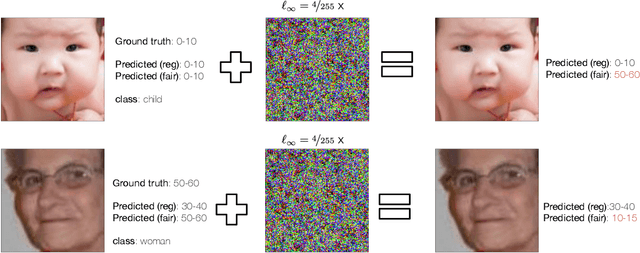

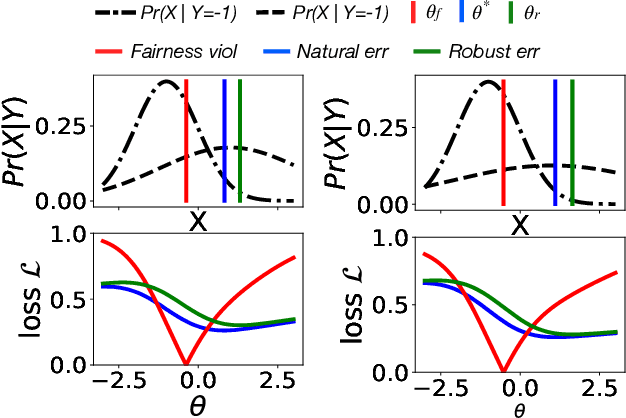
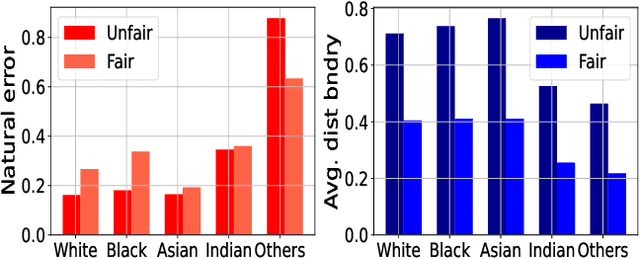
The remarkable performance of deep learning models and their applications in consequential domains (e.g., facial recognition) introduces important challenges at the intersection of equity and security. Fairness and robustness are two desired notions often required in learning models. Fairness ensures that models do not disproportionately harm (or benefit) some groups over others, while robustness measures the models' resilience against small input perturbations. This paper shows the existence of a dichotomy between fairness and robustness, and analyzes when achieving fairness decreases the model robustness to adversarial samples. The reported analysis sheds light on the factors causing such contrasting behavior, suggesting that distance to the decision boundary across groups as a key explainer for this behavior. Extensive experiments on non-linear models and different architectures validate the theoretical findings in multiple vision domains. Finally, the paper proposes a simple, yet effective, solution to construct models achieving good tradeoffs between fairness and robustness.
Learning Vision Transformer with Squeeze and Excitation for Facial Expression Recognition
Jul 08, 2021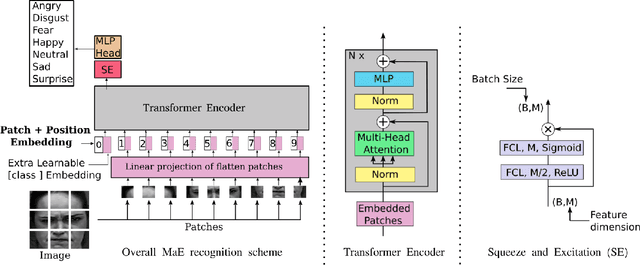
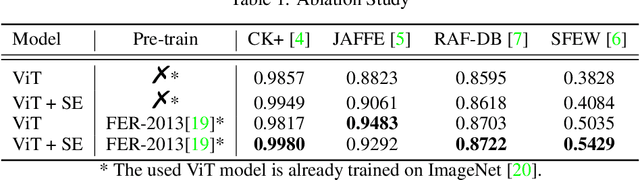
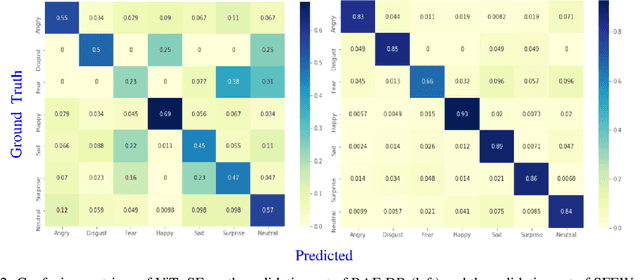
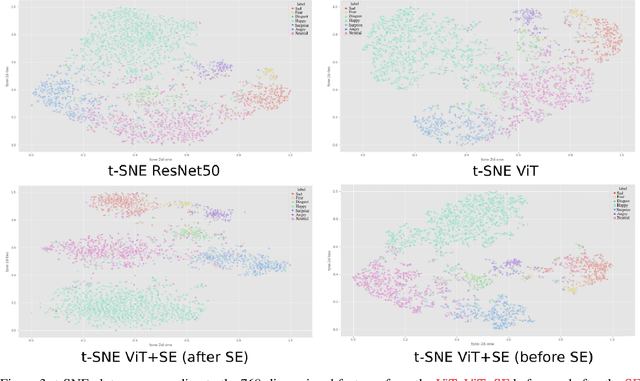
As various databases of facial expressions have been made accessible over the last few decades, the Facial Expression Recognition (FER) task has gotten a lot of interest. The multiple sources of the available databases raised several challenges for facial recognition task. These challenges are usually addressed by Convolution Neural Network (CNN) architectures. Different from CNN models, a Transformer model based on attention mechanism has been presented recently to address vision tasks. One of the major issue with Transformers is the need of a large data for training, while most FER databases are limited compared to other vision applications. Therefore, we propose in this paper to learn a vision Transformer jointly with a Squeeze and Excitation (SE) block for FER task. The proposed method is evaluated on different publicly available FER databases including CK+, JAFFE,RAF-DB and SFEW. Experiments demonstrate that our model outperforms state-of-the-art methods on CK+ and SFEW and achieves competitive results on JAFFE and RAF-DB.
Adults as Augmentations for Children in Facial Emotion Recognition with Contrastive Learning
Feb 10, 2022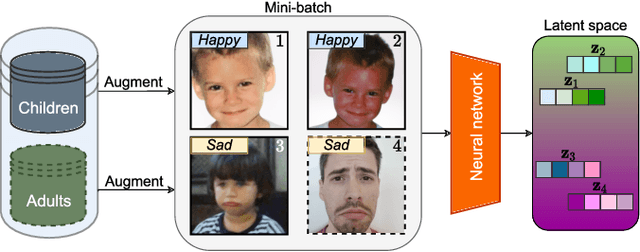
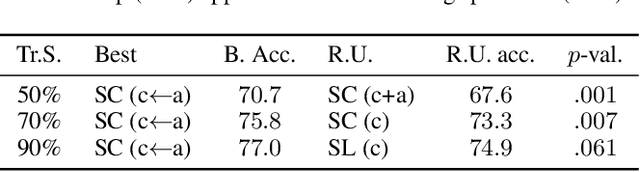
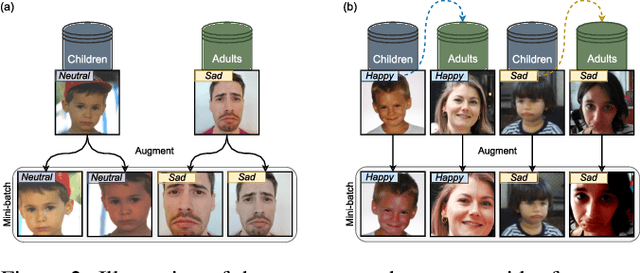
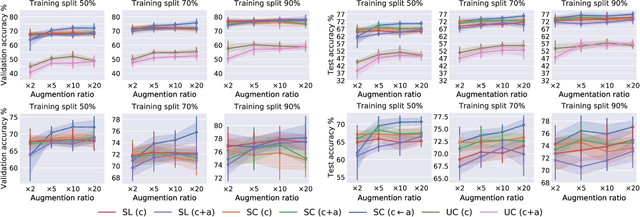
Emotion recognition in children can help the early identification of, and intervention on, psychological complications that arise in stressful situations such as cancer treatment. Though deep learning models are increasingly being adopted, data scarcity is often an issue in pediatric medicine, including for facial emotion recognition in children. In this paper, we study the application of data augmentation-based contrastive learning to overcome data scarcity in facial emotion recognition for children. We explore the idea of ignoring generational gaps, by adding abundantly available adult data to pediatric data, to learn better representations. We investigate different ways by which adult facial expression images can be used alongside those of children. In particular, we propose to explicitly incorporate within each mini-batch adult images as augmentations for children's. Out of $84$ combinations of learning approaches and training set sizes, we find that supervised contrastive learning with the proposed training scheme performs best, reaching a test accuracy that typically surpasses the one of the second-best approach by 2% to 3%. Our results indicate that adult data can be considered to be a meaningful augmentation of pediatric data for the recognition of emotional facial expression in children, and open up the possibility for other applications of contrastive learning to improve pediatric care by complementing data of children with that of adults.
A Novel Exploitative and Explorative GWO-SVM Algorithm for Smart Emotion Recognition
Jan 05, 2023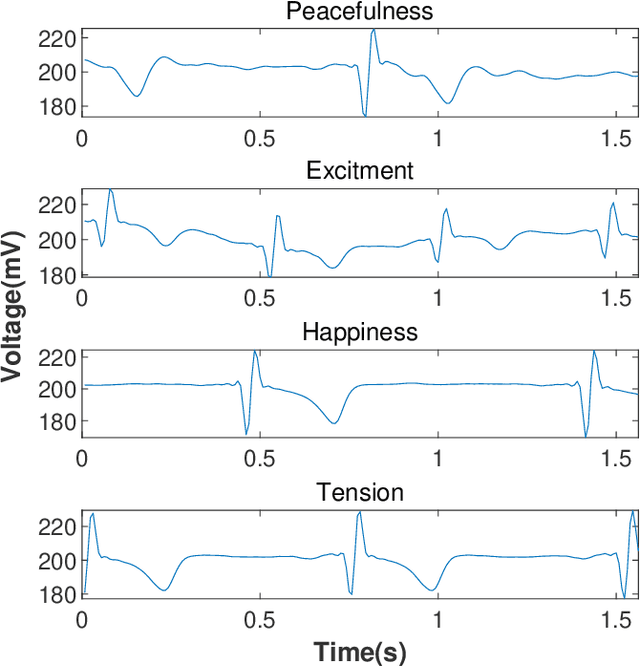
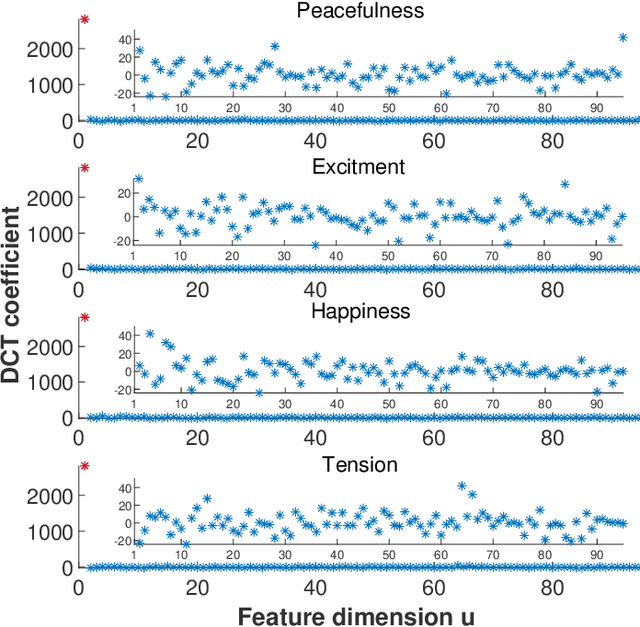
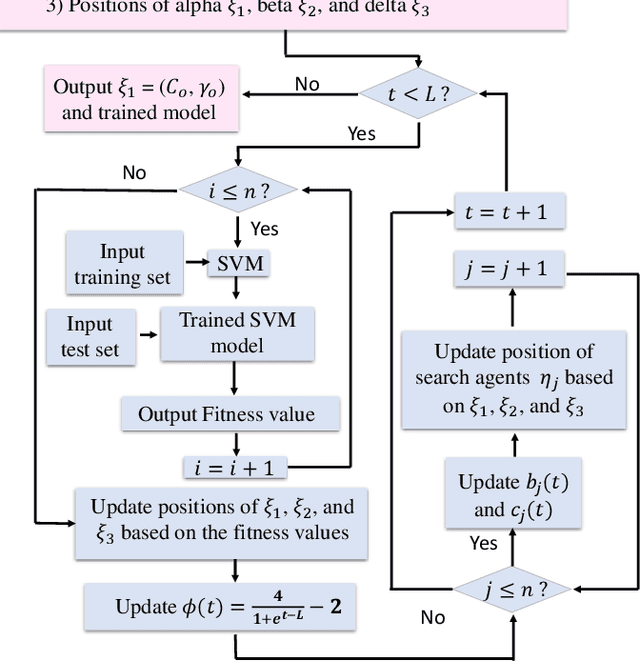
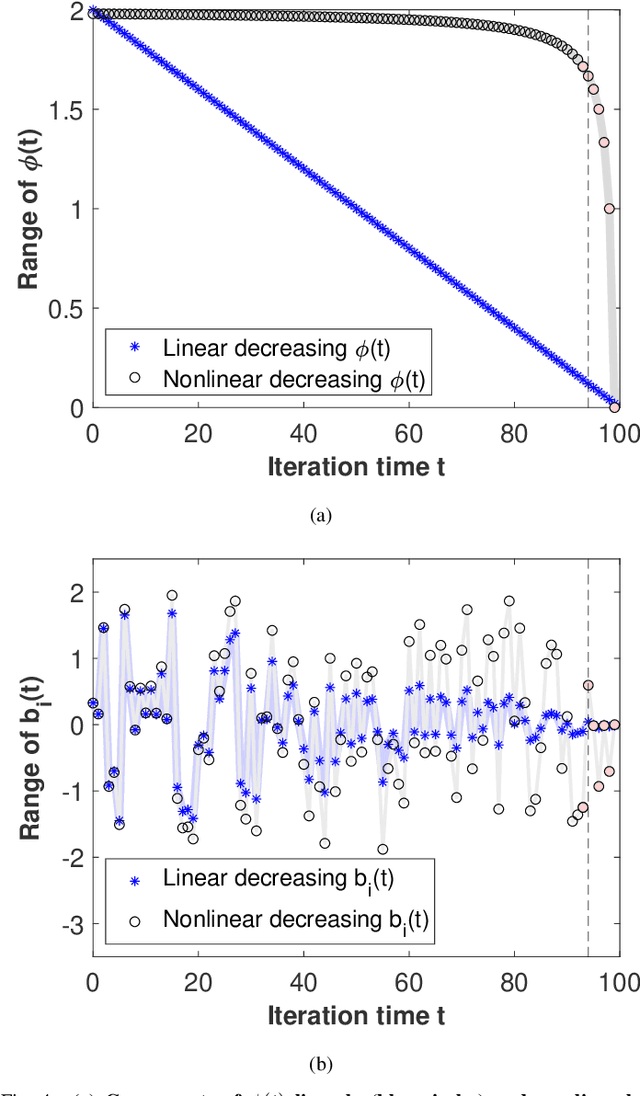
Emotion recognition or detection is broadly utilized in patient-doctor interactions for diseases such as schizophrenia and autism and the most typical techniques are speech detection and facial recognition. However, features extracted from these behavior-based emotion recognitions are not reliable since humans can disguise their emotions. Recording voices or tracking facial expressions for a long term is also not efficient. Therefore, our aim is to find a reliable and efficient emotion recognition scheme, which can be used for non-behavior-based emotion recognition in real-time. This can be solved by implementing a single-channel electrocardiogram (ECG) based emotion recognition scheme in a lightweight embedded system. However, existing schemes have relatively low accuracy. Therefore, we propose a reliable and efficient emotion recognition scheme - exploitative and explorative grey wolf optimizer based SVM (X - GWO - SVM) for ECG-based emotion recognition. Two datasets, one raw self-collected iRealcare dataset, and the widely-used benchmark WESAD dataset are used in the X - GWO - SVM algorithm for emotion recognition. This work demonstrates that the X - GWO - SVM algorithm can be used for emotion recognition and the algorithm exhibits superior performance in reliability compared to the use of other supervised machine learning methods in earlier works. It can be implemented in a lightweight embedded system, which is much more efficient than existing solutions based on deep neural networks.
MARLIN: Masked Autoencoder for facial video Representation LearnINg
Nov 12, 2022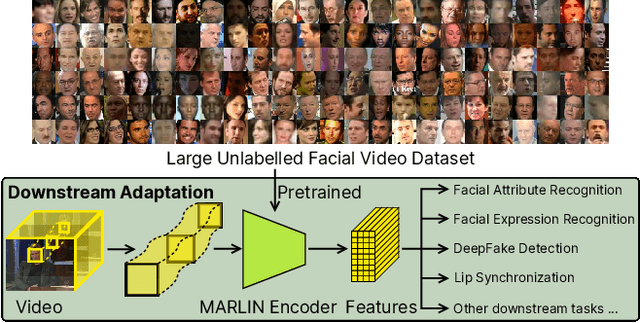
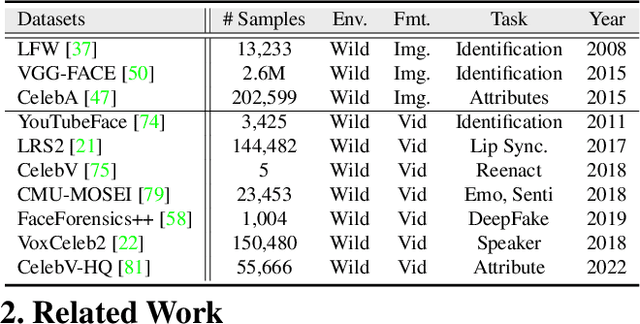

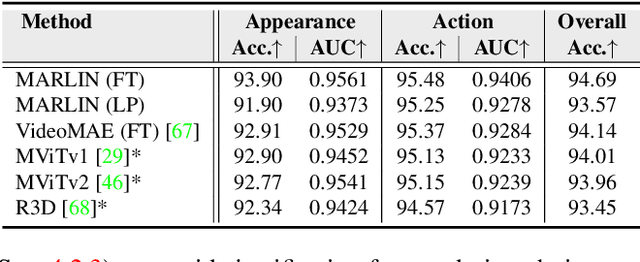
This paper proposes a self-supervised approach to learn universal facial representations from videos, that can transfer across a variety of facial analysis tasks such as Facial Attribute Recognition (FAR), Facial Expression Recognition (FER), DeepFake Detection (DFD), and Lip Synchronization (LS). Our proposed framework, named MARLIN, is a facial video masked autoencoder, that learns highly robust and generic facial embeddings from abundantly available non-annotated web crawled facial videos. As a challenging auxiliary task, MARLIN reconstructs the spatio-temporal details of the face from the densely masked facial regions which mainly include eyes, nose, mouth, lips, and skin to capture local and global aspects that in turn help in encoding generic and transferable features. Through a variety of experiments on diverse downstream tasks, we demonstrate MARLIN to be an excellent facial video encoder as well as feature extractor, that performs consistently well across a variety of downstream tasks including FAR (1.13% gain over supervised benchmark), FER (2.64% gain over unsupervised benchmark), DFD (1.86% gain over unsupervised benchmark), LS (29.36% gain for Frechet Inception Distance), and even in low data regime. Our codes and pre-trained models will be made public.
Facial Expression Recognition using Vanilla ViT backbones with MAE Pretraining
Jul 22, 2022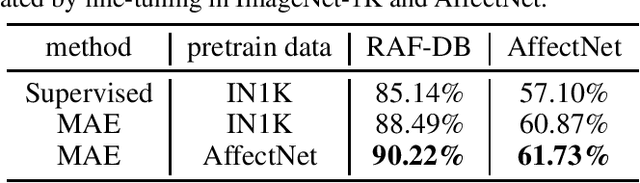
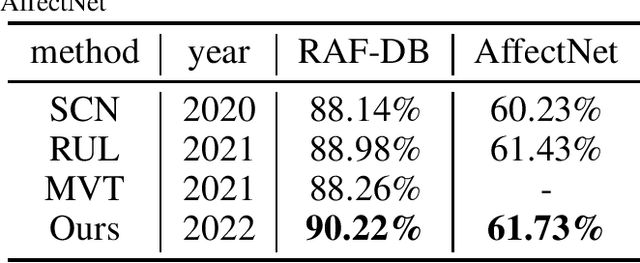
Humans usually convey emotions voluntarily or involuntarily by facial expressions. Automatically recognizing the basic expression (such as happiness, sadness, and neutral) from a facial image, i.e., facial expression recognition (FER), is extremely challenging and attracts much research interests. Large scale datasets and powerful inference models have been proposed to address the problem. Though considerable progress has been made, most of the state of the arts employing convolutional neural networks (CNNs) or elaborately modified Vision Transformers (ViTs) depend heavily on upstream supervised pretraining. Transformers are taking place the domination of CNNs in more and more computer vision tasks. But they usually need much more data to train, since they use less inductive biases compared with CNNs. To explore whether a vanilla ViT without extra training samples from upstream tasks is able to achieve competitive accuracy, we use a plain ViT with MAE pretraining to perform the FER task. Specifically, we first pretrain the original ViT as a Masked Autoencoder (MAE) on a large facial expression dataset without expression labels. Then, we fine-tune the ViT on popular facial expression datasets with expression labels. The presented method is quite competitive with 90.22\% on RAF-DB, 61.73\% on AfectNet and can serve as a simple yet strong ViT-based baseline for FER studies.
Unsupervised Facial Expression Representation Learning with Contrastive Local Warping
Mar 16, 2023
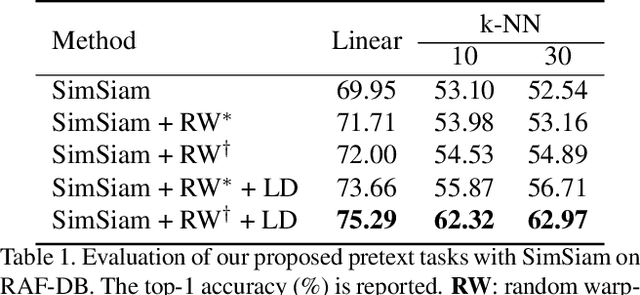
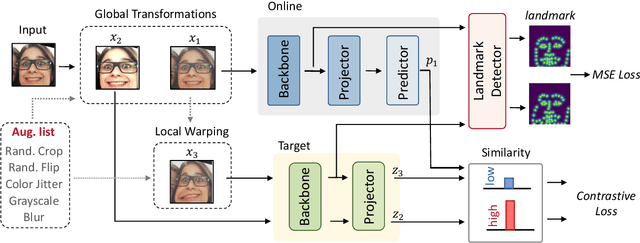
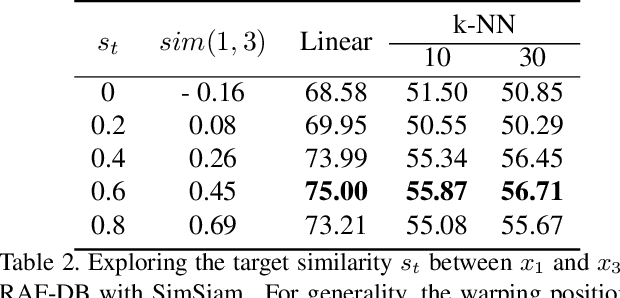
This paper investigates unsupervised representation learning for facial expression analysis. We think Unsupervised Facial Expression Representation (UFER) deserves exploration and has the potential to address some key challenges in facial expression analysis, such as scaling, annotation bias, the discrepancy between discrete labels and continuous emotions, and model pre-training. Such motivated, we propose a UFER method with contrastive local warping (ContraWarping), which leverages the insight that the emotional expression is robust to current global transformation (affine transformation, color jitter, etc.) but can be easily changed by random local warping. Therefore, given a facial image, ContraWarping employs some global transformations and local warping to generate its positive and negative samples and sets up a novel contrastive learning framework. Our in-depth investigation shows that: 1) the positive pairs from global transformations may be exploited with general self-supervised learning (e.g., BYOL) and already bring some informative features, and 2) the negative pairs from local warping explicitly introduce expression-related variation and further bring substantial improvement. Based on ContraWarping, we demonstrate the benefit of UFER under two facial expression analysis scenarios: facial expression recognition and image retrieval. For example, directly using ContraWarping features for linear probing achieves 79.14% accuracy on RAF-DB, significantly reducing the gap towards the full-supervised counterpart (88.92% / 84.81% with/without pre-training).
Cascaded Asymmetric Local Pattern: A Novel Descriptor for Unconstrained Facial Image Recognition and Retrieval
Jan 03, 2022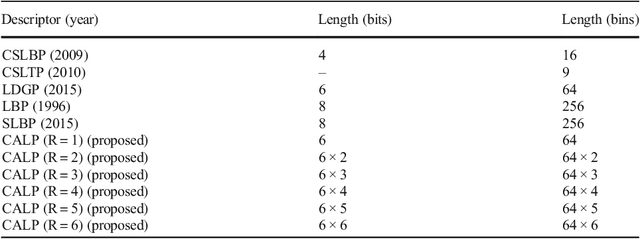
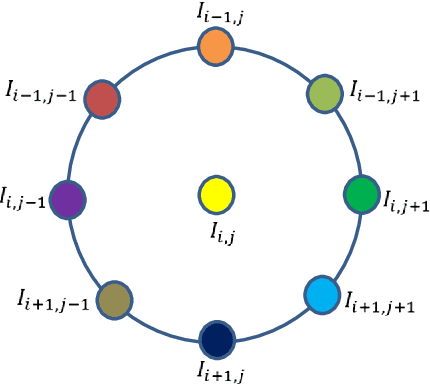
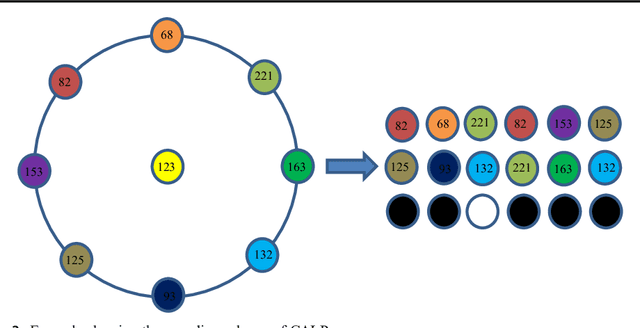

Feature description is one of the most frequently studied areas in the expert systems and machine learning. Effective encoding of the images is an essential requirement for accurate matching. These encoding schemes play a significant role in recognition and retrieval systems. Facial recognition systems should be effective enough to accurately recognize individuals under intrinsic and extrinsic variations of the system. The templates or descriptors used in these systems encode spatial relationships of the pixels in the local neighbourhood of an image. Features encoded using these hand crafted descriptors should be robust against variations such as; illumination, background, poses, and expressions. In this paper a novel hand crafted cascaded asymmetric local pattern (CALP) is proposed for retrieval and recognition facial image. The proposed descriptor uniquely encodes relationship amongst the neighbouring pixels in horizontal and vertical directions. The proposed encoding scheme has optimum feature length and shows significant improvement in accuracy under environmental and physiological changes in a facial image. State of the art hand crafted descriptors namely; LBP, LDGP, CSLBP, SLBP and CSLTP are compared with the proposed descriptor on most challenging datasets namely; Caltech-face, LFW, and CASIA-face-v5. Result analysis shows that, the proposed descriptor outperforms state of the art under uncontrolled variations in expressions, background, pose and illumination.
InMyFace: Inertial and Mechanomyography-Based Sensor Fusion for Wearable Facial Activity Recognition
Feb 08, 2023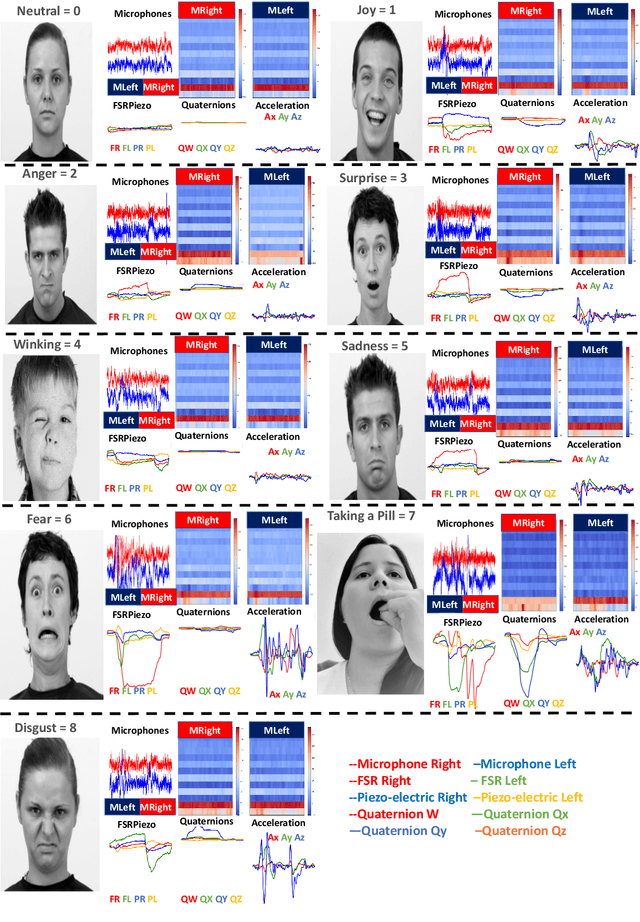
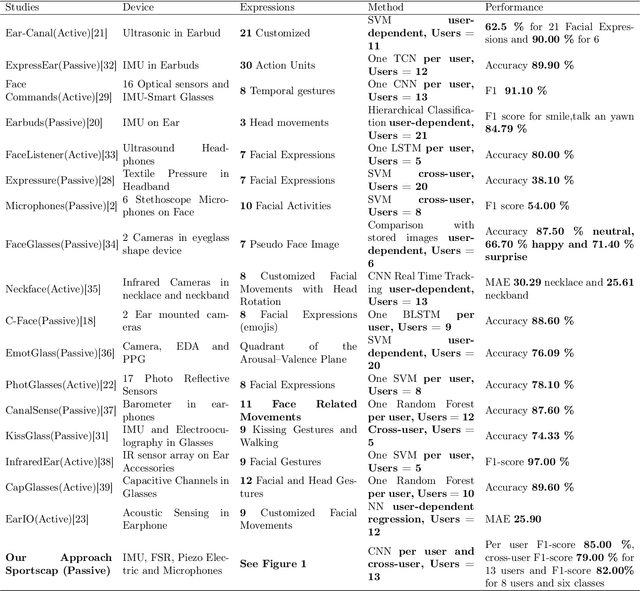
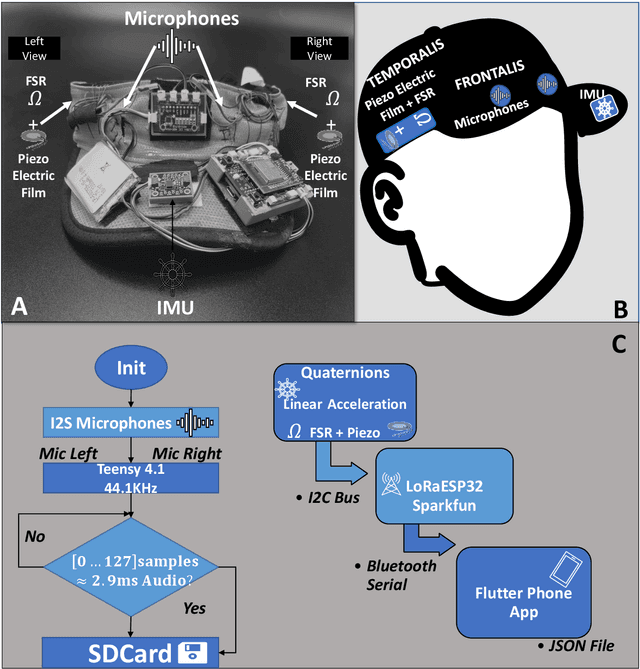
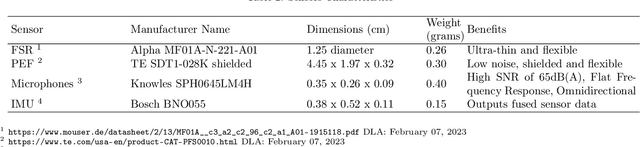
Recognizing facial activity is a well-understood (but non-trivial) computer vision problem. However, reliable solutions require a camera with a good view of the face, which is often unavailable in wearable settings. Furthermore, in wearable applications, where systems accompany users throughout their daily activities, a permanently running camera can be problematic for privacy (and legal) reasons. This work presents an alternative solution based on the fusion of wearable inertial sensors, planar pressure sensors, and acoustic mechanomyography (muscle sounds). The sensors were placed unobtrusively in a sports cap to monitor facial muscle activities related to facial expressions. We present our integrated wearable sensor system, describe data fusion and analysis methods, and evaluate the system in an experiment with thirteen subjects from different cultural backgrounds (eight countries) and both sexes (six women and seven men). In a one-model-per-user scheme and using a late fusion approach, the system yielded an average F1 score of 85.00% for the case where all sensing modalities are combined. With a cross-user validation and a one-model-for-all-user scheme, an F1 score of 79.00% was obtained for thirteen participants (six females and seven males). Moreover, in a hybrid fusion (cross-user) approach and six classes, an average F1 score of 82.00% was obtained for eight users. The results are competitive with state-of-the-art non-camera-based solutions for a cross-user study. In addition, our unique set of participants demonstrates the inclusiveness and generalizability of the approach.
An optimized Capsule-LSTM model for facial expression recognition with video sequences
May 27, 2021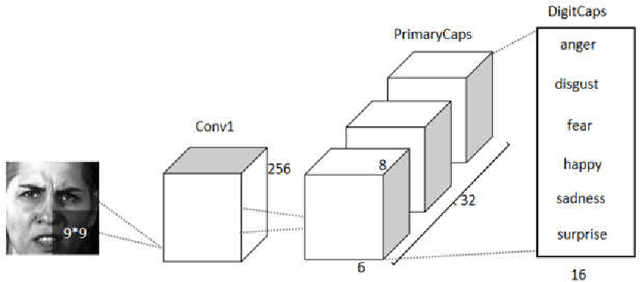
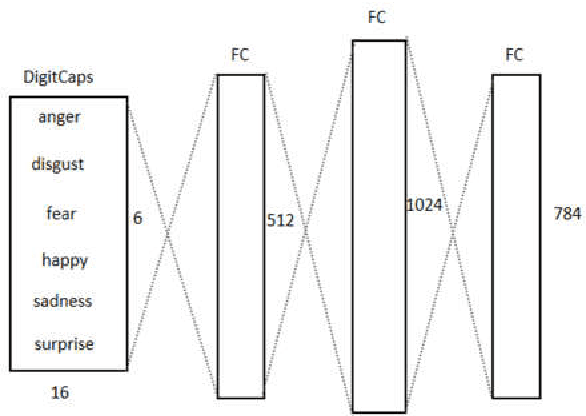
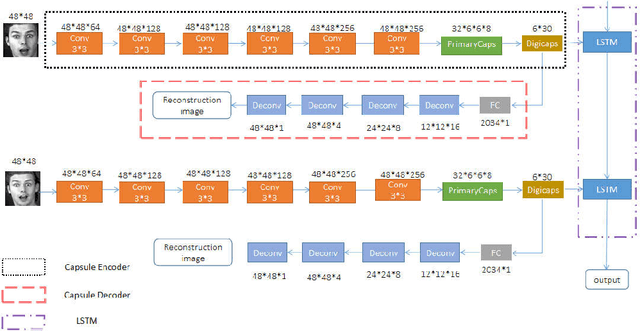

To overcome the limitations of convolutional neural network in the process of facial expression recognition, a facial expression recognition model Capsule-LSTM based on video frame sequence is proposed. This model is composed of three networks includingcapsule encoders, capsule decoders and LSTM network. The capsule encoder extracts the spatial information of facial expressions in video frames. Capsule decoder reconstructs the images to optimize the network. LSTM extracts the temporal information between video frames and analyzes the differences in expression changes between frames. The experimental results from the MMI dataset show that the Capsule-LSTM model proposed in this paper can effectively improve the accuracy of video expression recognition.