 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
Oct 26, 2023
Imitation learning from a large set of human demonstrations has proved to be an effective paradigm for building capable robot agents. However, the demonstrations can be extremely costly and time-consuming to collect. We introduce MimicGen, a system for automatically synthesizing large-scale, rich datasets from only a small number of human demonstrations by adapting them to new contexts. We use MimicGen to generate over 50K demonstrations across 18 tasks with diverse scene configurations, object instances, and robot arms from just ~200 human demonstrations. We show that robot agents can be effectively trained on this generated dataset by imitation learning to achieve strong performance in long-horizon and high-precision tasks, such as multi-part assembly and coffee preparation, across broad initial state distributions. We further demonstrate that the effectiveness and utility of MimicGen data compare favorably to collecting additional human demonstrations, making it a powerful and economical approach towards scaling up robot learning. Datasets, simulation environments, videos, and more at https://mimicgen.github.io .
Automatic Logical Forms improve fidelity in Table-to-Text generation
Oct 26, 2023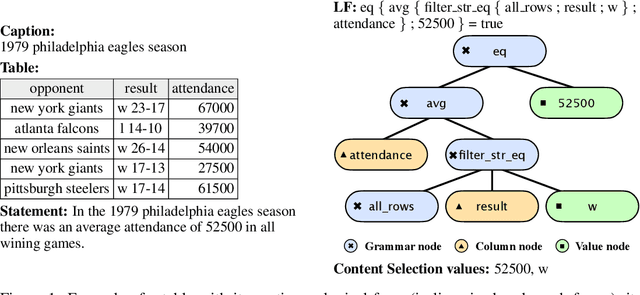


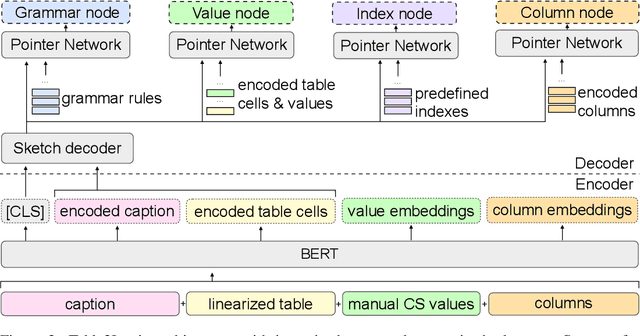
Table-to-text systems generate natural language statements from structured data like tables. While end-to-end techniques suffer from low factual correctness (fidelity), a previous study reported gains when using manual logical forms (LF) that represent the selected content and the semantics of the target text. Given the manual step, it was not clear whether automatic LFs would be effective, or whether the improvement came from content selection alone. We present TlT which, given a table and a selection of the content, first produces LFs and then the textual statement. We show for the first time that automatic LFs improve quality, with an increase in fidelity of 30 points over a comparable system not using LFs. Our experiments allow to quantify the remaining challenges for high factual correctness, with automatic selection of content coming first, followed by better Logic-to-Text generation and, to a lesser extent, better Table-to-Logic parsing.
A Unique Training Strategy to Enhance Language Models Capabilities for Health Mention Detection from Social Media Content
Oct 29, 2023An ever-increasing amount of social media content requires advanced AI-based computer programs capable of extracting useful information. Specifically, the extraction of health-related content from social media is useful for the development of diverse types of applications including disease spread, mortality rate prediction, and finding the impact of diverse types of drugs on diverse types of diseases. Language models are competent in extracting the syntactic and semantics of text. However, they face a hard time extracting similar patterns from social media texts. The primary reason for this shortfall lies in the non-standardized writing style commonly employed by social media users. Following the need for an optimal language model competent in extracting useful patterns from social media text, the key goal of this paper is to train language models in such a way that they learn to derive generalized patterns. The key goal is achieved through the incorporation of random weighted perturbation and contrastive learning strategies. On top of a unique training strategy, a meta predictor is proposed that reaps the benefits of 5 different language models for discriminating posts of social media text into non-health and health-related classes. Comprehensive experimentation across 3 public benchmark datasets reveals that the proposed training strategy improves the performance of the language models up to 3.87%, in terms of F1-score, as compared to their performance with traditional training. Furthermore, the proposed meta predictor outperforms existing health mention classification predictors across all 3 benchmark datasets.
Optimal Best Arm Identification with Fixed Confidence in Restless Bandits
Oct 20, 2023We study best arm identification in a restless multi-armed bandit setting with finitely many arms. The discrete-time data generated by each arm forms a homogeneous Markov chain taking values in a common, finite state space. The state transitions in each arm are captured by an ergodic transition probability matrix (TPM) that is a member of a single-parameter exponential family of TPMs. The real-valued parameters of the arm TPMs are unknown and belong to a given space. Given a function $f$ defined on the common state space of the arms, the goal is to identify the best arm -- the arm with the largest average value of $f$ evaluated under the arm's stationary distribution -- with the fewest number of samples, subject to an upper bound on the decision's error probability (i.e., the fixed-confidence regime). A lower bound on the growth rate of the expected stopping time is established in the asymptote of a vanishing error probability. Furthermore, a policy for best arm identification is proposed, and its expected stopping time is proved to have an asymptotic growth rate that matches the lower bound. It is demonstrated that tracking the long-term behavior of a certain Markov decision process and its state-action visitation proportions are the key ingredients in analyzing the converse and achievability bounds. It is shown that under every policy, the state-action visitation proportions satisfy a specific approximate flow conservation constraint and that these proportions match the optimal proportions dictated by the lower bound under any asymptotically optimal policy. The prior studies on best arm identification in restless bandits focus on independent observations from the arms, rested Markov arms, and restless Markov arms with known arm TPMs. In contrast, this work is the first to study best arm identification in restless bandits with unknown arm TPMs.
Parallel compressive super-resolution imaging with wide field-of-view based on physics enhanced network
Oct 20, 2023Achieving both high-performance and wide field-of-view (FOV) super-resolution imaging has been attracting increasing attention in recent years. However, such goal suffers from long reconstruction time and huge storage space. Parallel compressive imaging (PCI) provides an efficient solution, but the super-resolution quality and imaging speed are strongly dependent on precise optical transfer function (OTF), modulation masks and reconstruction algorithm. In this work, we propose a wide FOV parallel compressive super-resolution imaging approach based on physics enhanced network. By training the network with the prior OTF of an arbitrary 128x128-pixel region and fine-tuning the network with other OTFs within rest regions of FOV, we realize both mask optimization and super-resolution imaging with up to 1020x1500 wide FOV. Numerical simulations and practical experiments demonstrate the effectiveness and superiority of the proposed approach. We achieve high-quality reconstruction with 4x4 times super-resolution enhancement using only three designed masks to reach real-time imaging speed. The proposed approach promotes the technology of rapid imaging for super-resolution and wide FOV, ranging from infrared to Terahertz.
ASP: Automatic Selection of Proxy dataset for efficient AutoML
Oct 17, 2023Deep neural networks have gained great success due to the increasing amounts of data, and diverse effective neural network designs. However, it also brings a heavy computing burden as the amount of training data is proportional to the training time. In addition, a well-behaved model requires repeated trials of different structure designs and hyper-parameters, which may take a large amount of time even with state-of-the-art (SOTA) hyper-parameter optimization (HPO) algorithms and neural architecture search (NAS) algorithms. In this paper, we propose an Automatic Selection of Proxy dataset framework (ASP) aimed to dynamically find the informative proxy subsets of training data at each epoch, reducing the training data size as well as saving the AutoML processing time. We verify the effectiveness and generalization of ASP on CIFAR10, CIFAR100, ImageNet16-120, and ImageNet-1k, across various public model benchmarks. The experiment results show that ASP can obtain better results than other data selection methods at all selection ratios. ASP can also enable much more efficient AutoML processing with a speedup of 2x-20x while obtaining better architectures and better hyper-parameters compared to utilizing the entire dataset.
Quantum-Enhanced Forecasting: Leveraging Quantum Gramian Angular Field and CNNs for Stock Return Predictions
Oct 12, 2023
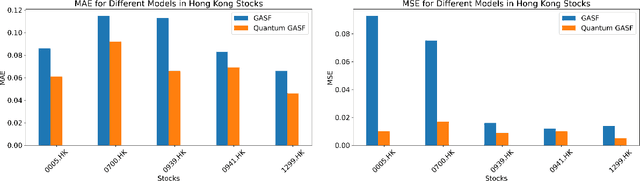
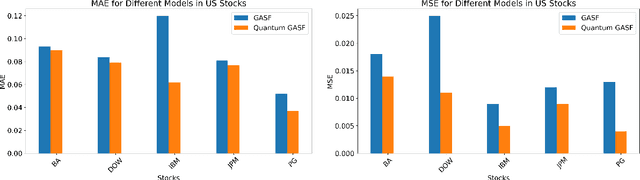
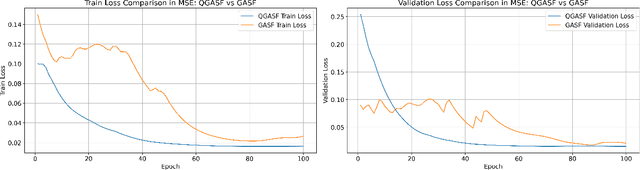
We propose a time series forecasting method named Quantum Gramian Angular Field (QGAF). This approach merges the advantages of quantum computing technology with deep learning, aiming to enhance the precision of time series classification and forecasting. We successfully transformed stock return time series data into two-dimensional images suitable for Convolutional Neural Network (CNN) training by designing specific quantum circuits. Distinct from the classical Gramian Angular Field (GAF) approach, QGAF's uniqueness lies in eliminating the need for data normalization and inverse cosine calculations, simplifying the transformation process from time series data to two-dimensional images. To validate the effectiveness of this method, we conducted experiments on datasets from three major stock markets: the China A-share market, the Hong Kong stock market, and the US stock market. Experimental results revealed that compared to the classical GAF method, the QGAF approach significantly improved time series prediction accuracy, reducing prediction errors by an average of 25% for Mean Absolute Error (MAE) and 48% for Mean Squared Error (MSE). This research confirms the potential and promising prospects of integrating quantum computing with deep learning techniques in financial time series forecasting.
Strategizing EV Charging and Renewable Integration in Texas
Oct 25, 2023Exploring the convergence of electric vehicles (EVs), renewable energy, and smart grid technologies in the context of Texas, this study addresses challenges hindering the widespread adoption of EVs. Acknowledging their environmental benefits, the research focuses on grid stability concerns, uncoordinated charging patterns, and the complicated relationship between EVs and renewable energy sources. Dynamic time warping (DTW) clustering and k-means clustering methodologies categorize days based on total load and net load, offering nuanced insights into daily electricity consumption and renewable energy generation patterns. By establishing optimal charging and vehicle-to-grid (V2G) windows tailored to specific load characteristics, the study provides a sophisticated methodology for strategic decision-making in energy consumption and renewable integration. The findings contribute to the ongoing discourse on achieving a sustainable and resilient energy future through the seamless integration of EVs into smart grids.
Towards Continually Learning Application Performance Models
Oct 25, 2023Machine learning-based performance models are increasingly being used to build critical job scheduling and application optimization decisions. Traditionally, these models assume that data distribution does not change as more samples are collected over time. However, owing to the complexity and heterogeneity of production HPC systems, they are susceptible to hardware degradation, replacement, and/or software patches, which can lead to drift in the data distribution that can adversely affect the performance models. To this end, we develop continually learning performance models that account for the distribution drift, alleviate catastrophic forgetting, and improve generalizability. Our best model was able to retain accuracy, regardless of having to learn the new distribution of data inflicted by system changes, while demonstrating a 2x improvement in the prediction accuracy of the whole data sequence in comparison to the naive approach.
Grokking in Linear Estimators -- A Solvable Model that Groks without Understanding
Oct 25, 2023Grokking is the intriguing phenomenon where a model learns to generalize long after it has fit the training data. We show both analytically and numerically that grokking can surprisingly occur in linear networks performing linear tasks in a simple teacher-student setup with Gaussian inputs. In this setting, the full training dynamics is derived in terms of the training and generalization data covariance matrix. We present exact predictions on how the grokking time depends on input and output dimensionality, train sample size, regularization, and network initialization. We demonstrate that the sharp increase in generalization accuracy may not imply a transition from "memorization" to "understanding", but can simply be an artifact of the accuracy measure. We provide empirical verification for our calculations, along with preliminary results indicating that some predictions also hold for deeper networks, with non-linear activations.