 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models Struggle to Align Entities across Modalities
Mar 05, 2025Cross-modal entity linking refers to the ability to align entities and their attributes across different modalities. While cross-modal entity linking is a fundamental skill needed for real-world applications such as multimodal code generation, fake news detection, or scene understanding, it has not been thoroughly studied in the literature. In this paper, we introduce a new task and benchmark to address this gap. Our benchmark, MATE, consists of 5.5k evaluation instances featuring visual scenes aligned with their textual representations. To evaluate cross-modal entity linking performance, we design a question-answering task that involves retrieving one attribute of an object in one modality based on a unique attribute of that object in another modality. We evaluate state-of-the-art Vision-Language Models (VLMs) and humans on this task, and find that VLMs struggle significantly compared to humans, particularly as the number of objects in the scene increases. Our analysis also shows that, while chain-of-thought prompting can improve VLM performance, models remain far from achieving human-level proficiency. These findings highlight the need for further research in cross-modal entity linking and show that MATE is a strong benchmark to support that progress.
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
Apr 08, 2024



Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
PixT3: Pixel-based Table To Text generation
Nov 16, 2023



Table-to-Text has been traditionally approached as a linear language to text problem. However, visually represented tables are rich in visual information and serve as a concise, effective form of representing data and its relationships. When using text-based approaches, after the linearization process, this information is either lost or represented in a space inefficient manner. This inefficiency has remained a constant challenge for text-based approaches making them struggle with large tables. In this paper, we demonstrate that image representation of tables are more space-efficient than the typical textual linearizations, and multi-modal approaches are competitive in Table-to-Text tasks. We present PixT3, a multimodal table-to-text model that outperforms the state-of-the-art (SotA) in the ToTTo benchmark in a pure Table-to-Text setting while remaining competitive in controlled Table-to-Text scenarios. It also generalizes better in unseen datasets, outperforming ToTTo SotA in all generation settings. Additionally, we introduce a new intermediate training curriculum to reinforce table structural awareness, leading to improved generation and overall faithfulness of the models.
Automatic Logical Forms improve fidelity in Table-to-Text generation
Oct 26, 2023



Table-to-text systems generate natural language statements from structured data like tables. While end-to-end techniques suffer from low factual correctness (fidelity), a previous study reported gains when using manual logical forms (LF) that represent the selected content and the semantics of the target text. Given the manual step, it was not clear whether automatic LFs would be effective, or whether the improvement came from content selection alone. We present TlT which, given a table and a selection of the content, first produces LFs and then the textual statement. We show for the first time that automatic LFs improve quality, with an increase in fidelity of 30 points over a comparable system not using LFs. Our experiments allow to quantify the remaining challenges for high factual correctness, with automatic selection of content coming first, followed by better Logic-to-Text generation and, to a lesser extent, better Table-to-Logic parsing.
HiTZ@Antidote: Argumentation-driven Explainable Artificial Intelligence for Digital Medicine
Jun 09, 2023

Providing high quality explanations for AI predictions based on machine learning is a challenging and complex task. To work well it requires, among other factors: selecting a proper level of generality/specificity of the explanation; considering assumptions about the familiarity of the explanation beneficiary with the AI task under consideration; referring to specific elements that have contributed to the decision; making use of additional knowledge (e.g. expert evidence) which might not be part of the prediction process; and providing evidence supporting negative hypothesis. Finally, the system needs to formulate the explanation in a clearly interpretable, and possibly convincing, way. Given these considerations, ANTIDOTE fosters an integrated vision of explainable AI, where low-level characteristics of the deep learning process are combined with higher level schemes proper of the human argumentation capacity. ANTIDOTE will exploit cross-disciplinary competences in deep learning and argumentation to support a broader and innovative view of explainable AI, where the need for high-quality explanations for clinical cases deliberation is critical. As a first result of the project, we publish the Antidote CasiMedicos dataset to facilitate research on explainable AI in general, and argumentation in the medical domain in particular.
Domain and View-point Agnostic Hand Action Recognition
Mar 03, 2021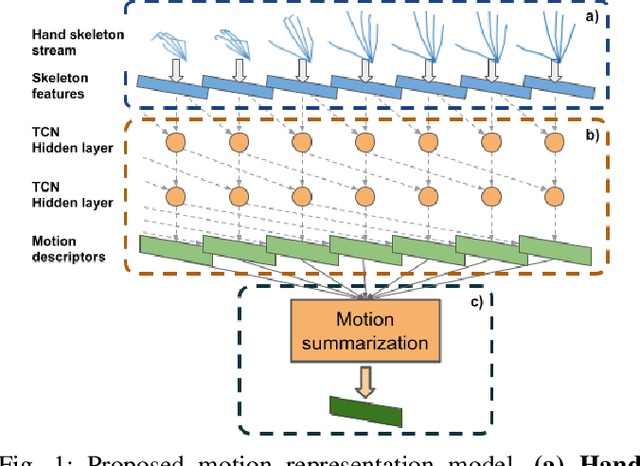
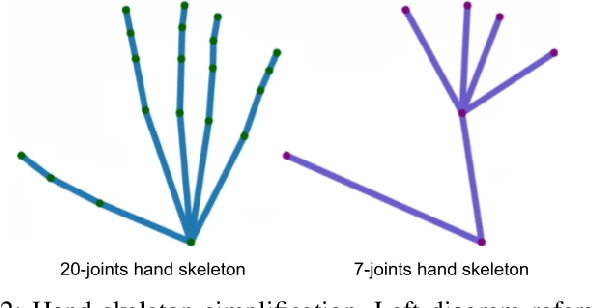
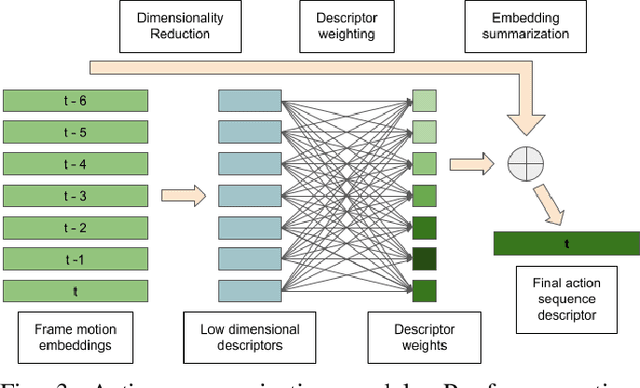
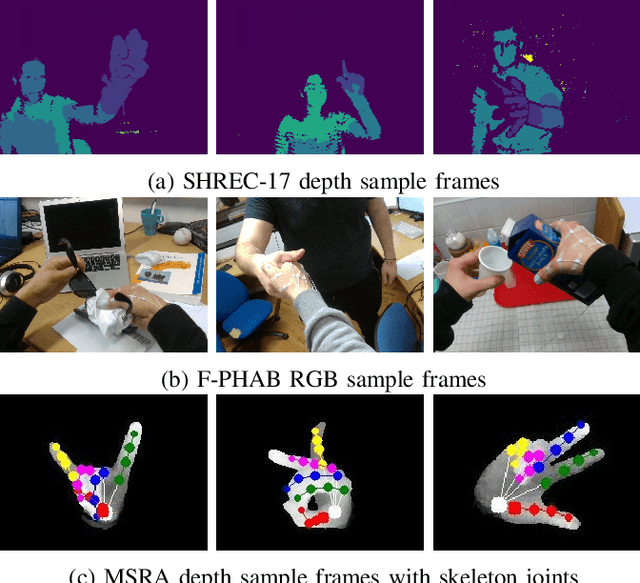
Hand action recognition is a special case of human action recognition with applications in human robot interaction, virtual reality or life-logging systems. Building action classifiers that are useful to recognize such heterogeneous set of activities is very challenging. There are very subtle changes across different actions from a given application but also large variations across domains (e.g. virtual reality vs life-logging). This work introduces a novel skeleton-based hand motion representation model that tackles this problem. The framework we propose is agnostic to the application domain or camera recording view-point. We demonstrate the performance of our proposed motion representation model both working for a single specific domain (intra-domain action classification) and working for different unseen domains (cross-domain action classification). For the intra-domain case, our approach gets better or similar performance than current state-of-the-art methods on well-known hand action recognition benchmarks. And when performing cross-domain hand action recognition (i.e., training our motion representation model in frontal-view recordings and testing it both for egocentric and third-person views), our approach achieves comparable results to the state-of-the-art methods that are trained intra-domain.
3D-MiniNet: Learning a 2D Representation from Point Clouds for Fast and Efficient 3D LIDAR Semantic Segmentation
Feb 27, 2020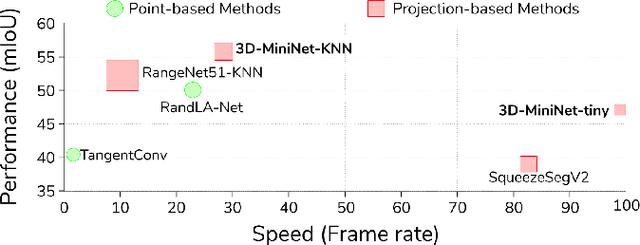
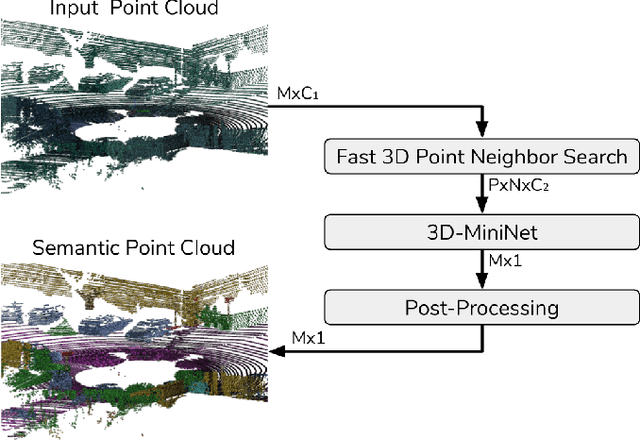
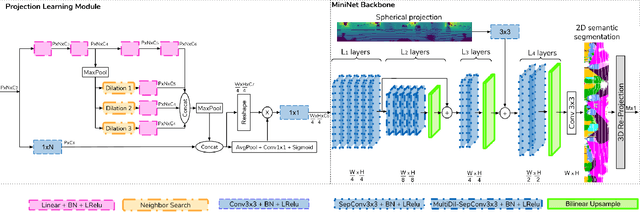

LIDAR semantic segmentation, which assigns a semantic label to each 3D point measured by the LIDAR, is becoming an essential task for many robotic applications such as autonomous driving. Fast and efficient semantic segmentation methods are needed to match the strong computational and temporal restrictions of many of these real-world applications. This work presents 3D-MiniNet, a novel approach for LIDAR semantic segmentation that combines 3D and 2D learning layers. It first learns a 2D representation from the raw points through a novel projection which extracts local and global information from the 3D data. This representation is fed to an efficient 2D Fully Convolutional Neural Network (FCNN) that produces a 2D semantic segmentation. These 2D semantic labels are re-projected back to the 3D space and enhanced through a post-processing module. The main novelty in our strategy relies on the projection learning module. Our detailed ablation study shows how each component contributes to the final performance of 3D-MiniNet. We validate our approach on well known public benchmarks (SemanticKITTI and KITTI), where 3D-MiniNet gets state-of-the-art results while being faster and more parameter-efficient than previous methods.
EV-SegNet: Semantic Segmentation for Event-based Cameras
Nov 29, 2018


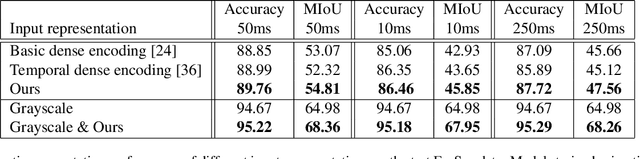
Event cameras, or Dynamic Vision Sensor (DVS), are very promising sensors which have shown several advantages over frame based cameras. However, most recent work on real applications of these cameras is focused on 3D reconstruction and 6-DOF camera tracking. Deep learning based approaches, which are leading the state-of-the-art in visual recognition tasks, could potentially take advantage of the benefits of DVS, but some adaptations are needed still needed in order to effectively work on these cameras. This work introduces a first baseline for semantic segmentation with this kind of data. We build a semantic segmentation CNN based on state-of-the-art techniques which takes event information as the only input. Besides, we propose a novel representation for DVS data that outperforms previously used event representations for related tasks. Since there is no existing labeled dataset for this task, we propose how to automatically generate approximated semantic segmentation labels for some sequences of the DDD17 dataset, which we publish together with the model, and demonstrate they are valid to train a model for DVS data only. We compare our results on semantic segmentation from DVS data with results using corresponding grayscale images, demonstrating how they are complementary and worth combining.