 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Control Camera Exposure via Reinforcement Learning
Apr 02, 2024
Adjusting camera exposure in arbitrary lighting conditions is the first step to ensure the functionality of computer vision applications. Poorly adjusted camera exposure often leads to critical failure and performance degradation. Traditional camera exposure control methods require multiple convergence steps and time-consuming processes, making them unsuitable for dynamic lighting conditions. In this paper, we propose a new camera exposure control framework that rapidly controls camera exposure while performing real-time processing by exploiting deep reinforcement learning. The proposed framework consists of four contributions: 1) a simplified training ground to simulate real-world's diverse and dynamic lighting changes, 2) flickering and image attribute-aware reward design, along with lightweight state design for real-time processing, 3) a static-to-dynamic lighting curriculum to gradually improve the agent's exposure-adjusting capability, and 4) domain randomization techniques to alleviate the limitation of the training ground and achieve seamless generalization in the wild.As a result, our proposed method rapidly reaches a desired exposure level within five steps with real-time processing (1 ms). Also, the acquired images are well-exposed and show superiority in various computer vision tasks, such as feature extraction and object detection.
Risk-averse Learning with Non-Stationary Distributions
Apr 03, 2024Considering non-stationary environments in online optimization enables decision-maker to effectively adapt to changes and improve its performance over time. In such cases, it is favorable to adopt a strategy that minimizes the negative impact of change to avoid potentially risky situations. In this paper, we investigate risk-averse online optimization where the distribution of the random cost changes over time. We minimize risk-averse objective function using the Conditional Value at Risk (CVaR) as risk measure. Due to the difficulty in obtaining the exact CVaR gradient, we employ a zeroth-order optimization approach that queries the cost function values multiple times at each iteration and estimates the CVaR gradient using the sampled values. To facilitate the regret analysis, we use a variation metric based on Wasserstein distance to capture time-varying distributions. Given that the distribution variation is sub-linear in the total number of episodes, we show that our designed learning algorithm achieves sub-linear dynamic regret with high probability for both convex and strongly convex functions. Moreover, theoretical results suggest that increasing the number of samples leads to a reduction in the dynamic regret bounds until the sampling number reaches a specific limit. Finally, we provide numerical experiments of dynamic pricing in a parking lot to illustrate the efficacy of the designed algorithm.
VTR: An Optimized Vision Transformer for SAR ATR Acceleration on FPGA
Apr 06, 2024Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) is a key technique used in military applications like remote-sensing image recognition. Vision Transformers (ViTs) are the current state-of-the-art in various computer vision applications, outperforming their CNN counterparts. However, using ViTs for SAR ATR applications is challenging due to (1) standard ViTs require extensive training data to generalize well due to their low locality; the standard SAR datasets, however, have a limited number of labeled training data which reduces the learning capability of ViTs; (2) ViTs have a high parameter count and are computation intensive which makes their deployment on resource-constrained SAR platforms difficult. In this work, we develop a lightweight ViT model that can be trained directly on small datasets without any pre-training by utilizing the Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA) modules. We directly train this model on SAR datasets which have limited training samples to evaluate its effectiveness for SAR ATR applications. We evaluate our proposed model, that we call VTR (ViT for SAR ATR), on three widely used SAR datasets: MSTAR, SynthWakeSAR, and GBSAR. Further, we propose a novel FPGA accelerator for VTR, in order to enable deployment for real-time SAR ATR applications.
Modeling Kinematic Uncertainty of Tendon-Driven Continuum Robots via Mixture Density Networks
Apr 05, 2024Tendon-driven continuum robot kinematic models are frequently computationally expensive, inaccurate due to unmodeled effects, or both. In particular, unmodeled effects produce uncertainties that arise during the robot's operation that lead to variability in the resulting geometry. We propose a novel solution to these issues through the development of a Gaussian mixture kinematic model. We train a mixture density network to output a Gaussian mixture model representation of the robot geometry given the current tendon displacements. This model computes a probability distribution that is more representative of the true distribution of geometries at a given configuration than a model that outputs a single geometry, while also reducing the computation time. We demonstrate one use of this model through a trajectory optimization method that explicitly reasons about the workspace uncertainty to minimize the probability of collision.
Addressing Concept Shift in Online Time Series Forecasting: Detect-then-Adapt
Mar 22, 2024Online updating of time series forecasting models aims to tackle the challenge of concept drifting by adjusting forecasting models based on streaming data. While numerous algorithms have been developed, most of them focus on model design and updating. In practice, many of these methods struggle with continuous performance regression in the face of accumulated concept drifts over time. To address this limitation, we present a novel approach, Concept \textbf{D}rift \textbf{D}etection an\textbf{D} \textbf{A}daptation (D3A), that first detects drifting conception and then aggressively adapts the current model to the drifted concepts after the detection for rapid adaption. To best harness the utility of historical data for model adaptation, we propose a data augmentation strategy introducing Gaussian noise into existing training instances. It helps mitigate the data distribution gap, a critical factor contributing to train-test performance inconsistency. The significance of our data augmentation process is verified by our theoretical analysis. Our empirical studies across six datasets demonstrate the effectiveness of D3A in improving model adaptation capability. Notably, compared to a simple Temporal Convolutional Network (TCN) baseline, D3A reduces the average Mean Squared Error (MSE) by $43.9\%$. For the state-of-the-art (SOTA) model, the MSE is reduced by $33.3\%$.
A Semi-Lagrangian Approach for Time and Energy Path Planning Optimization in Static Flow Fields
Mar 25, 2024Efficient path planning for autonomous mobile robots is a critical problem across numerous domains, where optimizing both time and energy consumption is paramount. This paper introduces a novel methodology that considers the dynamic influence of an environmental flow field and considers geometric constraints, including obstacles and forbidden zones, enriching the complexity of the planning problem. We formulate it as a multi-objective optimal control problem, propose a novel transformation called Harmonic Transformation, and apply a semi-Lagrangian scheme to solve it. The set of Pareto efficient solutions is obtained considering two distinct approaches: a deterministic method and an evolutionary-based one, both of which are designed to make use of the proposed Harmonic Transformation. Through an extensive analysis of these approaches, we demonstrate their efficacy in finding optimized paths.
Automated Contrastive Learning Strategy Search for Time Series
Mar 19, 2024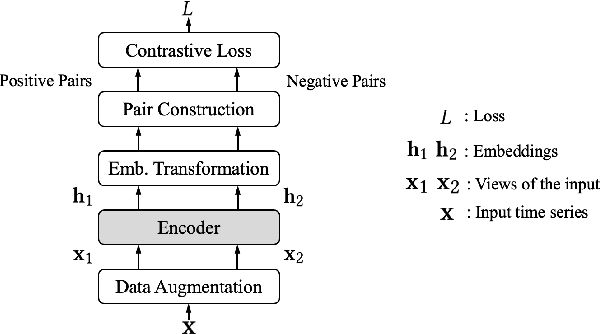
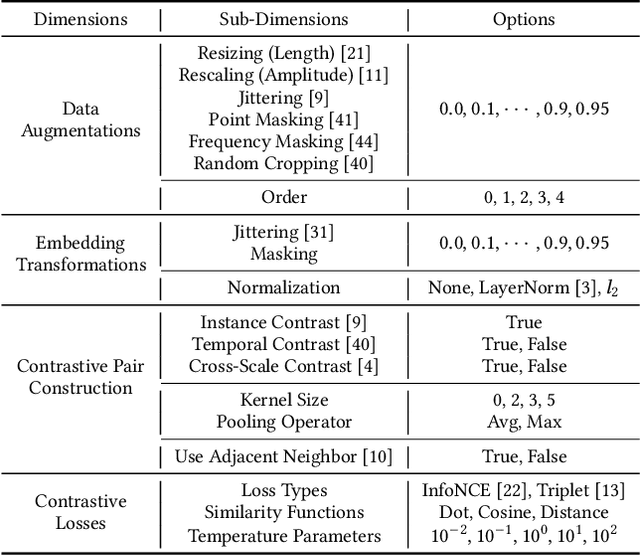
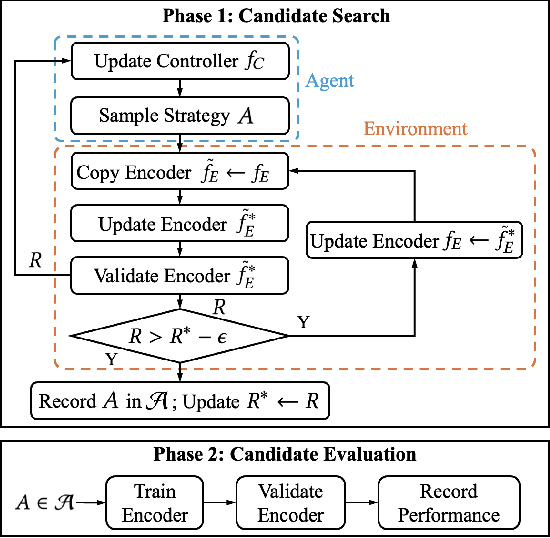
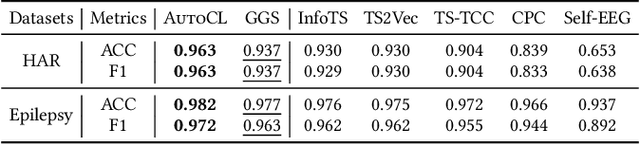
In recent years, Contrastive Learning (CL) has become a predominant representation learning paradigm for time series. Most existing methods in the literature focus on manually building specific Contrastive Learning Strategies (CLS) by human heuristics for certain datasets and tasks. However, manually developing CLS usually require excessive prior knowledge about the datasets and tasks, e.g., professional cognition of the medical time series in healthcare, as well as huge human labor and massive experiments to determine the detailed learning configurations. In this paper, we present an Automated Machine Learning (AutoML) practice at Microsoft, which automatically learns to contrastively learn representations for various time series datasets and tasks, namely Automated Contrastive Learning (AutoCL). We first construct a principled universal search space of size over 3x1012, covering data augmentation, embedding transformation, contrastive pair construction and contrastive losses. Further, we introduce an efficient reinforcement learning algorithm, which optimizes CLS from the performance on the validation tasks, to obtain more effective CLS within the space. Experimental results on various real-world tasks and datasets demonstrate that AutoCL could automatically find the suitable CLS for a given dataset and task. From the candidate CLS found by AutoCL on several public datasets/tasks, we compose a transferable Generally Good Strategy (GGS), which has a strong performance for other datasets. We also provide empirical analysis as a guidance for future design of CLS.
Sub-Nyquist Sampling OFDM Radar With a Time-Frequency Phase-Coded Waveform
Mar 21, 2024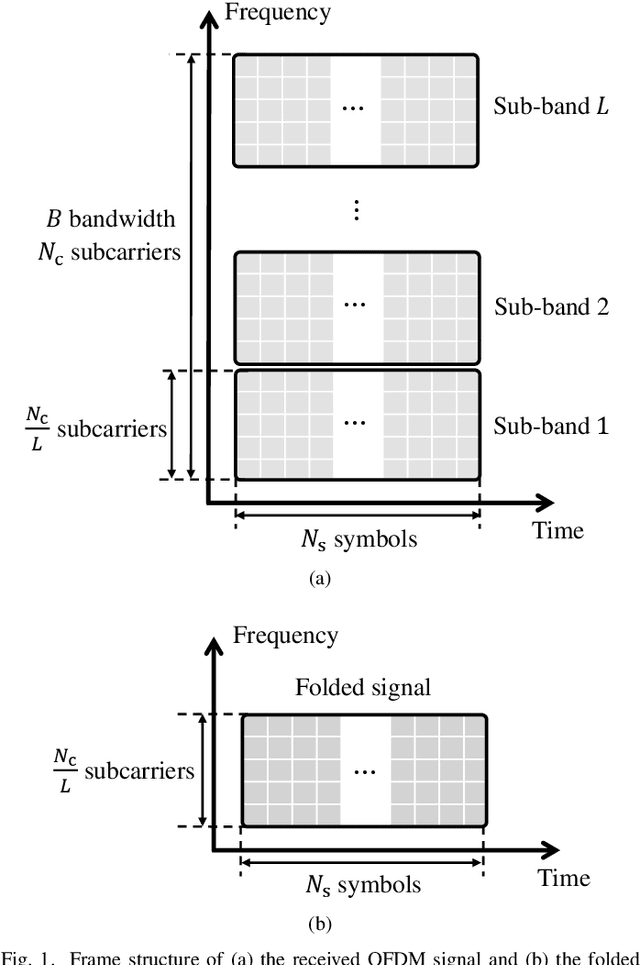
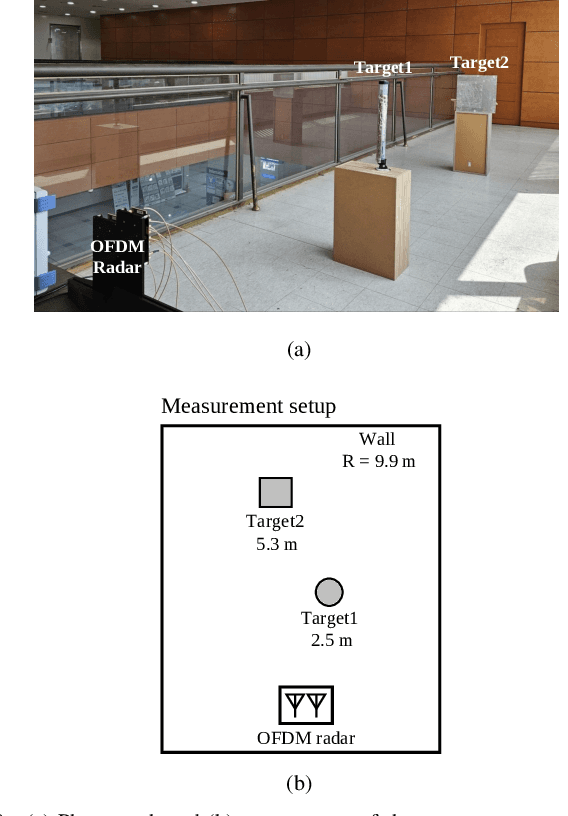
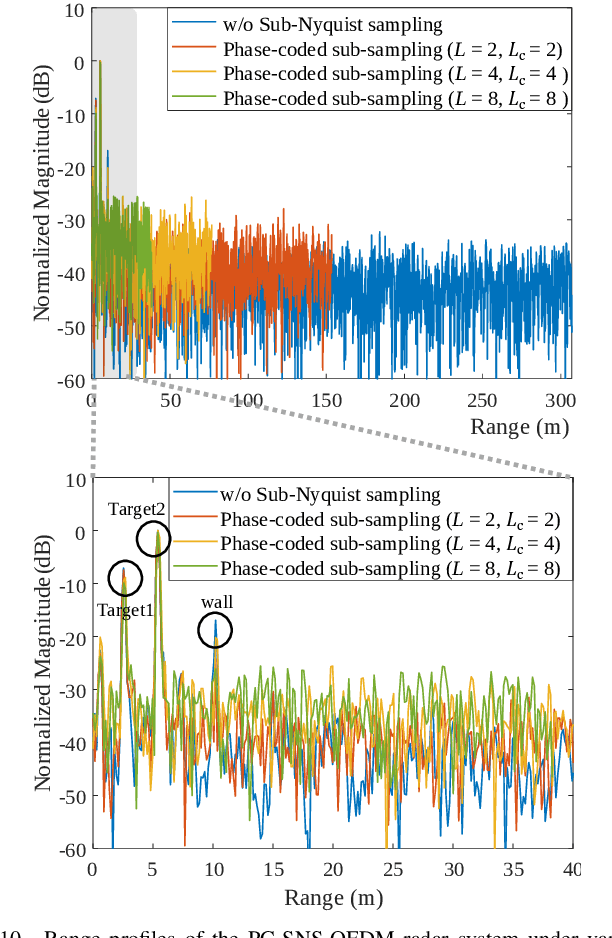
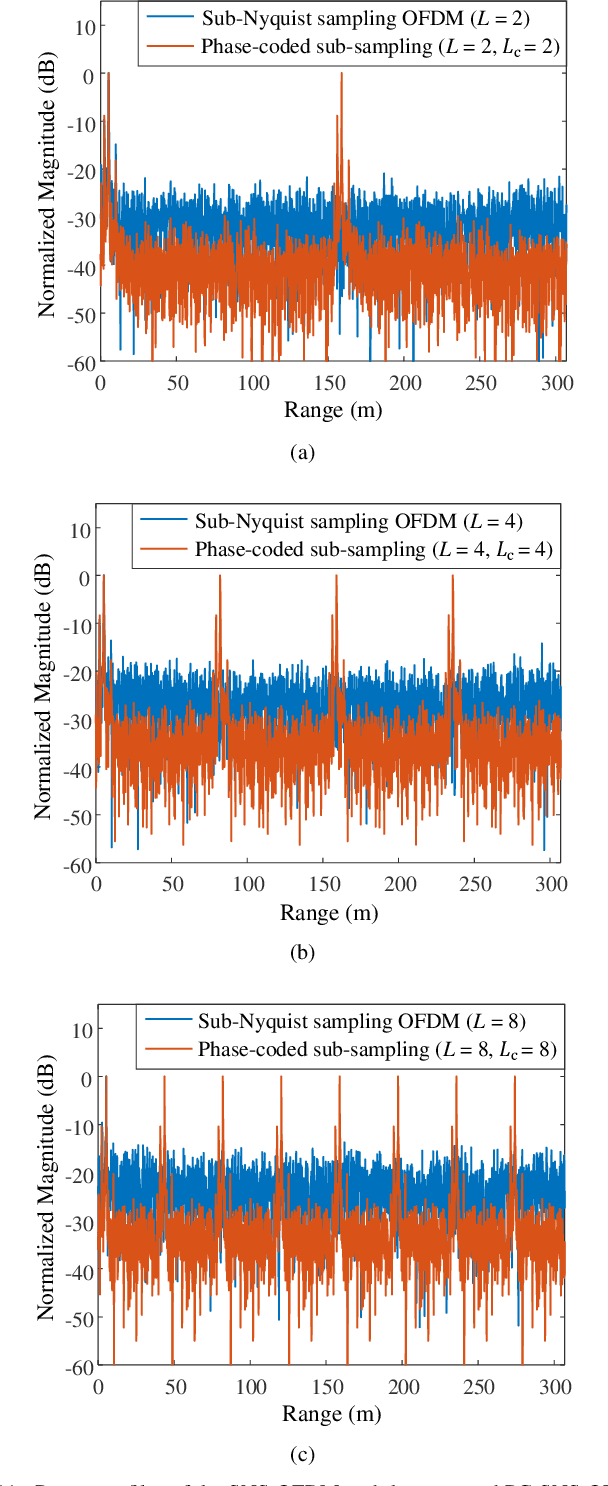
This paper presents a time-frequency phase-coded sub-Nyquist sampling orthogonal frequency division multiplexing (PC-SNS-OFDM) radar system to reduce the analog-to-digital converter (ADC) sampling rate without any additional hardware or signal processing. The proposed radar divides the transmitted OFDM signal into multiple sub-bands along the frequency axis and provides orthogonality to these sub-bands by multiplying phase codes in both the time and frequency domains. Although the sampling rate is reduced by the factor of the number of sub-bands, the sub-bands above the sampling rate are folded into the lowest one due to aliasing. In the process of restoring the signals in folded sub-bands to those in full signal bands, the proposed PC-SNS-OFDM radar effectively eliminates symbol-mismatch noise while introducing trade-offs in the range and Doppler ambiguities. The utilization of phase codes in both the frequency and time domains provides flexible control of the range and Doppler ambiguities. It also improves the signal-to-noise ratio (SNR) of detected targets compared to an earlier sub-Nyquist sampling OFDM radar system. This is validated with simulations and experiments under various sub-Nyquist sampling rates.
Incremental Learning with Concept Drift Detection and Prototype-based Embeddings for Graph Stream Classification
Apr 03, 2024Data stream mining aims at extracting meaningful knowledge from continually evolving data streams, addressing the challenges posed by nonstationary environments, particularly, concept drift which refers to a change in the underlying data distribution over time. Graph structures offer a powerful modelling tool to represent complex systems, such as, critical infrastructure systems and social networks. Learning from graph streams becomes a necessity to understand the dynamics of graph structures and to facilitate informed decision-making. This work introduces a novel method for graph stream classification which operates under the general setting where a data generating process produces graphs with varying nodes and edges over time. The method uses incremental learning for continual model adaptation, selecting representative graphs (prototypes) for each class, and creating graph embeddings. Additionally, it incorporates a loss-based concept drift detection mechanism to recalculate graph prototypes when drift is detected.
An evaluation of CFEAR Radar Odometry
Apr 03, 2024This article describes the method CFEAR Radar odometry, submitted to a competition at the Radar in Robotics workshop, ICRA 20241. CFEAR is an efficient and accurate method for spinning 2D radar odometry that generalizes well across environments. This article presents an overview of the odometry pipeline with new experiments on the public Boreas dataset. We show that a real-time capable configuration of CFEAR - with its original parameter set - yields surprisingly low drift in the Boreas dataset. Additionally, we discuss an improved implementation and solving strategy that enables the most accurate configuration to run in real-time with improved robustness, reaching as low as 0.61% translation drift at a frame rate of 68 Hz. A recent release of the source code is available to the community https://github.com/dan11003/CFEAR_Radarodometry_code_public, and we publish the evaluation from this article on https://github.com/dan11003/cfear_2024_workshop