 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Agent Combinatorial Path Finding with Heterogeneous Task Duration
Nov 26, 2023
Multi-Agent Combinatorial Path Finding (MCPF) seeks collision-free paths for multiple agents from their initial locations to destinations, visiting a set of intermediate target locations in the middle of the paths, while minimizing the sum of arrival times. While a few approaches have been developed to handle MCPF, most of them simply direct the agent to visit the targets without considering the task duration, i.e., the amount of time needed for an agent to execute the task (such as picking an item) at a target location. MCPF is NP-hard to solve to optimality, and the inclusion of task duration further complicates the problem. This paper investigates heterogeneous task duration, where the duration can be different with respect to both the agents and targets. We develop two methods, where the first method post-processes the paths planned by any MCPF planner to include the task duration and has no solution optimality guarantee; and the second method considers task duration during planning and is able to ensure solution optimality. The numerical and simulation results show that our methods can handle up to 20 agents and 50 targets in the presence of task duration, and can execute the paths subject to robot motion disturbance.
Unsupervised high-throughput segmentation of cells and cell nuclei in quantitative phase images
Nov 24, 2023In the effort to aid cytologic diagnostics by establishing automatic single cell screening using high throughput digital holographic microscopy for clinical studies thousands of images and millions of cells are captured. The bottleneck lies in an automatic, fast, and unsupervised segmentation technique that does not limit the types of cells which might occur. We propose an unsupervised multistage method that segments correctly without confusing noise or reflections with cells and without missing cells that also includes the detection of relevant inner structures, especially the cell nucleus in the unstained cell. In an effort to make the information reasonable and interpretable for cytopathologists, we also introduce new cytoplasmic and nuclear features of potential help for cytologic diagnoses which exploit the quantitative phase information inherent to the measurement scheme. We show that the segmentation provides consistently good results over many experiments on patient samples in a reasonable per cell analysis time.
Set Features for Anomaly Detection
Nov 24, 2023This paper proposes set features for detecting anomalies in samples that consist of unusual combinations of normal elements. Many leading methods discover anomalies by detecting an unusual part of a sample. For example, state-of-the-art segmentation-based approaches, first classify each element of the sample (e.g., image patch) as normal or anomalous and then classify the entire sample as anomalous if it contains anomalous elements. However, such approaches do not extend well to scenarios where the anomalies are expressed by an unusual combination of normal elements. In this paper, we overcome this limitation by proposing set features that model each sample by the distribution of its elements. We compute the anomaly score of each sample using a simple density estimation method, using fixed features. Our approach outperforms the previous state-of-the-art in image-level logical anomaly detection and sequence-level time series anomaly detection.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Nov 28, 2023Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
Gaussian processes based data augmentation and expected signature for time series classification
Oct 16, 2023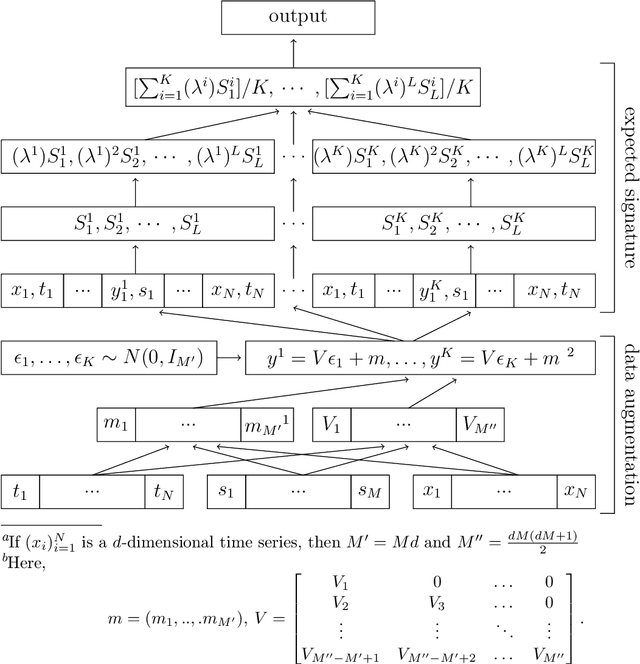
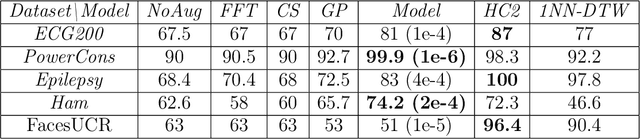
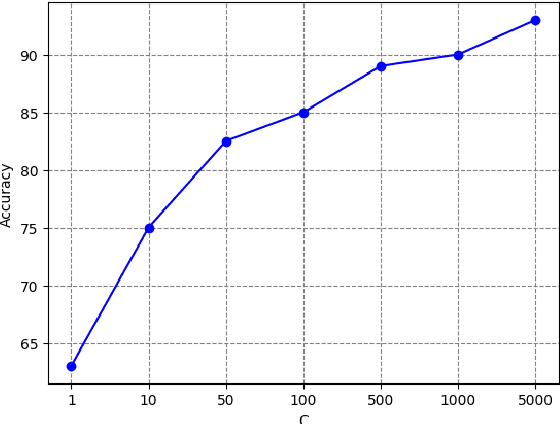
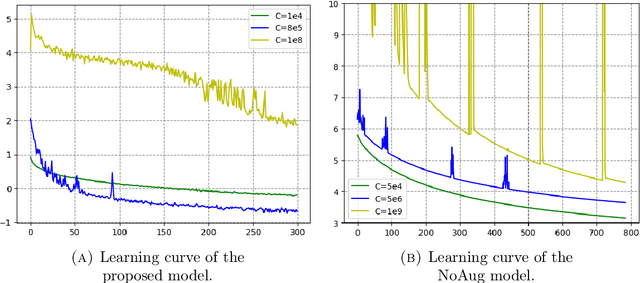
The signature is a fundamental object that describes paths (that is, continuous functions from an interval to a Euclidean space). Likewise, the expected signature provides a statistical description of the law of stochastic processes. We propose a feature extraction model for time series built upon the expected signature. This is computed through a Gaussian processes based data augmentation. One of the main features is that an optimal feature extraction is learnt through the supervised task that uses the model.
TANGO: Time-Reversal Latent GraphODE for Multi-Agent Dynamical Systems
Oct 10, 2023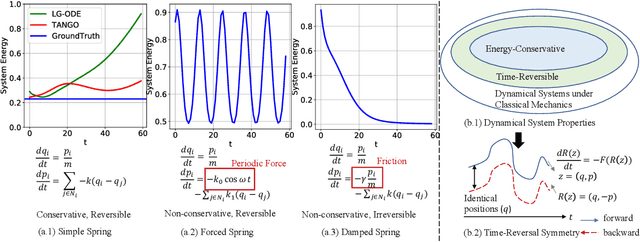
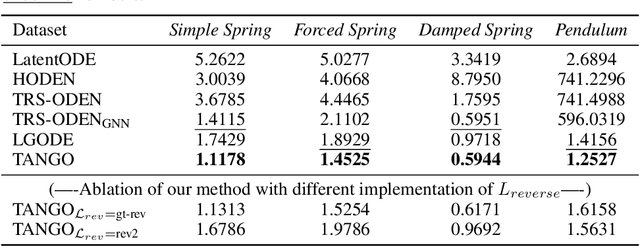
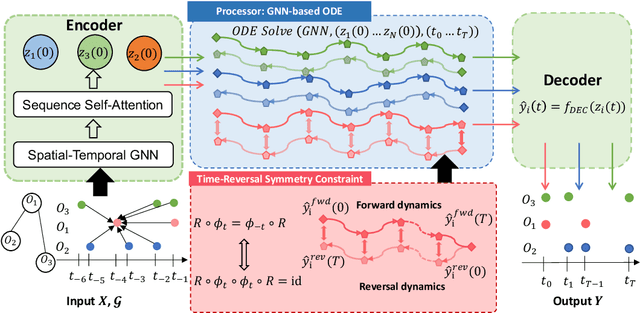
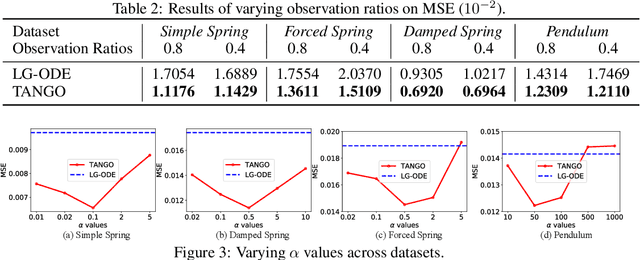
Learning complex multi-agent system dynamics from data is crucial across many domains, such as in physical simulations and material modeling. Extended from purely data-driven approaches, existing physics-informed approaches such as Hamiltonian Neural Network strictly follow energy conservation law to introduce inductive bias, making their learning more sample efficiently. However, many real-world systems do not strictly conserve energy, such as spring systems with frictions. Recognizing this, we turn our attention to a broader physical principle: Time-Reversal Symmetry, which depicts that the dynamics of a system shall remain invariant when traversed back over time. It still helps to preserve energies for conservative systems and in the meanwhile, serves as a strong inductive bias for non-conservative, reversible systems. To inject such inductive bias, in this paper, we propose a simple-yet-effective self-supervised regularization term as a soft constraint that aligns the forward and backward trajectories predicted by a continuous graph neural network-based ordinary differential equation (GraphODE). It effectively imposes time-reversal symmetry to enable more accurate model predictions across a wider range of dynamical systems under classical mechanics. In addition, we further provide theoretical analysis to show that our regularization essentially minimizes higher-order Taylor expansion terms during the ODE integration steps, which enables our model to be more noise-tolerant and even applicable to irreversible systems. Experimental results on a variety of physical systems demonstrate the effectiveness of our proposed method. Particularly, it achieves an MSE improvement of 11.5 % on a challenging chaotic triple-pendulum systems.
Introducing the Attribution Stability Indicator: a Measure for Time Series XAI Attributions
Oct 06, 2023
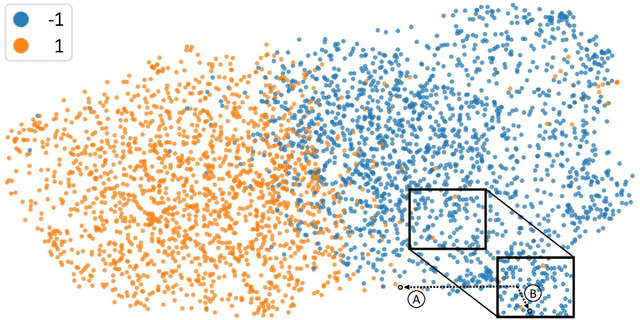
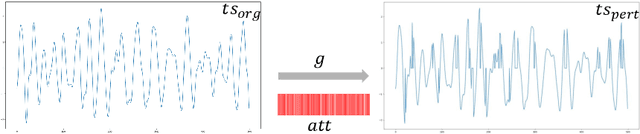

Given the increasing amount and general complexity of time series data in domains such as finance, weather forecasting, and healthcare, there is a growing need for state-of-the-art performance models that can provide interpretable insights into underlying patterns and relationships. Attribution techniques enable the extraction of explanations from time series models to gain insights but are hard to evaluate for their robustness and trustworthiness. We propose the Attribution Stability Indicator (ASI), a measure to incorporate robustness and trustworthiness as properties of attribution techniques for time series into account. We extend a perturbation analysis with correlations of the original time series to the perturbed instance and the attributions to include wanted properties in the measure. We demonstrate the wanted properties based on an analysis of the attributions in a dimension-reduced space and the ASI scores distribution over three whole time series classification datasets.
BERT-PIN: A BERT-based Framework for Recovering Missing Data Segments in Time-series Load Profiles
Oct 26, 2023Inspired by the success of the Transformer model in natural language processing and computer vision, this paper introduces BERT-PIN, a Bidirectional Encoder Representations from Transformers (BERT) powered Profile Inpainting Network. BERT-PIN recovers multiple missing data segments (MDSs) using load and temperature time-series profiles as inputs. To adopt a standard Transformer model structure for profile inpainting, we segment the load and temperature profiles into line segments, treating each segment as a word and the entire profile as a sentence. We incorporate a top candidates selection process in BERT-PIN, enabling it to produce a sequence of probability distributions, based on which users can generate multiple plausible imputed data sets, each reflecting different confidence levels. We develop and evaluate BERT-PIN using real-world dataset for two applications: multiple MDSs recovery and demand response baseline estimation. Simulation results show that BERT-PIN outperforms the existing methods in accuracy while is capable of restoring multiple MDSs within a longer window. BERT-PIN, served as a pre-trained model, can be fine-tuned for conducting many downstream tasks, such as classification and super resolution.
A time-causal and time-recursive analogue of the Gabor transform
Sep 13, 2023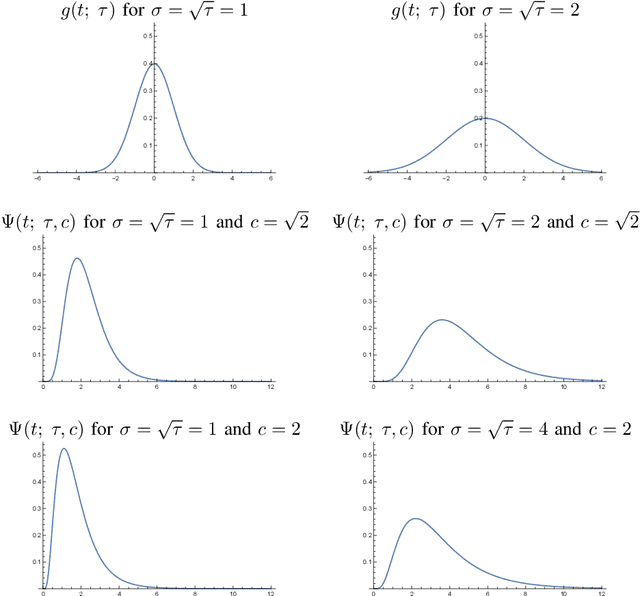
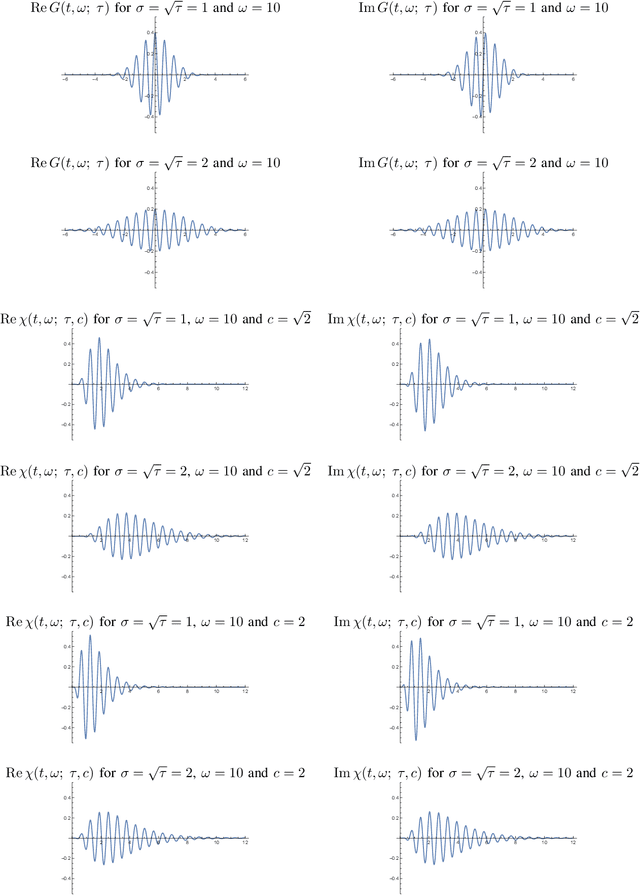
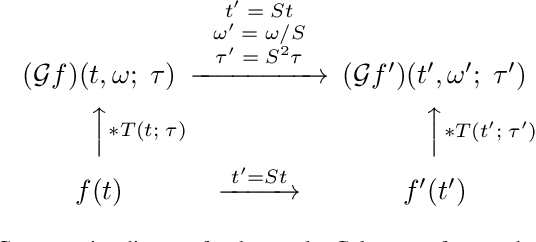
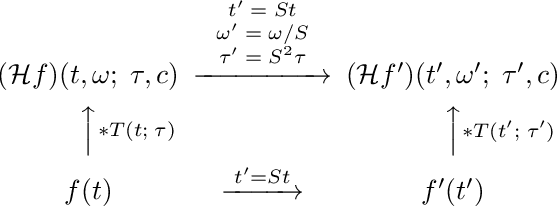
This paper presents a time-causal analogue of the Gabor filter, as well as a both time-causal and time-recursive analogue of the Gabor transform, where the proposed time-causal representations obey both temporal scale covariance and a cascade property with a simplifying kernel over temporal scales. The motivation behind these constructions is to enable theoretically well-founded time-frequency analysis over multiple temporal scales for real-time situations, or for physical or biological modelling situations, when the future cannot be accessed, and the non-causal access to future in Gabor filtering is therefore not viable for a time-frequency analysis of the system. We develop the theory for these representations, obtained by replacing the Gaussian kernel in Gabor filtering with a time-causal kernel, referred to as the time-causal limit kernel, which guarantees simplification properties from finer to coarser levels of scales in a time-causal situation, similar as the Gaussian kernel can be shown to guarantee over a non-causal temporal domain. In these ways, the proposed time-frequency representations guarantee well-founded treatment over multiple scales, in situations when the characteristic scales in the signals, or physical or biological phenomena, to be analyzed may vary substantially, and additionally all steps in the time-frequency analysis have to be fully time-causal.
Exploring the Relationship between In-Context Learning and Instruction Tuning
Nov 17, 2023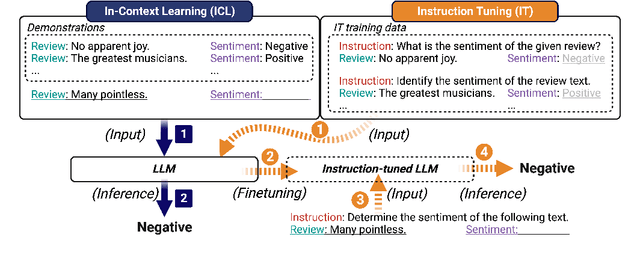
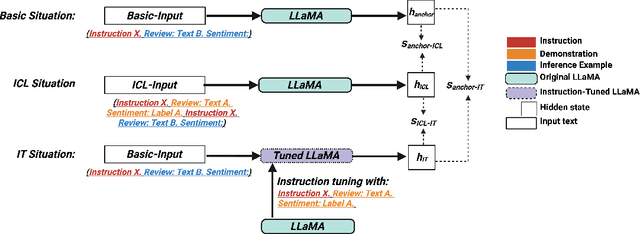

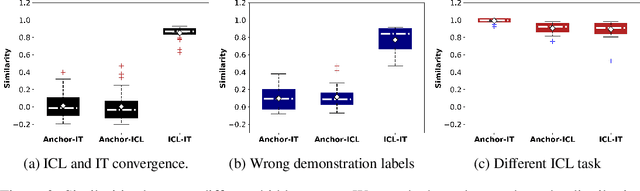
In-Context Learning (ICL) and Instruction Tuning (IT) are two primary paradigms of adopting Large Language Models (LLMs) to downstream applications. However, they are significantly different. In ICL, a set of demonstrations are provided at inference time but the LLM's parameters are not updated. In IT, a set of demonstrations are used to tune LLM's parameters in training time but no demonstrations are used at inference time. Although a growing body of literature has explored ICL and IT, studies on these topics have largely been conducted in isolation, leading to a disconnect between these two paradigms. In this work, we explore the relationship between ICL and IT by examining how the hidden states of LLMs change in these two paradigms. Through carefully designed experiments conducted with LLaMA-2 (7B and 13B), we find that ICL is implicit IT. In other words, ICL changes an LLM's hidden states as if the demonstrations were used to instructionally tune the model. Furthermore, the convergence between ICL and IT is largely contingent upon several factors related to the provided demonstrations. Overall, this work offers a unique perspective to explore the connection between ICL and IT and sheds light on understanding the behaviors of LLM.