 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Symmetry-regularized neural ordinary differential equations
Nov 28, 2023
Neural Ordinary Differential Equations (Neural ODEs) is a class of deep neural network models that interpret the hidden state dynamics of neural networks as an ordinary differential equation, thereby capable of capturing system dynamics in a continuous time framework. In this work, I integrate symmetry regularization into Neural ODEs. In particular, I use continuous Lie symmetry of ODEs and PDEs associated with the model to derive conservation laws and add them to the loss function, making it physics-informed. This incorporation of inherent structural properties into the loss function could significantly improve robustness and stability of the model during training. To illustrate this method, I employ a toy model that utilizes a cosine rate of change in the hidden state, showcasing the process of identifying Lie symmetries, deriving conservation laws, and constructing a new loss function.
A General 3D Non-Stationary 5G Wireless Channel Model
Nov 28, 2023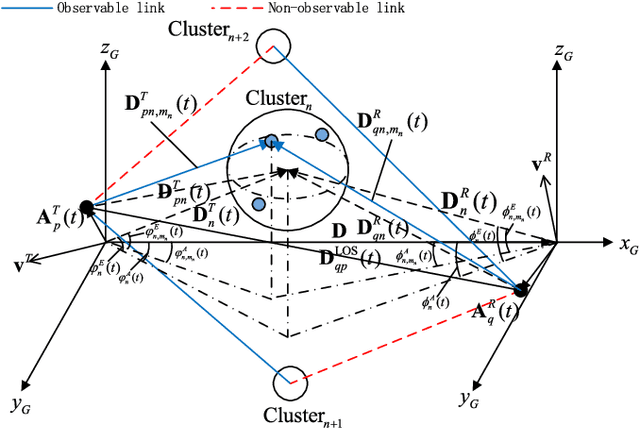
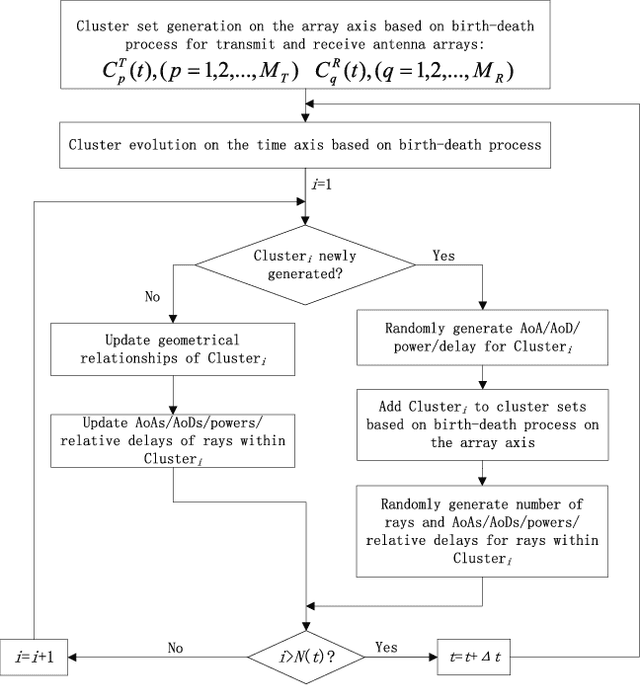
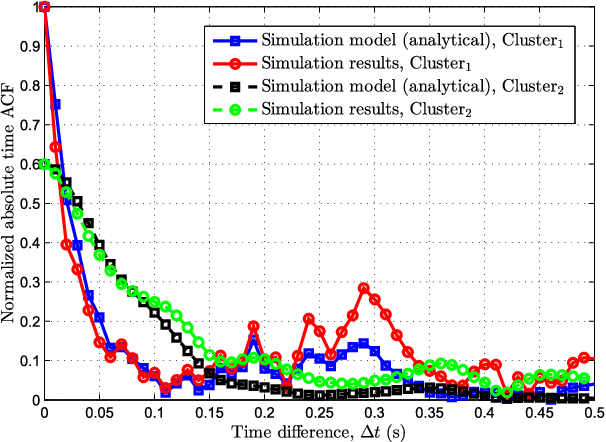
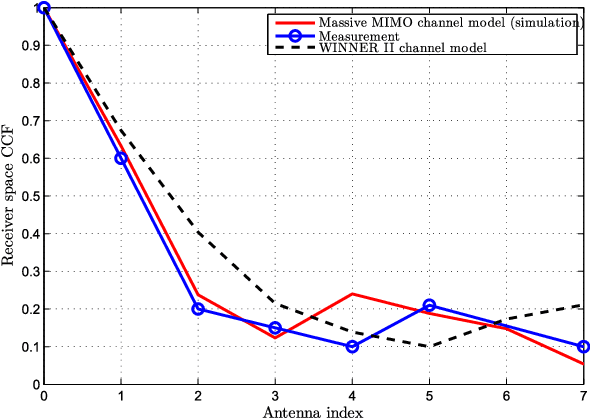
A novel unified framework of geometry-based stochastic models (GBSMs) for the fifth generation (5G) wireless communication systems is proposed in this paper. The proposed general 5G channel model aims at capturing small-scale fading channel characteristics of key 5G communication scenarios, such as massive multiple-input multiple-output (MIMO), high-speed train (HST), vehicle-to-vehicle (V2V), and millimeter wave (mmWave) communication scenarios. It is a three-dimensional (3D) non-stationary channel model based on the WINNER II and Saleh-Valenzuela (SV) channel models considering array-time cluster evolution. Moreover, it can easily be reduced to various simplified channel models by properly adjusting model parameters. Statistical properties of the proposed general 5G small-scale fading channel model are investigated to demonstrate its capability of capturing channel characteristics of various scenarios, with excellent fitting to some corresponding channel measurements.
Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook
Oct 16, 2023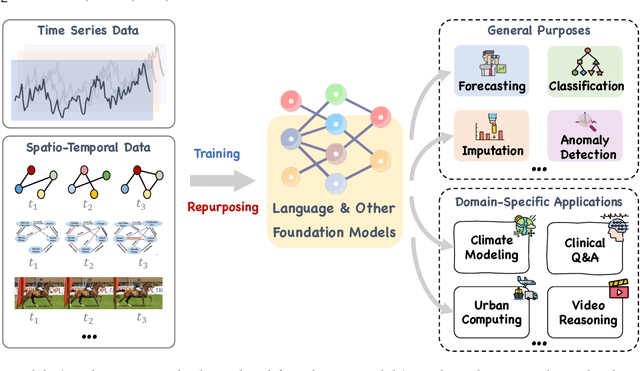
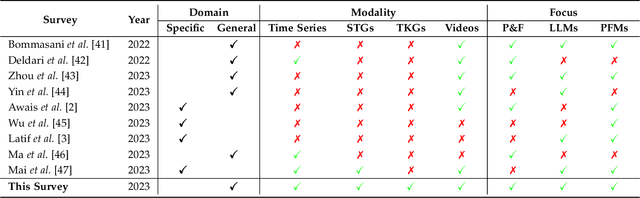
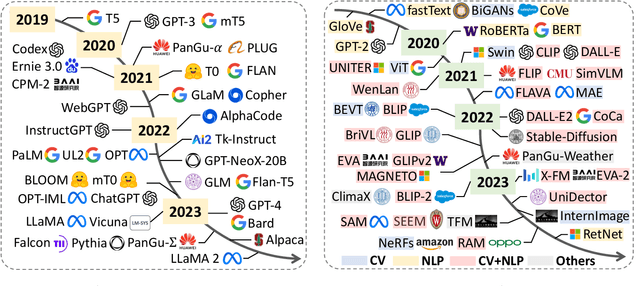
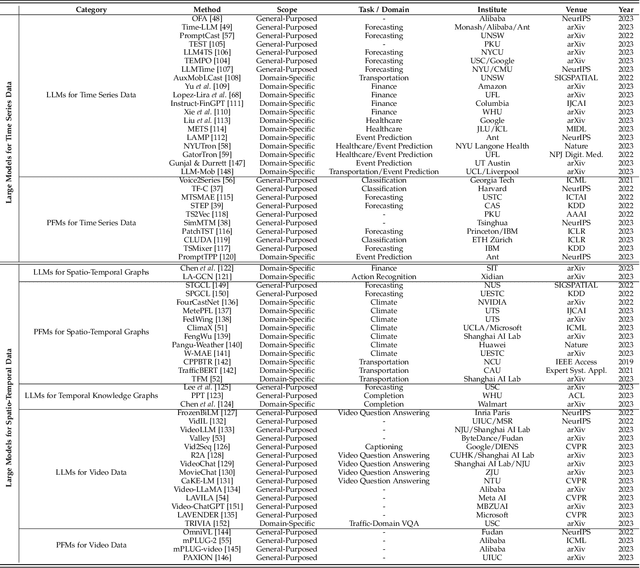
Temporal data, notably time series and spatio-temporal data, are prevalent in real-world applications. They capture dynamic system measurements and are produced in vast quantities by both physical and virtual sensors. Analyzing these data types is vital to harnessing the rich information they encompass and thus benefits a wide range of downstream tasks. Recent advances in large language and other foundational models have spurred increased use of these models in time series and spatio-temporal data mining. Such methodologies not only enable enhanced pattern recognition and reasoning across diverse domains but also lay the groundwork for artificial general intelligence capable of comprehending and processing common temporal data. In this survey, we offer a comprehensive and up-to-date review of large models tailored (or adapted) for time series and spatio-temporal data, spanning four key facets: data types, model categories, model scopes, and application areas/tasks. Our objective is to equip practitioners with the knowledge to develop applications and further research in this underexplored domain. We primarily categorize the existing literature into two major clusters: large models for time series analysis (LM4TS) and spatio-temporal data mining (LM4STD). On this basis, we further classify research based on model scopes (i.e., general vs. domain-specific) and application areas/tasks. We also provide a comprehensive collection of pertinent resources, including datasets, model assets, and useful tools, categorized by mainstream applications. This survey coalesces the latest strides in large model-centric research on time series and spatio-temporal data, underscoring the solid foundations, current advances, practical applications, abundant resources, and future research opportunities.
SoTTA: Robust Test-Time Adaptation on Noisy Data Streams
Oct 16, 2023Test-time adaptation (TTA) aims to address distributional shifts between training and testing data using only unlabeled test data streams for continual model adaptation. However, most TTA methods assume benign test streams, while test samples could be unexpectedly diverse in the wild. For instance, an unseen object or noise could appear in autonomous driving. This leads to a new threat to existing TTA algorithms; we found that prior TTA algorithms suffer from those noisy test samples as they blindly adapt to incoming samples. To address this problem, we present Screening-out Test-Time Adaptation (SoTTA), a novel TTA algorithm that is robust to noisy samples. The key enabler of SoTTA is two-fold: (i) input-wise robustness via high-confidence uniform-class sampling that effectively filters out the impact of noisy samples and (ii) parameter-wise robustness via entropy-sharpness minimization that improves the robustness of model parameters against large gradients from noisy samples. Our evaluation with standard TTA benchmarks with various noisy scenarios shows that our method outperforms state-of-the-art TTA methods under the presence of noisy samples and achieves comparable accuracy to those methods without noisy samples. The source code is available at https://github.com/taeckyung/SoTTA .
On the Out-Of-Distribution Robustness of Self-Supervised Representation Learning for Phonocardiogram Signals
Dec 01, 2023Objective: Despite the recent increase in research activity, deep-learning models have not yet been widely accepted in medicine. The shortage of high-quality annotated data often hinders the development of robust and generalizable models, which do not suffer from degraded effectiveness when presented with newly-collected, out-of-distribution (OOD) datasets. Methods: Contrastive Self-Supervised Learning (SSL) offers a potential solution to the scarcity of labeled data as it takes advantage of unlabeled data to increase model effectiveness and robustness. In this research, we propose applying contrastive SSL for detecting abnormalities in phonocardiogram (PCG) samples by learning a generalized representation of the signal. Specifically, we perform an extensive comparative evaluation of a wide range of audio-based augmentations and evaluate trained classifiers on multiple datasets across different downstream tasks. Results: We experimentally demonstrate that, depending on its training distribution, the effectiveness of a fully-supervised model can degrade up to 32% when evaluated on unseen data, while SSL models only lose up to 10% or even improve in some cases. Conclusions: Contrastive SSL pretraining can assist in providing robust classifiers which can generalize to unseen, OOD data, without relying on time- and labor-intensive annotation processes by medical experts. Furthermore, the proposed extensive evaluation protocol sheds light on the most promising and appropriate augmentations for robust PCG signal processing. Significance: We provide researchers and practitioners with a roadmap towards producing robust models for PCG classification, in addition to an open-source codebase for developing novel approaches.
A Low-Power Neuromorphic Approach for Efficient Eye-Tracking
Dec 01, 2023This paper introduces a neuromorphic methodology for eye tracking, harnessing pure event data captured by a Dynamic Vision Sensor (DVS) camera. The framework integrates a directly trained Spiking Neuron Network (SNN) regression model and leverages a state-of-the-art low power edge neuromorphic processor - Speck, collectively aiming to advance the precision and efficiency of eye-tracking systems. First, we introduce a representative event-based eye-tracking dataset, "Ini-30", which was collected with two glass-mounted DVS cameras from thirty volunteers. Then,a SNN model, based on Integrate And Fire (IAF) neurons, named "Retina", is described , featuring only 64k parameters (6.63x fewer than the latest) and achieving pupil tracking error of only 3.24 pixels in a 64x64 DVS input. The continous regression output is obtained by means of convolution using a non-spiking temporal 1D filter slided across the output spiking layer. Finally, we evaluate Retina on the neuromorphic processor, showing an end-to-end power between 2.89-4.8 mW and a latency of 5.57-8.01 mS dependent on the time window. We also benchmark our model against the latest event-based eye-tracking method, "3ET", which was built upon event frames. Results show that Retina achieves superior precision with 1.24px less pupil centroid error and reduced computational complexity with 35 times fewer MAC operations. We hope this work will open avenues for further investigation of close-loop neuromorphic solutions and true event-based training pursuing edge performance.
Learning to forecast diagnostic parameters using pre-trained weather embedding
Dec 01, 2023Data-driven weather prediction (DDWP) models are increasingly becoming popular for weather forecasting. However, while operational weather forecasts predict a wide variety of weather variables, DDWPs currently forecast a specific set of key prognostic variables. Non-prognostic ("diagnostic") variables are sometimes modeled separately as dependent variables of the prognostic variables (c.f. FourCastNet), or by including the diagnostic variable as a target in the DDWP. However, the cost of training and deploying bespoke models for each diagnostic variable can increase dramatically with more diagnostic variables, and limit the operational use of such models. Likewise, retraining an entire DDWP each time a new diagnostic variable is added is also cost-prohibitive. We present an two-stage approach that allows new diagnostic variables to be added to an end-to-end DDWP model without the expensive retraining. In the first stage, we train an autoencoder that learns to embed prognostic variables into a latent space. In the second stage, the autoencoder is frozen and "downstream" models are trained to predict diagnostic variables using only the latent representations of prognostic variables as input. Our experiments indicate that models trained using the two-stage approach offer accuracy comparable to training bespoke models, while leading to significant reduction in resource utilization during training and inference. This approach allows for new "downstream" models to be developed as needed, without affecting existing models and thus reducing the friction in operationalizing new models.
Towards Clinical Prediction with Transparency: An Explainable AI Approach to Survival Modelling in Residential Aged Care
Dec 01, 2023Background: Accurate survival time estimates aid end-of-life medical decision-making. Objectives: Develop an interpretable survival model for elderly residential aged care residents using advanced machine learning. Setting: A major Australasian residential aged care provider. Participants: Residents aged 65+ admitted for long-term care from July 2017 to August 2023. Sample size: 11,944 residents across 40 facilities. Predictors: Factors include age, gender, health status, co-morbidities, cognitive function, mood, nutrition, mobility, smoking, sleep, skin integrity, and continence. Outcome: Probability of survival post-admission, specifically calibrated for 6-month survival estimates. Statistical Analysis: Tested CoxPH, EN, RR, Lasso, GB, XGB, and RF models in 20 experiments with a 90/10 train/test split. Evaluated accuracy using C-index, Harrell's C-index, dynamic AUROC, IBS, and calibrated ROC. Chose XGB for its performance and calibrated it for 1, 3, 6, and 12-month predictions using Platt scaling. Employed SHAP values to analyze predictor impacts. Results: GB, XGB, and RF models showed the highest C-Index values (0.714, 0.712, 0.712). The optimal XGB model demonstrated a 6-month survival prediction AUROC of 0.746 (95% CI 0.744-0.749). Key mortality predictors include age, male gender, mobility, health status, pressure ulcer risk, and appetite. Conclusions: The study successfully applies machine learning to create a survival model for aged care, aligning with clinical insights on mortality risk factors and enhancing model interpretability and clinical utility through explainable AI.
Towards Running Time Analysis of Interactive Multi-objective Evolutionary Algorithms
Oct 15, 2023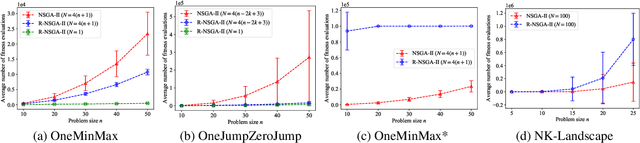
Evolutionary algorithms (EAs) are widely used for multi-objective optimization due to their population-based nature. Traditional multi-objective EAs (MOEAs) generate a large set of solutions to approximate the Pareto front, leaving a decision maker (DM) with the task of selecting a preferred solution. However, this process can be inefficient and time-consuming, especially when there are many objectives or the subjective preferences of DM is known. To address this issue, interactive MOEAs (iMOEAs) combine decision making into the optimization process, i.e., update the population with the help of the DM. In contrast to their wide applications, there has existed only two pieces of theoretical works on iMOEAs, which only considered interactive variants of the two simple single-objective algorithms, RLS and (1+1)-EA. This paper provides the first running time analysis (the essential theoretical aspect of EAs) for practical iMOEAs. Specifically, we prove that the expected running time of the well-developed interactive NSGA-II (called R-NSGA-II) for solving the OneMinMax and OneJumpZeroJump problems is $O(n \log n)$ and $O(n^k)$, respectively, which are all asymptotically faster than the traditional NSGA-II. Meanwhile, we present a variant of OneMinMax, and prove that R-NSGA-II can be exponentially slower than NSGA-II. These results provide theoretical justification for the effectiveness of iMOEAs while identifying situations where they may fail. Experiments are also conducted to validate the theoretical results.
Autoregressive Language Models For Estimating the Entropy of Epic EHR Audit Logs
Nov 26, 2023EHR audit logs are a highly granular stream of events that capture clinician activities, and is a significant area of interest for research in characterizing clinician workflow on the electronic health record (EHR). Existing techniques to measure the complexity of workflow through EHR audit logs (audit logs) involve time- or frequency-based cross-sectional aggregations that are unable to capture the full complexity of a EHR session. We briefly evaluate the usage of transformer-based tabular language model (tabular LM) in measuring the entropy or disorderedness of action sequences within workflow and release the evaluated models publicly.