 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWearable Foundation Models Should Go Beyond Static Encoders
Mar 20, 2026Wearable foundation models (WFMs), trained on large volumes of data collected by affordable, always-on devices, have demonstrated strong performance on short-term, well-defined health monitoring tasks, including activity recognition, fitness tracking, and cardiovascular signal assessment. However, most existing WFMs primarily map short temporal windows to predefined labels via static encoders, emphasizing retrospective prediction rather than reasoning over evolving personal history, context, and future risk trajectories. As a result, they are poorly suited for modeling chronic, progressive, or episodic health conditions that unfold over weeks, months or years. Hence, we argue that WFMs must move beyond static encoders and be explicitly designed for longitudinal, anticipatory health reasoning. We identify three foundational shifts required to enable this transition: (1) Structurally rich data, which goes beyond isolated datasets or outcome-conditioned collection to integrated multimodal, long-term personal trajectories, and contextual metadata, ideally supported by open and interoperable data ecosystems; (2) Longitudinal-aware multimodal modeling, which prioritizes long-context inference, temporal abstraction, and personalization over cross-sectional or population-level prediction; and (3) Agentic inference systems, which move beyond static prediction to support planning, decision-making, and clinically grounded intervention under uncertainty. Together, these shifts reframe wearable health monitoring from retrospective signal interpretation toward continuous, anticipatory, and human-aligned health support.
ConSensus: Multi-Agent Collaboration for Multimodal Sensing
Jan 10, 2026Large language models (LLMs) are increasingly grounded in sensor data to perceive and reason about human physiology and the physical world. However, accurately interpreting heterogeneous multimodal sensor data remains a fundamental challenge. We show that a single monolithic LLM often fails to reason coherently across modalities, leading to incomplete interpretations and prior-knowledge bias. We introduce ConSensus, a training-free multi-agent collaboration framework that decomposes multimodal sensing tasks into specialized, modality-aware agents. To aggregate agent-level interpretations, we propose a hybrid fusion mechanism that balances semantic aggregation, which enables cross-modal reasoning and contextual understanding, with statistical consensus, which provides robustness through agreement across modalities. While each approach has complementary failure modes, their combination enables reliable inference under sensor noise and missing data. We evaluate ConSensus on five diverse multimodal sensing benchmarks, demonstrating an average accuracy improvement of 7.1% over the single-agent baseline. Furthermore, ConSensus matches or exceeds the performance of iterative multi-agent debate methods while achieving a 12.7 times reduction in average fusion token cost through a single-round hybrid fusion protocol, yielding a robust and efficient solution for real-world multimodal sensing tasks.
SNAP: Low-Latency Test-Time Adaptation with Sparse Updates
Nov 19, 2025Test-Time Adaptation (TTA) adjusts models using unlabeled test data to handle dynamic distribution shifts. However, existing methods rely on frequent adaptation and high computational cost, making them unsuitable for resource-constrained edge environments. To address this, we propose SNAP, a sparse TTA framework that reduces adaptation frequency and data usage while preserving accuracy. SNAP maintains competitive accuracy even when adapting based on only 1% of the incoming data stream, demonstrating its robustness under infrequent updates. Our method introduces two key components: (i) Class and Domain Representative Memory (CnDRM), which identifies and stores a small set of samples that are representative of both class and domain characteristics to support efficient adaptation with limited data; and (ii) Inference-only Batch-aware Memory Normalization (IoBMN), which dynamically adjusts normalization statistics at inference time by leveraging these representative samples, enabling efficient alignment to shifting target domains. Integrated with five state-of-the-art TTA algorithms, SNAP reduces latency by up to 93.12%, while keeping the accuracy drop below 3.3%, even across adaptation rates ranging from 1% to 50%. This demonstrates its strong potential for practical use on edge devices serving latency-sensitive applications. The source code is available at https://github.com/chahh9808/SNAP.
Collective Voice: Recovered-Peer Support Mediated by An LLM-Based Chatbot for Eating Disorder Recovery
Sep 18, 2025Peer recovery narratives provide unique benefits beyond professional or lay mentoring by fostering hope and sustained recovery in eating disorder (ED) contexts. Yet, such support is limited by the scarcity of peer-involved programs and potential drawbacks on recovered peers, including relapse risk. To address this, we designed RecoveryTeller, a chatbot adopting a recovered-peer persona that portrays itself as someone recovered from an ED. We examined whether such a persona can reproduce the support affordances of peer recovery narratives. We compared RecoveryTeller with a lay-mentor persona chatbot offering similar guidance but without a recovery background. We conducted a 20-day cross-over deployment study with 26 ED participants, each using both chatbots for 10 days. RecoveryTeller elicited stronger emotional resonance than a lay-mentor chatbot, yet tensions between emotional and epistemic trust led participants to view the two personas as complementary rather than substitutes. We provide design implications for mental health chatbot persona design.
QuRe: Query-Relevant Retrieval through Hard Negative Sampling in Composed Image Retrieval
Jul 16, 2025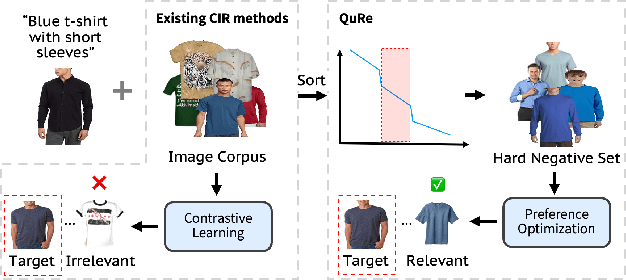
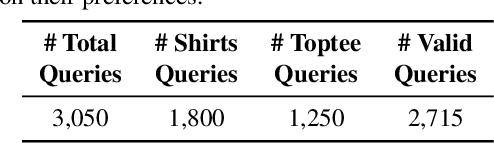
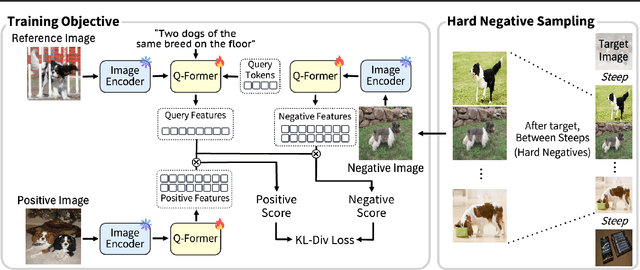
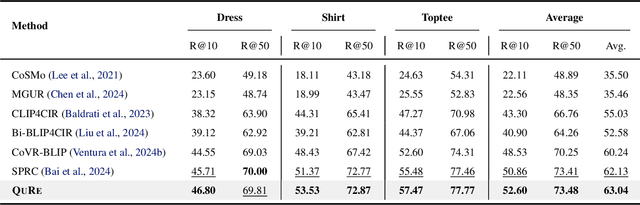
Composed Image Retrieval (CIR) retrieves relevant images based on a reference image and accompanying text describing desired modifications. However, existing CIR methods only focus on retrieving the target image and disregard the relevance of other images. This limitation arises because most methods employing contrastive learning-which treats the target image as positive and all other images in the batch as negatives-can inadvertently include false negatives. This may result in retrieving irrelevant images, reducing user satisfaction even when the target image is retrieved. To address this issue, we propose Query-Relevant Retrieval through Hard Negative Sampling (QuRe), which optimizes a reward model objective to reduce false negatives. Additionally, we introduce a hard negative sampling strategy that selects images positioned between two steep drops in relevance scores following the target image, to effectively filter false negatives. In order to evaluate CIR models on their alignment with human satisfaction, we create Human-Preference FashionIQ (HP-FashionIQ), a new dataset that explicitly captures user preferences beyond target retrieval. Extensive experiments demonstrate that QuRe achieves state-of-the-art performance on FashionIQ and CIRR datasets while exhibiting the strongest alignment with human preferences on the HP-FashionIQ dataset. The source code is available at https://github.com/jackwaky/QuRe.
Test-Time Adaptation with Binary Feedback
May 24, 2025



Deep learning models perform poorly when domain shifts exist between training and test data. Test-time adaptation (TTA) is a paradigm to mitigate this issue by adapting pre-trained models using only unlabeled test samples. However, existing TTA methods can fail under severe domain shifts, while recent active TTA approaches requiring full-class labels are impractical due to high labeling costs. To address this issue, we introduce a new setting of TTA with binary feedback. This setting uses a few binary feedback inputs from annotators to indicate whether model predictions are correct, thereby significantly reducing the labeling burden of annotators. Under the setting, we propose BiTTA, a novel dual-path optimization framework that leverages reinforcement learning to balance binary feedback-guided adaptation on uncertain samples with agreement-based self-adaptation on confident predictions. Experiments show BiTTA achieves 13.3%p accuracy improvements over state-of-the-art baselines, demonstrating its effectiveness in handling severe distribution shifts with minimal labeling effort. The source code is available at https://github.com/taeckyung/BiTTA.
Private Yet Social: How LLM Chatbots Support and Challenge Eating Disorder Recovery
Dec 16, 2024


Eating disorders (ED) are complex mental health conditions that require long-term management and support. Recent advancements in large language model (LLM)-based chatbots offer the potential to assist individuals in receiving immediate support. Yet, concerns remain about their reliability and safety in sensitive contexts such as ED. We explore the opportunities and potential harms of using LLM-based chatbots for ED recovery. We observe the interactions between 26 participants with ED and an LLM-based chatbot, WellnessBot, designed to support ED recovery, over 10 days. We discovered that our participants have felt empowered in recovery by discussing ED-related stories with the chatbot, which served as a personal yet social avenue. However, we also identified harmful chatbot responses, especially concerning individuals with ED, that went unnoticed partly due to participants' unquestioning trust in the chatbot's reliability. Based on these findings, we provide design implications for safe and effective LLM-based interventions in ED management.
(FL)$^2$: Overcoming Few Labels in Federated Semi-Supervised Learning
Oct 31, 2024



Federated Learning (FL) is a distributed machine learning framework that trains accurate global models while preserving clients' privacy-sensitive data. However, most FL approaches assume that clients possess labeled data, which is often not the case in practice. Federated Semi-Supervised Learning (FSSL) addresses this label deficiency problem, targeting situations where only the server has a small amount of labeled data while clients do not. However, a significant performance gap exists between Centralized Semi-Supervised Learning (SSL) and FSSL. This gap arises from confirmation bias, which is more pronounced in FSSL due to multiple local training epochs and the separation of labeled and unlabeled data. We propose $(FL)^2$, a robust training method for unlabeled clients using sharpness-aware consistency regularization. We show that regularizing the original pseudo-labeling loss is suboptimal, and hence we carefully select unlabeled samples for regularization. We further introduce client-specific adaptive thresholding and learning status-aware aggregation to adjust the training process based on the learning progress of each client. Our experiments on three benchmark datasets demonstrate that our approach significantly improves performance and bridges the gap with SSL, particularly in scenarios with scarce labeled data.
SoundCollage: Automated Discovery of New Classes in Audio Datasets
Oct 30, 2024



Developing new machine learning applications often requires the collection of new datasets. However, existing datasets may already contain relevant information to train models for new purposes. We propose SoundCollage: a framework to discover new classes within audio datasets by incorporating (1) an audio pre-processing pipeline to decompose different sounds in audio samples and (2) an automated model-based annotation mechanism to identify the discovered classes. Furthermore, we introduce clarity measure to assess the coherence of the discovered classes for better training new downstream applications. Our evaluations show that the accuracy of downstream audio classifiers within discovered class samples and held-out datasets improves over the baseline by up to 34.7% and 4.5%, respectively, highlighting the potential of SoundCollage in making datasets reusable by labeling with newly discovered classes. To encourage further research in this area, we open-source our code at https://github.com/nokia-bell-labs/audio-class-discovery.
By My Eyes: Grounding Multimodal Large Language Models with Sensor Data via Visual Prompting
Jul 15, 2024



Large language models (LLMs) have demonstrated exceptional abilities across various domains. However, utilizing LLMs for ubiquitous sensing applications remains challenging as existing text-prompt methods show significant performance degradation when handling long sensor data sequences. We propose a visual prompting approach for sensor data using multimodal LLMs (MLLMs). We design a visual prompt that directs MLLMs to utilize visualized sensor data alongside the target sensory task descriptions. Additionally, we introduce a visualization generator that automates the creation of optimal visualizations tailored to a given sensory task, eliminating the need for prior task-specific knowledge. We evaluated our approach on nine sensory tasks involving four sensing modalities, achieving an average of 10% higher accuracy than text-based prompts and reducing token costs by 15.8x. Our findings highlight the effectiveness and cost-efficiency of visual prompts with MLLMs for various sensory tasks.