 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Underwater Acoustic Signal Recognition Based on Salient Feature
Jan 04, 2024
With the rapid advancement of technology, the recognition of underwater acoustic signals in complex environments has become increasingly crucial. Currently, mainstream underwater acoustic signal recognition relies primarily on time-frequency analysis to extract spectral features, finding widespread applications in the field. However, existing recognition methods heavily depend on expert systems, facing limitations such as restricted knowledge bases and challenges in handling complex relationships. These limitations stem from the complexity and maintenance difficulties associated with rules or inference engines. Recognizing the potential advantages of deep learning in handling intricate relationships, this paper proposes a method utilizing neural networks for underwater acoustic signal recognition. The proposed approach involves continual learning of features extracted from spectra for the classification of underwater acoustic signals. Deep learning models can automatically learn abstract features from data and continually adjust weights during training to enhance classification performance.
Blar-SQL: Faster, Stronger, Smaller NL2SQL
Jan 04, 2024Large Language Models (LLMs) have gained considerable notoriety in the field of natural language to SQL tasks (NL2SQL). In this study, we show how task decomposition can greatly benefit LLMs in database understanding and query generation in order to answer human questions with an SQL query. We fined-tuned open source models, specifically Llama-2 and Code Llama, by combining 2 different models each designated to focus on one of two tasks in order to leverage each model's core competency to further increase the accuracy of the final SQL query. We propose a new framework to divide the schema into chunks in order to fit more information into a limited context. Our results are comparable with those obtained by GPT-4 at the same time being 135 times smaller, 90 times faster and more than 100 times cheaper than GPT-4.
TransNAS-TSAD: Harnessing Transformers for Multi-Objective Neural Architecture Search in Time Series Anomaly Detection
Dec 03, 2023The surge in real-time data collection across various industries has underscored the need for advanced anomaly detection in both univariate and multivariate time series data. Traditional methods, while comprehensive, often struggle to capture the complex interdependencies in such data. This paper introduces TransNAS-TSAD, a novel framework that synergizes transformer architecture with neural architecture search (NAS), enhanced through NSGA-II algorithm optimization. This innovative approach effectively tackles the complexities of both univariate and multivariate time series, balancing computational efficiency with detection accuracy. Our evaluation reveals that TransNAS-TSAD surpasses conventional anomaly detection models, demonstrating marked improvements in diverse data scenarios. We also propose the Efficiency-Accuracy-Complexity Score (EACS) as a new metric for assessing model performance, emphasizing the crucial balance between accuracy and computational resources. TransNAS-TSAD sets a new benchmark in time series anomaly detection, offering a versatile, efficient solution for complex real-world applications. This research paves the way for future developments in the field, highlighting its potential in a wide range of industry applications.
Understanding Representation Learnability of Nonlinear Self-Supervised Learning
Jan 06, 2024Self-supervised learning (SSL) has empirically shown its data representation learnability in many downstream tasks. There are only a few theoretical works on data representation learnability, and many of those focus on final data representation, treating the nonlinear neural network as a ``black box". However, the accurate learning results of neural networks are crucial for describing the data distribution features learned by SSL models. Our paper is the first to analyze the learning results of the nonlinear SSL model accurately. We consider a toy data distribution that contains two features: the label-related feature and the hidden feature. Unlike previous linear setting work that depends on closed-form solutions, we use the gradient descent algorithm to train a 1-layer nonlinear SSL model with a certain initialization region and prove that the model converges to a local minimum. Furthermore, different from the complex iterative analysis, we propose a new analysis process which uses the exact version of Inverse Function Theorem to accurately describe the features learned by the local minimum. With this local minimum, we prove that the nonlinear SSL model can capture the label-related feature and hidden feature at the same time. In contrast, the nonlinear supervised learning (SL) model can only learn the label-related feature. We also present the learning processes and results of the nonlinear SSL and SL model via simulation experiments.
Spatiotemporally adaptive compression for scientific dataset with feature preservation -- a case study on simulation data with extreme climate events analysis
Jan 06, 2024Scientific discoveries are increasingly constrained by limited storage space and I/O capacities. For time-series simulations and experiments, their data often need to be decimated over timesteps to accommodate storage and I/O limitations. In this paper, we propose a technique that addresses storage costs while improving post-analysis accuracy through spatiotemporal adaptive, error-controlled lossy compression. We investigate the trade-off between data precision and temporal output rates, revealing that reducing data precision and increasing timestep frequency lead to more accurate analysis outcomes. Additionally, we integrate spatiotemporal feature detection with data compression and demonstrate that performing adaptive error-bounded compression in higher dimensional space enables greater compression ratios, leveraging the error propagation theory of a transformation-based compressor. To evaluate our approach, we conduct experiments using the well-known E3SM climate simulation code and apply our method to compress variables used for cyclone tracking. Our results show a significant reduction in storage size while enhancing the quality of cyclone tracking analysis, both quantitatively and qualitatively, in comparison to the prevalent timestep decimation approach. Compared to three state-of-the-art lossy compressors lacking feature preservation capabilities, our adaptive compression framework improves perfectly matched cases in TC tracking by 26.4-51.3% at medium compression ratios and by 77.3-571.1% at large compression ratios, with a merely 5-11% computational overhead.
* 10 pages, 13 figures, 2023 IEEE International Conference on e-Science and Grid Computing
Efficient Asynchronous Federated Learning with Sparsification and Quantization
Jan 06, 2024While data is distributed in multiple edge devices, Federated Learning (FL) is attracting more and more attention to collaboratively train a machine learning model without transferring raw data. FL generally exploits a parameter server and a large number of edge devices during the whole process of the model training, while several devices are selected in each round. However, straggler devices may slow down the training process or even make the system crash during training. Meanwhile, other idle edge devices remain unused. As the bandwidth between the devices and the server is relatively low, the communication of intermediate data becomes a bottleneck. In this paper, we propose Time-Efficient Asynchronous federated learning with Sparsification and Quantization, i.e., TEASQ-Fed. TEASQ-Fed can fully exploit edge devices to asynchronously participate in the training process by actively applying for tasks. We utilize control parameters to choose an appropriate number of parallel edge devices, which simultaneously execute the training tasks. In addition, we introduce a caching mechanism and weighted averaging with respect to model staleness to further improve the accuracy. Furthermore, we propose a sparsification and quantitation approach to compress the intermediate data to accelerate the training. The experimental results reveal that TEASQ-Fed improves the accuracy (up to 16.67% higher) while accelerating the convergence of model training (up to twice faster).
Local Adaptive Clustering Based Image Matching for Automatic Visual Identification
Jan 03, 2024Monitoring cameras are extensively utilized in industrial production to monitor equipment running. With advancements in computer vision, device recognition using image features is viable. This paper presents a vision-assisted identification system that implements real-time automatic equipment labeling through image matching in surveillance videos. The system deploys the ORB algorithm to extract image features and the GMS algorithm to remove incorrect matching points. According to the principles of clustering and template locality, a method known as Local Adaptive Clustering (LAC) has been established to enhance label positioning. This method segments matching templates using the cluster center, which improves the efficiency and stability of labels. The experimental results demonstrate that LAC effectively curtails the label drift.
TEA: Test-time Energy Adaptation
Nov 24, 2023Test-time adaptation (TTA) aims to improve model generalizability when test data diverges from training distribution, offering the distinct advantage of not requiring access to training data and processes, especially valuable in the context of large pre-trained models. However, current TTA methods fail to address the fundamental issue: covariate shift, i.e., the decreased generalizability can be attributed to the model's reliance on the marginal distribution of the training data, which may impair model calibration and introduce confirmation bias. To address this, we propose a novel energy-based perspective, enhancing the model's perception of target data distributions without requiring access to training data or processes. Building on this perspective, we introduce $\textbf{T}$est-time $\textbf{E}$nergy $\textbf{A}$daptation ($\textbf{TEA}$), which transforms the trained classifier into an energy-based model and aligns the model's distribution with the test data's, enhancing its ability to perceive test distributions and thus improving overall generalizability. Extensive experiments across multiple tasks, benchmarks and architectures demonstrate TEA's superior generalization performance against state-of-the-art methods. Further in-depth analyses reveal that TEA can equip the model with a comprehensive perception of test distribution, ultimately paving the way toward improved generalization and calibration.
YOLO-OB: An improved anchor-free real-time multiscale colon polyp detector in colonoscopy
Dec 14, 2023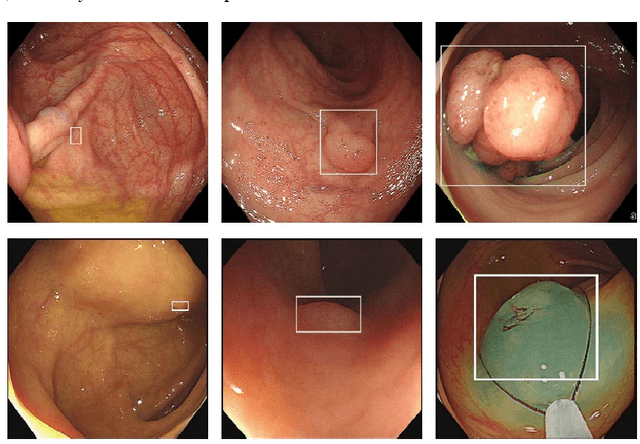

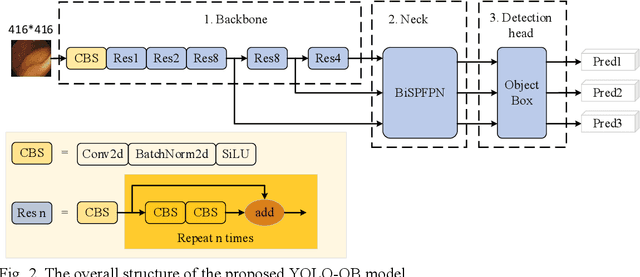

Colon cancer is expected to become the second leading cause of cancer death in the United States in 2023. Although colonoscopy is one of the most effective methods for early prevention of colon cancer, up to 30% of polyps may be missed by endoscopists, thereby increasing patients' risk of developing colon cancer. Though deep neural networks have been proven to be an effective means of enhancing the detection rate of polyps. However, the variation of polyp size brings the following problems: (1) it is difficult to design an efficient and sufficient multi-scale feature fusion structure; (2) matching polyps of different sizes with fixed-size anchor boxes is a hard challenge. These problems reduce the performance of polyp detection and also lower the model's training and detection efficiency. To address these challenges, this paper proposes a new model called YOLO-OB. Specifically, we developed a bidirectional multiscale feature fusion structure, BiSPFPN, which could enhance the feature fusion capability across different depths of a CNN. We employed the ObjectBox detection head, which used a center-based anchor-free box regression strategy that could detect polyps of different sizes on feature maps of any scale. Experiments on the public dataset SUN and the self-collected colon polyp dataset Union demonstrated that the proposed model significantly improved various performance metrics of polyp detection, especially the recall rate. Compared to the state-of-the-art results on the public dataset SUN, the proposed method achieved a 6.73% increase on recall rate from 91.5% to 98.23%. Furthermore, our YOLO-OB was able to achieve real-time polyp detection at a speed of 39 frames per second using a RTX3090 graphics card. The implementation of this paper can be found here: https://github.com/seanyan62/YOLO-OB.
A Low-Complexity Range Estimation with Adjusted Affine Frequency Division Multiplexing Waveform
Dec 29, 2023Affine frequency division multiplexing (AFDM) is a recently proposed communication waveform for time-varying channel scenarios. As a chirp-based multicarrier modulation technique it can not only satisfy the needs of multiple scenarios in future mobile communication networks but also achieve good performance in radar sensing by adjusting the built-in parameters, making it a promising air interface waveform in integrated sensing and communication (ISAC) applications. In this paper, we investigate an AFDM-based radar system and analyze the radar ambiguity function of AFDM with different built-in parameters, based on which we find an AFDM waveform with the specific parameter c2 owns the near-optimal time-domain ambiguity function. Then a low-complexity algorithm based on matched filtering for high-resolution target range estimation is proposed for this specific AFDM waveform. Through simulation and analysis, the specific AFDM waveform has near-optimal range estimation performance with the proposed low-complexity algorithm while having the same bit error rate (BER) performance as orthogonal time frequency space (OTFS) using simple linear minimum mean square error (LMMSE) equalizer.