 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Autonomous Approach to Measure Social Distances and Hygienic Practices during COVID-19 Pandemic in Public Open Spaces
Nov 14, 2020

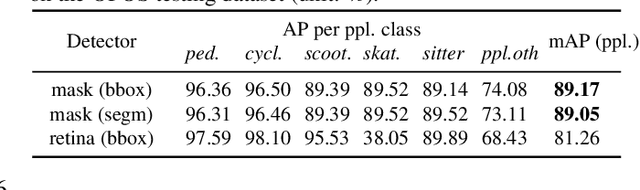
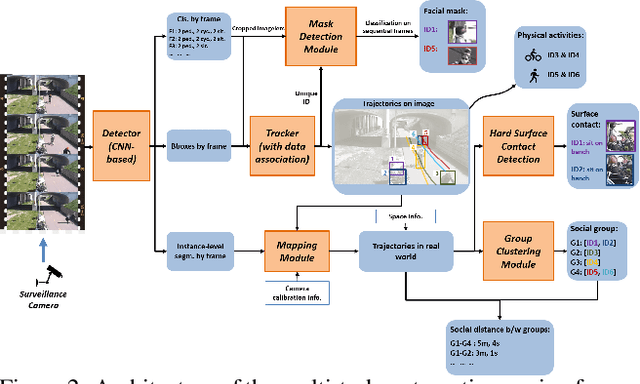
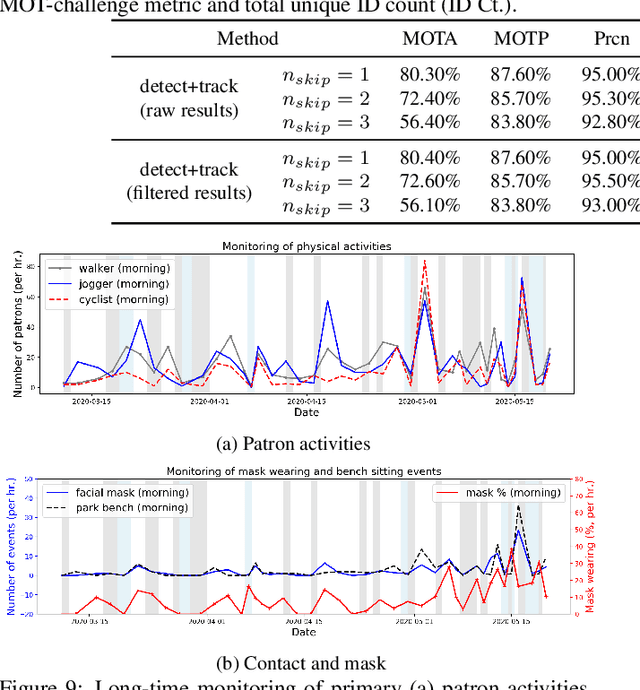
Coronavirus has been spreading around the world since the end of 2019. The virus can cause acute respiratory syndrome, which can be lethal, and is easily transmitted between hosts. Most states have issued state-at-home executive orders, however, parks and other public open spaces have largely remained open and are seeing sharp increases in public use. Therefore, in order to ensure public safety, it is imperative for patrons of public open spaces to practice safe hygiene and take preventative measures. This work provides a scalable sensing approach to detect physical activities within public open spaces and monitor adherence to social distancing guidelines suggested by the US Centers for Disease Control and Prevention (CDC). A deep learning-based computer vision sensing framework is designed to investigate the careful and proper utilization of parks and park facilities with hard surfaces (e.g. benches, fence poles, and trash cans) using video feeds from a pre-installed surveillance camera network. The sensing framework consists of a CNN-based object detector, a multi-target tracker, a mapping module, and a group reasoning module. The experiments are carried out during the COVID-19 pandemic between March 2020 and May 2020 across several key locations at the Detroit Riverfront Parks in Detroit, Michigan. The sensing framework is validated by comparing automatic sensing results with manually labeled ground-truth results. The proposed approach significantly improves the efficiency of providing spatial and temporal statistics of users in public open spaces by creating straightforward data visualizations for federal and state agencies. The results can also provide on-time triggering information for an alarming or actuator system which can later be added to intervene inappropriate behavior during this pandemic.
Brief Announcement: On the Limits of Parallelizing Convolutional Neural Networks on GPUs
May 28, 2020

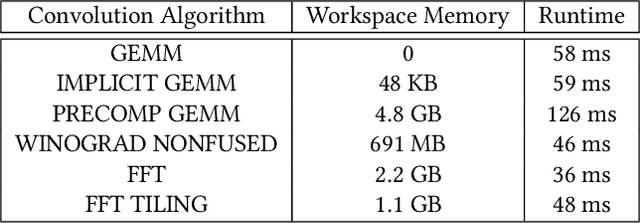
GPUs are currently the platform of choice for training neural networks. However, training a deep neural network (DNN) is a time-consuming process even on GPUs because of the massive number of parameters that have to be learned. As a result, accelerating DNN training has been an area of significant research in the last couple of years. While earlier networks such as AlexNet had a linear dependency between layers and operations, state-of-the-art networks such as ResNet, PathNet, and GoogleNet have a non-linear structure that exhibits a higher level of inter-operation parallelism. However, popular deep learning (DL) frameworks such as TensorFlow and PyTorch launch the majority of neural network operations, especially convolutions, serially on GPUs and do not exploit this inter-op parallelism. In this brief announcement, we make a case for the need and potential benefit of exploiting this rich parallelism in state-of-the-art non-linear networks for reducing the training time. We identify the challenges and limitations in enabling concurrent layer execution on GPU backends (such as cuDNN) of DL frameworks and propose potential solutions.
Neural Physicist: Learning Physical Dynamics from Image Sequences
Jun 09, 2020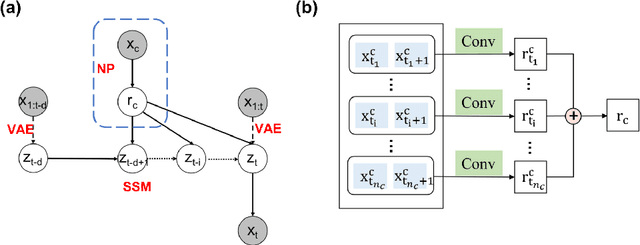
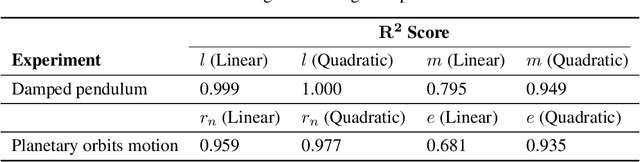

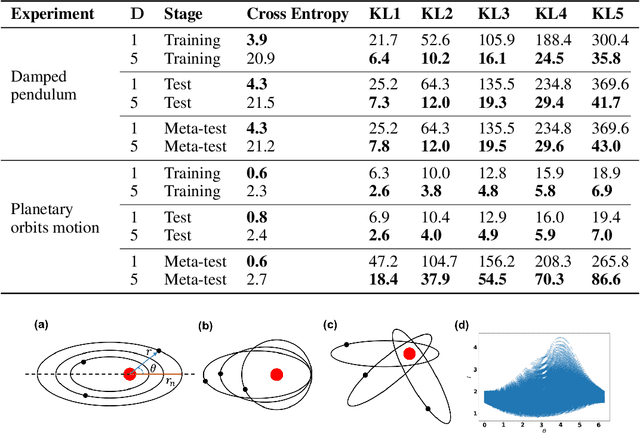
We present a novel architecture named Neural Physicist (NeurPhy) to learn physical dynamics directly from image sequences using deep neural networks. For any physical system, given the global system parameters, the time evolution of states is governed by the underlying physical laws. How to learn meaningful system representations in an end-to-end way and estimate accurate state transition dynamics facilitating long-term prediction have been long-standing challenges. In this paper, by leveraging recent progresses in representation learning and state space models (SSMs), we propose NeurPhy, which uses variational auto-encoder (VAE) to extract underlying Markovian dynamic state at each time step, neural process (NP) to extract the global system parameters, and a non-linear non-recurrent stochastic state space model to learn the physical dynamic transition. We apply NeurPhy to two physical experimental environments, i.e., damped pendulum and planetary orbits motion, and achieve promising results. Our model can not only extract the physically meaningful state representations, but also learn the state transition dynamics enabling long-term predictions for unseen image sequences. Furthermore, from the manifold dimension of the latent state space, we can easily identify the degree of freedom (DoF) of the underlying physical systems.
Deliberate Exploration Supports Navigation in Unfamiliar Worlds
Jul 01, 2020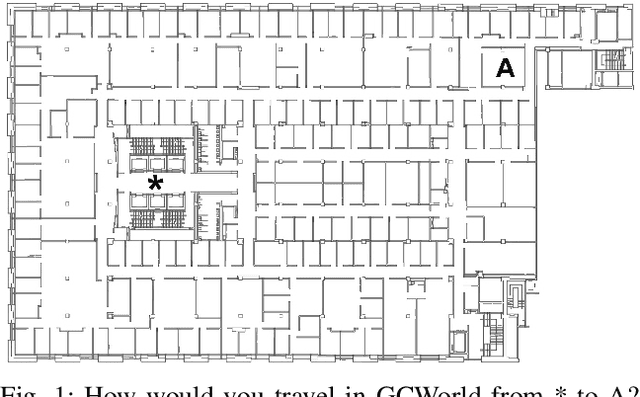
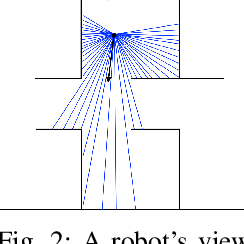
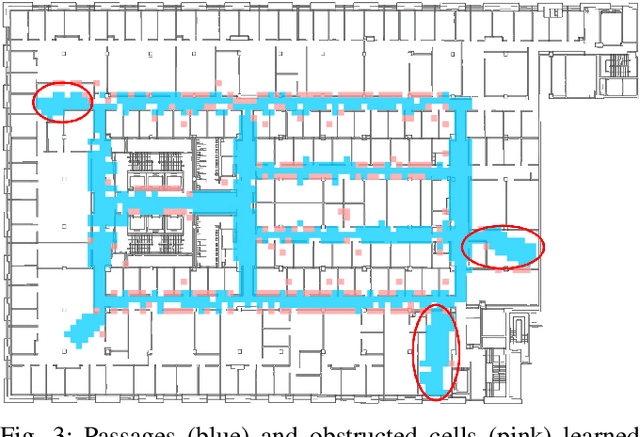
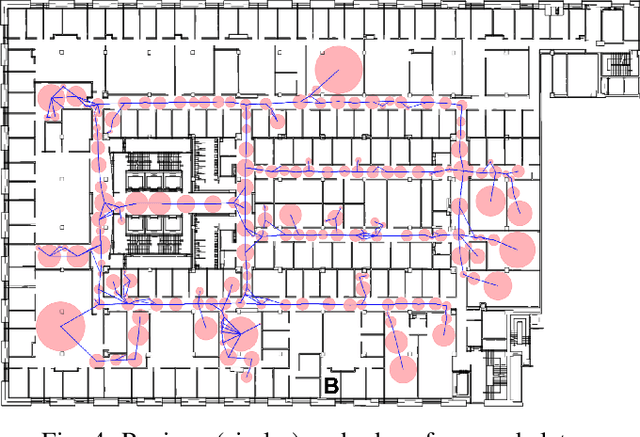
To perform tasks well in a new domain, one must first know something about it. This paper reports on a robot controller for navigation through unfamiliar indoor worlds. Based on spatial affordances, it integrates planning with reactive heuristics. Before it addresses specific targets, however, the system deliberately explores for high-level connectivity and captures that data in a cognitive spatial model. Despite limited exploration time, planning in the resultant model is faster and better supports successful travel in a challenging, realistic space.
Stochastic and Robust MPC for Bipedal Locomotion: A Comparative Study on Robustness and Performance
May 15, 2020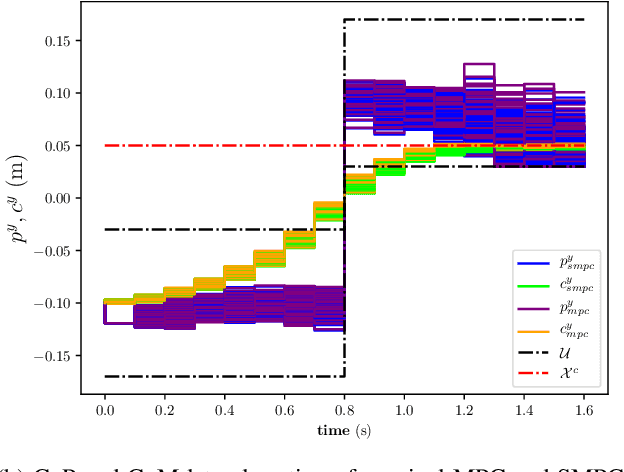
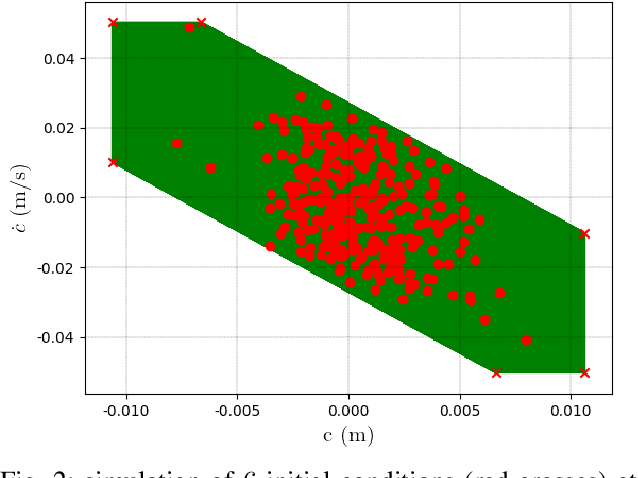
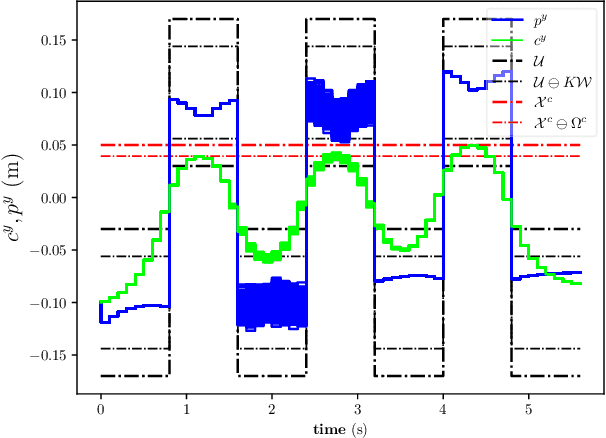
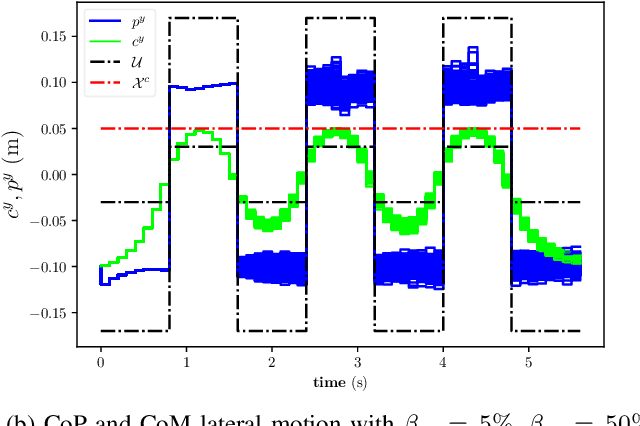
Linear Model Predictive Control (MPC) has been successfully used for generating feasible walking motions for humanoid robots. However, the effect of uncertainties on constraints satisfaction has only been studied using Robust MPC (RMPC) approaches, which account for the worst-case realization of bounded disturbances at each time instant. In this letter, we propose for the first time to use linear stochastic MPC (SMPC) to account for uncertainties in bipedal walking. We show that SMPC offers more flexibility to the user (or a high level decision maker) by tolerating small (user-defined) probabilities of constraint violation. Therefore, SMPC can be tuned to achieve a constraint satisfaction probability that is arbitrarily close to 100\%, but without sacrificing performance as much as tube-based RMPC. We compare SMPC against RMPC in terms of robustness (constraint satisfaction) and performance (optimality). Our results highlight the benefits of SMPC and its interest for the robotics community as a powerful mathematical tool for dealing with uncertainties.
COVID-19 Data Analysis and Forecasting: Algeria and the World
Jul 19, 2020
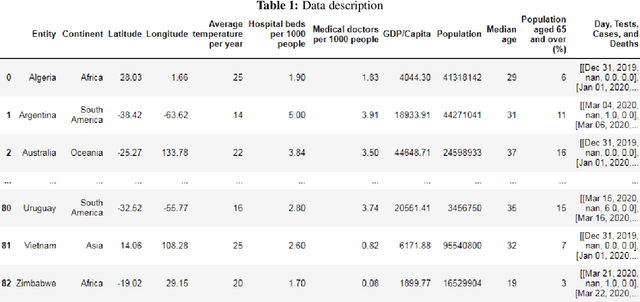
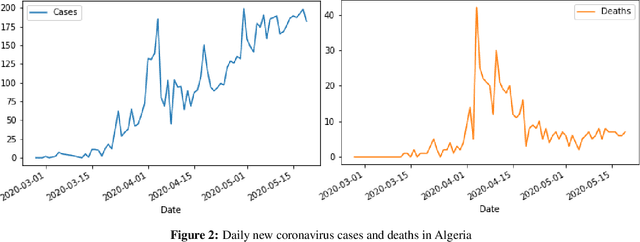
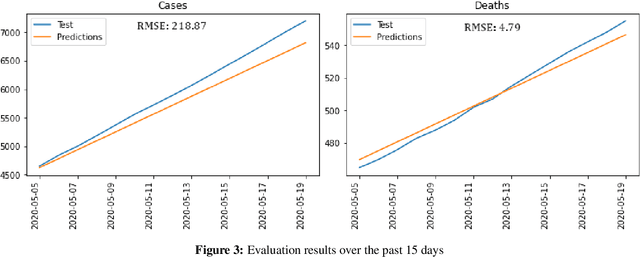
The novel coronavirus disease 2019 COVID-19 has been leading the world into a prominent crisis. As of May 19, 2020, the virus had spread to 215 countries with more than 4,622,001 confirmed cases and 311,916 reported deaths worldwide, including Algeria with 7201 cases and 555 deaths. Analyze and forecast COVID-19 cases and deaths growth could be useful in many ways, governments could estimate medical equipment and take appropriate policy responses, and experts could approximate the peak and the end of the disease. In this work, we first train a time series Prophet model to analyze and forecast the number of COVID-19 cases and deaths in Algeria based on the previously reported numbers. Then, to better understand the spread and the properties of the COVID-19, we include external factors that may contribute to accelerate/slow the spread of the virus, construct a dataset from reliable sources, and conduct a large-scale data analysis considering 82 countries worldwide. The evaluation results show that the time series Prophet model accurately predicts the number of cases and deaths in Algeria with low RMSE scores of 218.87 and 4.79 respectively, while the forecast suggests that the total number of cases and deaths are expected to increase in the coming weeks. Moreover, the worldwide data-driven analysis reveals several correlations between the increase/decrease in the number of cases and deaths and external factors that may contribute to accelerate/slow the spread of the virus such as geographic, climatic, health, economic, and demographic factors.
Rotated Binary Neural Network
Oct 22, 2020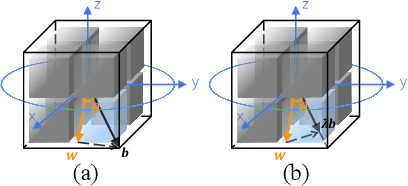
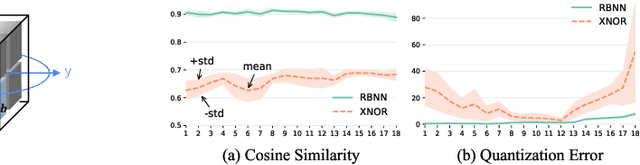
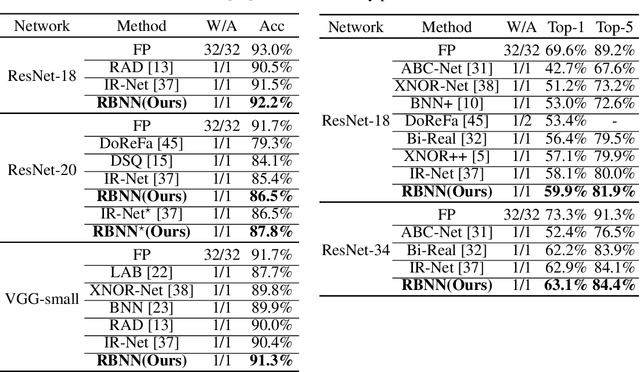
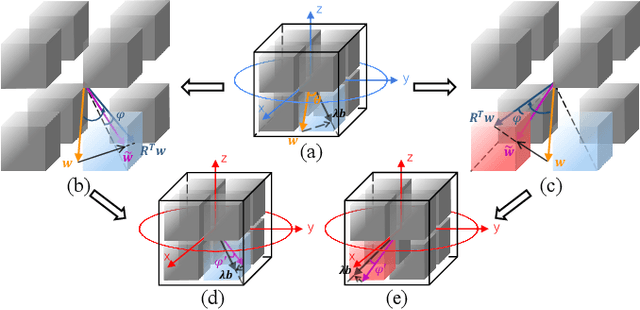
Binary Neural Network (BNN) shows its predominance in reducing the complexity of deep neural networks. However, it suffers severe performance degradation. One of the major impediments is the large quantization error between the full-precision weight vector and its binary vector. Previous works focus on compensating for the norm gap while leaving the angular bias hardly touched. In this paper, for the first time, we explore the influence of angular bias on the quantization error and then introduce a Rotated Binary Neural Network (RBNN), which considers the angle alignment between the full-precision weight vector and its binarized version. At the beginning of each training epoch, we propose to rotate the full-precision weight vector to its binary vector to reduce the angular bias. To avoid the high complexity of learning a large rotation matrix, we further introduce a bi-rotation formulation that learns two smaller rotation matrices. In the training stage, we devise an adjustable rotated weight vector for binarization to escape the potential local optimum. Our rotation leads to around 50% weight flips which maximize the information gain. Finally, we propose a training-aware approximation of the sign function for the gradient backward. Experiments on CIFAR-10 and ImageNet demonstrate the superiorities of RBNN over many state-of-the-arts. Our source code, experimental settings, training logs and binary models are available at https://github.com/lmbxmu/RBNN.
Context-Aware Drive-thru Recommendation Service at Fast Food Restaurants
Oct 13, 2020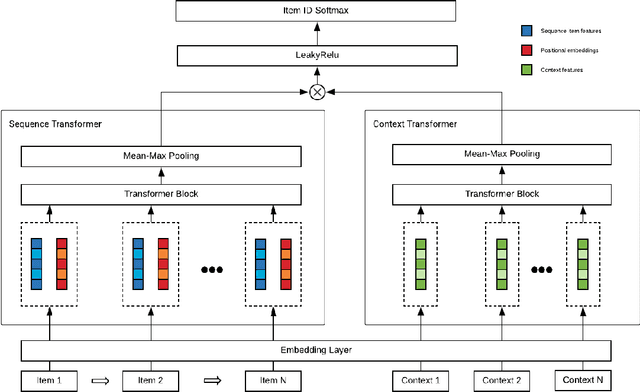

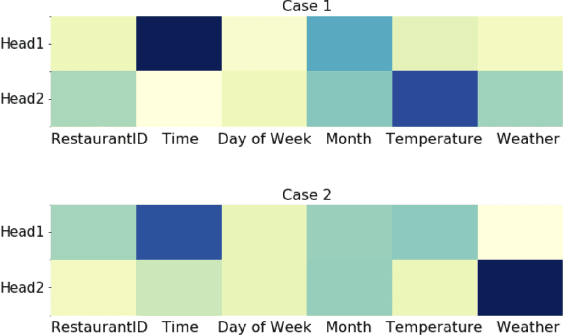
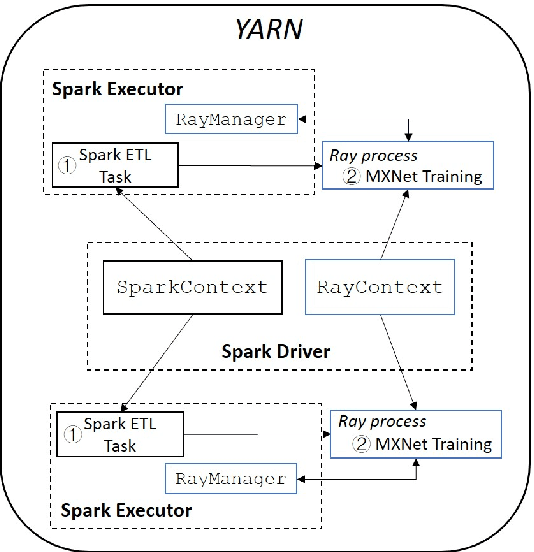
Drive-thru is a popular sales channel in the fast food industry where consumers can make food purchases without leaving their cars. Drive-thru recommendation systems allow restaurants to display food recommendations on the digital menu board as guests are making their orders. Popular recommendation models in eCommerce scenarios rely on user attributes (such as user profiles or purchase history) to generate recommendations, while such information is hard to obtain in the drive-thru use case. Thus, in this paper, we propose a new recommendation model Transformer Cross Transformer (TxT), which exploits the guest order behavior and contextual features (such as location, time, and weather) using Transformer encoders for drive-thru recommendations. Empirical results show that our TxT model achieves superior results in Burger King's drive-thru production environment compared with existing recommendation solutions. In addition, we implement a unified system to run end-to-end big data analytics and deep learning workloads on the same cluster. We find that in practice, maintaining a single big data cluster for the entire pipeline is more efficient and cost-saving. Our recommendation system is not only beneficial for drive-thru scenarios, and it can also be generalized to other customer interaction channels.
Machine learning for recovery factor estimation of an oil reservoir: a tool for de-risking at a hydrocarbon asset evaluation
Oct 22, 2020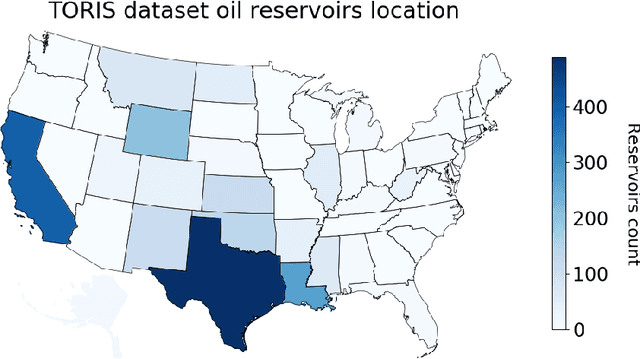
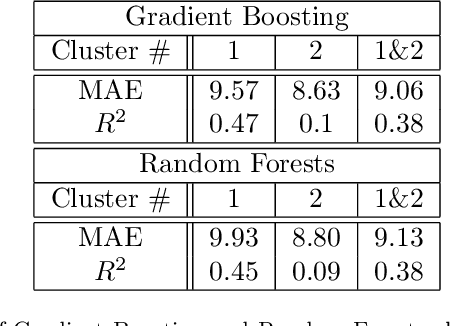
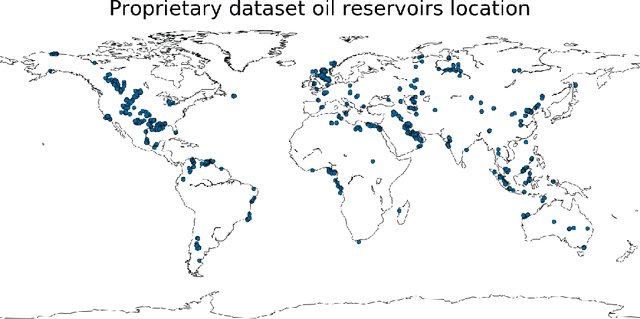
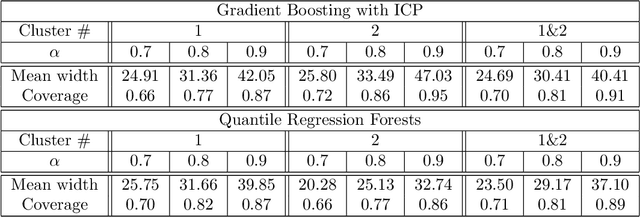
Well known oil recovery factor estimation techniques such as analogy, volumetric calculations, material balance, decline curve analysis, hydrodynamic simulations have certain limitations. Those techniques are time-consuming, require specific data and expert knowledge. Besides, though uncertainty estimation is highly desirable for this problem, the methods above do not include this by default. In this work, we present a data-driven technique for oil recovery factor of hydrocarbon reservoirs using parameters and various representative statistics. We apply advanced machine learning methods using extensive historical worldwide oilfields datasets (more than 2000 oil reservoirs). The data-driven model might be used as a general tool for rapid and completely objective estimation of the oil recovery factor. In addition, it includes the ability to work with partial input data and to estimate the prediction interval of the oil recovery factor. We perform the evaluation in terms of accuracy and prediction intervals coverage for several tree-based machine learning techniques in application to the following two cases: (1) using parameters only related to geometry, geology, transport, storage and fluid properties, (2) using an extended set of parameters including development and production data. For both cases model proved itself to be robust and reliable. We conclude that the proposed data-driven approach overcomes several limitations of the traditional methods and is suitable for rapid, reliable and objective estimation of oil recovery factor for hydrocarbon reservoir.
Heuristic Rank Selection with Progressively Searching Tensor Ring Network
Sep 22, 2020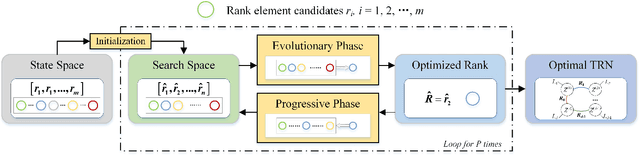
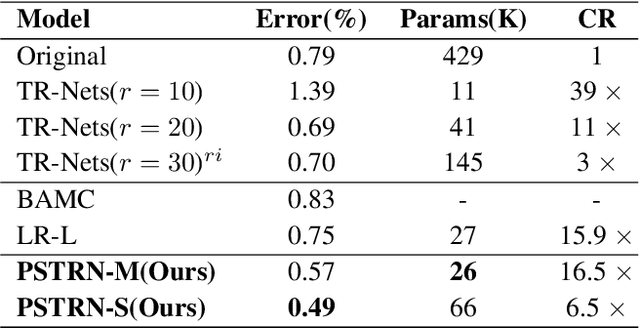
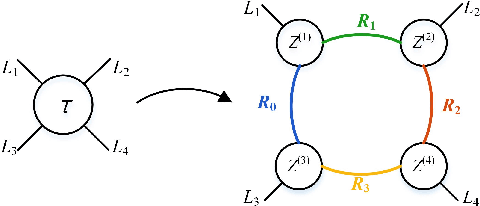
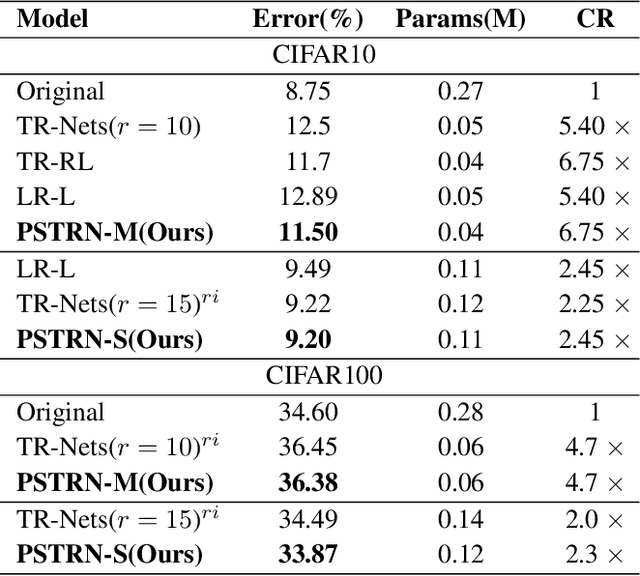
Recently, Tensor Ring Networks (TRNs) have been applied in deep networks, achieving remarkable successes in compression ratio and accuracy. Although highly related to the performance of TRNs, rank is seldom studied in previous works and usually set to equal in experiments. Meanwhile, there is not any heuristic method to choose the rank, and an enumerating way to find appropriate rank is extremely time-consuming. Interestingly, we discover that part of the rank elements is sensitive and usually aggregate in a certain region, namely an interest region. Therefore, based on the above phenomenon, we propose a novel progressive genetic algorithm named Progressively Searching Tensor Ring Network Search (PSTRN), which has the ability to find optimal rank precisely and efficiently. Through the evolutionary phase and progressive phase, PSTRN can converge to the interest region quickly and harvest good performance. Experimental results show that PSTRN can significantly reduce the complexity of seeking rank, compared with the enumerating method. Furthermore, our method is validated on public benchmarks like MNIST, CIFAR10/100 and HMDB51, achieving state-of-the-art performance.