 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Transfer-Learning-Aware Neuro-Evolution for Diseases Detection in Chest X-Ray Images
Apr 15, 2020
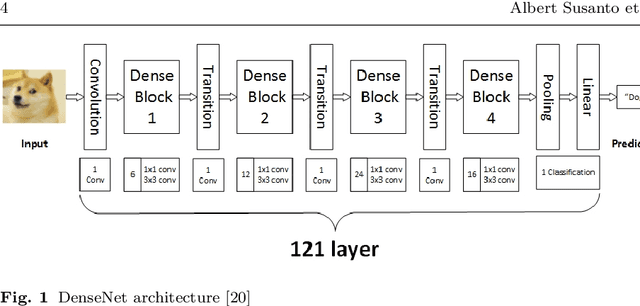
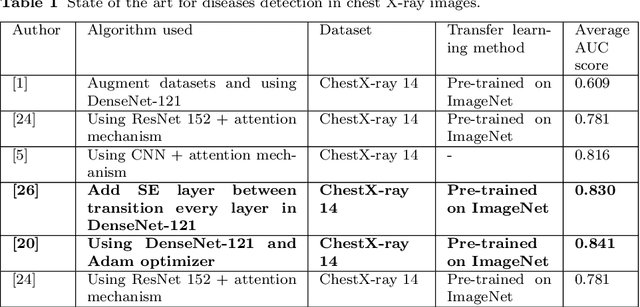
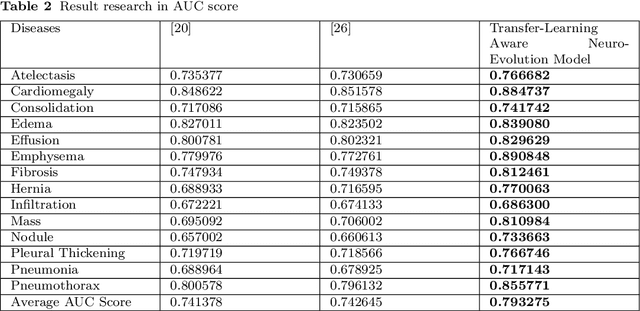
The neural network needs excessive costs of time because of the complexity of architecture when trained on images. Transfer learning and fine-tuning can help improve time and cost efficiency when training a neural network. Yet, Transfer learning and fine-tuning needs a lot of experiment to try with. Therefore, a method to find the best architecture for transfer learning and fine-tuning is needed. To overcome this problem, neuro-evolution using a genetic algorithm can be used to find the best architecture for transfer learning. To check the performance of this study, dataset ChestX-Ray 14 and DenseNet-121 as a base neural network model are used. This study used the AUC score, differences in execution time for training, and McNemar's test to the significance test. In terms of result, this study got a 5% difference in the AUC score, 3 % faster in terms of execution time, and significance in most of the disease detection. Finally, this study gives a concrete summary of how neuro-evolution transfer learning can help in terms of transfer learning and fine-tuning.
RobustPointSet: A Dataset for Benchmarking Robustness of Point Cloud Classifiers
Nov 25, 2020
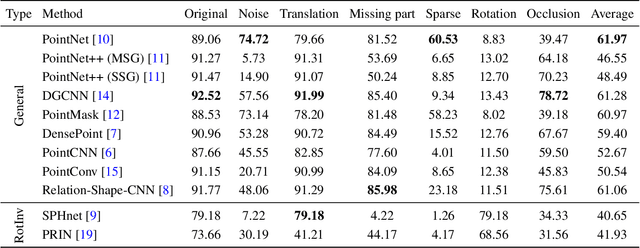

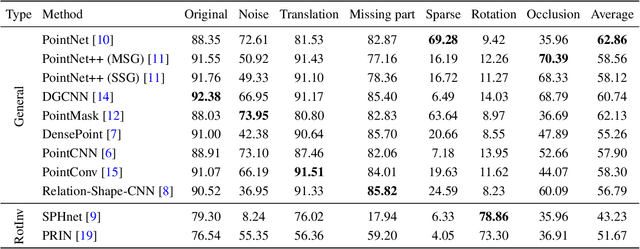
The 3D deep learning community has seen significant strides in pointcloud processing over the last few years. However, the datasets on which deep models have been trained have largely remained the same. Most datasets comprise clean, clutter-free pointclouds canonicalized for pose. Models trained on these datasets fail in uninterpretible and unintuitive ways when presented with data that contains transformations "unseen" at train time. While data augmentation enables models to be robust to "previously seen" input transformations, 1) we show that this does not work for unseen transformations during inference, and 2) data augmentation makes it difficult to analyze a model's inherent robustness to transformations. To this end, we create a publicly available dataset for robustness analysis of point cloud classification models (independent of data augmentation) to input transformations, called RobustPointSet. Our experiments indicate that despite all the progress in the point cloud classification, there is no single architecture that consistently performs better---several fail drastically---when evaluated on transformed test sets. We also find that robustness to unseen transformations cannot be brought about merely by extensive data augmentation. RobustPointSet can be accessed through https://github.com/AutodeskAILab/RobustPointSet.
Few-shot model-based adaptation in noisy conditions
Oct 16, 2020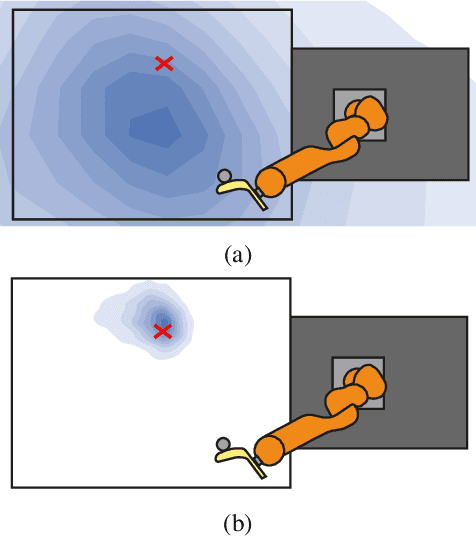
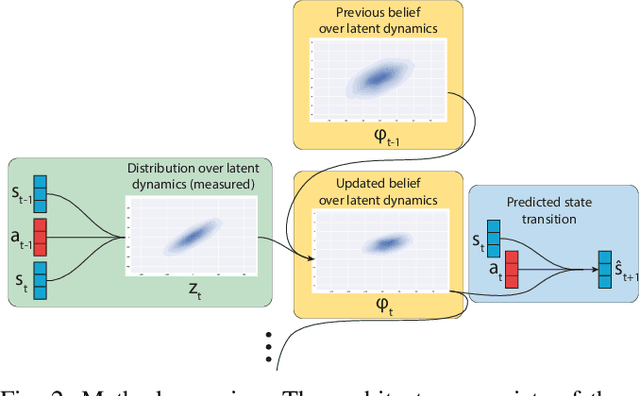
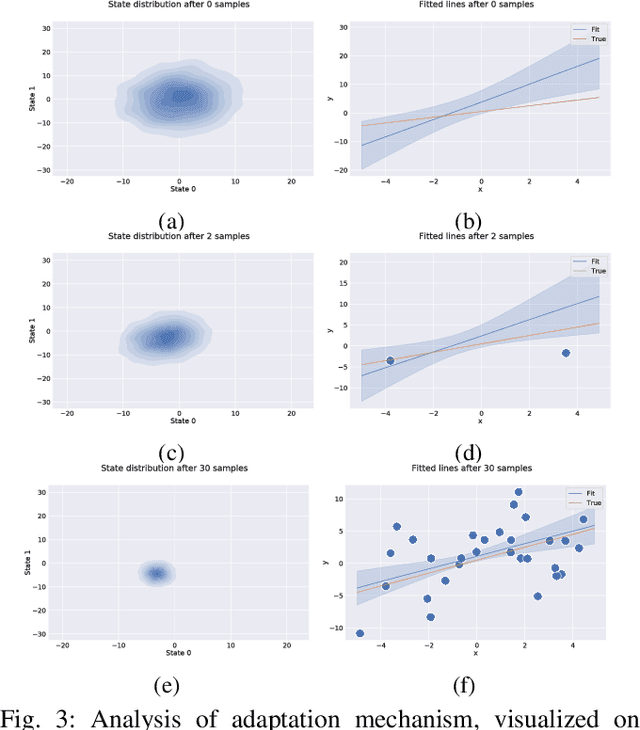

Few-shot adaptation is a challenging problem in the context of simulation-to-real transfer in robotics, requiring safe and informative data collection. In physical systems, additional challenge may be posed by domain noise, which is present in virtually all real-world applications. In this paper, we propose to perform few-shot adaptation of dynamics models in noisy conditions using an uncertainty-aware Kalman filter-based neural network architecture. We show that the proposed method, which explicitly addresses domain noise, improves few-shot adaptation error over a blackbox adaptation LSTM baseline, and over a model-free on-policy reinforcement learning approach, which tries to learn an adaptable and informative policy at the same time. The proposed method also allows for system analysis by analyzing hidden states of the model during and after adaptation.
A metric on directed graphs and Markov chains based on hitting probabilities
Jun 25, 2020
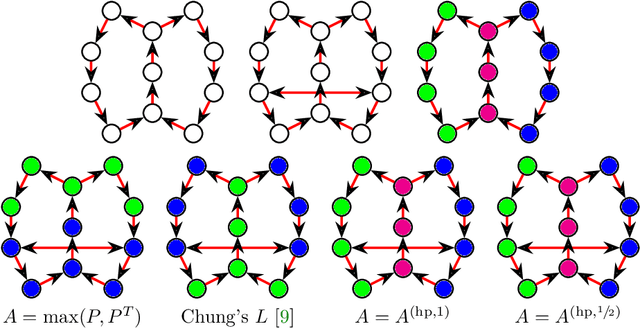
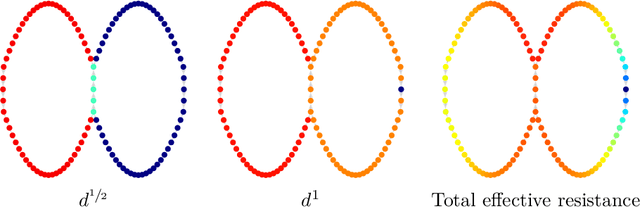

The shortest-path, commute time, and diffusion distances on undirected graphs have been widely employed in applications such as dimensionality reduction, link prediction, and trip planning. Increasingly, there is interest in using asymmetric structure of data derived from Markov chains and directed graphs, but few metrics are specifically adapted to this task. We introduce a metric on the state space of any ergodic, finite-state, time-homogeneous Markov chain and, in particular, on any Markov chain derived from a directed graph. Our construction is based on hitting probabilities, with nearness in the metric space related to the transfer of random walkers from one node to another at stationarity. Notably, our metric is insensitive to shortest and average path distances, thus giving new information compared to existing metrics. We use possible degeneracies in the metric to develop an interesting structural theory of directed graphs and explore a related quotienting procedure. Our metric can be computed in $O(n^3)$ time, where $n$ is the number of states, and in examples we scale up to $n=10,000$ nodes and $\approx 38M$ edges on a desktop computer. In several examples, we explore the nature of the metric, compare it to alternative methods, and demonstrate its utility for weak recovery of community structure in dense graphs, visualization, structure recovering, dynamics exploration, and multiscale cluster detection.
Audio-Visual Event Recognition through the lens of Adversary
Nov 15, 2020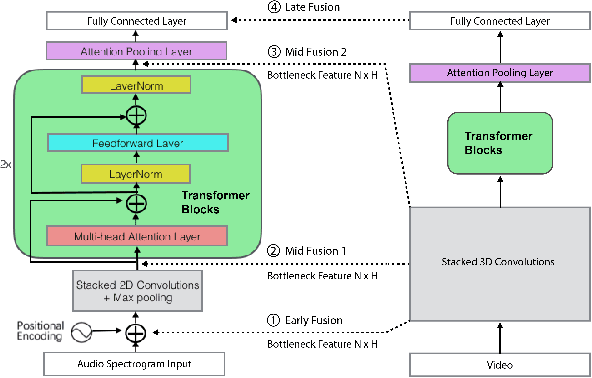
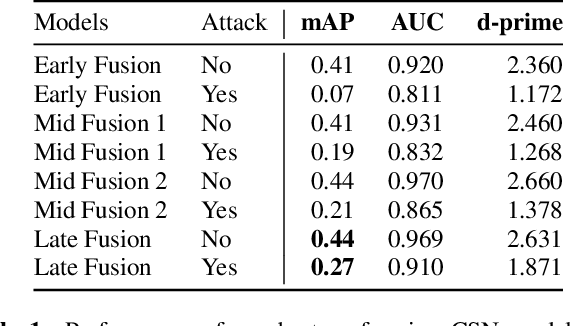
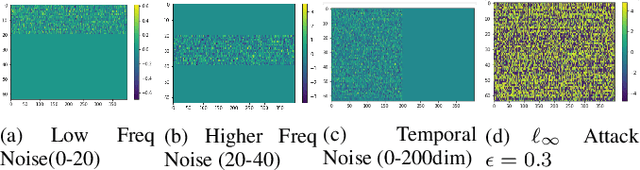
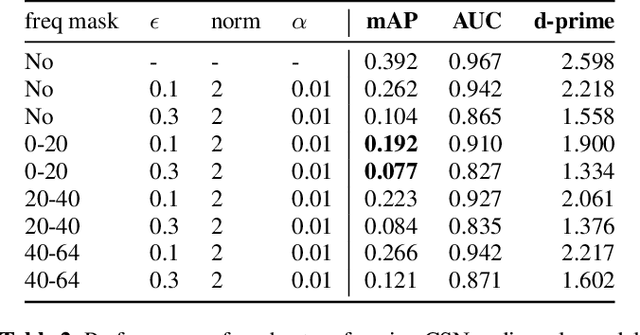
As audio/visual classification models are widely deployed for sensitive tasks like content filtering at scale, it is critical to understand their robustness along with improving the accuracy. This work aims to study several key questions related to multimodal learning through the lens of adversarial noises: 1) The trade-off between early/middle/late fusion affecting its robustness and accuracy 2) How do different frequency/time domain features contribute to the robustness? 3) How do different neural modules contribute to the adversarial noise? In our experiment, we construct adversarial examples to attack state-of-the-art neural models trained on Google AudioSet. We compare how much attack potency in terms of adversarial perturbation of size $\epsilon$ using different $L_p$ norms we would need to "deactivate" the victim model. Using adversarial noise to ablate multimodal models, we are able to provide insights into what is the best potential fusion strategy to balance the model parameters/accuracy and robustness trade-off and distinguish the robust features versus the non-robust features that various neural networks model tend to learn.
Spatio-temporal Sequence Prediction with Point Processes and Self-organizing Decision Trees
Jun 25, 2020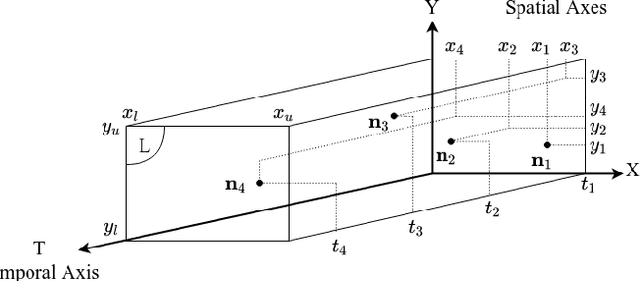
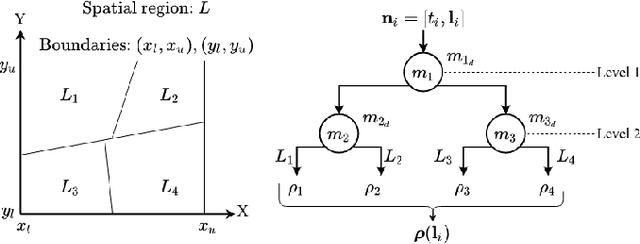
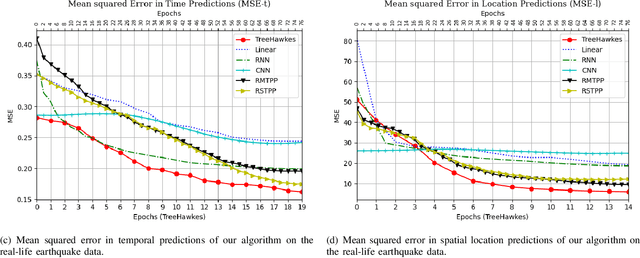
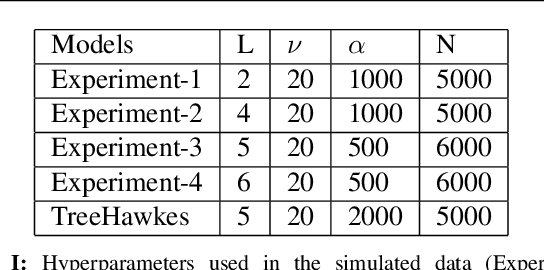
We investigate spatio-temporal prediction and introduce a novel prediction algorithm. Our approach is based on the point processes, which we use to model the event arrivals in both space and time. Although we specifically use the Hawkes process, other processes can be readily used as provided remarks in the paper. Moreover, we partition the given spatial region into subregions by an adaptive decision tree and model each subregion with individual and interacting point processes. With individual point processes for each subregion, we estimate the time and location of the events using the past event times and locations. Furthermore, thanks to the nonstationary and self-exciting point generation mechanism in the Hawkes process and the adaptive partitioning of the space, we model the data as nonstationary in both time and space. Finally, we provide a gradient based joint optimization algorithm for the adaptive tree parameter and the point process parameters. With the joint optimization, our algorithm can infer the source statistics and adaptive partitioning of the region. We also provide a training algorithm for the online setup, where we update the model parameters with newly arrived points. We provide experimental results on both simulated data and real-life data where we compare our approach with the standard approaches and demonstrate significant performance improvements thanks to the adaptive spatial partitioning mechanism and the joint optimization procedure.
Single Shot Reversible GAN for BCG artifact removal in simultaneous EEG-fMRI
Nov 04, 2020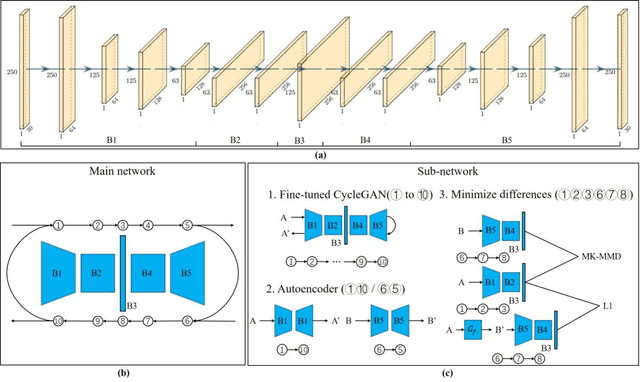
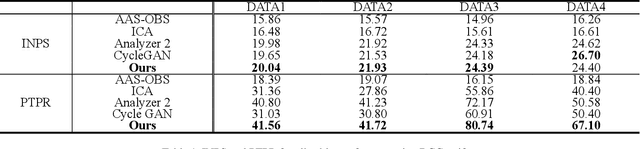
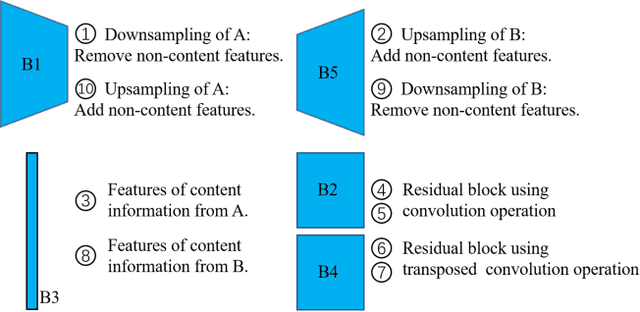
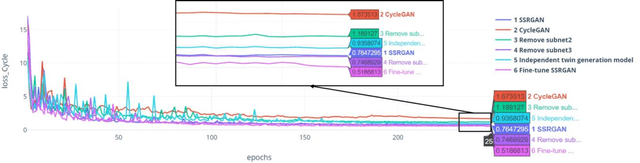
Simultaneous EEG-fMRI acquisition and analysis technology has been widely used in various research fields of brain science. However, how to remove the ballistocardiogram (BCG) artifacts in this scenario remains a huge challenge. Because it is impossible to obtain clean and BCG-contaminated EEG signals at the same time, BCG artifact removal is a typical unpaired signal-to-signal problem. To solve this problem, this paper proposed a new GAN training model - Single Shot Reversible GAN (SSRGAN). The model is allowing bidirectional input to better combine the characteristics of the two types of signals, instead of using two independent models for bidirectional conversion as in the past. Furthermore, the model is decomposed into multiple independent convolutional blocks with specific functions. Through additional training of the blocks, the local representation ability of the model is improved, thereby improving the overall model performance. Experimental results show that, compared with existing methods, the method proposed in this paper can remove BCG artifacts more effectively and retain the useful EEG information.
Incremental Training of Graph Neural Networks on Temporal Graphs under Distribution Shift
Jun 25, 2020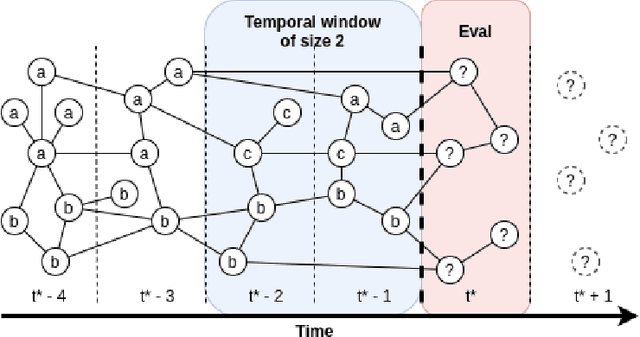

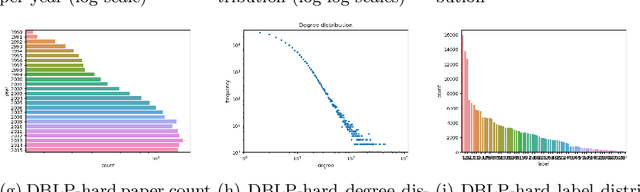
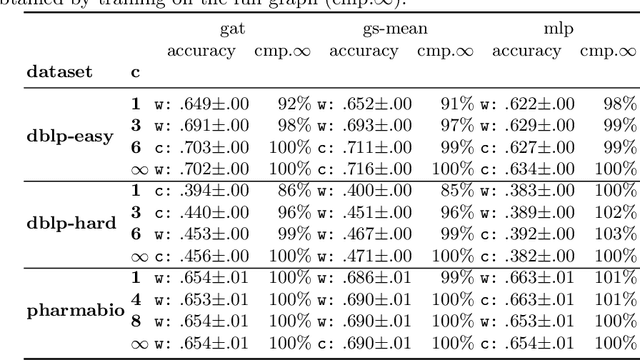
Current graph neural networks (GNNs) are promising, especially when the entire graph is known for training. However, it is not yet clear how to efficiently train GNNs on temporal graphs, where new vertices, edges, and even classes appear over time. We face two challenges: First, shifts in the label distribution (including the appearance of new labels), which require adapting the model. Second, the growth of the graph, which makes it, at some point, infeasible to train over all vertices and edges. We address these issues by applying a sliding window technique, i.e., we incrementally train GNNs on limited window sizes and analyze their performance. For our experiments, we have compiled three new temporal graph datasets based on scientific publications and evaluate isotropic and anisotropic GNN architectures. Our results show that both GNN types provide good results even for a window size of just 1 time step. With window sizes of 3 to 4 time steps, GNNs achieve at least 95% accuracy compared to using the entire timeline of the graph. With window sizes of 6 or 8, at least 99% accuracy could be retained. These discoveries have direct consequences for training GNNs over temporal graphs. We provide the code (https://github.com/Incremental-GNNs) and the newly compiled datasets (https://zenodo.org/record/3764770) for reproducibility and reuse.
Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
Nov 25, 2020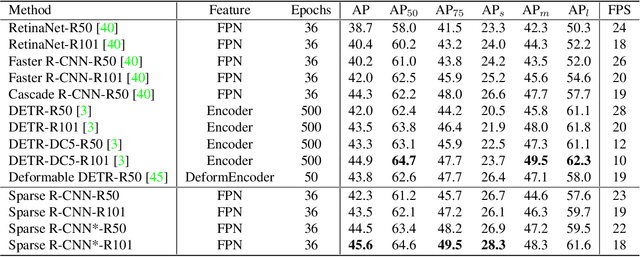
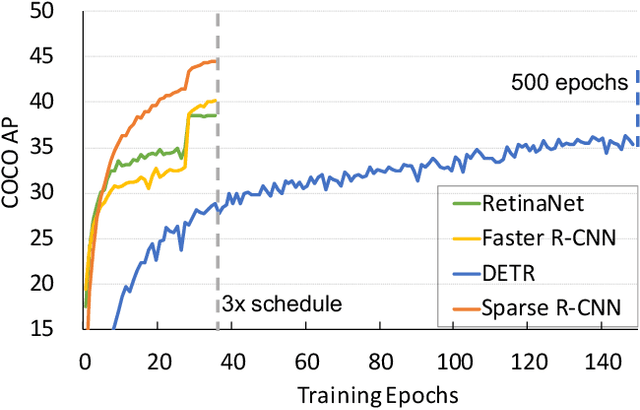

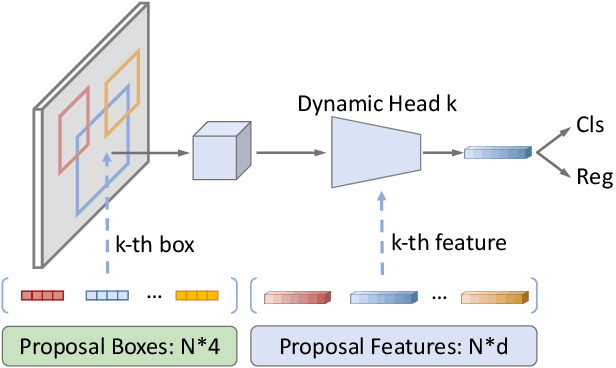
We present Sparse R-CNN, a purely sparse method for object detection in images. Existing works on object detection heavily rely on dense object candidates, such as $k$ anchor boxes pre-defined on all grids of image feature map of size $H\times W$. In our method, however, a fixed sparse set of learned object proposals, total length of $N$, are provided to object recognition head to perform classification and location. By eliminating $HWk$ (up to hundreds of thousands) hand-designed object candidates to $N$ (e.g. 100) learnable proposals, Sparse R-CNN completely avoids all efforts related to object candidates design and many-to-one label assignment. More importantly, final predictions are directly output without non-maximum suppression post-procedure. Sparse R-CNN demonstrates accuracy, run-time and training convergence performance on par with the well-established detector baselines on the challenging COCO dataset, e.g., achieving 44.5 AP in standard $3\times$ training schedule and running at 22 fps using ResNet-50 FPN model. We hope our work could inspire re-thinking the convention of dense prior in object detectors. The code is available at: https://github.com/PeizeSun/SparseR-CNN.
RotNet: Fast and Scalable Estimation of Stellar Rotation Periods Using Convolutional Neural Networks
Dec 04, 2020
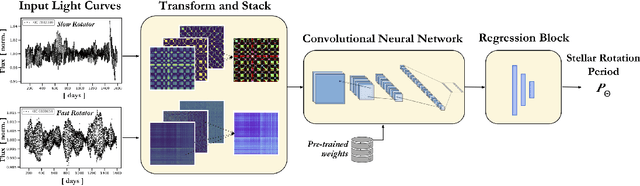
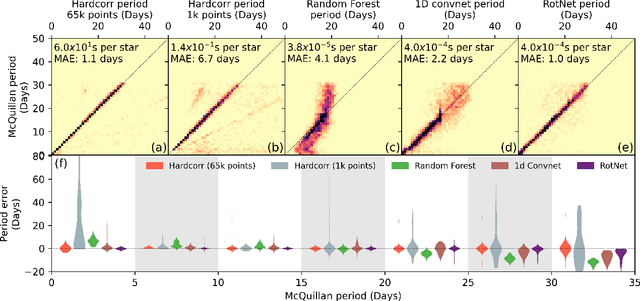
Magnetic activity in stars manifests as dark spots on their surfaces that modulate the brightness observed by telescopes. These light curves contain important information on stellar rotation. However, the accurate estimation of rotation periods is computationally expensive due to scarce ground truth information, noisy data, and large parameter spaces that lead to degenerate solutions. We harness the power of deep learning and successfully apply Convolutional Neural Networks to regress stellar rotation periods from Kepler light curves. Geometry-preserving time-series to image transformations of the light curves serve as inputs to a ResNet-18 based architecture which is trained through transfer learning. The McQuillan catalog of published rotation periods is used as ansatz to groundtruth. We benchmark the performance of our method against a random forest regressor, a 1D CNN, and the Auto-Correlation Function (ACF) - the current standard to estimate rotation periods. Despite limiting our input to fewer data points (1k), our model yields more accurate results and runs 350 times faster than ACF runs on the same number of data points and 10,000 times faster than ACF runs on 65k data points. With only minimal feature engineering our approach has impressive accuracy, motivating the application of deep learning to regress stellar parameters on an even larger scale