 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analyzing COVID-19 on Online Social Media: Trends, Sentiments and Emotions
Jun 02, 2020
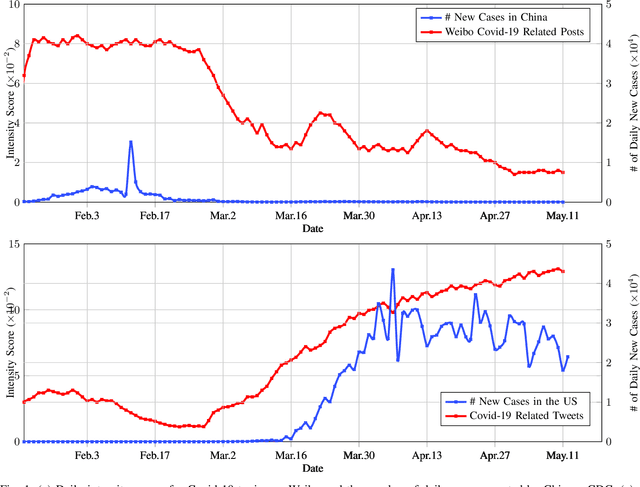
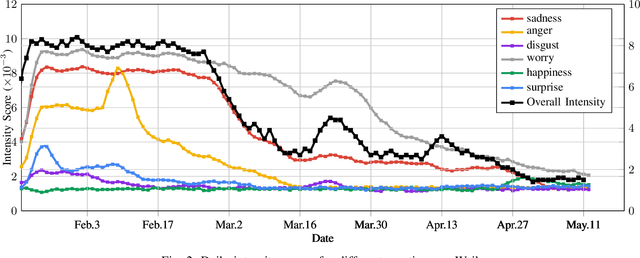
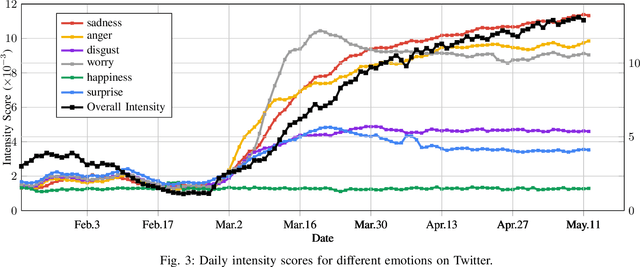
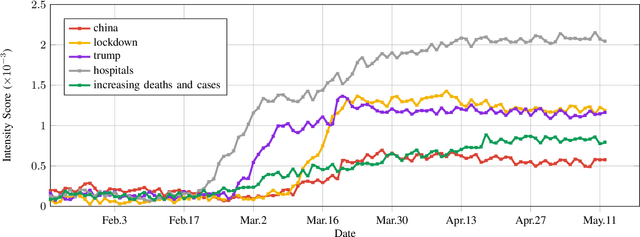
At the time of writing, the ongoing pandemic of coronavirus disease (COVID-19) has caused severe impacts on society, economy and people's daily lives. People constantly express their opinions on various aspects of the pandemic on social media, making user-generated content an important source for understanding public emotions and concerns. In this paper, we perform a comprehensive analysis on the affective trajectories of the American people and the Chinese people based on Twitter and Weibo posts between January 20th, 2020 and May 11th 2020. Specifically, by identifying people's sentiments, emotions (i.e., anger, disgust, fear, happiness, sadness, surprise) and the emotional triggers (e.g., what a user is angry/sad about) we are able to depict the dynamics of public affect in the time of COVID-19. By contrasting two very different countries, China and the Unites States, we reveal sharp differences in people's views on COVID-19 in different cultures. Our study provides a computational approach to unveiling public emotions and concerns on the pandemic in real-time, which would potentially help policy-makers better understand people's need and thus make optimal policy.
A reinforcement learning approach to rare trajectory sampling
May 27, 2020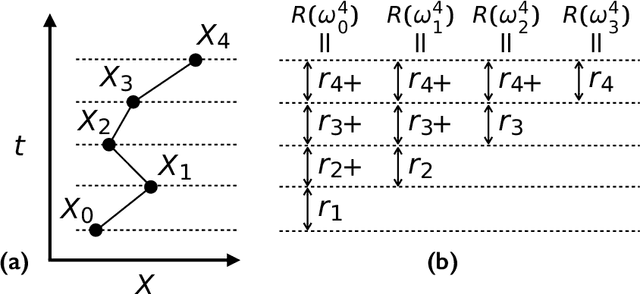

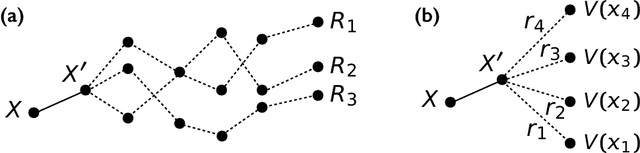
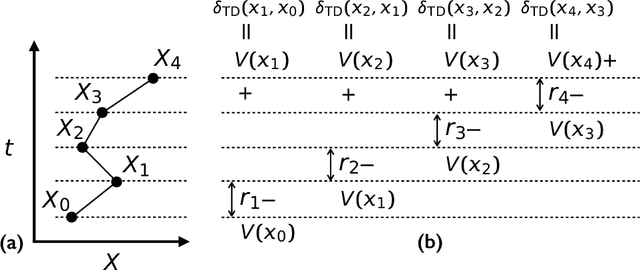
Very often when studying non-equilibrium systems one is interested in analysing dynamical behaviour that occurs with very low probability, so called rare events. In practice, since rare events are by definition atypical, they are often difficult to access in a statistically significant way. What are required are strategies to "make rare events typical" so that they can be generated on demand. Here we present such a general approach to adaptively construct a dynamics that efficiently samples atypical events. We do so by exploiting the methods of reinforcement learning (RL), which refers to the set of machine learning techniques aimed at finding the optimal behaviour to maximise a reward associated with the dynamics. We consider the general perspective of dynamical trajectory ensembles, whereby rare events are described in terms of ensemble reweighting. By minimising the distance between a reweighted ensemble and that of a suitably parametrised controlled dynamics we arrive at a set of methods similar to those of RL to numerically approximate the optimal dynamics that realises the rare behaviour of interest. As simple illustrations we consider in detail the problem of excursions of a random walker, for the case of rare events with a finite time horizon; and the problem of a studying current statistics of a particle hopping in a ring geometry, for the case of an infinite time horizon. We discuss natural extensions of the ideas presented here, including to continuous-time Markov systems, first passage time problems and non-Markovian dynamics.
Efficient Balanced Treatment Assignments for Experimentation
Oct 21, 2020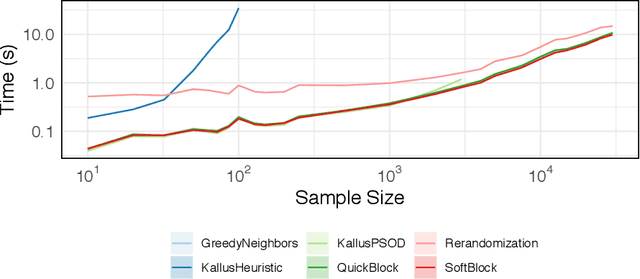
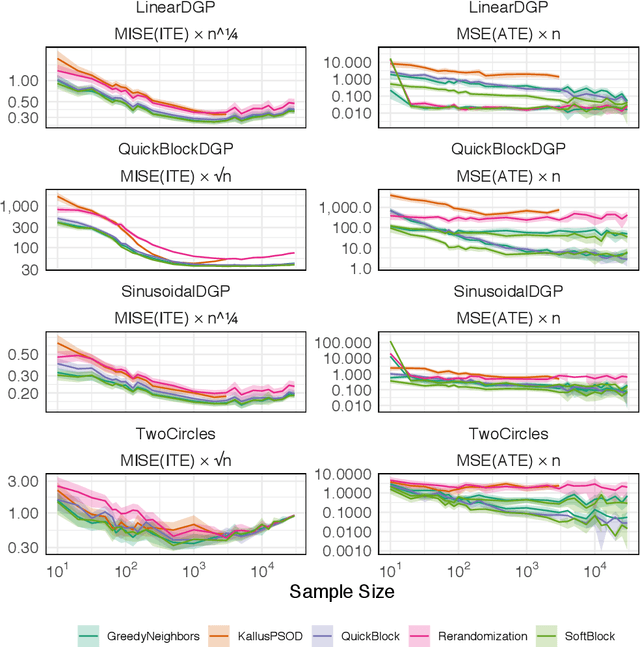
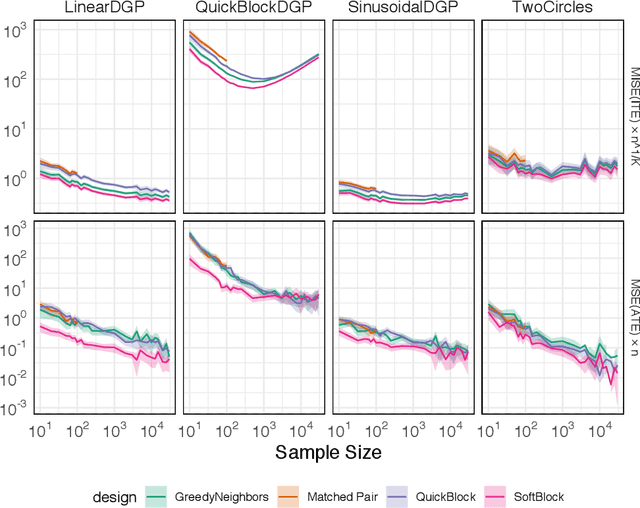
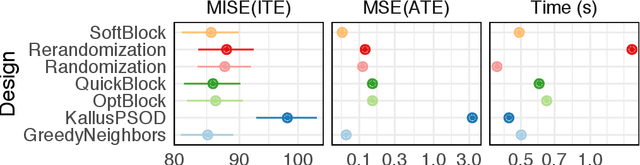
In this work, we reframe the problem of balanced treatment assignment as optimization of a two-sample test between test and control units. Using this lens we provide an assignment algorithm that is optimal with respect to the minimum spanning tree test of Friedman and Rafsky (1979). This assignment to treatment groups may be performed exactly in polynomial time. We provide a probabilistic interpretation of this process in terms of the most probable element of designs drawn from a determinantal point process which admits a probabilistic interpretation of the design. We provide a novel formulation of estimation as transductive inference and show how the tree structures used in design can also be used in an adjustment estimator. We conclude with a simulation study demonstrating the improved efficacy of our method.
A Supervised Learning Methodology for Real-Time Disguised Face Recognition in the Wild
Sep 08, 2018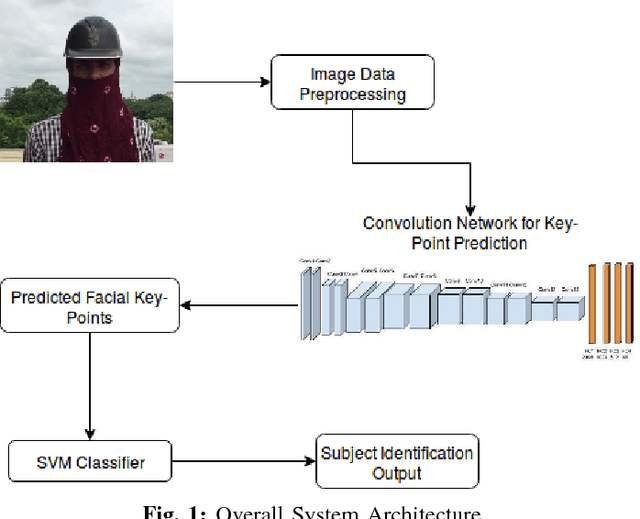



Facial recognition has always been a challeng- ing task for computer vision scientists and experts. Despite complexities arising due to variations in camera parameters, illumination and face orientations, significant progress has been made in the field with deep learning algorithms now competing with human-level accuracy. But in contrast to the recent advances in face recognition techniques, Disguised Facial Identification continues to be a tougher challenge in the field of computer vision. The modern day scenario, where security is of prime concern, regular face identification techniques do not perform as required when the faces are disguised, which calls for a different approach to handle situations where intruders have their faces masked. Along the same lines, we propose a deep learning architecture for disguised facial recognition (DFR). The algorithm put forward in this paper detects 20 facial key-points in the first stage, using a 14-layered convolutional neural network (CNN). These facial key-points are later utilized by a support vector machine (SVM) for classifying the disguised faces based on the euclidean distance ratios and angles between different facial key-points. This overall architecture imparts a basic intelligence to our system. Our key-point feature prediction accuracy is 65% while the classification rate is 72.4%. Moreover, the architecture works at 19 FPS, thereby performing in almost real-time. The efficiency of our approach is also compared with the state-of-the-art Disguised Facial Identification methods.
GPU Accelerated Convex Approximations for Fast Multi-Agent Trajectory Optimization
Nov 09, 2020
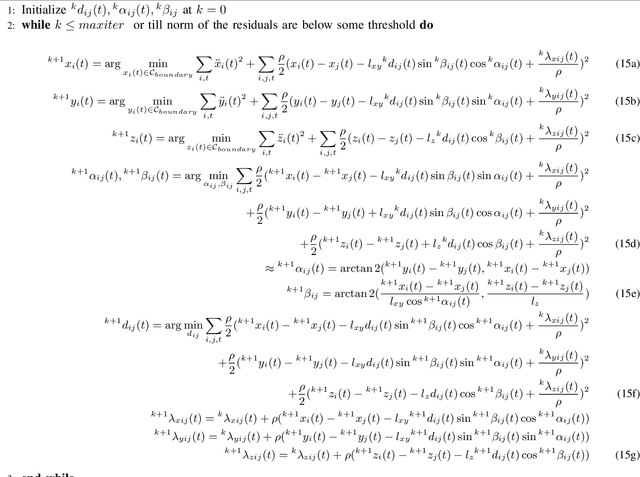
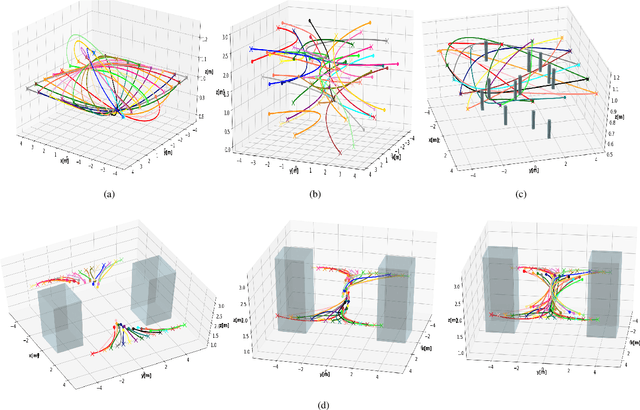
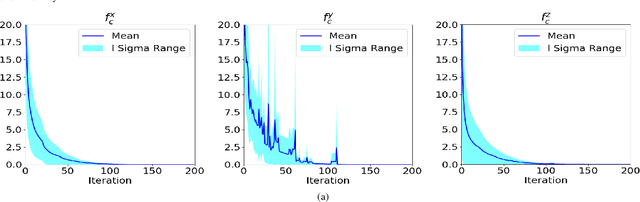
In this paper, we present a computationally efficient trajectory optimizer that can exploit GPUs to jointly compute trajectories of tens of agents in under a second. At the heart of our optimizer is a novel reformulation of the non-convex collision avoidance constraints that reduces the core computation in each iteration to that of solving a large scale, convex, unconstrained Quadratic Program (QP). We also show that the matrix factorization/inverse computation associated with the QP needs to be done only once and can be done offline for a given number of agents. This further simplifies the solution process, effectively reducing it to a problem of evaluating a few matrix-vector products. Moreover, for a large number of agents, this computation can be trivially accelerated on GPUs using existing off-the-shelf libraries. We validate our optimizer's performance on challenging benchmarks and show substantial improvement over state of the art in computation time and trajectory quality.
Invisible Perturbations: Physical Adversarial Examples Exploiting the Rolling Shutter Effect
Nov 30, 2020
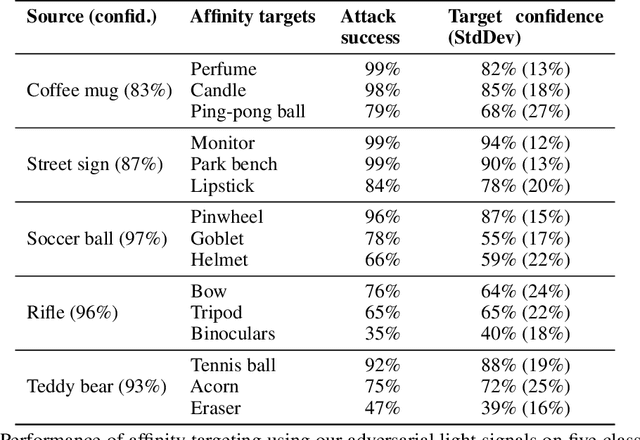
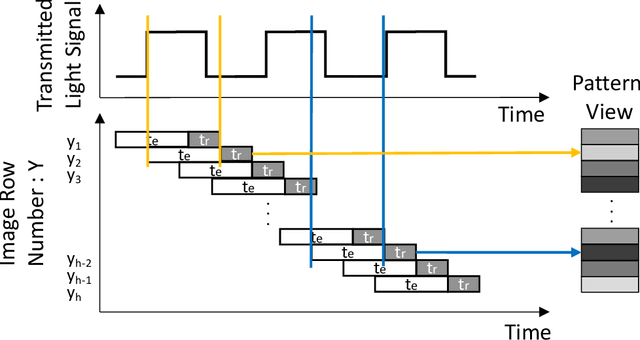
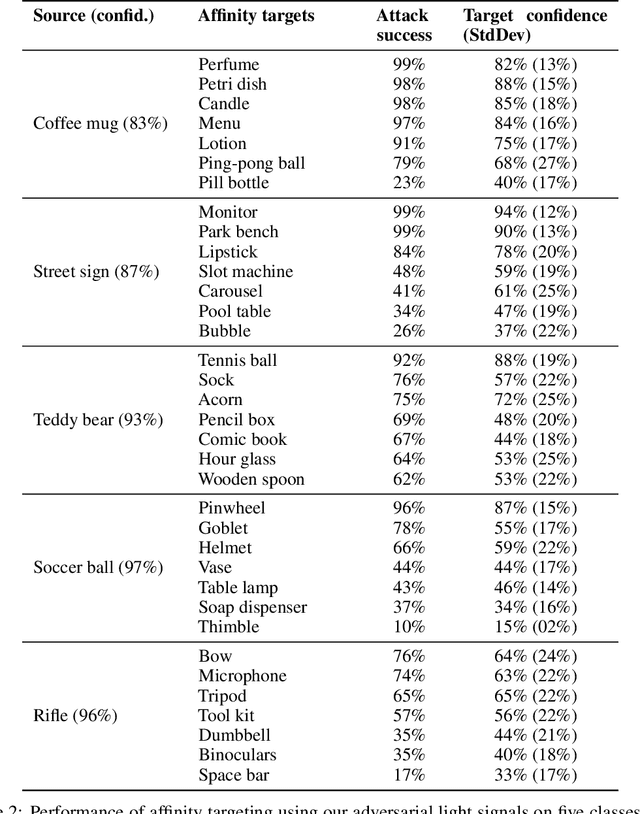
Physical adversarial examples for camera-based computer vision have so far been achieved through visible artifacts -- a sticker on a Stop sign, colorful borders around eyeglasses or a 3D printed object with a colorful texture. An implicit assumption here is that the perturbations must be visible so that a camera can sense them. By contrast, we contribute a procedure to generate, for the first time, physical adversarial examples that are invisible to human eyes. Rather than modifying the victim object with visible artifacts, we modify light that illuminates the object. We demonstrate how an attacker can craft a modulated light signal that adversarially illuminates a scene and causes targeted misclassifications on a state-of-the-art ImageNet deep learning model. Concretely, we exploit the radiometric rolling shutter effect in commodity cameras to create precise striping patterns that appear on images. To human eyes, it appears like the object is illuminated, but the camera creates an image with stripes that will cause ML models to output the attacker-desired classification. We conduct a range of simulation and physical experiments with LEDs, demonstrating targeted attack rates up to 84%.
Real-time 3D Tracking of Articulated Tools for Robotic Surgery
Oct 30, 2016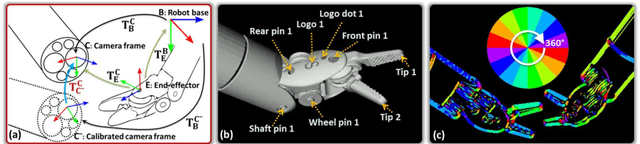
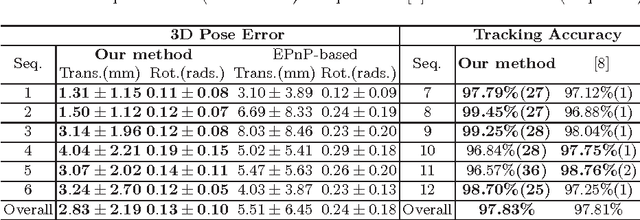
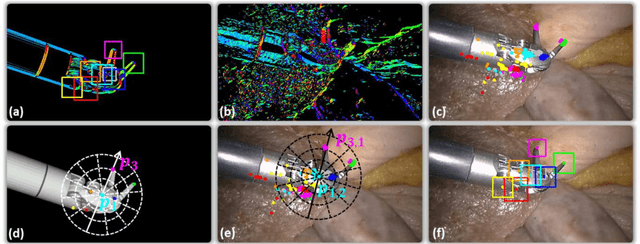
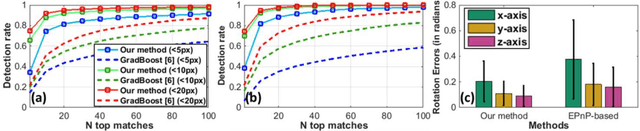
In robotic surgery, tool tracking is important for providing safe tool-tissue interaction and facilitating surgical skills assessment. Despite recent advances in tool tracking, existing approaches are faced with major difficulties in real-time tracking of articulated tools. Most algorithms are tailored for offline processing with pre-recorded videos. In this paper, we propose a real-time 3D tracking method for articulated tools in robotic surgery. The proposed method is based on the CAD model of the tools as well as robot kinematics to generate online part-based templates for efficient 2D matching and 3D pose estimation. A robust verification approach is incorporated to reject outliers in 2D detections, which is then followed by fusing inliers with robot kinematic readings for 3D pose estimation of the tool. The proposed method has been validated with phantom data, as well as ex vivo and in vivo experiments. The results derived clearly demonstrate the performance advantage of the proposed method when compared to the state-of-the-art.
ORBIT: Ordering Based Information Transfer Across Space and Time for Global Surface Water Monitoring
Nov 15, 2017
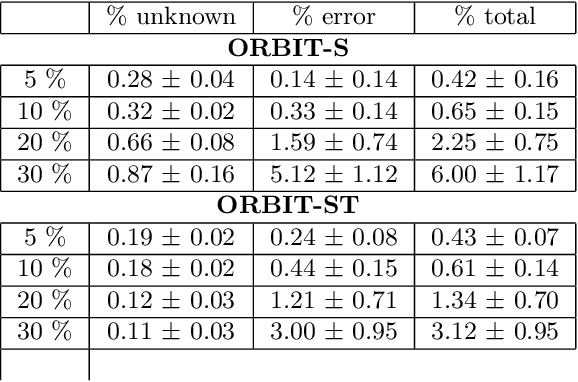
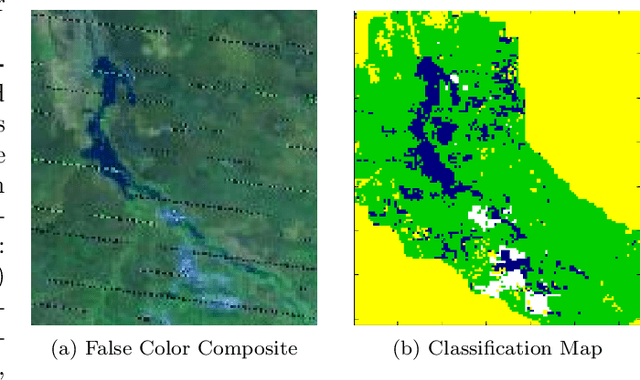
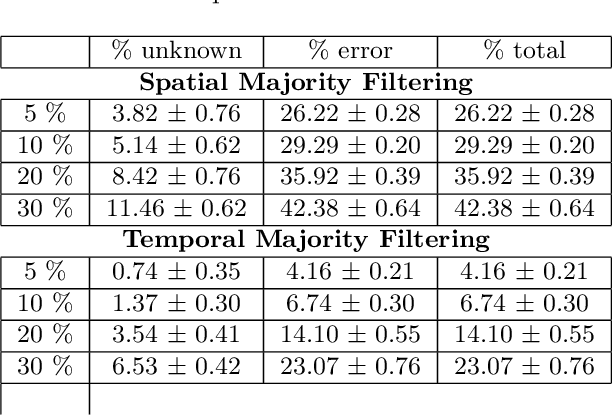
Many earth science applications require data at both high spatial and temporal resolution for effective monitoring of various ecosystem resources. Due to practical limitations in sensor design, there is often a trade-off in different resolutions of spatio-temporal datasets and hence a single sensor alone cannot provide the required information. Various data fusion methods have been proposed in the literature that mainly rely on individual timesteps when both datasets are available to learn a mapping between features values at different resolutions using local relationships between pixels. Earth observation data is often plagued with spatially and temporally correlated noise, outliers and missing data due to atmospheric disturbances which pose a challenge in learning the mapping from a local neighborhood at individual timesteps. In this paper, we aim to exploit time-independent global relationships between pixels for robust transfer of information across different scales. Specifically, we propose a new framework, ORBIT (Ordering Based Information Transfer) that uses relative ordering constraint among pixels to transfer information across both time and scales. The effectiveness of the framework is demonstrated for global surface water monitoring using both synthetic and real-world datasets.
StyleMelGAN: An Efficient High-Fidelity Adversarial Vocoder with Temporal Adaptive Normalization
Nov 03, 2020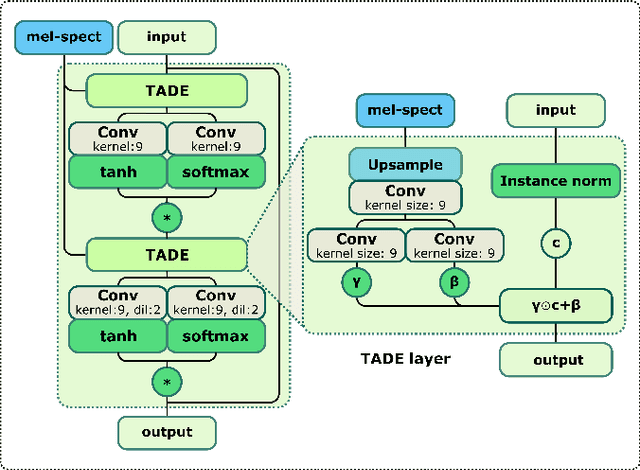
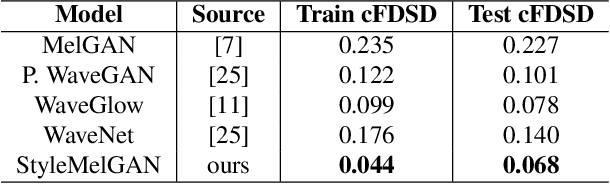
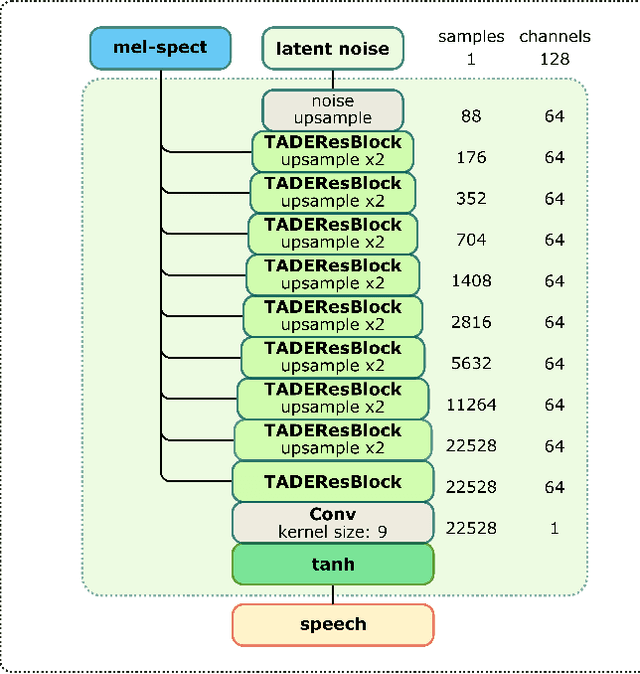

In recent years, neural vocoders have surpassed classical speech generation approaches in naturalness and perceptual quality of the synthesized speech. Computationally heavy models like WaveNet and WaveGlow achieve best results, while lightweight GAN models, e.g. MelGAN and Parallel WaveGAN, remain inferior in terms of perceptual quality. We therefore propose StyleMelGAN, a lightweight neural vocoder allowing synthesis of high-fidelity speech with low computational complexity. StyleMelGAN employs temporal adaptive normalization to style a low-dimensional noise vector with the acoustic features of the target speech. For efficient training, multiple random-window discriminators adversarially evaluate the speech signal analyzed by a filter bank, with regularization provided by a multi-scale spectral reconstruction loss. The highly parallelizable speech generation is several times faster than real-time on CPUs and GPUs. MUSHRA and P.800 listening tests show that StyleMelGAN outperforms prior neural vocoders in copy-synthesis and Text-to-Speech scenarios.
Learned Block-based Hybrid Image Compression
Dec 17, 2020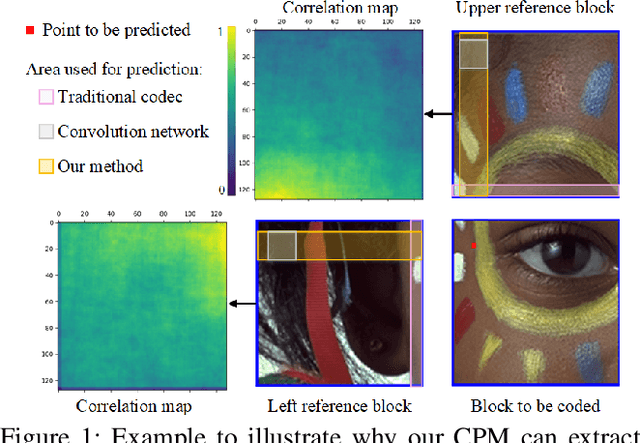
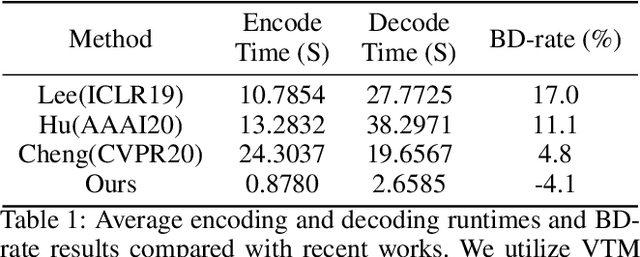
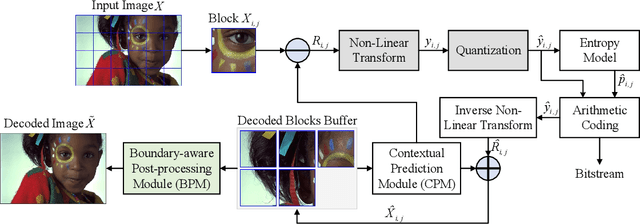
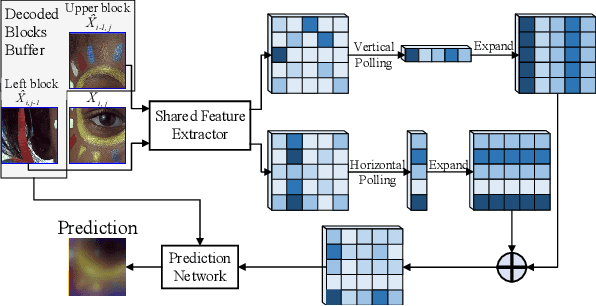
Learned image compression based on neural networks have made huge progress thanks to its superiority in learning better representation through non-linear transformation. Different from traditional hybrid coding frameworks, that are commonly block-based, existing learned image codecs usually process the images in a full-resolution manner thus not supporting acceleration via parallelism and explicit prediction. Compared to learned image codecs, traditional hybrid coding frameworks are in general hand-crafted and lack the adaptability of being optimized according to heterogeneous metrics. Therefore, in order to collect their good qualities and offset their weakness, we explore a learned block-based hybrid image compression (LBHIC) framework, which achieves a win-win between coding performance and efficiency. Specifically, we introduce block partition and explicit learned predictive coding into learned image compression framework. Compared to prediction through linear weighting of neighbor pixels in traditional codecs, our contextual prediction module (CPM) is designed to better capture long-range correlations by utilizing the strip pooling to extract the most relevant information in neighboring latent space. Moreover, to alleviate blocking artifacts, we further propose a boundary-aware post-processing module (BPM) with the importance of edge taken into account. Extensive experiments demonstrate that the proposed LBHIC codec outperforms state-of-the-art image compression methods in terms of both PSNR and MS-SSIM metrics and promises obvious time-saving.