 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleMelGAN: An Efficient High-Fidelity Adversarial Vocoder with Temporal Adaptive Normalization
Paper and Code
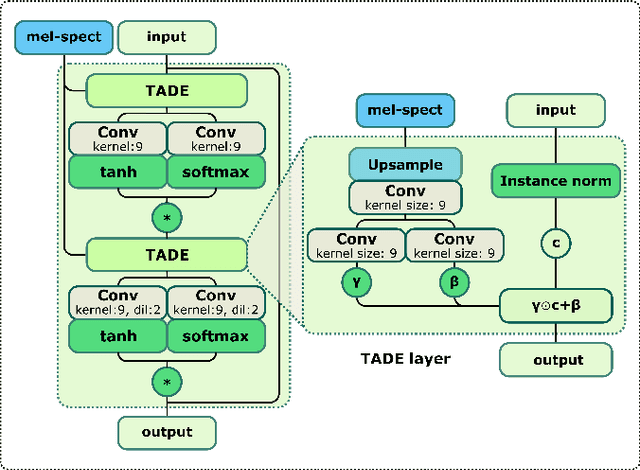
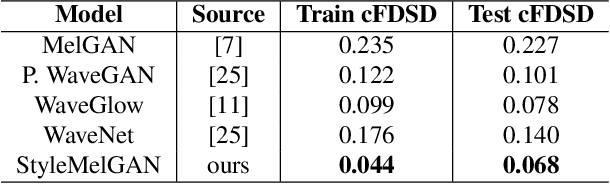
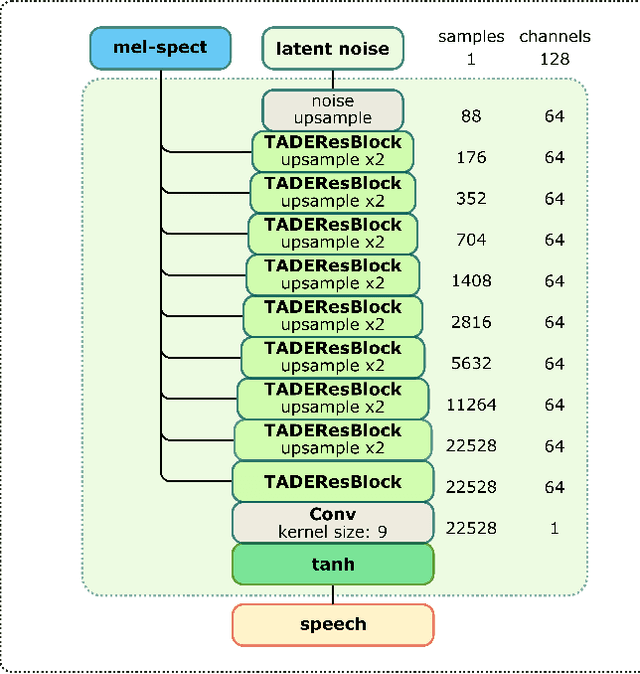

In recent years, neural vocoders have surpassed classical speech generation approaches in naturalness and perceptual quality of the synthesized speech. Computationally heavy models like WaveNet and WaveGlow achieve best results, while lightweight GAN models, e.g. MelGAN and Parallel WaveGAN, remain inferior in terms of perceptual quality. We therefore propose StyleMelGAN, a lightweight neural vocoder allowing synthesis of high-fidelity speech with low computational complexity. StyleMelGAN employs temporal adaptive normalization to style a low-dimensional noise vector with the acoustic features of the target speech. For efficient training, multiple random-window discriminators adversarially evaluate the speech signal analyzed by a filter bank, with regularization provided by a multi-scale spectral reconstruction loss. The highly parallelizable speech generation is several times faster than real-time on CPUs and GPUs. MUSHRA and P.800 listening tests show that StyleMelGAN outperforms prior neural vocoders in copy-synthesis and Text-to-Speech scenarios.