 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Monocular Real-time Hand Shape and Motion Capture using Multi-modal Data
Mar 21, 2020

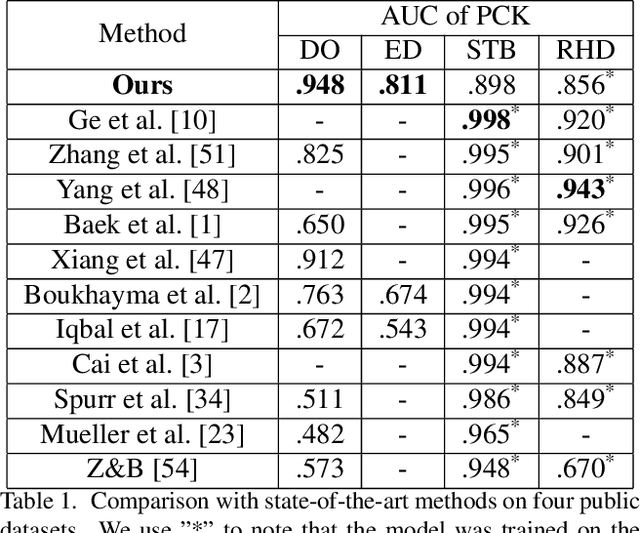
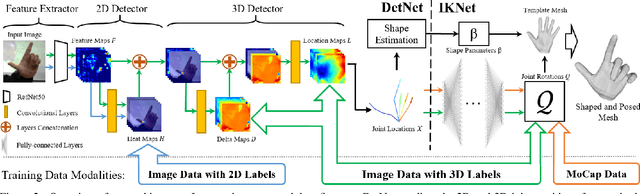
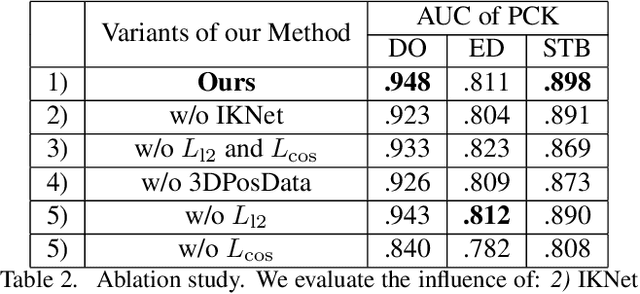
We present a novel method for monocular hand shape and pose estimation at unprecedented runtime performance of 100fps and at state-of-the-art accuracy. This is enabled by a new learning based architecture designed such that it can make use of all the sources of available hand training data: image data with either 2D or 3D annotations, as well as stand-alone 3D animations without corresponding image data. It features a 3D hand joint detection module and an inverse kinematics module which regresses not only 3D joint positions but also maps them to joint rotations in a single feed-forward pass. This output makes the method more directly usable for applications in computer vision and graphics compared to only regressing 3D joint positions. We demonstrate that our architectural design leads to a significant quantitative and qualitative improvement over the state of the art on several challenging benchmarks. Our model is publicly available for future research.
Scheduling Optimization of Heterogeneous Services by Resolving Conflicts
Mar 02, 2021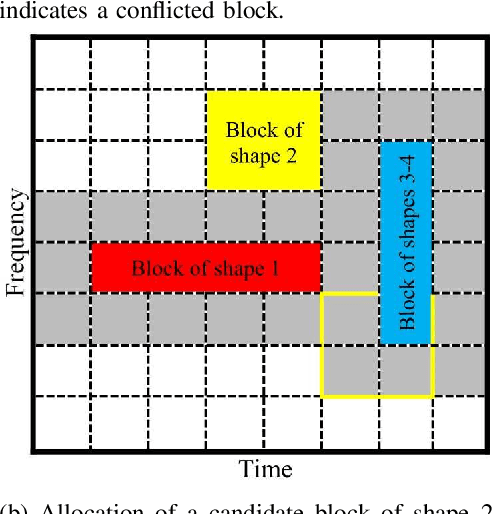
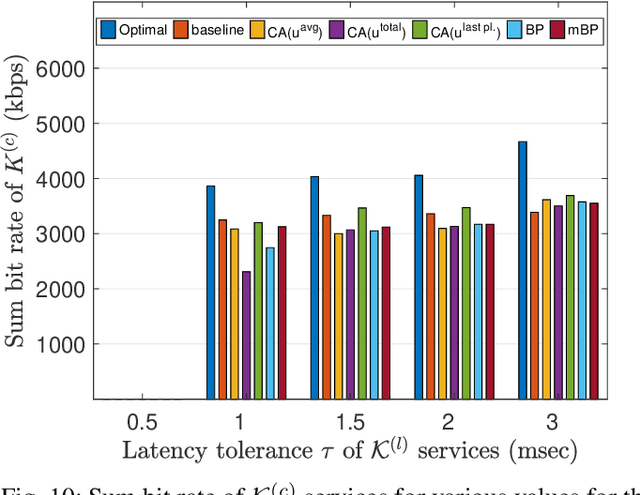
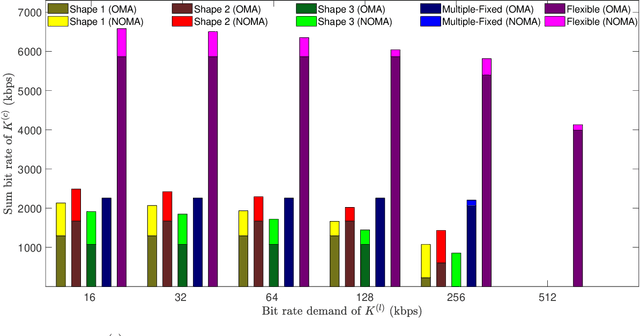
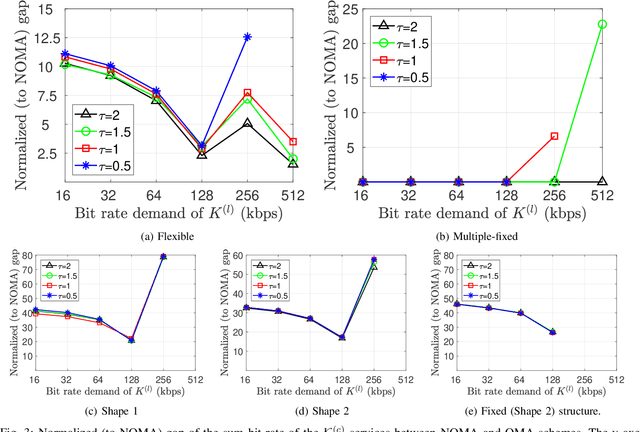
Fifth generation (5G) new radio introduced flexible numerology to provide the necessary flexibility for accommodating heterogeneous services. However, optimizing the scheduling of heterogeneous services with differing delay and throughput requirements over 5G new radio is a challenging task. In this paper, we investigate near optimal, low complexity scheduling of radio resources for ultra-reliable low-latency communications (URLLC) when coexisting with enhanced mobile broadband (eMBB) services. We demonstrate that maximizing the sum throughput of eMBB services while servicing URLLC users, is, in the long-term, equivalent to minimizing the number of URLLC placements in the time-frequency grid; this result stems from reducing the number of infeasible placements for eMBB, to which we refer to as "conflicts". To meet this new objective, we propose and investigate new conflict-aware heuristics; a family of "greedy" and a lightweight heuristic inspired by bin packing optimization, all of near optimal performance. Moreover, having shed light on the impact of conflict in layer-2 scheduling, non-orthogonal multiple access (NOMA) emerges as a competitive approach for conflict resolution, in addition to the well established increased spectral efficiency with respect to OMA. The superior performance of NOMA, thanks to alleviating conflicts,is showcased by extensive numerical results.
Accelerating Quantitative Susceptibility Mapping using Compressed Sensing and Deep Neural Network
Mar 17, 2021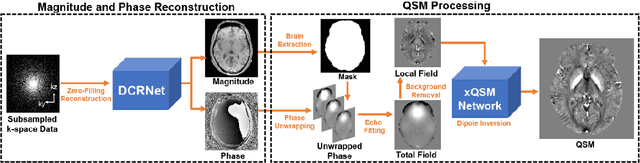
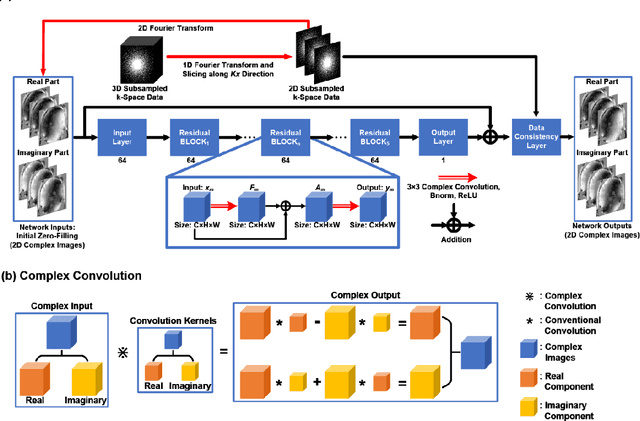
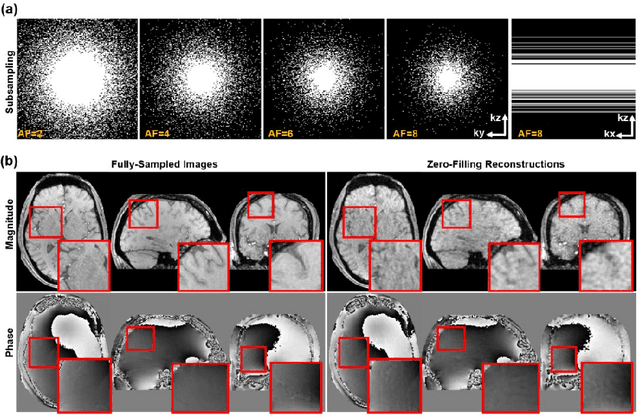
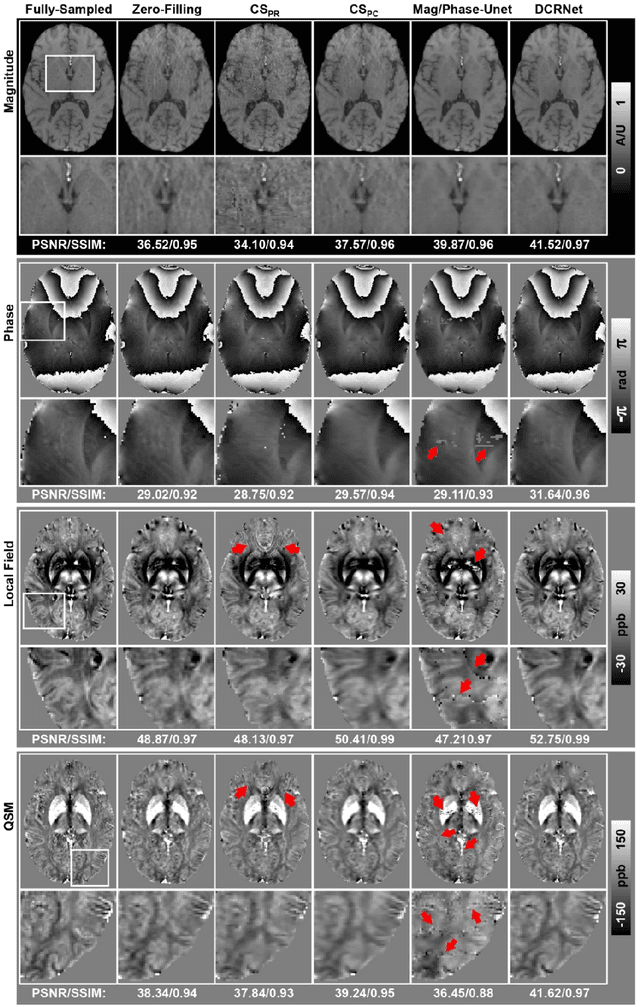
Quantitative susceptibility mapping (QSM) is an MRI phase-based post-processing method that quantifies tissue magnetic susceptibility distributions. However, QSM acquisitions are relatively slow, even with parallel imaging. Incoherent undersampling and compressed sensing reconstruction techniques have been used to accelerate traditional magnitude-based MRI acquisitions; however, most do not recover the full phase signal due to its non-convex nature. In this study, a learning-based Deep Complex Residual Network (DCRNet) is proposed to recover both the magnitude and phase images from incoherently undersampled data, enabling high acceleration of QSM acquisition. Magnitude, phase, and QSM results from DCRNet were compared with two iterative and one deep learning methods on retrospectively undersampled acquisitions from six healthy volunteers, one intracranial hemorrhage and one multiple sclerosis patients, as well as one prospectively undersampled healthy subject using a 7T scanner. Peak signal to noise ratio (PSNR), structural similarity (SSIM) and region-of-interest susceptibility measurements are reported for numerical comparisons. The proposed DCRNet method substantially reduced artifacts and blurring compared to the other methods and resulted in the highest PSNR and SSIM on the magnitude, phase, local field, and susceptibility maps. It led to 4.0% to 8.8% accuracy improvements in deep grey matter susceptibility than some existing methods, when the acquisition was accelerated four times. The proposed DCRNet also dramatically shortened the reconstruction time by nearly 10 thousand times for each scan, from around 80 hours using conventional approaches to only 30 seconds.
Real Time Lidar and Radar High-Level Fusion for Obstacle Detection and Tracking with evaluation on a ground truth
Jul 30, 2018
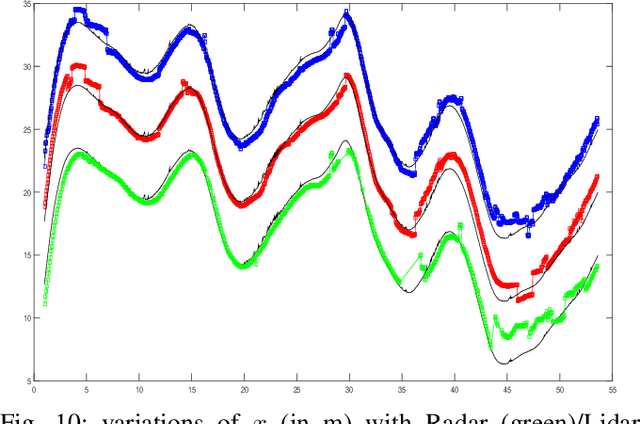
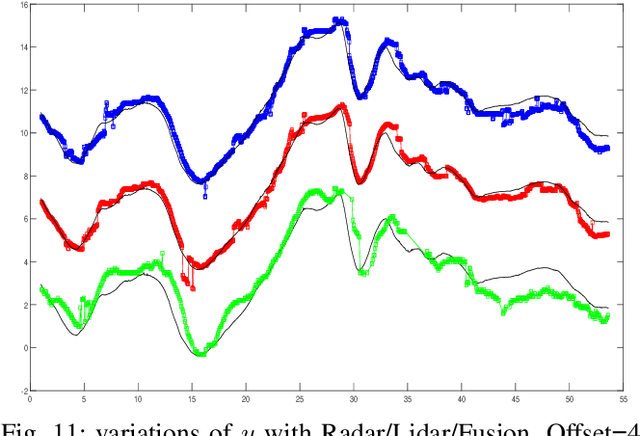
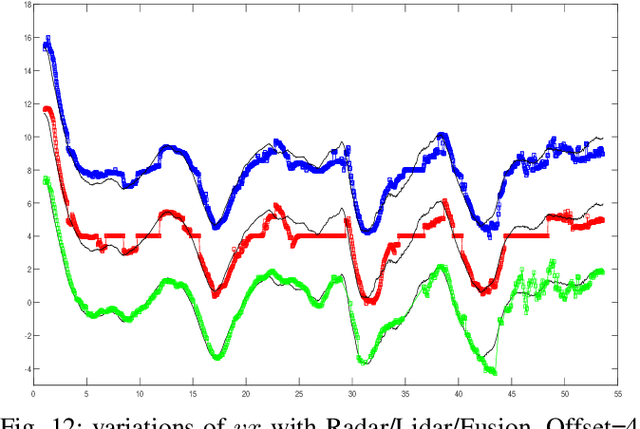
- Both Lidars and Radars are sensors for obstacle detection. While Lidars are very accurate on obstacles positions and less accurate on their velocities, Radars are more precise on obstacles velocities and less precise on their positions. Sensor fusion between Lidar and Radar aims at improving obstacle detection using advantages of the two sensors. The present paper proposes a real-time Lidar/Radar data fusion algorithm for obstacle detection and tracking based on the global nearest neighbour standard filter (GNN). This algorithm is implemented and embedded in an automative vehicle as a component generated by a real-time multisensor software. The benefits of data fusion comparing with the use of a single sensor are illustrated through several tracking scenarios (on a highway and on a bend) and using real-time kinematic sensors mounted on the ego and tracked vehicles as a ground truth.
Multi-robot task allocation for safe planning under dynamic uncertainties
Mar 02, 2021
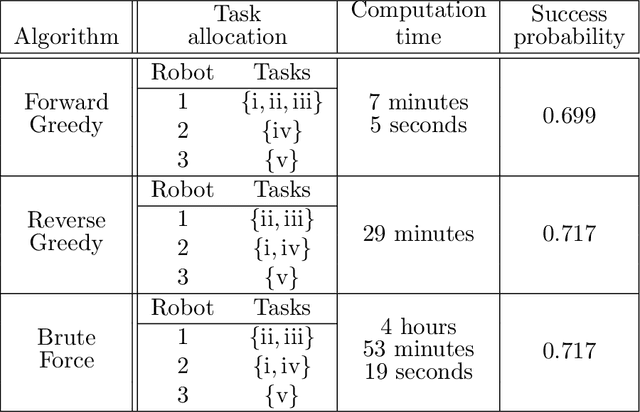
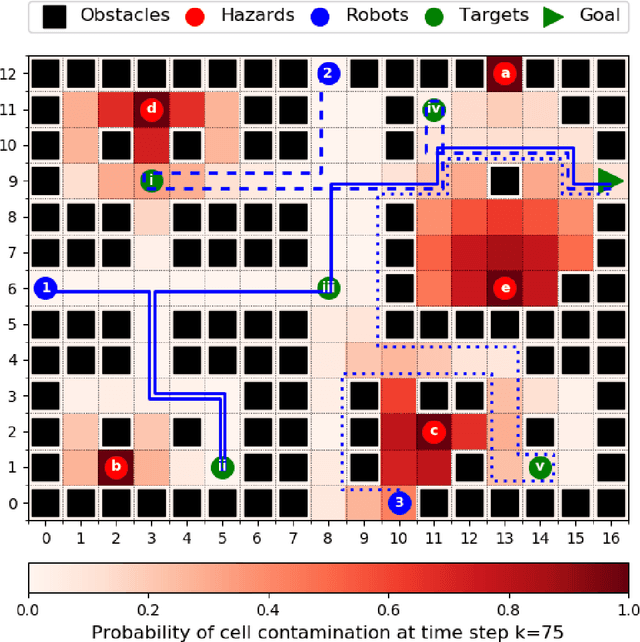
This paper considers the problem of multi-robot safe mission planning in uncertain dynamic environments. This problem arises in several applications including safety-critical exploration, surveillance, and emergency rescue missions. Computation of a multi-robot optimal control policy is challenging not only because of the complexity of incorporating dynamic uncertainties while planning, but also because of the exponential growth in problem size as a function of the number of robots. Leveraging recent works obtaining a tractable safety maximizing plan for a single robot, we propose a scalable two-stage framework to solve the problem at hand. Specifically, the problem is split into a low-level single-agent planning problem and a high-level task allocation problem. The low-level problem uses an efficient approximation of stochastic reachability for a Markov decision process to handle the dynamic uncertainty. The task allocation, on the other hand, is solved using polynomial-time forward and reverse greedy heuristics. The safety objective of our multi-robot safe planning problem allows an implementation of the greedy heuristics through a distributed auction-based approach. Moreover, by leveraging the properties of the safety objective function, we ensure provable performance bounds on the safety of the approximate solutions proposed by these two heuristics. Our result is illustrated through case studies.
Tilting the playing field: Dynamical loss functions for machine learning
Feb 13, 2021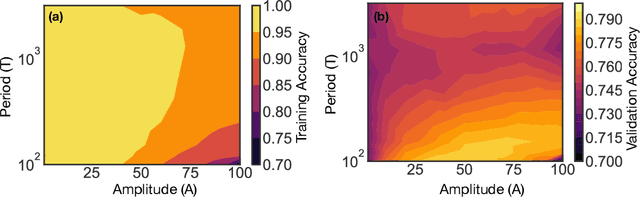
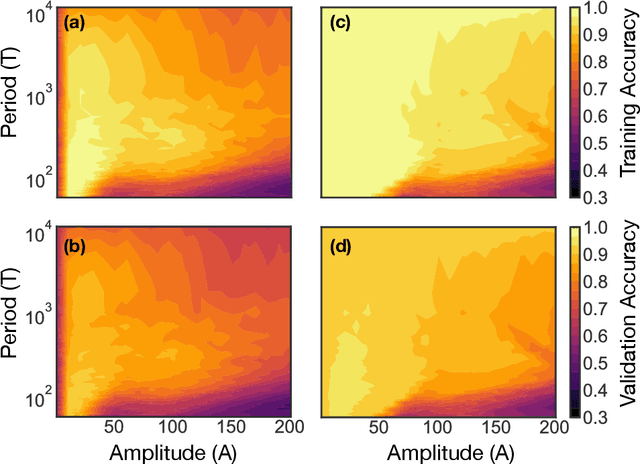
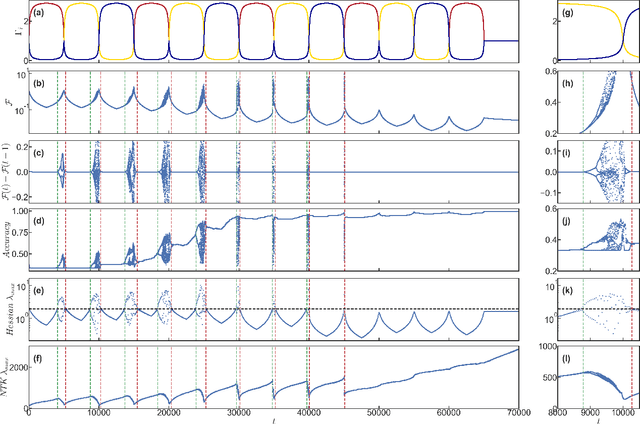
We show that learning can be improved by using loss functions that evolve cyclically during training to emphasize one class at a time. In underparameterized networks, such dynamical loss functions can lead to successful training for networks that fail to find a deep minima of the standard cross-entropy loss. In overparameterized networks, dynamical loss functions can lead to better generalization. Improvement arises from the interplay of the changing loss landscape with the dynamics of the system as it evolves to minimize the loss. In particular, as the loss function oscillates, instabilities develop in the form of bifurcation cascades, which we study using the Hessian and Neural Tangent Kernel. Valleys in the landscape widen and deepen, and then narrow and rise as the loss landscape changes during a cycle. As the landscape narrows, the learning rate becomes too large and the network becomes unstable and bounces around the valley. This process ultimately pushes the system into deeper and wider regions of the loss landscape and is characterized by decreasing eigenvalues of the Hessian. This results in better regularized models with improved generalization performance.
SAFELearning: Enable Backdoor Detectability In Federated Learning With Secure Aggregation
Feb 04, 2021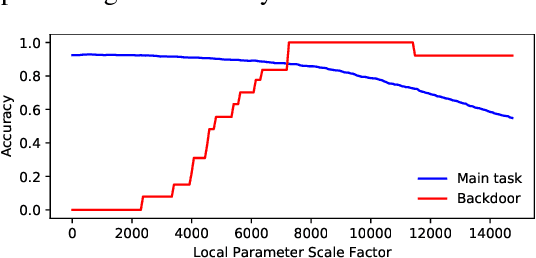

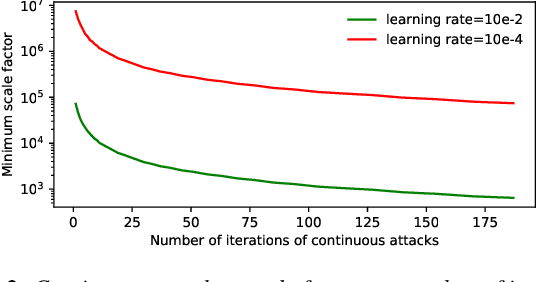

For model privacy, local model parameters in federated learning shall be obfuscated before sent to the remote aggregator. This technique is referred to as \emph{secure aggregation}. However, secure aggregation makes model poisoning attacks, e.g., to insert backdoors, more convenient given existing anomaly detection methods mostly require access to plaintext local models. This paper proposes SAFELearning which supports backdoor detection for secure aggregation. We achieve this through two new primitives - \emph{oblivious random grouping (ORG)} and \emph{partial parameter disclosure (PPD)}. ORG partitions participants into one-time random subgroups with group configurations oblivious to participants; PPD allows secure partial disclosure of aggregated subgroup models for anomaly detection without leaking individual model privacy. SAFELearning is able to significantly reduce backdoor model accuracy without jeopardizing the main task accuracy under common backdoor strategies. Extensive experiments show SAFELearning reduces backdoor accuracy from $100\%$ to $8.2\%$ for ResNet-18 over CIFAR-10 when $10\%$ participants are malicious.
Alternative Detectors for Spectrum Sensing by Exploiting Excess Bandwidth
Feb 13, 2021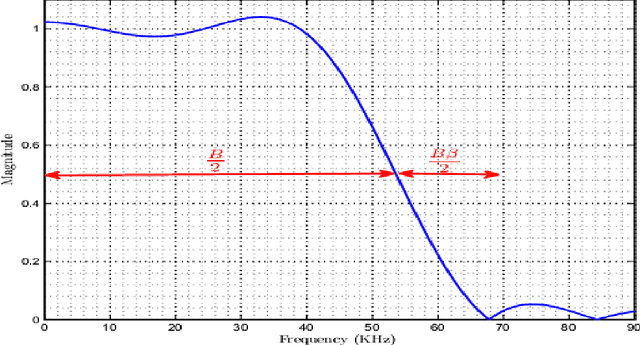
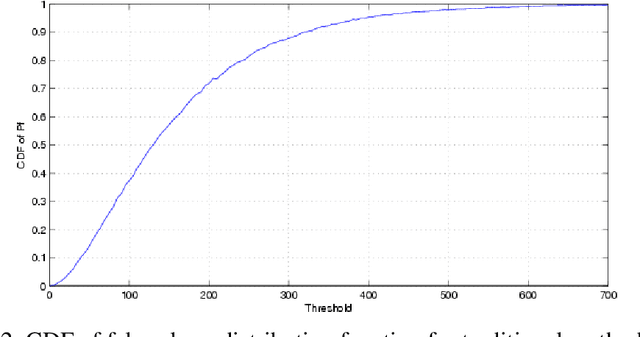
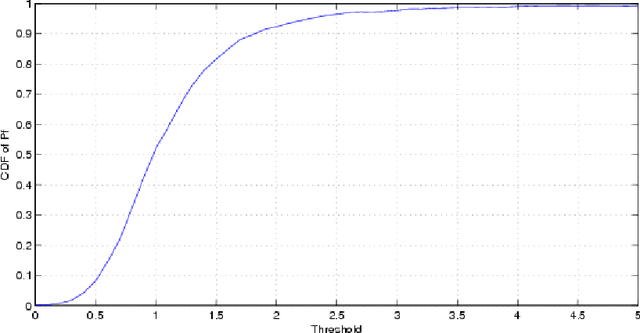
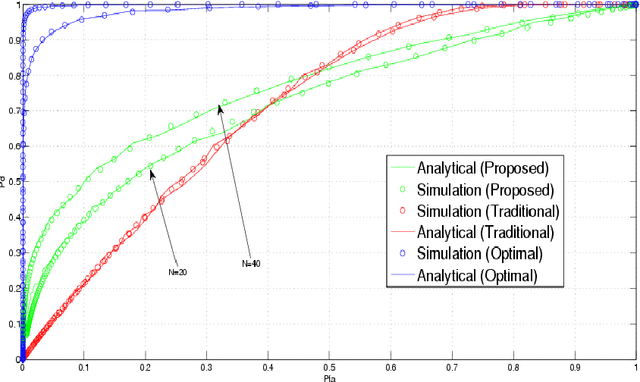
The problems regarding spectrum sensing are studied by exploiting a priori and a posteriori in information of the received noise variance. First, the traditional Average Likelihood Ratio (ALR) and the General Likelihood Ratio Test (GLRT) detectors are investigated under a Gamma distributed function as a channel noise, for the first time, under the availability of a priori statistical distribution about the noise variance. Then, two robust detectors are proposed using the exiting excess bandwidth to deliver a posteriori probability on the received noise variance uncertainty. The first proposed detector that is based on traditional ALR employs marginal distribution of the observation under available a priori and a posteriori of the received signal, while the second proposed detector employs the Maximum a posteriori (MAP) estimation of the inverse of the noise power under the same hypothesizes as the first detector. In addition, analytical expressions for the performance of the proposed detectors are obtained in terms of the false-alarm and detection probabilities. The simulation results exhibit the superiority of the proposed detectors over the traditional counterparts.
Real-Time Bidding with Multi-Agent Reinforcement Learning in Display Advertising
Sep 11, 2018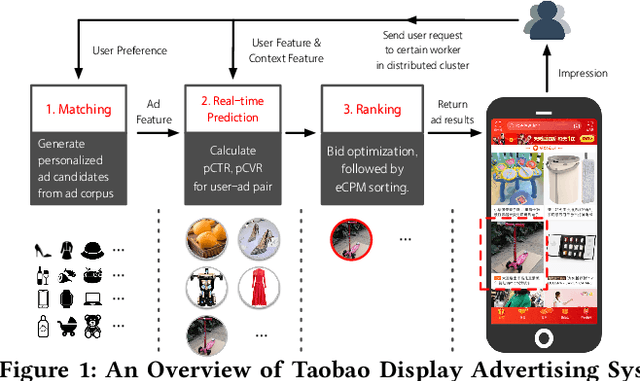
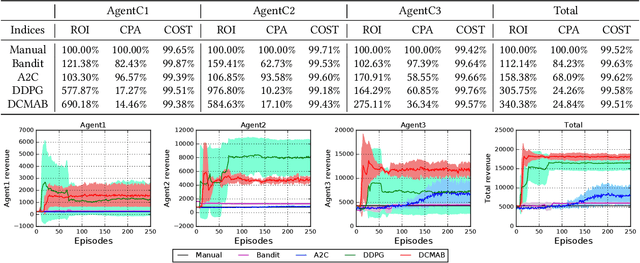
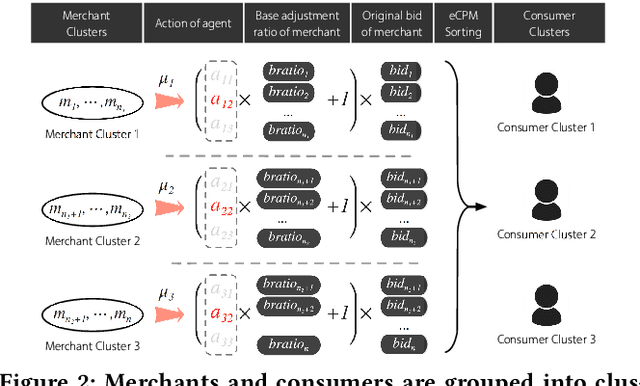
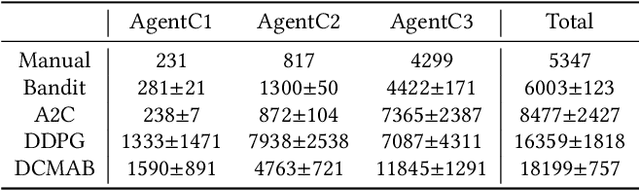
Real-time advertising allows advertisers to bid for each impression for a visiting user. To optimize specific goals such as maximizing revenue and return on investment (ROI) led by ad placements, advertisers not only need to estimate the relevance between the ads and user's interests, but most importantly require a strategic response with respect to other advertisers bidding in the market. In this paper, we formulate bidding optimization with multi-agent reinforcement learning. To deal with a large number of advertisers, we propose a clustering method and assign each cluster with a strategic bidding agent. A practical Distributed Coordinated Multi-Agent Bidding (DCMAB) has been proposed and implemented to balance the tradeoff between the competition and cooperation among advertisers. The empirical study on our industry-scaled real-world data has demonstrated the effectiveness of our methods. Our results show cluster-based bidding would largely outperform single-agent and bandit approaches, and the coordinated bidding achieves better overall objectives than purely self-interested bidding agents.
Taming Wild Price Fluctuations: Monotone Stochastic Convex Optimization with Bandit Feedback
Mar 16, 2021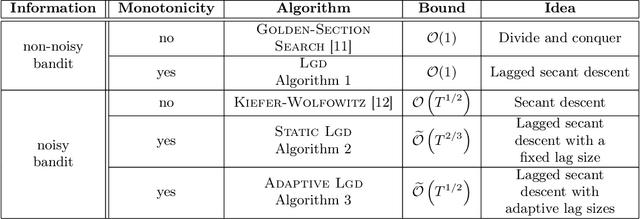
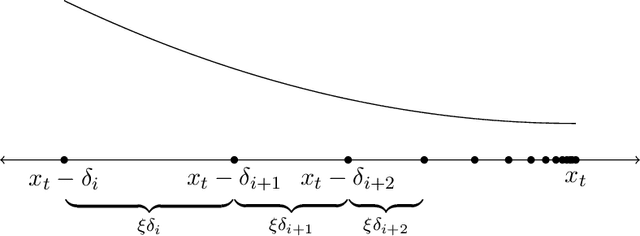
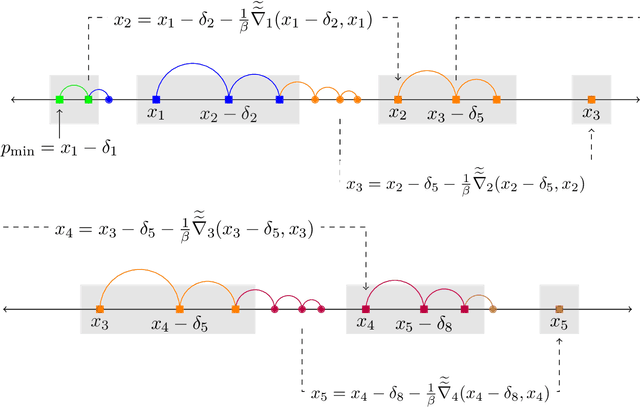
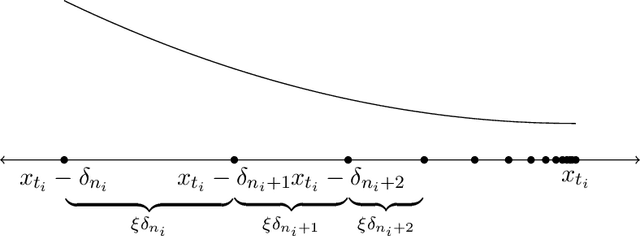
Prices generated by automated price experimentation algorithms often display wild fluctuations, leading to unfavorable customer perceptions and violations of individual fairness: e.g., the price seen by a customer can be significantly higher than what was seen by her predecessors, only to fall once again later. To address this concern, we propose demand learning under a monotonicity constraint on the sequence of prices, within the framework of stochastic convex optimization with bandit feedback. Our main contribution is the design of the first sublinear-regret algorithms for monotonic price experimentation for smooth and strongly concave revenue functions under noisy as well as noiseless bandit feedback. The monotonicity constraint presents a unique challenge: since any increase (or decrease) in the decision-levels is final, an algorithm needs to be cautious in its exploration to avoid over-shooting the optimum. At the same time, minimizing regret requires that progress be made towards the optimum at a sufficient pace. Balancing these two goals is particularly challenging under noisy feedback, where obtaining sufficiently accurate gradient estimates is expensive. Our key innovation is to utilize conservative gradient estimates to adaptively tailor the degree of caution to local gradient information, being aggressive far from the optimum and being increasingly cautious as the prices approach the optimum. Importantly, we show that our algorithms guarantee the same regret rates (up to logarithmic factors) as the best achievable rates of regret without the monotonicity requirement.