 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Global LLM Leaderboards Are Misleading: Small Portfolios for Heterogeneous Supervised ML
May 07, 2026Ranking LLMs via pairwise human feedback underpins current leaderboards for open-ended tasks, such as creative writing and problem-solving. We analyze ~89K comparisons in 116 languages from 52 LLMs from Arena, and show that the best-fit global Bradley-Terry (BT) ranking is misleading. Nearly 2/3 of the decisive votes cancel out, and even the top 50 models according to the global BT ranking are statistically indistinguishable (pairwise win probabilities are at most 0.53 within the top 50 models). We trace this failure to strong, structured heterogeneity of opinions across language, task, and time. Moreover, we find an important characteristic - *language* plays a key role. Grouping by language (and families) increases the agreement of votes massively, resulting in two orders of magnitude higher spread in the ELO scores (i.e., very consistent rankings). What appears as global noise is in fact a mixture of coherent but conflicting subpopulations. To address such heterogeneity in supervised machine learning, we introduce the framework of $(λ, ν)$-portfolios, which are small sets of models that achieve a prediction error at most $λ$, "covering" at least a $ν$ fraction of users. We formulate this as a variant of the set cover problem and provide guarantees using the VC dimension of the underlying set system. On the Arena data, our algorithms recover just 5 distinct BT rankings that cover over 96% of votes at a modest $λ$, compared to the 21% coverage by the global ranking. We also provide a portfolio of 6 LLMs that cover twice as many votes as the top-6 LLMs from a global ranking. We further construct portfolios for a classification problem on the COMPAS dataset using an ensemble of fairness-regularized classification models and show that these portfolios can be used to detect blind spots in the data, which might be of independent interest to policymakers.
Many Preferences, Few Policies: Towards Scalable Language Model Personalization
Apr 05, 2026The holy grail of LLM personalization is a single LLM for each user, perfectly aligned with that user's preferences. However, maintaining a separate LLM per user is impractical due to constraints on compute, memory, and system complexity. We address this challenge by developing a principled method for selecting a small portfolio of LLMs that captures representative behaviors across heterogeneous users. We model user preferences across multiple traits (e.g., safety, humor, brevity) through a multi-dimensional weight vector. Given reward functions across these dimensions, our algorithm PALM (Portfolio of Aligned LLMs) generates a small portfolio of LLMs such that, for any weight vector, the portfolio contains a near-optimal LLM for the corresponding scalarized objective. To the best of our knowledge, this is the first result that provides theoretical guarantees on both the size and approximation quality of LLM portfolios for personalization. It characterizes the trade-off between system cost and personalization, as well as the diversity of LLMs required to cover the landscape of user preferences. We provide empirical results that validate these guarantees and demonstrate greater output diversity over common baselines.
Improved Regret Guarantees for Online Mirror Descent using a Portfolio of Mirror Maps
Feb 13, 2026OMD and its variants give a flexible framework for OCO where the performance depends crucially on the choice of the mirror map. While the geometries underlying OPGD and OEG, both special cases of OMD, are well understood, it remains a challenging open question on how to construct an optimal mirror map for any given constrained set and a general family of loss functions, e.g., sparse losses. Motivated by parameterizing a near-optimal set of mirror maps, we consider a simpler question: is it even possible to obtain polynomial gains in regret by using mirror maps for geometries that interpolate between $L_1$ and $L_2$, which may not be possible by restricting to only OEG ($L_1$) or OPGD ($L_2$). Our main result answers this question positively. We show that mirror maps based on block norms adapt better to the sparsity of loss functions, compared to previous $L_p$ (for $p \in [1, 2]$) interpolations. In particular, we construct a family of online convex optimization instances in $\mathbb{R}^d$, where block norm-based mirror maps achieve a provable polynomial (in $d$) improvement in regret over OEG and OPGD for sparse loss functions. We then turn to the setting in which the sparsity level of the loss functions is unknown. In this case, the choice of geometry itself becomes an online decision problem. We first show that naively switching between OEG and OPGD can incur linear regret, highlighting the intrinsic difficulty of geometry selection. To overcome this issue, we propose a meta-algorithm based on multiplicative weights that dynamically selects among a family of uniform block norms. We show that this approach effectively tunes OMD to the sparsity of the losses, yielding adaptive regret guarantees. Overall, our results demonstrate that online mirror-map selection can significantly enhance the ability of OMD to exploit sparsity in online convex optimization.
AnyView: Synthesizing Any Novel View in Dynamic Scenes
Jan 23, 2026Modern generative video models excel at producing convincing, high-quality outputs, but struggle to maintain multi-view and spatiotemporal consistency in highly dynamic real-world environments. In this work, we introduce \textbf{AnyView}, a diffusion-based video generation framework for \emph{dynamic view synthesis} with minimal inductive biases or geometric assumptions. We leverage multiple data sources with various levels of supervision, including monocular (2D), multi-view static (3D) and multi-view dynamic (4D) datasets, to train a generalist spatiotemporal implicit representation capable of producing zero-shot novel videos from arbitrary camera locations and trajectories. We evaluate AnyView on standard benchmarks, showing competitive results with the current state of the art, and propose \textbf{AnyViewBench}, a challenging new benchmark tailored towards \emph{extreme} dynamic view synthesis in diverse real-world scenarios. In this more dramatic setting, we find that most baselines drastically degrade in performance, as they require significant overlap between viewpoints, while AnyView maintains the ability to produce realistic, plausible, and spatiotemporally consistent videos when prompted from \emph{any} viewpoint. Results, data, code, and models can be viewed at: https://tri-ml.github.io/AnyView/
Mixed-Integer Projections for Automated Data Correction of EMRs Improve Predictions of Sepsis among Hospitalized Patients
Aug 21, 2023Machine learning (ML) models are increasingly pivotal in automating clinical decisions. Yet, a glaring oversight in prior research has been the lack of proper processing of Electronic Medical Record (EMR) data in the clinical context for errors and outliers. Addressing this oversight, we introduce an innovative projections-based method that seamlessly integrates clinical expertise as domain constraints, generating important meta-data that can be used in ML workflows. In particular, by using high-dimensional mixed-integer programs that capture physiological and biological constraints on patient vitals and lab values, we can harness the power of mathematical "projections" for the EMR data to correct patient data. Consequently, we measure the distance of corrected data from the constraints defining a healthy range of patient data, resulting in a unique predictive metric we term as "trust-scores". These scores provide insight into the patient's health status and significantly boost the performance of ML classifiers in real-life clinical settings. We validate the impact of our framework in the context of early detection of sepsis using ML. We show an AUROC of 0.865 and a precision of 0.922, that surpasses conventional ML models without such projections.
TACOS: Topology-Aware Collective Algorithm Synthesizer for Distributed Training
Apr 11, 2023



Collective communications are an indispensable part of distributed training. Running a topology-aware collective algorithm is crucial for optimizing communication performance by minimizing congestion. Today such algorithms only exist for a small set of simple topologies, limiting the topologies employed in training clusters and handling irregular topologies due to network failures. In this paper, we propose TACOS, an automated topology-aware collective synthesizer for arbitrary input network topologies. TACOS synthesized 3.73x faster All-Reduce algorithm over baselines, and synthesized collective algorithms for 512-NPU system in just 6.1 minutes.
Artificial Intelligence/Operations Research Workshop 2 Report Out
Apr 10, 2023



This workshop Report Out focuses on the foundational elements of trustworthy AI and OR technology, and how to ensure all AI and OR systems implement these elements in their system designs. Four sessions on various topics within Trustworthy AI were held, these being Fairness, Explainable AI/Causality, Robustness/Privacy, and Human Alignment and Human-Computer Interaction. Following discussions of each of these topics, workshop participants also brainstormed challenge problems which require the collaboration of AI and OR researchers and will result in the integration of basic techniques from both fields to eventually benefit societal needs.
Tree DNN: A Deep Container Network
Dec 07, 2022

Multi-Task Learning (MTL) has shown its importance at user products for fast training, data efficiency, reduced overfitting etc. MTL achieves it by sharing the network parameters and training a network for multiple tasks simultaneously. However, MTL does not provide the solution, if each task needs training from a different dataset. In order to solve the stated problem, we have proposed an architecture named TreeDNN along with it's training methodology. TreeDNN helps in training the model with multiple datasets simultaneously, where each branch of the tree may need a different training dataset. We have shown in the results that TreeDNN provides competitive performance with the advantage of reduced ROM requirement for parameter storage and increased responsiveness of the system by loading only specific branch at inference time.
Reusing Combinatorial Structure: Faster Iterative Projections over Submodular Base Polytopes
Jun 22, 2021
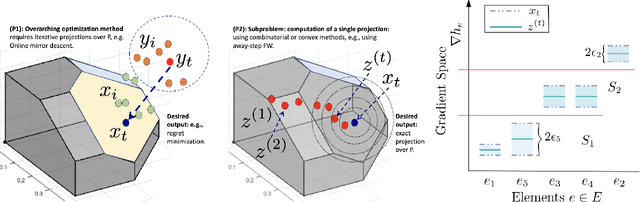

Optimization algorithms such as projected Newton's method, FISTA, mirror descent and its variants enjoy near-optimal regret bounds and convergence rates, but suffer from a computational bottleneck of computing "projections'' in potentially each iteration (e.g., $O(T^{1/2})$ regret of online mirror descent). On the other hand, conditional gradient variants solve a linear optimization in each iteration, but result in suboptimal rates (e.g., $O(T^{3/4})$ regret of online Frank-Wolfe). Motivated by this trade-off in runtime v/s convergence rates, we consider iterative projections of close-by points over widely-prevalent submodular base polytopes $B(f)$. We develop a toolkit to speed up the computation of projections using both discrete and continuous perspectives. We subsequently adapt the away-step Frank-Wolfe algorithm to use this information and enable early termination. For the special case of cardinality based submodular polytopes, we improve the runtime of computing certain Bregman projections by a factor of $\Omega(n/\log(n))$. Our theoretical results show orders of magnitude reduction in runtime in preliminary computational experiments.
Taming Wild Price Fluctuations: Monotone Stochastic Convex Optimization with Bandit Feedback
Mar 16, 2021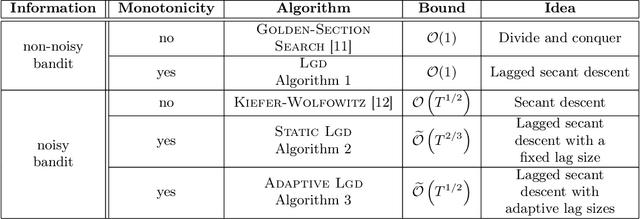
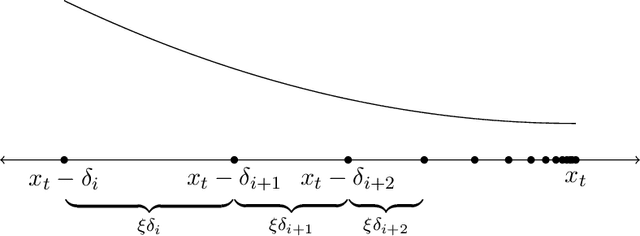
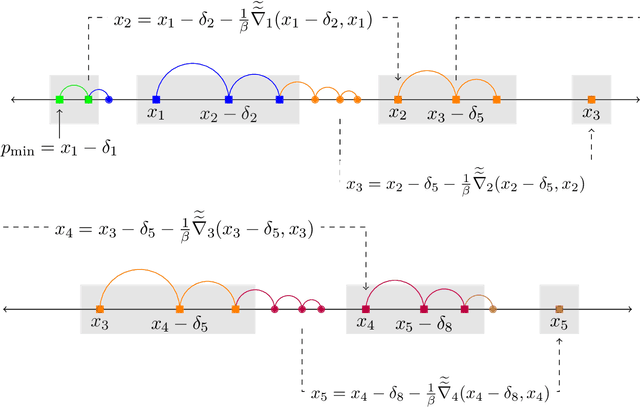
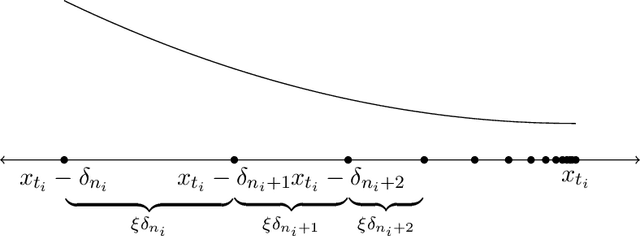
Prices generated by automated price experimentation algorithms often display wild fluctuations, leading to unfavorable customer perceptions and violations of individual fairness: e.g., the price seen by a customer can be significantly higher than what was seen by her predecessors, only to fall once again later. To address this concern, we propose demand learning under a monotonicity constraint on the sequence of prices, within the framework of stochastic convex optimization with bandit feedback. Our main contribution is the design of the first sublinear-regret algorithms for monotonic price experimentation for smooth and strongly concave revenue functions under noisy as well as noiseless bandit feedback. The monotonicity constraint presents a unique challenge: since any increase (or decrease) in the decision-levels is final, an algorithm needs to be cautious in its exploration to avoid over-shooting the optimum. At the same time, minimizing regret requires that progress be made towards the optimum at a sufficient pace. Balancing these two goals is particularly challenging under noisy feedback, where obtaining sufficiently accurate gradient estimates is expensive. Our key innovation is to utilize conservative gradient estimates to adaptively tailor the degree of caution to local gradient information, being aggressive far from the optimum and being increasingly cautious as the prices approach the optimum. Importantly, we show that our algorithms guarantee the same regret rates (up to logarithmic factors) as the best achievable rates of regret without the monotonicity requirement.