 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining of Physical Neural Networks
Jun 05, 2024



Physical neural networks (PNNs) are a class of neural-like networks that leverage the properties of physical systems to perform computation. While PNNs are so far a niche research area with small-scale laboratory demonstrations, they are arguably one of the most underappreciated important opportunities in modern AI. Could we train AI models 1000x larger than current ones? Could we do this and also have them perform inference locally and privately on edge devices, such as smartphones or sensors? Research over the past few years has shown that the answer to all these questions is likely "yes, with enough research": PNNs could one day radically change what is possible and practical for AI systems. To do this will however require rethinking both how AI models work, and how they are trained - primarily by considering the problems through the constraints of the underlying hardware physics. To train PNNs at large scale, many methods including backpropagation-based and backpropagation-free approaches are now being explored. These methods have various trade-offs, and so far no method has been shown to scale to the same scale and performance as the backpropagation algorithm widely used in deep learning today. However, this is rapidly changing, and a diverse ecosystem of training techniques provides clues for how PNNs may one day be utilized to create both more efficient realizations of current-scale AI models, and to enable unprecedented-scale models.
Tilting the playing field: Dynamical loss functions for machine learning
Feb 13, 2021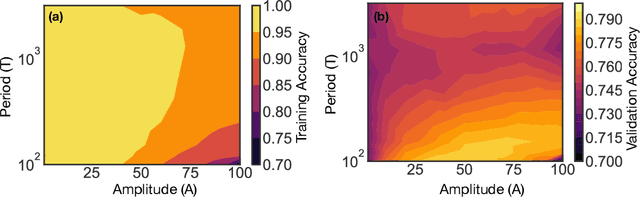
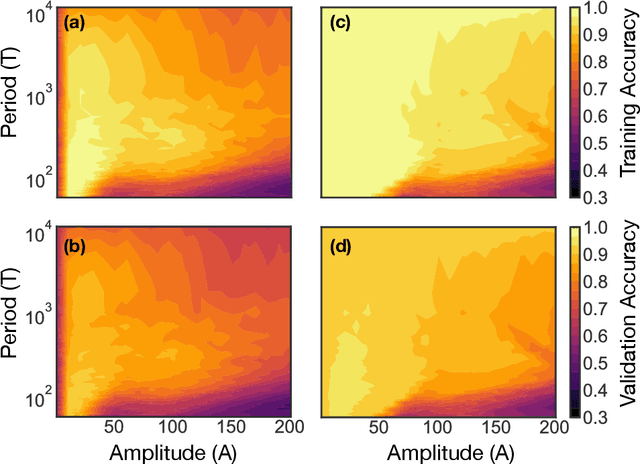
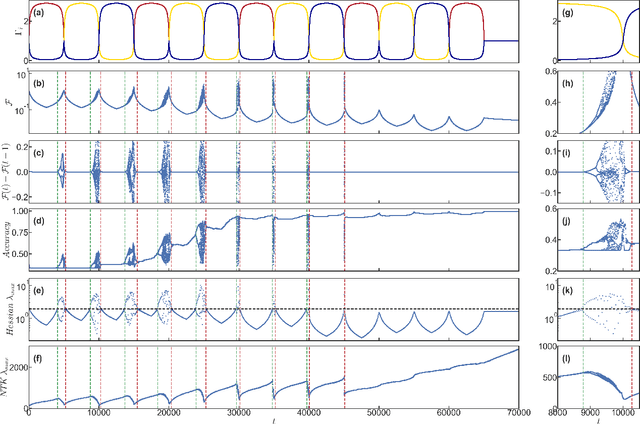
We show that learning can be improved by using loss functions that evolve cyclically during training to emphasize one class at a time. In underparameterized networks, such dynamical loss functions can lead to successful training for networks that fail to find a deep minima of the standard cross-entropy loss. In overparameterized networks, dynamical loss functions can lead to better generalization. Improvement arises from the interplay of the changing loss landscape with the dynamics of the system as it evolves to minimize the loss. In particular, as the loss function oscillates, instabilities develop in the form of bifurcation cascades, which we study using the Hessian and Neural Tangent Kernel. Valleys in the landscape widen and deepen, and then narrow and rise as the loss landscape changes during a cycle. As the landscape narrows, the learning rate becomes too large and the network becomes unstable and bounces around the valley. This process ultimately pushes the system into deeper and wider regions of the loss landscape and is characterized by decreasing eigenvalues of the Hessian. This results in better regularized models with improved generalization performance.
Attractive vs. truncated repulsive supercooled liquids : dynamics is encoded in the pair correlation function
Jun 03, 2019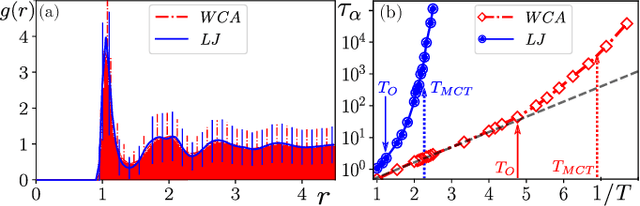
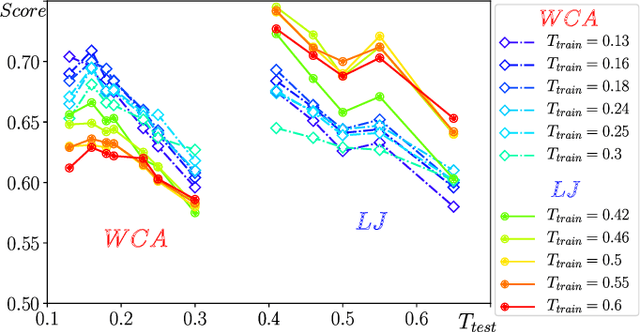
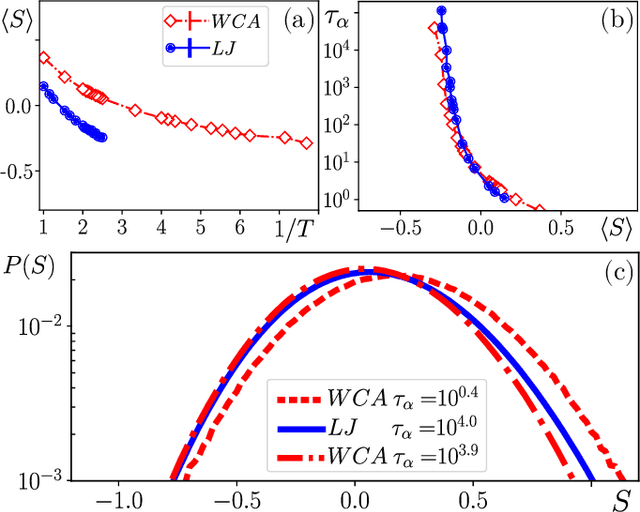
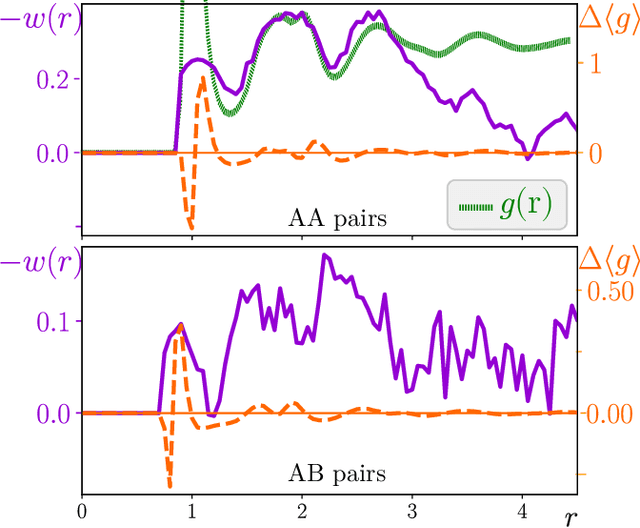
We compare glassy dynamics in two liquids that differ in the form of their interaction potentials. Both systems have the same repulsive interactions but one has also an attractive part in the potential. These two systems exhibit very different dynamics despite having nearly identical pair correlation functions. We demonstrate that a properly weighted integral of the pair correlation function, which amplifies the subtle differences between the two systems, correctly captures their dynamical differences. The weights are obtained from a standard machine learning algorithm.