 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Asynchronous and Sparse Human-Object Interaction in Videos
Mar 03, 2021
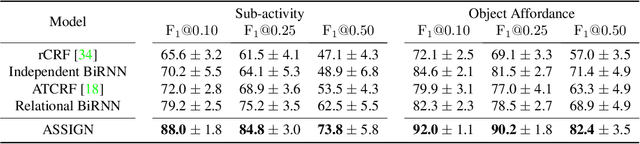
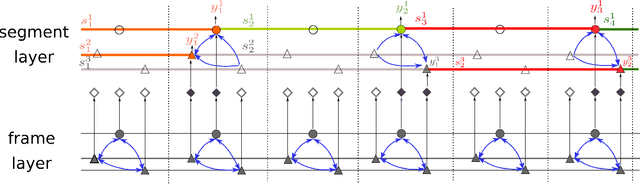
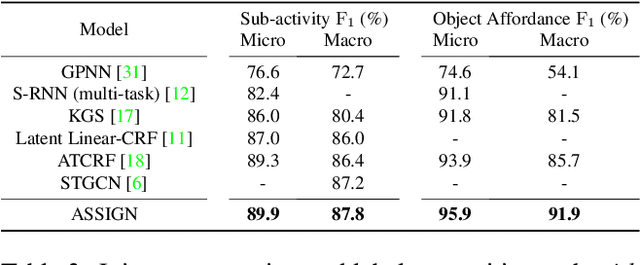
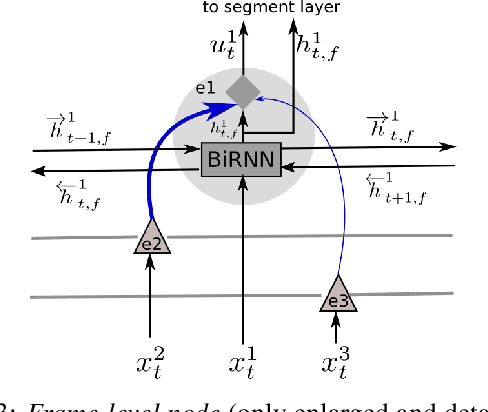
Human activities can be learned from video. With effective modeling it is possible to discover not only the action labels but also the temporal structures of the activities such as the progression of the sub-activities. Automatically recognizing such structure from raw video signal is a new capability that promises authentic modeling and successful recognition of human-object interactions. Toward this goal, we introduce Asynchronous-Sparse Interaction Graph Networks (ASSIGN), a recurrent graph network that is able to automatically detect the structure of interaction events associated with entities in a video scene. ASSIGN pioneers learning of autonomous behavior of video entities including their dynamic structure and their interaction with the coexisting neighbors. Entities' lives in our model are asynchronous to those of others therefore more flexible in adaptation to complex scenarios. Their interactions are sparse in time hence more faithful to the true underlying nature and more robust in inference and learning. ASSIGN is tested on human-object interaction recognition and shows superior performance in segmenting and labeling of human sub-activities and object affordances from raw videos. The native ability for discovering temporal structures of the model also eliminates the dependence on external segmentation that was previously mandatory for this task.
RSAC: Regularized Subspace Approximation Classifier for Lightweight Continuous Learning
Jul 03, 2020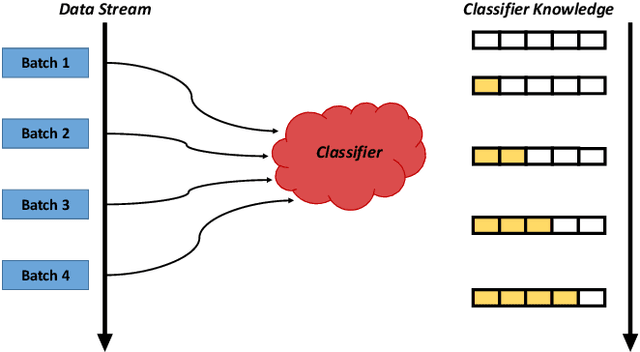
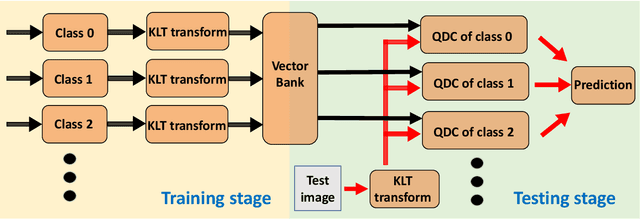

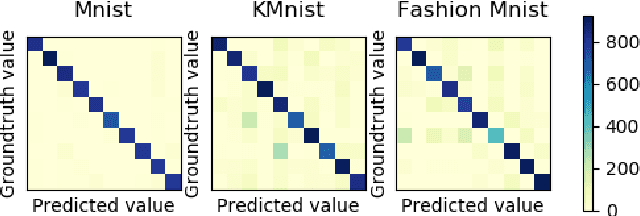
Continuous learning seeks to perform the learning on the data that arrives from time to time. While prior works have demonstrated several possible solutions, these approaches require excessive training time as well as memory usage. This is impractical for applications where time and storage are constrained, such as edge computing. In this work, a novel training algorithm, regularized subspace approximation classifier (RSAC), is proposed to achieve lightweight continuous learning. RSAC contains a feature reduction module and classifier module with regularization. Extensive experiments show that RSAC is more efficient than prior continuous learning works and outperforms these works on various experimental settings.
Resilient Active Information Acquisition with Teams of Robots
Mar 03, 2021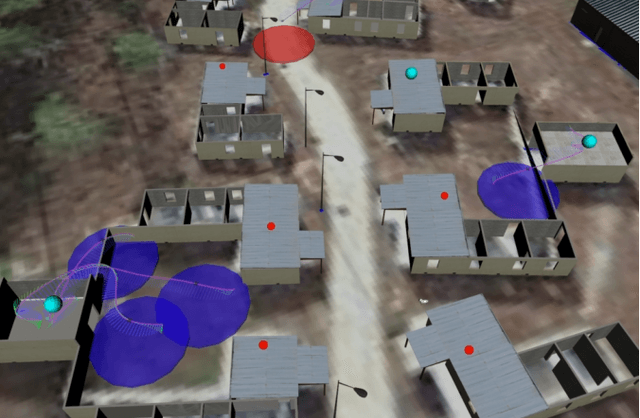
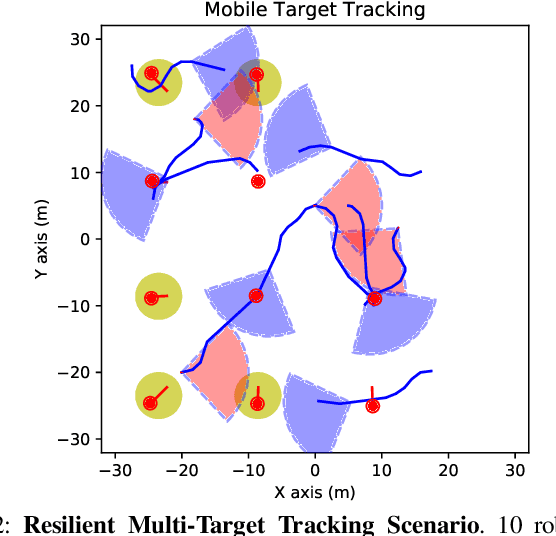
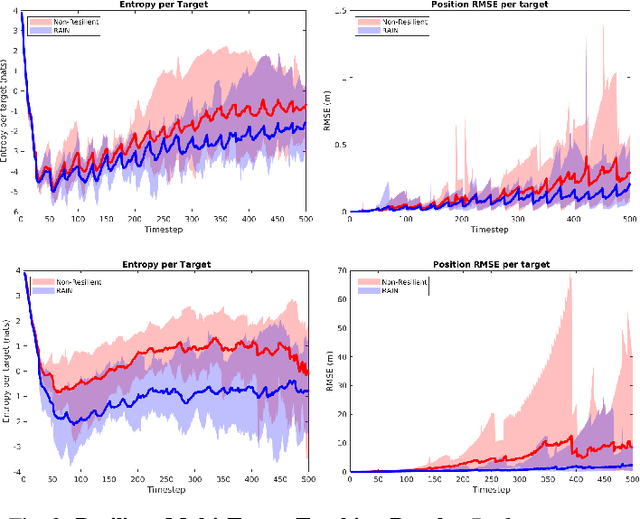
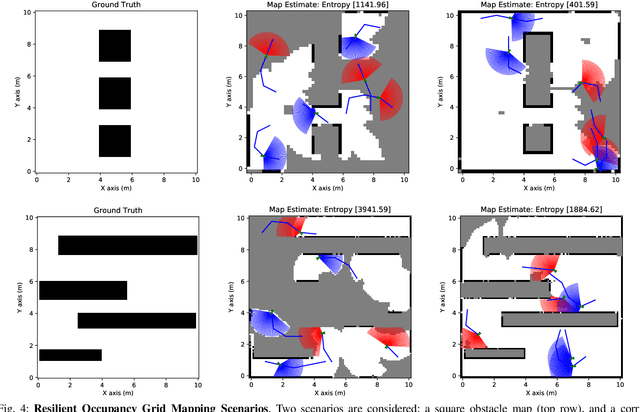
Emerging applications of collaborative autonomy, such as Multi-Target Tracking, Unknown Map Exploration, and Persistent Surveillance, require robots plan paths to navigate an environment while maximizing the information collected via on-board sensors. In this paper, we consider such information acquisition tasks but in adversarial environments, where attacks may temporarily disable the robots' sensors. We propose the first receding horizon algorithm, aiming for robust and adaptive multi-robot planning against any number of attacks, which we call Resilient Active Information acquisitioN (RAIN). RAIN calls, in an online fashion, a Robust Trajectory Planning (RTP) subroutine which plans attack-robust control inputs over a look-ahead planning horizon. We quantify RTP's performance by bounding its suboptimality. We base our theoretical analysis on notions of curvature introduced in combinatorial optimization. We evaluate RAIN in three information acquisition scenarios: Multi-Target Tracking, Occupancy Grid Mapping, and Persistent Surveillance. The scenarios are simulated in C++ and a Unity-based simulator. In all simulations, RAIN runs in real-time, and exhibits superior performance against a state-of-the-art baseline information acquisition algorithm, even in the presence of a high number of attacks. We also demonstrate RAIN's robustness and effectiveness against varying models of attacks (worst-case and random), as well as, varying replanning rates.
MIcro-Surgical Anastomose Workflow recognition challenge report
Mar 24, 2021
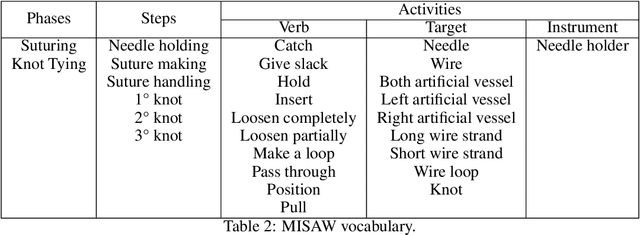
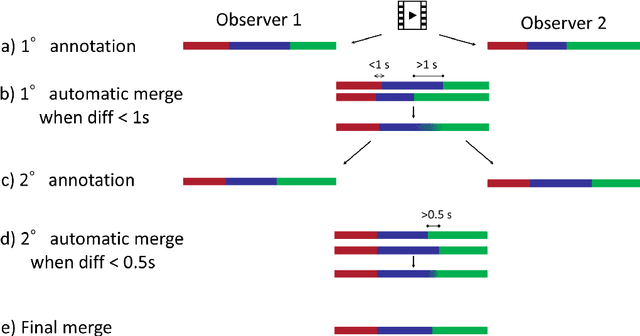
The "MIcro-Surgical Anastomose Workflow recognition on training sessions" (MISAW) challenge provided a data set of 27 sequences of micro-surgical anastomosis on artificial blood vessels. This data set was composed of videos, kinematics, and workflow annotations described at three different granularity levels: phase, step, and activity. The participants were given the option to use kinematic data and videos to develop workflow recognition models. Four tasks were proposed to the participants: three of them were related to the recognition of surgical workflow at three different granularity levels, while the last one addressed the recognition of all granularity levels in the same model. One ranking was made for each task. We used the average application-dependent balanced accuracy (AD-Accuracy) as the evaluation metric. This takes unbalanced classes into account and it is more clinically relevant than a frame-by-frame score. Six teams, including a non-competing team, participated in at least one task. All models employed deep learning models, such as CNN or RNN. The best models achieved more than 95% AD-Accuracy for phase recognition, 80% for step recognition, 60% for activity recognition, and 75% for all granularity levels. For high levels of granularity (i.e., phases and steps), the best models had a recognition rate that may be sufficient for applications such as prediction of remaining surgical time or resource management. However, for activities, the recognition rate was still low for applications that can be employed clinically. The MISAW data set is publicly available to encourage further research in surgical workflow recognition. It can be found at www.synapse.org/MISAW
Rapid treatment planning for low-dose-rate prostate brachytherapy with TP-GAN
Mar 18, 2021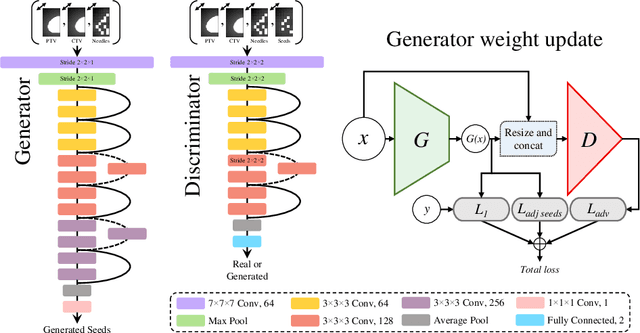
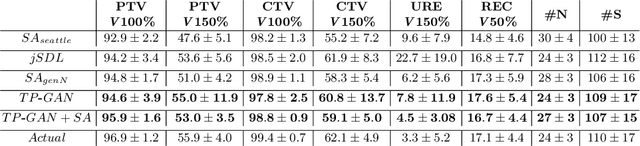

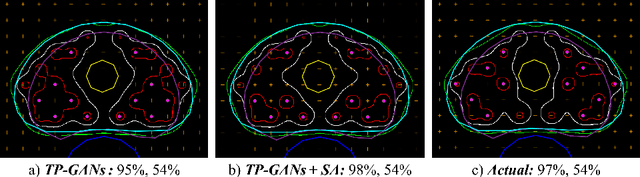
Treatment planning in low-dose-rate prostate brachytherapy (LDR-PB) aims to produce arrangement of implantable radioactive seeds that deliver a minimum prescribed dose to the prostate whilst minimizing toxicity to healthy tissues. There can be multiple seed arrangements that satisfy this dosimetric criterion, not all deemed 'acceptable' for implant from a physician's perspective. This leads to plans that are subjective to the physician's/centre's preference, planning style, and expertise. We propose a method that aims to reduce this variability by training a model to learn from a large pool of successful retrospective LDR-PB data (961 patients) and create consistent plans that mimic the high-quality manual plans. Our model is based on conditional generative adversarial networks that use a novel loss function for penalizing the model on spatial constraints of the seeds. An optional optimizer based on a simulated annealing (SA) algorithm can be used to further fine-tune the plans if necessary (determined by the treating physician). Performance analysis was conducted on 150 test cases demonstrating comparable results to that of the manual prehistorical plans. On average, the clinical target volume covering 100% of the prescribed dose was 98.9% for our method compared to 99.4% for manual plans. Moreover, using our model, the planning time was significantly reduced to an average of 2.5 mins/plan with SA, and less than 3 seconds without SA. Compared to this, manual planning at our centre takes around 20 mins/plan.
Predicting Discharge Medications at Admission Time Based on Deep Learning
Dec 05, 2017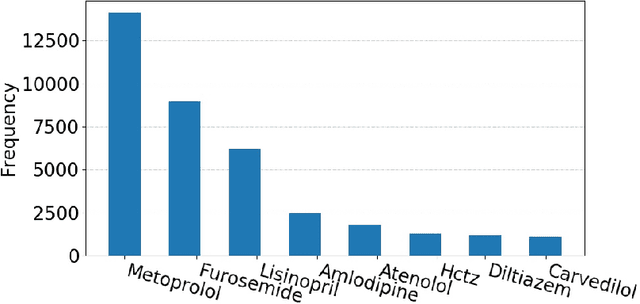

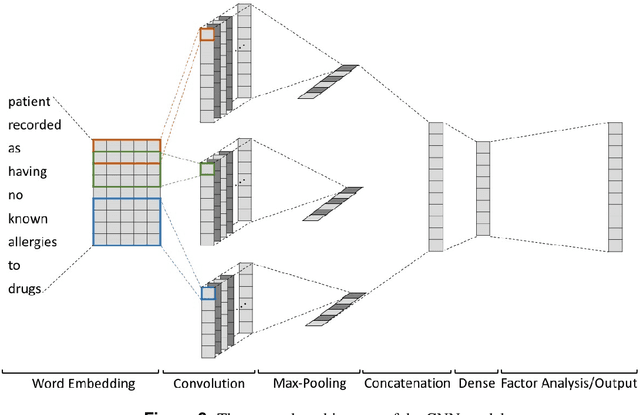
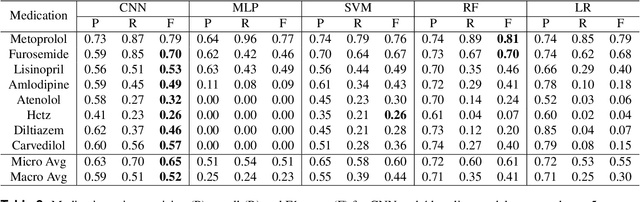
Predicting discharge medications right after a patient being admitted is an important clinical decision, which provides physicians with guidance on what type of medication regimen to plan for and what possible changes on initial medication may occur during an inpatient stay. It also facilitates medication reconciliation process with easy detection of medication discrepancy at discharge time to improve patient safety. However, since the information available upon admission is limited and patients' condition may evolve during an inpatient stay, these predictions could be a difficult decision for physicians to make. In this work, we investigate how to leverage deep learning technologies to assist physicians in predicting discharge medications based on information documented in the admission note. We build a convolutional neural network which takes an admission note as input and predicts the medications placed on the patient at discharge time. Our method is able to distill semantic patterns from unstructured and noisy texts, and is capable of capturing the pharmacological correlations among medications. We evaluate our method on 25K patient visits and compare with 4 strong baselines. Our methods demonstrate a 20% increase in macro-averaged F1 score than the best baseline.
Test and Evaluation Framework for Multi-Agent Systems of Autonomous Intelligent Agents
Jan 25, 2021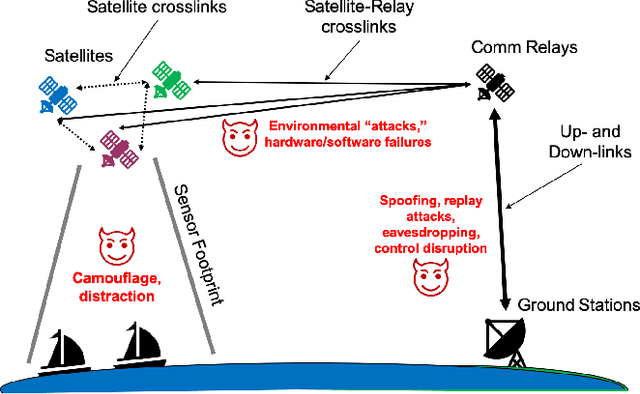
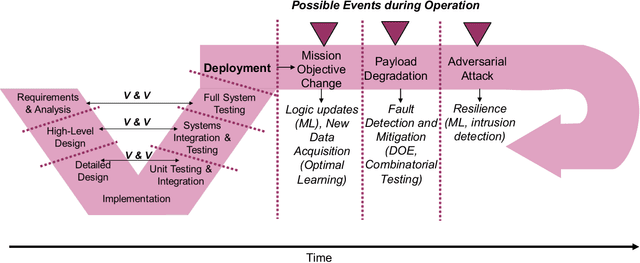
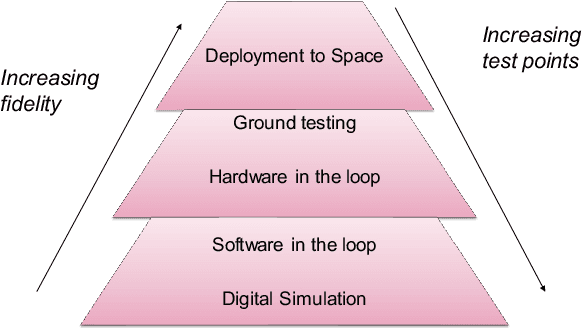
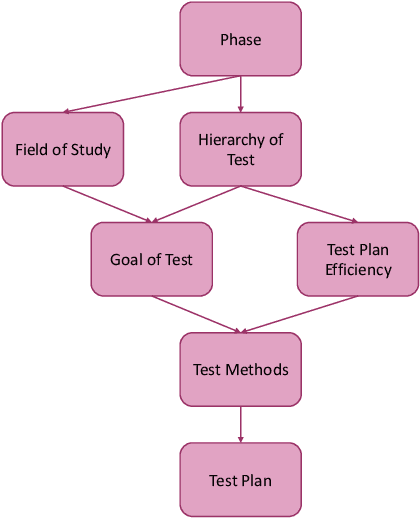
Test and evaluation is a necessary process for ensuring that engineered systems perform as intended under a variety of conditions, both expected and unexpected. In this work, we consider the unique challenges of developing a unifying test and evaluation framework for complex ensembles of cyber-physical systems with embedded artificial intelligence. We propose a framework that incorporates test and evaluation throughout not only the development life cycle, but continues into operation as the system learns and adapts in a noisy, changing, and contended environment. The framework accounts for the challenges of testing the integration of diverse systems at various hierarchical scales of composition while respecting that testing time and resources are limited. A generic use case is provided for illustrative purposes and research directions emerging as a result of exploring the use case via the framework are suggested.
Parsimonious Quantile Regression of Financial Asset Tail Dynamics via Sequential Learning
Oct 16, 2020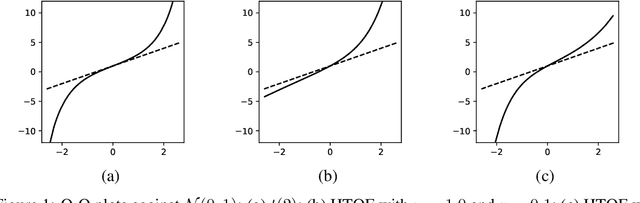
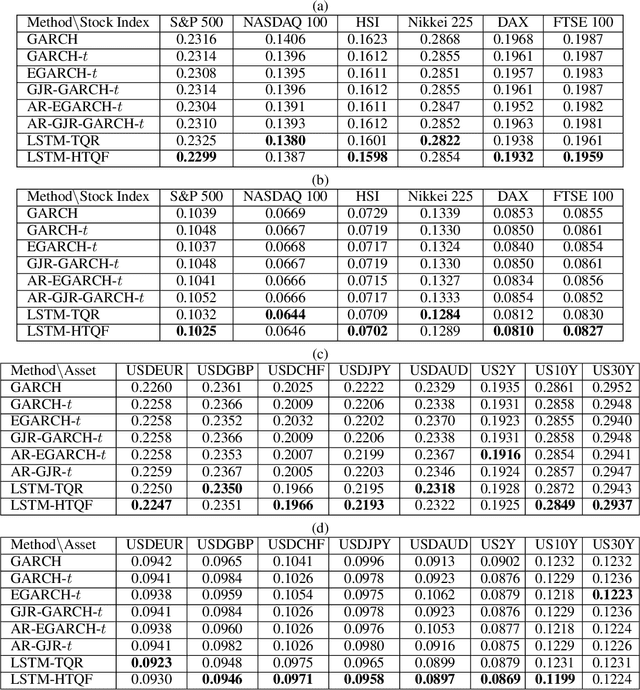
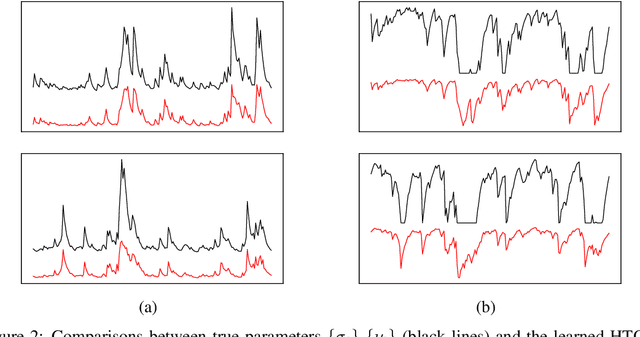
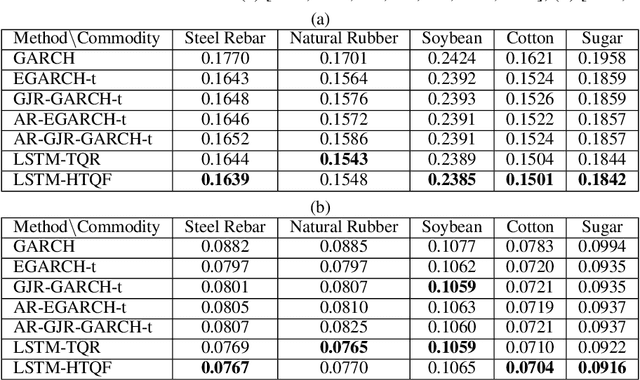
We propose a parsimonious quantile regression framework to learn the dynamic tail behaviors of financial asset returns. Our model captures well both the time-varying characteristic and the asymmetrical heavy-tail property of financial time series. It combines the merits of a popular sequential neural network model, i.e., LSTM, with a novel parametric quantile function that we construct to represent the conditional distribution of asset returns. Our model also captures individually the serial dependences of higher moments, rather than just the volatility. Across a wide range of asset classes, the out-of-sample forecasts of conditional quantiles or VaR of our model outperform the GARCH family. Further, the proposed approach does not suffer from the issue of quantile crossing, nor does it expose to the ill-posedness comparing to the parametric probability density function approach.
Meta-Learned Attribute Self-Gating for Continual Generalized Zero-Shot Learning
Feb 23, 2021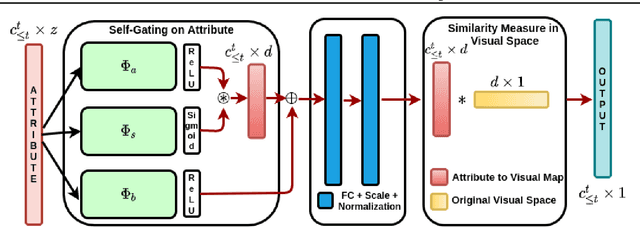
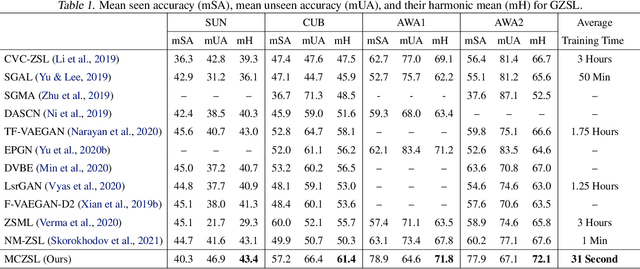
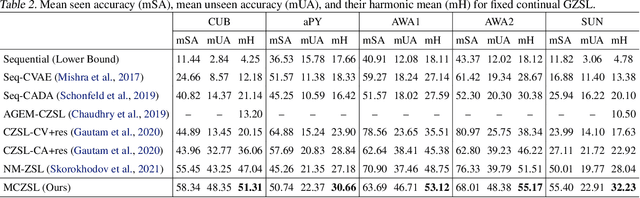
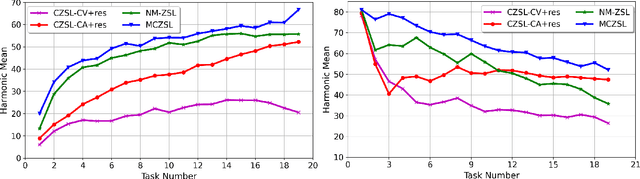
Zero-shot learning (ZSL) has been shown to be a promising approach to generalizing a model to categories unseen during training by leveraging class attributes, but challenges still remain. Recently, methods using generative models to combat bias towards classes seen during training have pushed the state of the art of ZSL, but these generative models can be slow or computationally expensive to train. Additionally, while many previous ZSL methods assume a one-time adaptation to unseen classes, in reality, the world is always changing, necessitating a constant adjustment for deployed models. Models unprepared to handle a sequential stream of data are likely to experience catastrophic forgetting. We propose a meta-continual zero-shot learning (MCZSL) approach to address both these issues. In particular, by pairing self-gating of attributes and scaled class normalization with meta-learning based training, we are able to outperform state-of-the-art results while being able to train our models substantially faster ($>100\times$) than expensive generative-based approaches. We demonstrate this by performing experiments on five standard ZSL datasets (CUB, aPY, AWA1, AWA2 and SUN) in both generalized zero-shot learning and generalized continual zero-shot learning settings.
A Generative Machine Learning Approach to Policy Optimization in Pursuit-Evasion Games
Oct 13, 2020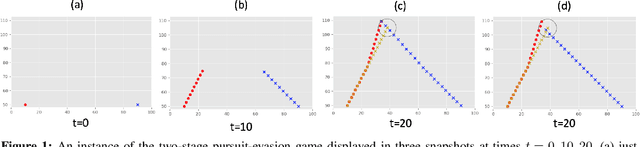
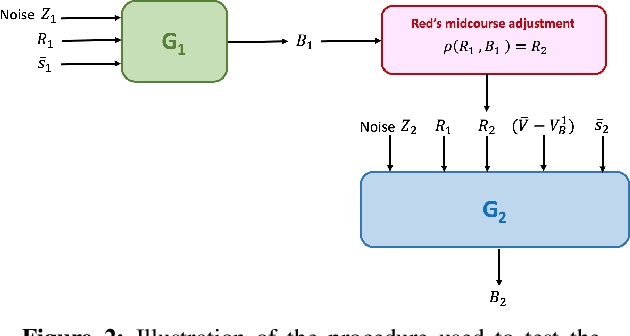
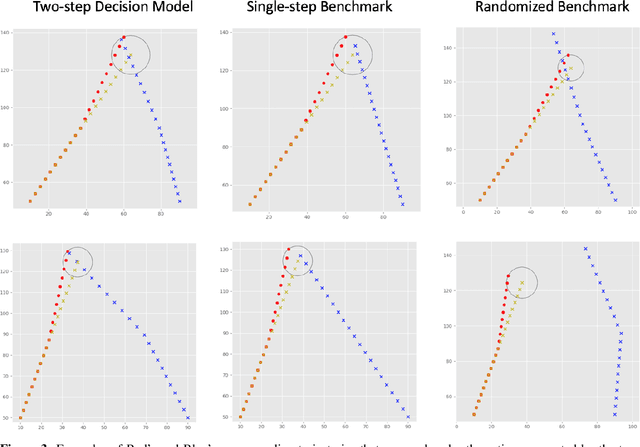
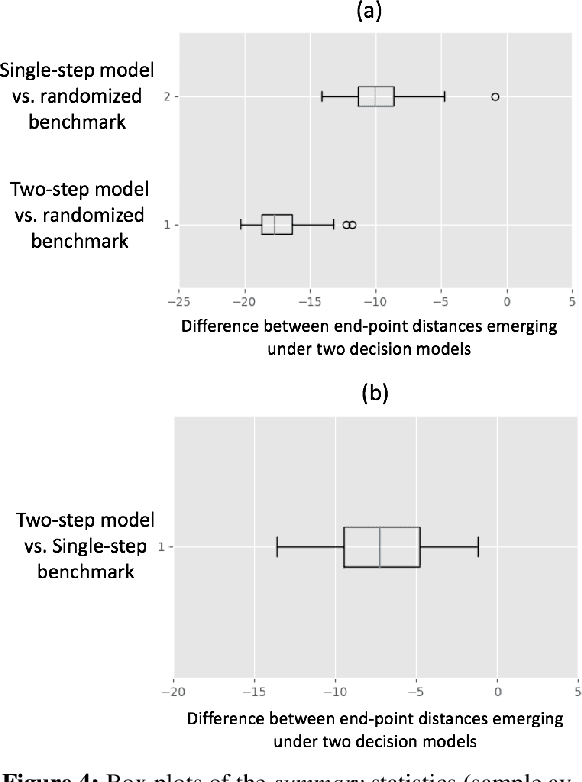
We consider a pursuit-evasion game [11] played between two agents, 'Blue' (the pursuer) and 'Red' (the evader), over $T$ time steps. Red aims to attack Blue's territory. Blue's objective is to intercept Red by time $T$ and thereby limit the success of Red's attack. Blue must plan its pursuit trajectory by choosing parameters that determine its course of movement (speed and angle in our setup) such that it intercepts Red by time $T$. We show that Blue's path-planning problem in pursuing Red, can be posed as a sequential decision making problem under uncertainty. Blue's unawareness of Red's action policy renders the analytic dynamic programming approach intractable for finding the optimal action policy for Blue. In this work, we are interested in exploring data-driven approaches to the policy optimization problem that Blue faces. We apply generative machine learning (ML) approaches to learn optimal action policies for Blue. This highlights the ability of generative ML model to learn the relevant implicit representations for the dynamics of simulated pursuit-evasion games. We demonstrate the effectiveness of our modeling approach via extensive statistical assessments. This work can be viewed as a preliminary step towards further adoption of generative modeling approaches for addressing policy optimization problems that arise in the context of multi-agent learning and planning [1].