 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Scoring for Machine Learning Classifier Error Impact Evaluation
Aug 06, 2025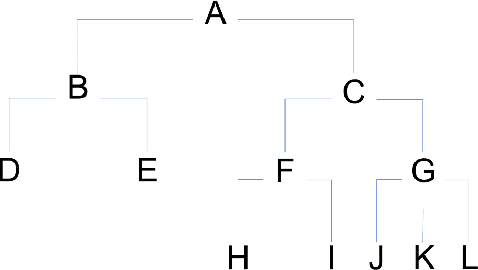
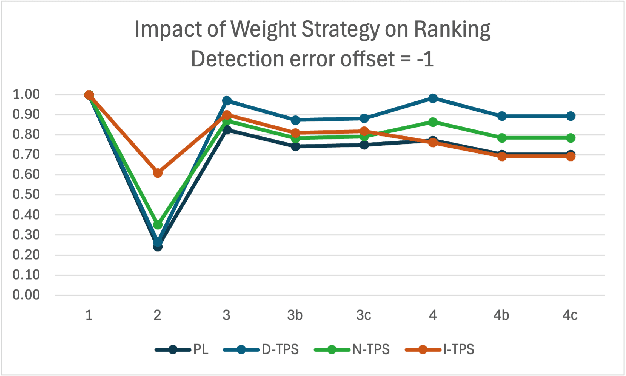
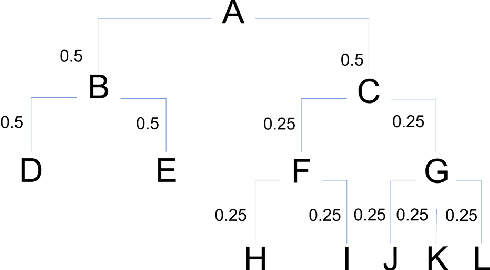
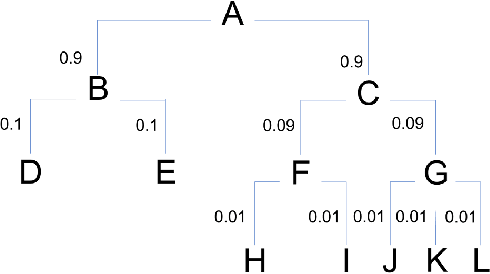
A common use of machine learning (ML) models is predicting the class of a sample. Object detection is an extension of classification that includes localization of the object via a bounding box within the sample. Classification, and by extension object detection, is typically evaluated by counting a prediction as incorrect if the predicted label does not match the ground truth label. This pass/fail scoring treats all misclassifications as equivalent. In many cases, class labels can be organized into a class taxonomy with a hierarchical structure to either reflect relationships among the data or operator valuation of misclassifications. When such a hierarchical structure exists, hierarchical scoring metrics can return the model performance of a given prediction related to the distance between the prediction and the ground truth label. Such metrics can be viewed as giving partial credit to predictions instead of pass/fail, enabling a finer-grained understanding of the impact of misclassifications. This work develops hierarchical scoring metrics varying in complexity that utilize scoring trees to encode relationships between class labels and produce metrics that reflect distance in the scoring tree. The scoring metrics are demonstrated on an abstract use case with scoring trees that represent three weighting strategies and evaluated by the kind of errors discouraged. Results demonstrate that these metrics capture errors with finer granularity and the scoring trees enable tuning. This work demonstrates an approach to evaluating ML performance that ranks models not only by how many errors are made but by the kind or impact of errors. Python implementations of the scoring metrics will be available in an open-source repository at time of publication.
Test & Evaluation Best Practices for Machine Learning-Enabled Systems
Oct 10, 2023

Machine learning (ML) - based software systems are rapidly gaining adoption across various domains, making it increasingly essential to ensure they perform as intended. This report presents best practices for the Test and Evaluation (T&E) of ML-enabled software systems across its lifecycle. We categorize the lifecycle of ML-enabled software systems into three stages: component, integration and deployment, and post-deployment. At the component level, the primary objective is to test and evaluate the ML model as a standalone component. Next, in the integration and deployment stage, the goal is to evaluate an integrated ML-enabled system consisting of both ML and non-ML components. Finally, once the ML-enabled software system is deployed and operationalized, the T&E objective is to ensure the system performs as intended. Maintenance activities for ML-enabled software systems span the lifecycle and involve maintaining various assets of ML-enabled software systems. Given its unique characteristics, the T&E of ML-enabled software systems is challenging. While significant research has been reported on T&E at the component level, limited work is reported on T&E in the remaining two stages. Furthermore, in many cases, there is a lack of systematic T&E strategies throughout the ML-enabled system's lifecycle. This leads practitioners to resort to ad-hoc T&E practices, which can undermine user confidence in the reliability of ML-enabled software systems. New systematic testing approaches, adequacy measurements, and metrics are required to address the T&E challenges across all stages of the ML-enabled system lifecycle.
Evaluating Automated Driving Planner Robustness against Adversarial Influence
May 29, 2022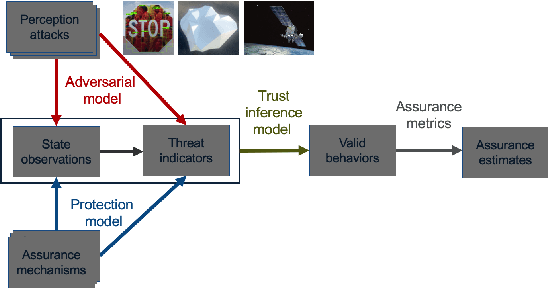

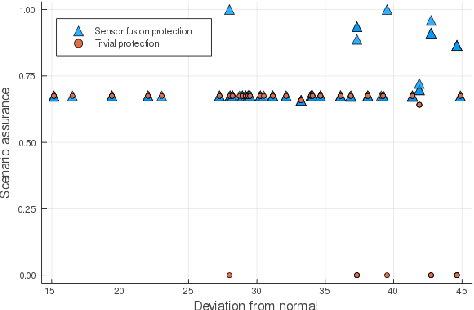

Evaluating the robustness of automated driving planners is a critical and challenging task. Although methodologies to evaluate vehicles are well established, they do not yet account for a reality in which vehicles with autonomous components share the road with adversarial agents. Our approach, based on probabilistic trust models, aims to help researchers assess the robustness of protections for machine learning-enabled planners against adversarial influence. In contrast with established practices that evaluate safety using the same evaluation dataset for all vehicles, we argue that adversarial evaluation fundamentally requires a process that seeks to defeat a specific protection. Hence, we propose that evaluations be based on estimating the difficulty for an adversary to determine conditions that effectively induce unsafe behavior. This type of inference requires precise statements about threats, protections, and aspects of planning decisions to be guarded. We demonstrate our approach by evaluating protections for planners relying on camera-based object detectors.
Systematic Training and Testing for Machine Learning Using Combinatorial Interaction Testing
Jan 28, 2022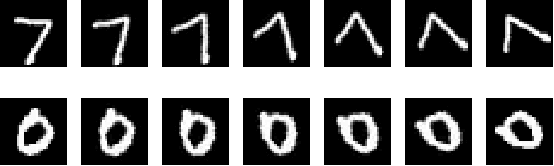
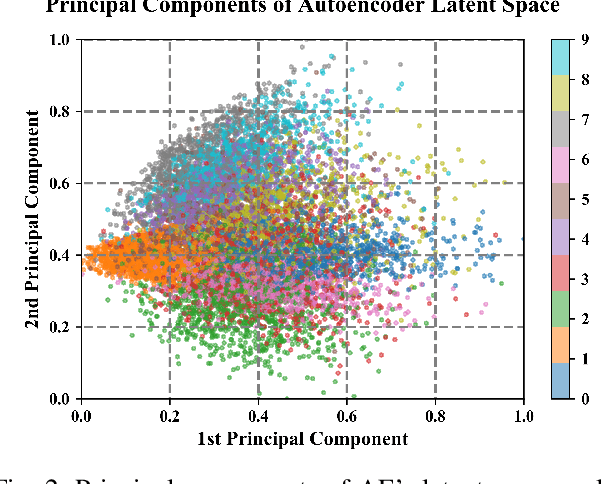
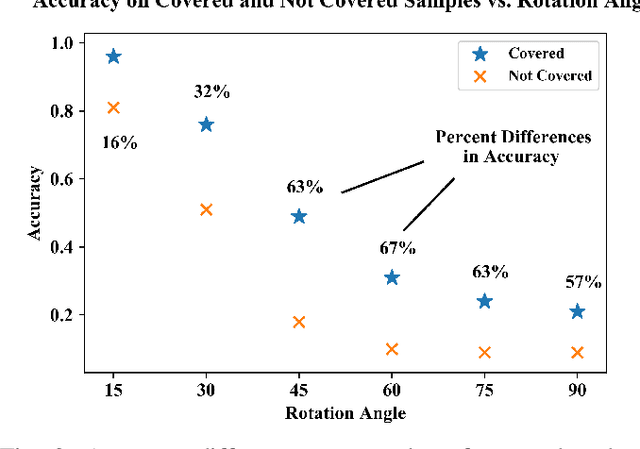
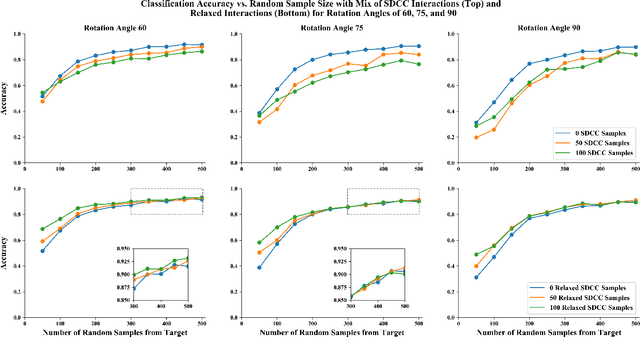
This paper demonstrates the systematic use of combinatorial coverage for selecting and characterizing test and training sets for machine learning models. The presented work adapts combinatorial interaction testing, which has been successfully leveraged in identifying faults in software testing, to characterize data used in machine learning. The MNIST hand-written digits data is used to demonstrate that combinatorial coverage can be used to select test sets that stress machine learning model performance, to select training sets that lead to robust model performance, and to select data for fine-tuning models to new domains. Thus, the results posit combinatorial coverage as a holistic approach to training and testing for machine learning. In contrast to prior work which has focused on the use of coverage in regard to the internal of neural networks, this paper considers coverage over simple features derived from inputs and outputs. Thus, this paper addresses the case where the supplier of test and training sets for machine learning models does not have intellectual property rights to the models themselves. Finally, the paper addresses prior criticism of combinatorial coverage and provides a rebuttal which advocates the use of coverage metrics in machine learning applications.
Test and Evaluation Framework for Multi-Agent Systems of Autonomous Intelligent Agents
Jan 25, 2021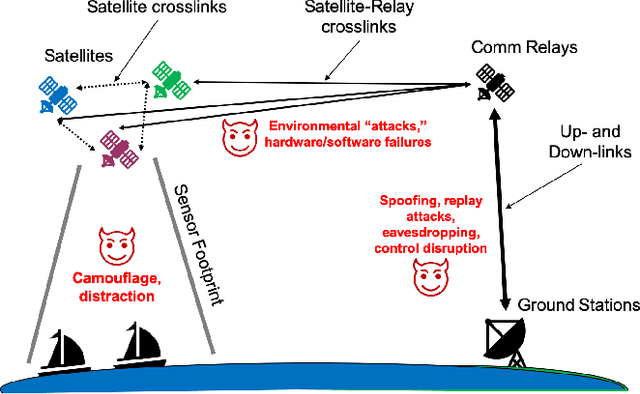
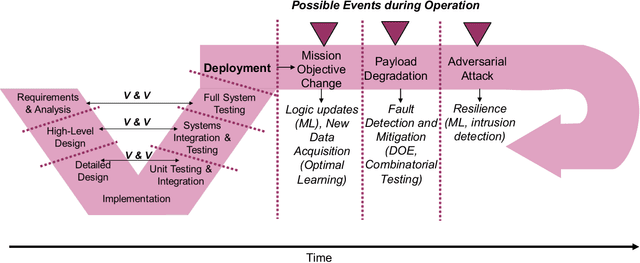
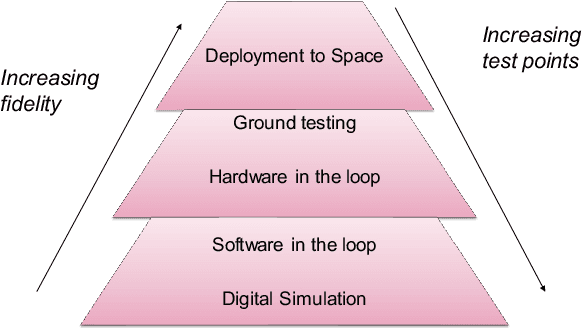
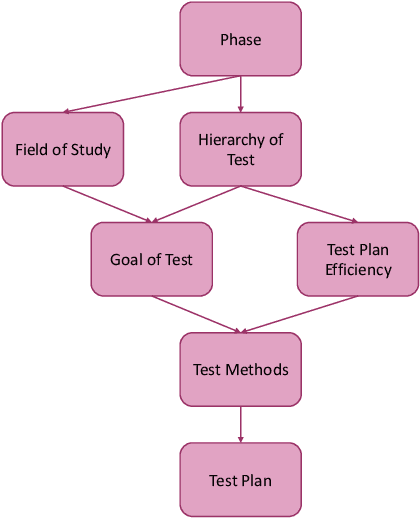
Test and evaluation is a necessary process for ensuring that engineered systems perform as intended under a variety of conditions, both expected and unexpected. In this work, we consider the unique challenges of developing a unifying test and evaluation framework for complex ensembles of cyber-physical systems with embedded artificial intelligence. We propose a framework that incorporates test and evaluation throughout not only the development life cycle, but continues into operation as the system learns and adapts in a noisy, changing, and contended environment. The framework accounts for the challenges of testing the integration of diverse systems at various hierarchical scales of composition while respecting that testing time and resources are limited. A generic use case is provided for illustrative purposes and research directions emerging as a result of exploring the use case via the framework are suggested.