 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Combining Similarity and Adversarial Learning to Generate Visual Explanation: Application to Medical Image Classification
Dec 14, 2020
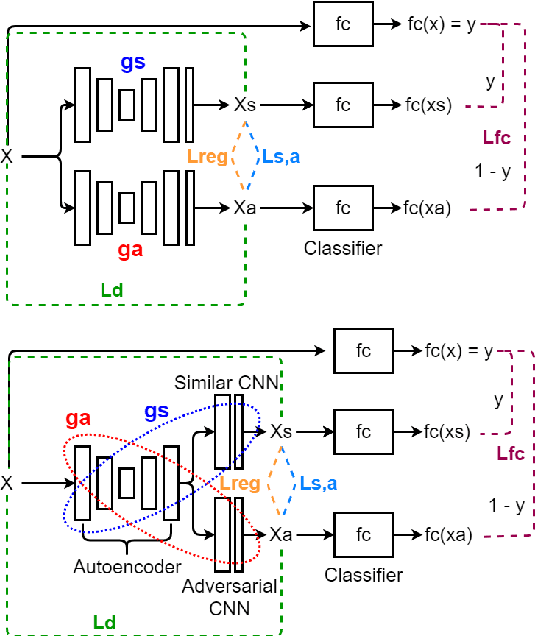
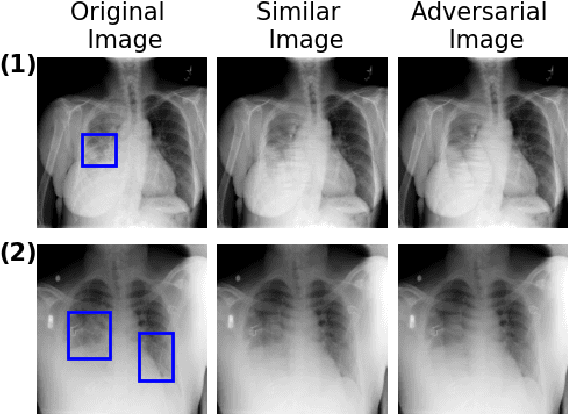
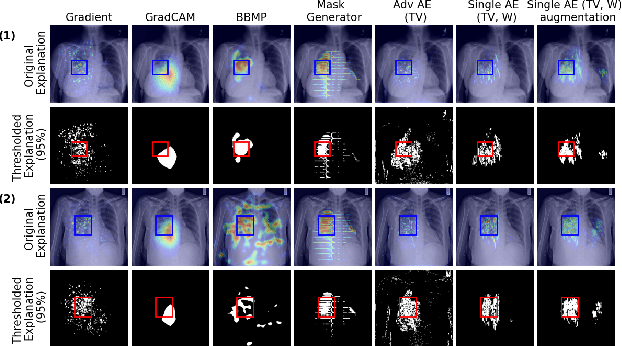

Explaining decisions of black-box classifiers is paramount in sensitive domains such as medical imaging since clinicians confidence is necessary for adoption. Various explanation approaches have been proposed, among which perturbation based approaches are very promising. Within this class of methods, we leverage a learning framework to produce our visual explanations method. From a given classifier, we train two generators to produce from an input image the so called similar and adversarial images. The similar image shall be classified as the input image whereas the adversarial shall not. Visual explanation is built as the difference between these two generated images. Using metrics from the literature, our method outperforms state-of-the-art approaches. The proposed approach is model-agnostic and has a low computation burden at prediction time. Thus, it is adapted for real-time systems. Finally, we show that random geometric augmentations applied to the original image play a regularization role that improves several previously proposed explanation methods. We validate our approach on a large chest X-ray database.
HandTailor: Towards High-Precision Monocular 3D Hand Recovery
Feb 18, 2021
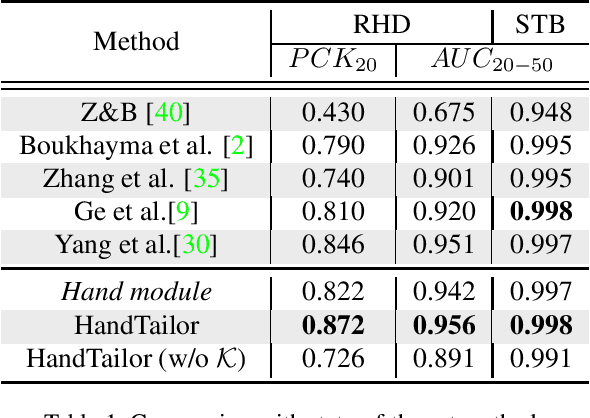
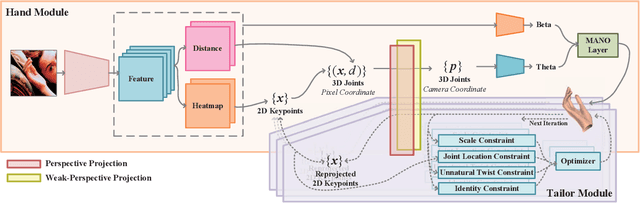
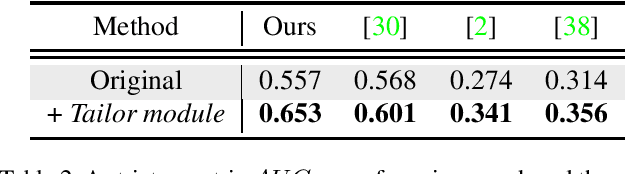
3D hand pose estimation and shape recovery are challenging tasks in computer vision. We introduce a novel framework HandTailor, which combines a learning-based hand module and an optimization-based tailor module to achieve high-precision hand mesh recovery from a monocular RGB image. The proposed hand module unifies perspective projection and weak perspective projection in a single network towards accuracy-oriented and in-the-wild scenarios. The proposed tailor module then utilizes the coarsely reconstructed mesh model provided by the hand module as initialization, and iteratively optimizes an energy function to obtain better results. The tailor module is time-efficient, costs only 8ms per frame on a modern CPU. We demonstrate that HandTailor can get state-of-the-art performance on several public benchmarks, with impressive qualitative results on in-the-wild experiments.
Spillover Algorithm: A Decentralized Coordination Approach for Multi-Robot Production Planning in Open Shared Factories
Jan 23, 2021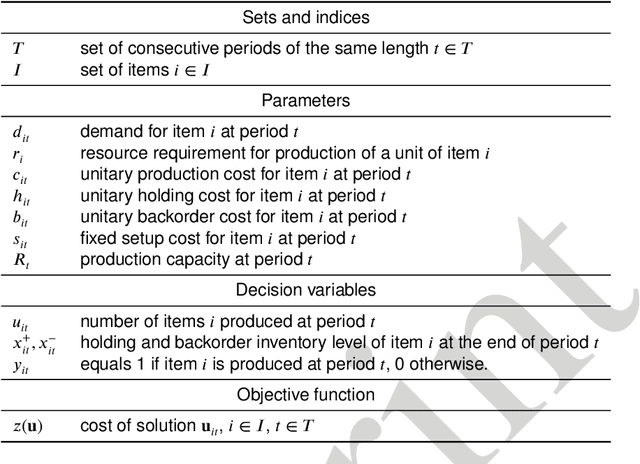
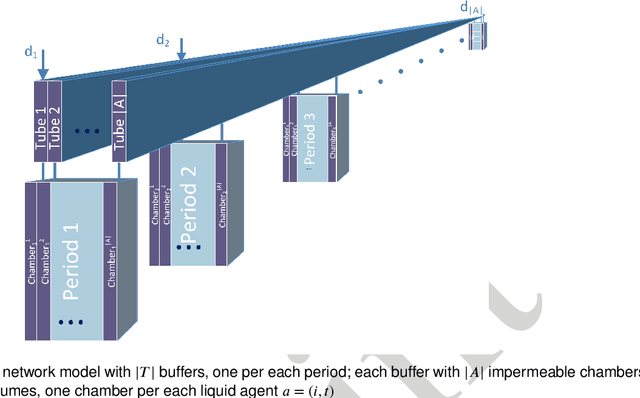

Open and shared manufacturing factories typically dispose of a limited number of robots that should be properly allocated to tasks in time and space for an effective and efficient system performance. In particular, we deal with the dynamic capacitated production planning problem with sequence independent setup costs where quantities of products to manufacture and location of robots need to be determined at consecutive periods within a given time horizon and products can be anticipated or backordered related to the demand period. We consider a decentralized multi-agent variant of this problem in an open factory setting with multiple owners of robots as well as different owners of the items to be produced, both considered self-interested and individually rational. Existing solution approaches to the classic constrained lot-sizing problem are centralized exact methods that require sharing of global knowledge of all the participants' private and sensitive information and are not applicable in the described multi-agent context. Therefore, we propose a computationally efficient decentralized approach based on the spillover effect that solves this NP-hard problem by distributing decisions in an intrinsically decentralized multi-agent system environment while protecting private and sensitive information. To the best of our knowledge, this is the first decentralized algorithm for the solution of the studied problem in intrinsically decentralized environments where production resources and/or products are owned by multiple stakeholders with possibly conflicting objectives. To show its efficiency, the performance of the Spillover Algorithm is benchmarked against state-of-the-art commercial solver CPLEX 12.8.
Near Real-Time Data Labeling Using a Depth Sensor for EMG Based Prosthetic Arms
Nov 10, 2018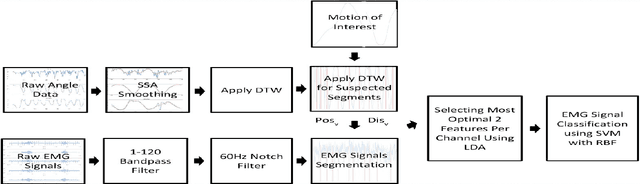
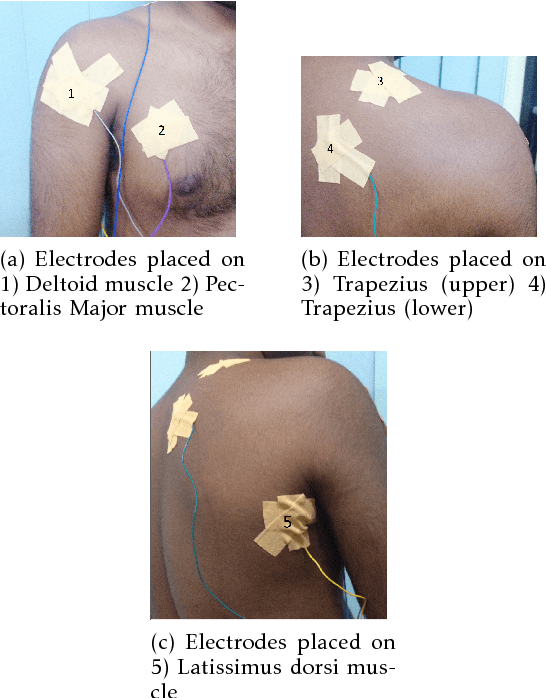
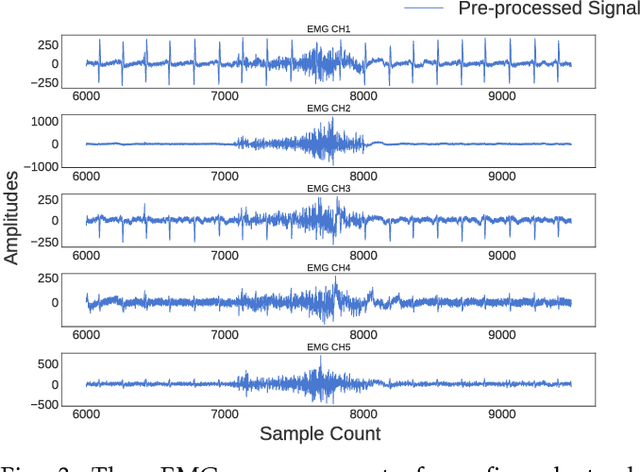
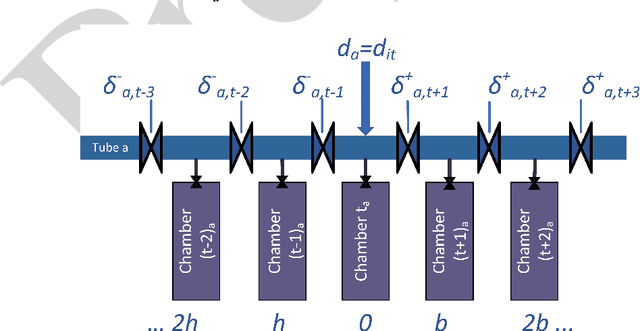
Recognizing sEMG (Surface Electromyography) signals belonging to a particular action (e.g., lateral arm raise) automatically is a challenging task as EMG signals themselves have a lot of variation even for the same action due to several factors. To overcome this issue, there should be a proper separation which indicates similar patterns repetitively for a particular action in raw signals. A repetitive pattern is not always matched because the same action can be carried out with different time duration. Thus, a depth sensor (Kinect) was used for pattern identification where three joint angles were recording continuously which is clearly separable for a particular action while recording sEMG signals. To Segment out a repetitive pattern in angle data, MDTW (Moving Dynamic Time Warping) approach is introduced. This technique is allowed to retrieve suspected motion of interest from raw signals. MDTW based on DTW algorithm, but it will be moving through the whole dataset in a pre-defined manner which is capable of picking up almost all the suspected segments inside a given dataset an optimal way. Elevated bicep curl and lateral arm raise movements are taken as motions of interest to show how the proposed technique can be employed to achieve auto identification and labelling. The full implementation is available at https://github.com/GPrathap/OpenBCIPython
Real-Time Fruit Recognition and Grasping Estimation for Autonomous Apple Harvesting
Apr 05, 2020

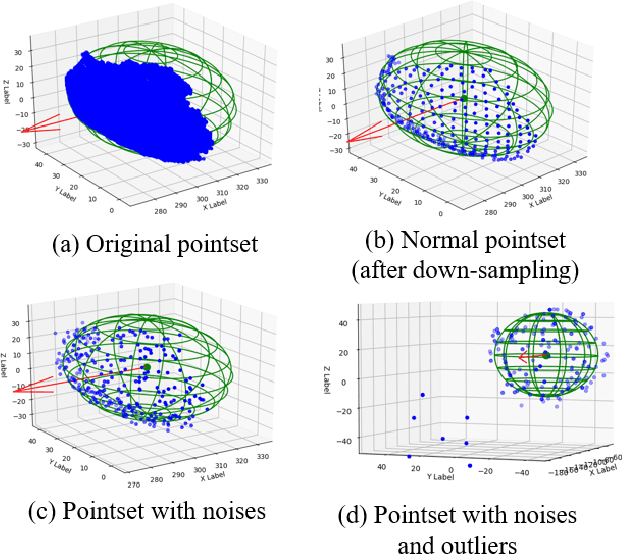

In this research, a fully neural network based visual perception framework for autonomous apple harvesting is proposed. The proposed framework includes a multi-function neural network for fruit recognition and a Pointnet grasp estimation to determine the proper grasp pose to guide the robotic execution. Fruit recognition takes raw input of RGB images from the RGB-D camera to perform fruit detection and instance segmentation, and Pointnet grasp estimation take point cloud of each fruit as input and output the prediction of grasp pose for each of fruits. The proposed framework is validated by using RGB-D images collected from laboratory and orchard environments, a robotic grasping test in a controlled environment is also included in the experiments. Experimental shows that the proposed framework can accurately localise and estimate the grasp pose for robotic grasping.
Listening to Sounds of Silence for Speech Denoising
Oct 22, 2020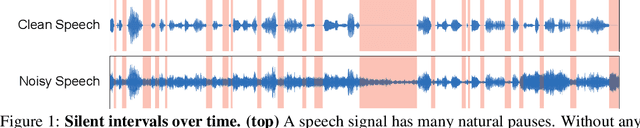
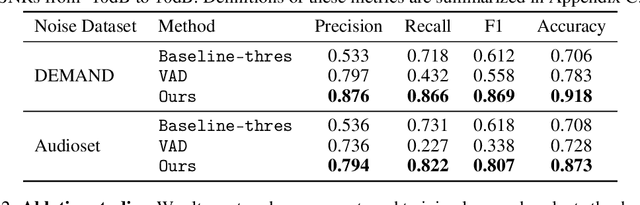
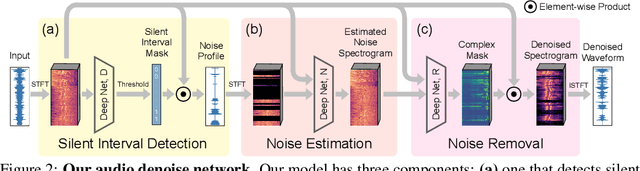
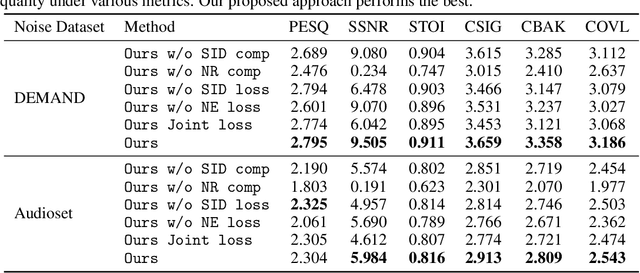
We introduce a deep learning model for speech denoising, a long-standing challenge in audio analysis arising in numerous applications. Our approach is based on a key observation about human speech: there is often a short pause between each sentence or word. In a recorded speech signal, those pauses introduce a series of time periods during which only noise is present. We leverage these incidental silent intervals to learn a model for automatic speech denoising given only mono-channel audio. Detected silent intervals over time expose not just pure noise but its time-varying features, allowing the model to learn noise dynamics and suppress it from the speech signal. Experiments on multiple datasets confirm the pivotal role of silent interval detection for speech denoising, and our method outperforms several state-of-the-art denoising methods, including those that accept only audio input (like ours) and those that denoise based on audiovisual input (and hence require more information). We also show that our method enjoys excellent generalization properties, such as denoising spoken languages not seen during training.
Domain Generalization: A Survey
Mar 31, 2021



Generalization to out-of-distribution (OOD) data is a capability natural to humans yet challenging for machines to reproduce. This is because most statistical learning algorithms strongly rely on the i.i.d.~assumption on source/target data, while in practice domain shift between source and target is common. Domain generalization (DG) aims to achieve OOD generalization by using only source data for model learning. Since first introduced in 2011, research in DG has made great progresses. In particular, intensive research in this topic has led to a broad spectrum of methodologies, e.g., those based on domain alignment, meta-learning, data augmentation, or ensemble learning, just to name a few; and has covered various applications such as object recognition, segmentation, action recognition, and person re-identification. In this paper, for the first time, a comprehensive literature review is provided to summarize the developments in DG in the past decade. Specifically, we first cover the background by formally defining DG and relating it to other research fields like domain adaptation and transfer learning. Second, we conduct a thorough review into existing methods and present a categorization based on their methodologies and motivations. Finally, we conclude this survey with insights and discussions on future research directions.
Multi-Discriminator Sobolev Defense-GAN Against Adversarial Attacks for End-to-End Speech Systems
Mar 15, 2021

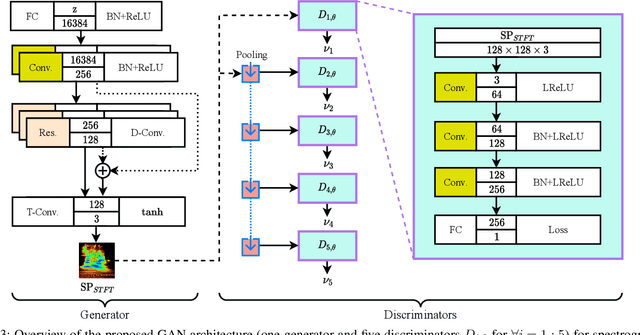
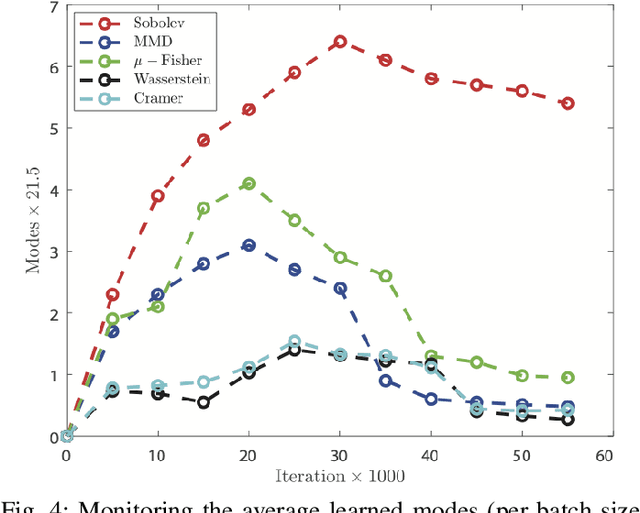
This paper introduces a defense approach against end-to-end adversarial attacks developed for cutting-edge speech-to-text systems. The proposed defense algorithm has four major steps. First, we represent speech signals with 2D spectrograms using the short-time Fourier transform. Second, we iteratively find a safe vector using a spectrogram subspace projection operation. This operation minimizes the chordal distance adjustment between spectrograms with an additional regularization term. Third, we synthesize a spectrogram with such a safe vector using a novel GAN architecture trained with Sobolev integral probability metric. To improve the model's performance in terms of stability and the total number of learned modes, we impose an additional constraint on the generator network. Finally, we reconstruct the signal from the synthesized spectrogram and the Griffin-Lim phase approximation technique. We evaluate the proposed defense approach against six strong white and black-box adversarial attacks benchmarked on DeepSpeech, Kaldi, and Lingvo models. Our experimental results show that our algorithm outperforms other state-of-the-art defense algorithms both in terms of accuracy and signal quality.
Efficient and Scalable Structure Learning for Bayesian Networks: Algorithms and Applications
Dec 07, 2020


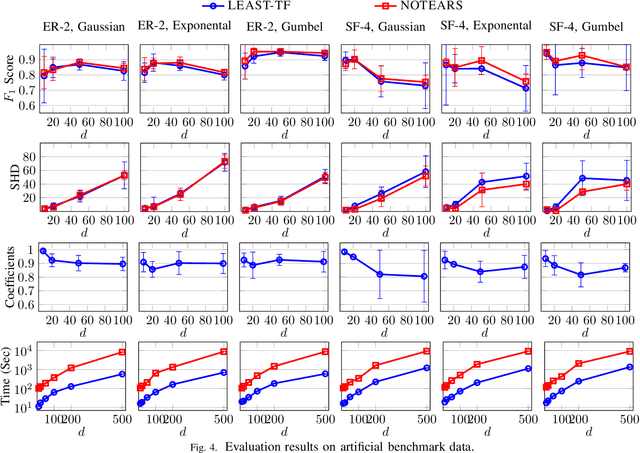
Structure Learning for Bayesian network (BN) is an important problem with extensive research. It plays central roles in a wide variety of applications in Alibaba Group. However, existing structure learning algorithms suffer from considerable limitations in real world applications due to their low efficiency and poor scalability. To resolve this, we propose a new structure learning algorithm LEAST, which comprehensively fulfills our business requirements as it attains high accuracy, efficiency and scalability at the same time. The core idea of LEAST is to formulate the structure learning into a continuous constrained optimization problem, with a novel differentiable constraint function measuring the acyclicity of the resulting graph. Unlike with existing work, our constraint function is built on the spectral radius of the graph and could be evaluated in near linear time w.r.t. the graph node size. Based on it, LEAST can be efficiently implemented with low storage overhead. According to our benchmark evaluation, LEAST runs 1 to 2 orders of magnitude faster than state of the art method with comparable accuracy, and it is able to scale on BNs with up to hundreds of thousands of variables. In our production environment, LEAST is deployed and serves for more than 20 applications with thousands of executions per day. We describe a concrete scenario in a ticket booking service in Alibaba, where LEAST is applied to build a near real-time automatic anomaly detection and root error cause analysis system. We also show that LEAST unlocks the possibility of applying BN structure learning in new areas, such as large-scale gene expression data analysis and explainable recommendation system.
Efficient and Consistent Robust Time Series Analysis
Jul 01, 2016
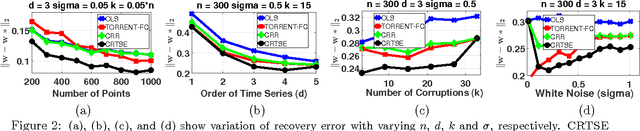
We study the problem of robust time series analysis under the standard auto-regressive (AR) time series model in the presence of arbitrary outliers. We devise an efficient hard thresholding based algorithm which can obtain a consistent estimate of the optimal AR model despite a large fraction of the time series points being corrupted. Our algorithm alternately estimates the corrupted set of points and the model parameters, and is inspired by recent advances in robust regression and hard-thresholding methods. However, a direct application of existing techniques is hindered by a critical difference in the time-series domain: each point is correlated with all previous points rendering existing tools inapplicable directly. We show how to overcome this hurdle using novel proof techniques. Using our techniques, we are also able to provide the first efficient and provably consistent estimator for the robust regression problem where a standard linear observation model with white additive noise is corrupted arbitrarily. We illustrate our methods on synthetic datasets and show that our methods indeed are able to consistently recover the optimal parameters despite a large fraction of points being corrupted.