 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards a Dimension-Free Understanding of Adaptive Linear Control
Mar 19, 2021
We study the problem of adaptive control of the linear quadratic regulator for systems in very high, or even infinite dimension. We demonstrate that while sublinear regret requires finite dimensional inputs, the ambient state dimension of the system need not be bounded in order to perform online control. We provide the first regret bounds for LQR which hold for infinite dimensional systems, replacing dependence on ambient dimension with more natural notions of problem complexity. Our guarantees arise from a novel perturbation bound for certainty equivalence which scales with the prediction error in estimating the system parameters, without requiring consistent parameter recovery in more stringent measures like the operator norm. When specialized to finite dimensional settings, our bounds recover near optimal dimension and time horizon dependence.
Autonomous UAV Exploration of Dynamic Environments via Incremental Sampling and Probabilistic Roadmap
Oct 14, 2020
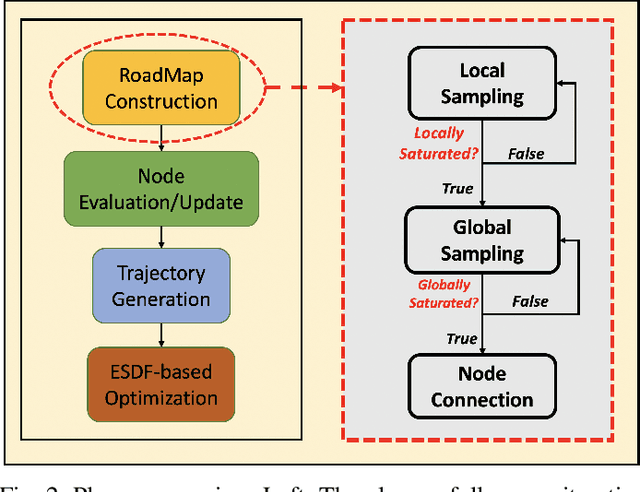
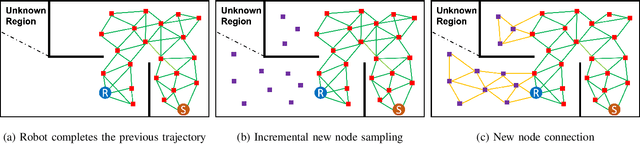
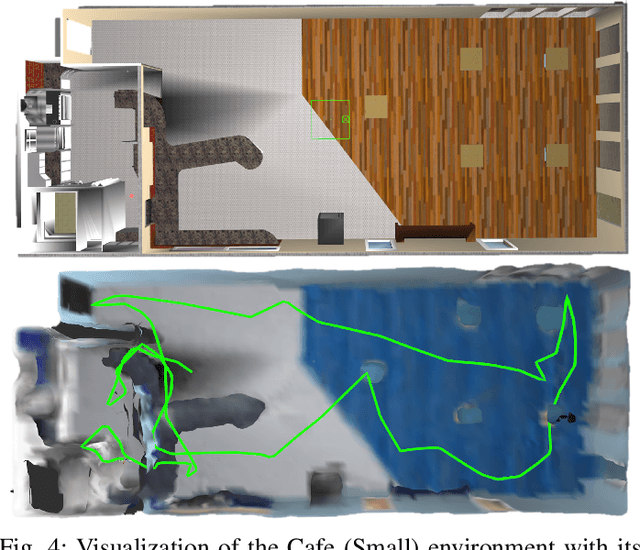
Autonomous exploration requires robots to generate informative trajectories iteratively. Although sampling-based methods are highly efficient in unmanned aerial vehicle exploration, many of these methods do not effectively utilize the sampled information from the previous planning iterations, leading to redundant computation and longer exploration time. Also, few have explicitly shown their exploration ability in dynamic environments even though they can run real-time. To overcome these limitations, we propose a novel dynamic exploration planner (DEP) for exploring unknown environments using incremental sampling and Probabilistic Roadmap (PRM). In our sampling strategy, nodes are added incrementally and distributed evenly in the explored region, yielding the best viewpoints. To further shortening exploration time and ensuring safety, our planner optimizes paths locally and refine it based on the Euclidean Signed Distance Function (ESDF) map. Meanwhile, as the multi-query planner, PRM allows the proposed planner to quickly search alternative paths to avoid dynamic obstacles for safe exploration. Simulation experiments show that our method safely explores dynamic environments and outperforms the frontier-based planner and receding horizon next-best-view planner in terms of exploration time, path length, and computational time.
RTSeg: Real-time Semantic Segmentation Comparative Study
Jun 10, 2018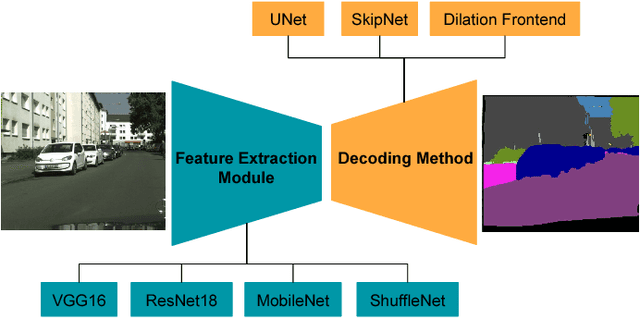
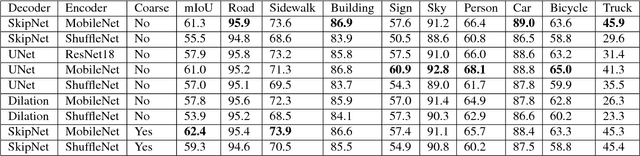
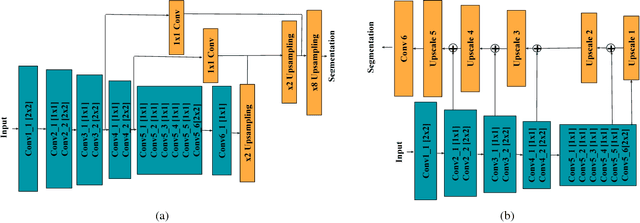

Semantic segmentation benefits robotics related applications especially autonomous driving. Most of the research on semantic segmentation is only on increasing the accuracy of segmentation models with little attention to computationally efficient solutions. The few work conducted in this direction does not provide principled methods to evaluate the different design choices for segmentation. In this paper, we address this gap by presenting a real-time semantic segmentation benchmarking framework with a decoupled design for feature extraction and decoding methods. The framework is comprised of different network architectures for feature extraction such as VGG16, Resnet18, MobileNet, and ShuffleNet. It is also comprised of multiple meta-architectures for segmentation that define the decoding methodology. These include SkipNet, UNet, and Dilation Frontend. Experimental results are presented on the Cityscapes dataset for urban scenes. The modular design allows novel architectures to emerge, that lead to 143x GFLOPs reduction in comparison to SegNet. This benchmarking framework is publicly available at "https://github.com/MSiam/TFSegmentation".
An Equivariant Filter for Visual Inertial Odometry
Apr 08, 2021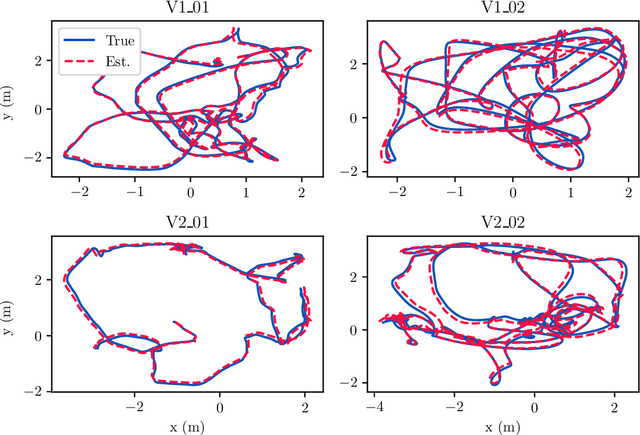
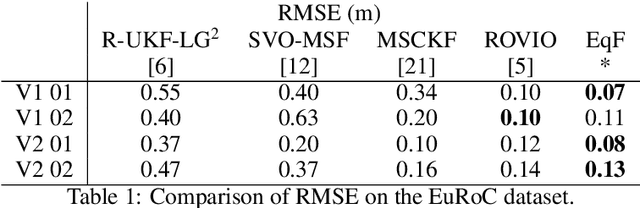
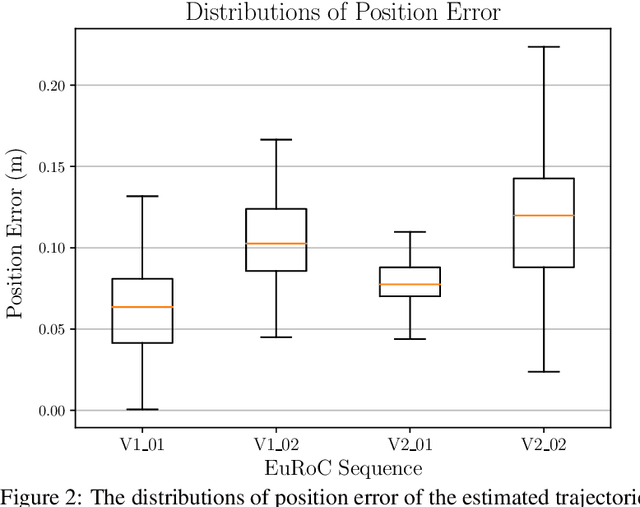
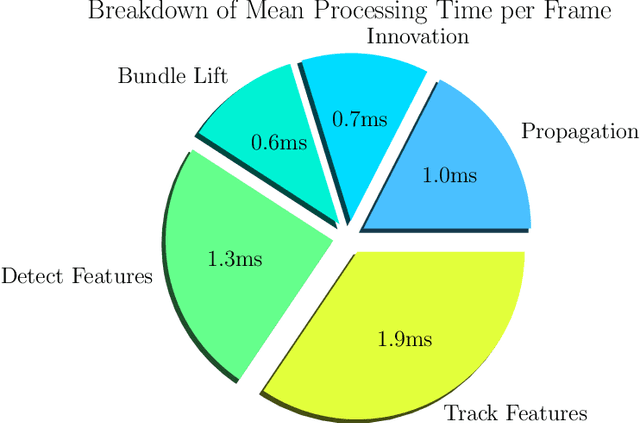
Visual Inertial Odometry (VIO) is of great interest due the ubiquity of devices equipped with both a monocular camera and Inertial Measurement Unit (IMU). Methods based on the extended Kalman Filter remain popular in VIO due to their low memory requirements, CPU usage, and processing time when compared to optimisation-based methods. In this paper, we analyse the VIO problem from a geometric perspective and propose a novel formulation on a smooth quotient manifold where the equivalence relationship is the well-known invariance of VIO to choice of reference frame. We propose a novel Lie group that acts transitively on this manifold and is compatible with the visual measurements. This structure allows for the application of Equivariant Filter (EqF) design leading to a novel filter for the VIO problem. Combined with a very simple vision processing front-end, the proposed filter demonstrates state-of-the-art performance on the EuRoC dataset compared to other EKF-based VIO algorithms.
Locally Private $k$-Means Clustering with Constant Multiplicative Approximation and Near-Optimal Additive Error
May 31, 2021

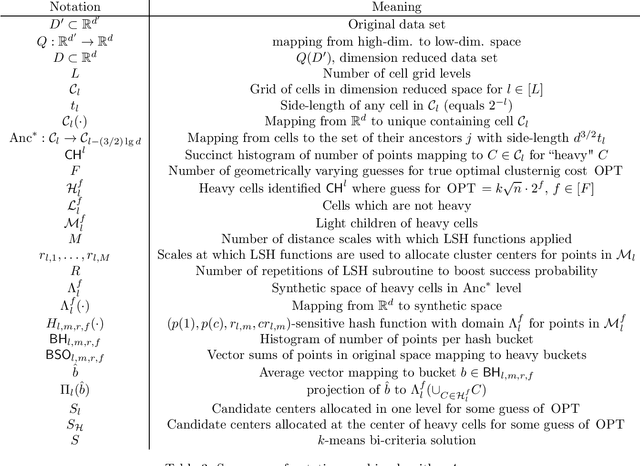
Given a data set of size $n$ in $d'$-dimensional Euclidean space, the $k$-means problem asks for a set of $k$ points (called centers) so that the sum of the $\ell_2^2$-distances between points of a given data set of size $n$ and the set of $k$ centers is minimized. Recent work on this problem in the locally private setting achieves constant multiplicative approximation with additive error $\tilde{O} (n^{1/2 + a} \cdot k \cdot \max \{\sqrt{d}, \sqrt{k} \})$ and proves a lower bound of $\Omega(\sqrt{n})$ on the additive error for any solution with a constant number of rounds. In this work we bridge the gap between the exponents of $n$ in the upper and lower bounds on the additive error with two new algorithms. Given any $\alpha>0$, our first algorithm achieves a multiplicative approximation guarantee which is at most a $(1+\alpha)$ factor greater than that of any non-private $k$-means clustering algorithm with $k^{\tilde{O}(1/\alpha^2)} \sqrt{d' n} \mbox{poly}\log n$ additive error. Given any $c>\sqrt{2}$, our second algorithm achieves $O(k^{1 + \tilde{O}(1/(2c^2-1))} \sqrt{d' n} \mbox{poly} \log n)$ additive error with constant multiplicative approximation. Both algorithms go beyond the $\Omega(n^{1/2 + a})$ factor that occurs in the additive error for arbitrarily small parameters $a$ in previous work, and the second algorithm in particular shows for the first time that it is possible to solve the locally private $k$-means problem in a constant number of rounds with constant factor multiplicative approximation and polynomial dependence on $k$ in the additive error arbitrarily close to linear.
MMBERT: Multimodal BERT Pretraining for Improved Medical VQA
Apr 03, 2021

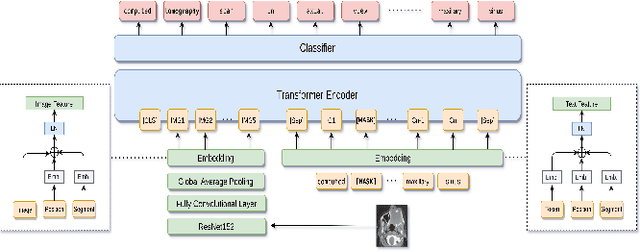
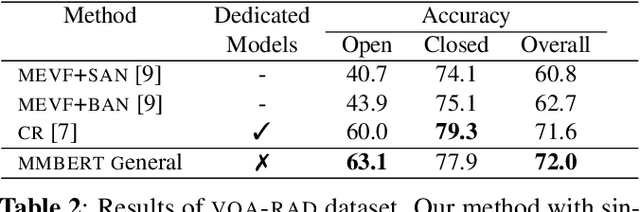
Images in the medical domain are fundamentally different from the general domain images. Consequently, it is infeasible to directly employ general domain Visual Question Answering (VQA) models for the medical domain. Additionally, medical images annotation is a costly and time-consuming process. To overcome these limitations, we propose a solution inspired by self-supervised pretraining of Transformer-style architectures for NLP, Vision and Language tasks. Our method involves learning richer medical image and text semantic representations using Masked Language Modeling (MLM) with image features as the pretext task on a large medical image+caption dataset. The proposed solution achieves new state-of-the-art performance on two VQA datasets for radiology images -- VQA-Med 2019 and VQA-RAD, outperforming even the ensemble models of previous best solutions. Moreover, our solution provides attention maps which help in model interpretability. The code is available at https://github.com/VirajBagal/MMBERT
Detecting Nonlinear Causality in Multivariate Time Series with Sparse Additive Models
Apr 26, 2018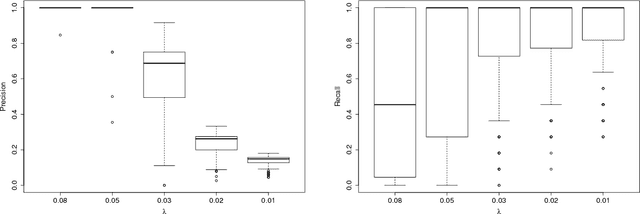
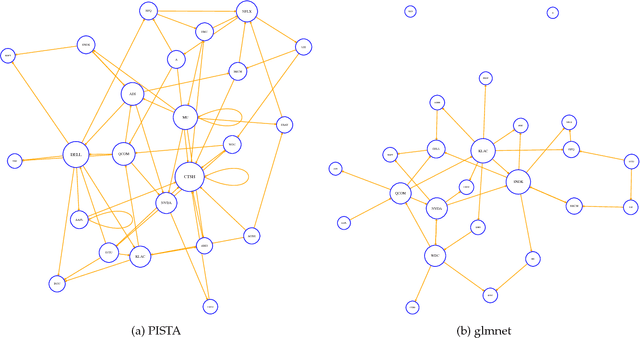
We propose a nonparametric method for detecting nonlinear causal relationship within a set of multidimensional discrete time series, by using sparse additive models (SpAMs). We show that, when the input to the SpAM is a $\beta$-mixing time series, the model can be fitted by first approximating each unknown function with a linear combination of a set of B-spline bases, and then solving a group-lasso-type optimization problem with nonconvex regularization. Theoretically, we characterize the oracle statistical properties of the proposed sparse estimator in function estimation and model selection. Numerically, we propose an efficient pathwise iterative shrinkage thresholding algorithm (PISTA), which tames the nonconvexity and guarantees linear convergence towards the desired sparse estimator with high probability.
Precarity: Modeling the Long Term Effects of Compounded Decisions on Individual Instability
Apr 24, 2021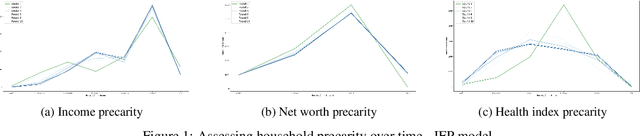
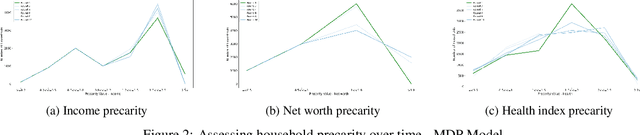
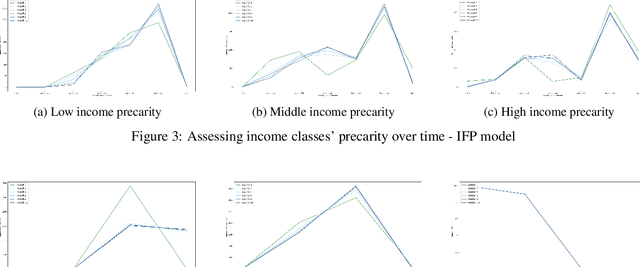
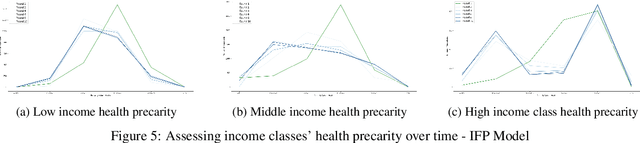
When it comes to studying the impacts of decision making, the research has been largely focused on examining the fairness of the decisions, the long-term effects of the decision pipelines, and utility-based perspectives considering both the decision-maker and the individuals. However, there has hardly been any focus on precarity which is the term that encapsulates the instability in people's lives. That is, a negative outcome can overspread to other decisions and measures of well-being. Studying precarity necessitates a shift in focus - from the point of view of the decision-maker to the perspective of the decision subject. This centering of the subject is an important direction that unlocks the importance of parting with aggregate measures to examine the long-term effects of decision making. To address this issue, in this paper, we propose a modeling framework that simulates the effects of compounded decision-making on precarity over time. Through our simulations, we are able to show the heterogeneity of precarity by the non-uniform ruinous aftereffects of negative decisions on different income classes of the underlying population and how policy interventions can help mitigate such effects.
An iterative K-FAC algorithm for Deep Learning
Jan 01, 2021Kronecker-factored Approximate Curvature (K-FAC) method is a high efficiency second order optimizer for the deep learning. Its training time is less than SGD(or other first-order method) with same accuracy in many large-scale problems. The key of K-FAC is to approximates Fisher information matrix (FIM) as a block-diagonal matrix where each block is an inverse of tiny Kronecker factors. In this short note, we present CG-FAC -- an new iterative K-FAC algorithm. It uses conjugate gradient method to approximate the nature gradient. This CG-FAC method is matrix-free, that is, no need to generate the FIM matrix, also no need to generate the Kronecker factors A and G. We prove that the time and memory complexity of iterative CG-FAC is much less than that of standard K-FAC algorithm.
UCT: Learning Unified Convolutional Networks for Real-time Visual Tracking
Nov 10, 2017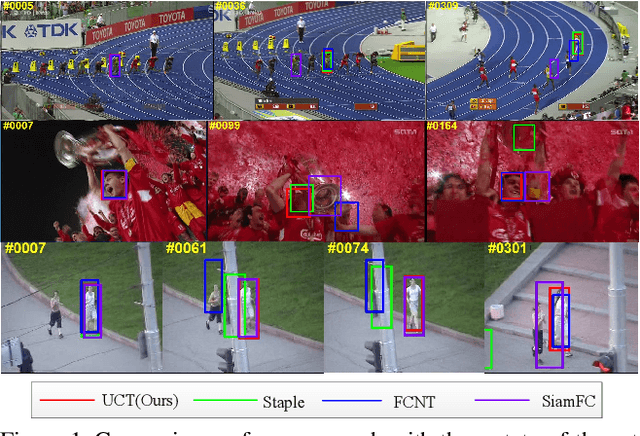
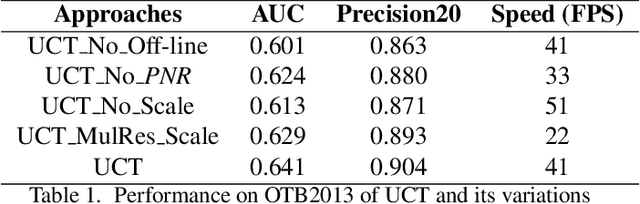
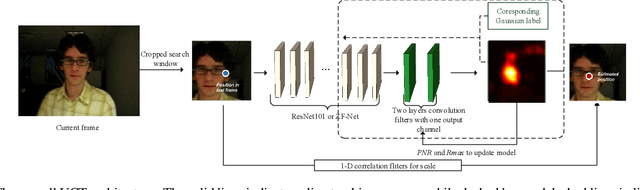

Convolutional neural networks (CNN) based tracking approaches have shown favorable performance in recent benchmarks. Nonetheless, the chosen CNN features are always pre-trained in different task and individual components in tracking systems are learned separately, thus the achieved tracking performance may be suboptimal. Besides, most of these trackers are not designed towards real-time applications because of their time-consuming feature extraction and complex optimization details.In this paper, we propose an end-to-end framework to learn the convolutional features and perform the tracking process simultaneously, namely, a unified convolutional tracker (UCT). Specifically, The UCT treats feature extractor and tracking process both as convolution operation and trains them jointly, enabling learned CNN features are tightly coupled to tracking process. In online tracking, an efficient updating method is proposed by introducing peak-versus-noise ratio (PNR) criterion, and scale changes are handled efficiently by incorporating a scale branch into network. The proposed approach results in superior tracking performance, while maintaining real-time speed. The standard UCT and UCT-Lite can track generic objects at 41 FPS and 154 FPS without further optimization, respectively. Experiments are performed on four challenging benchmark tracking datasets: OTB2013, OTB2015, VOT2014 and VOT2015, and our method achieves state-of-the-art results on these benchmarks compared with other real-time trackers.