 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recursive Contour Saliency Blending Network for Accurate Salient Object Detection
May 31, 2021
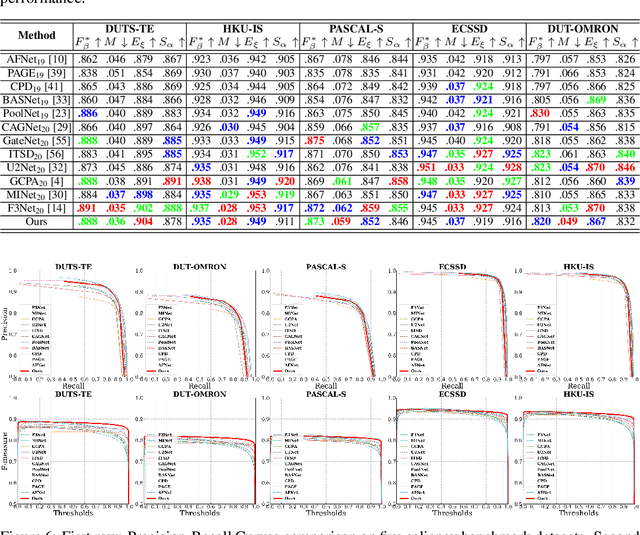
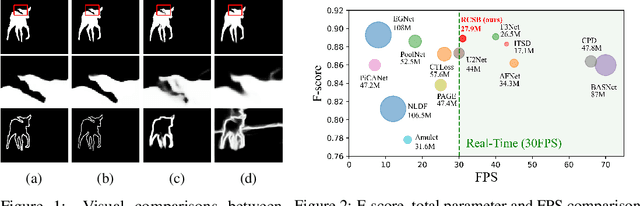
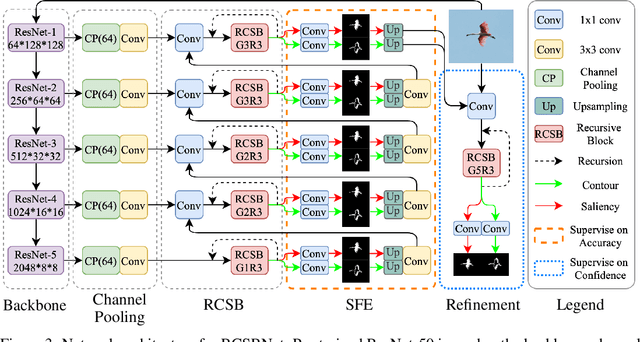
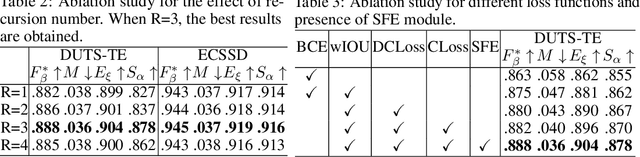
Contour information plays a vital role in salient object detection. However, excessive false positives remain in predictions from existing contour-based models due to insufficient contour-saliency fusion. In this work, we designed a network for better edge quality in salient object detection. We proposed a contour-saliency blending module to exchange information between contour and saliency. We adopted recursive CNN to increase contour-saliency fusion while keeping the total trainable parameters the same. Furthermore, we designed a stage-wise feature extraction module to help the model pick up the most helpful features from previous intermediate saliency predictions. Besides, we proposed two new loss functions, namely Dual Confinement Loss and Confidence Loss, for our model to generate better boundary predictions. Evaluation results on five common benchmark datasets reveal that our model achieves competitive state-of-the-art performance. Last but not least, our model is lightweight and fast, with only 27.9 million parameters and real-time inferencing at 31 FPS.
Solve routing problems with a residual edge-graph attention neural network
May 06, 2021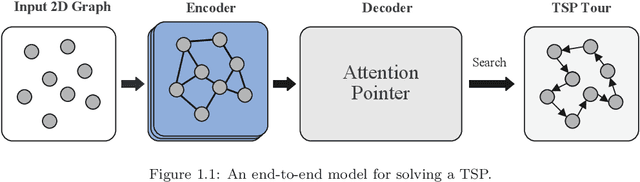
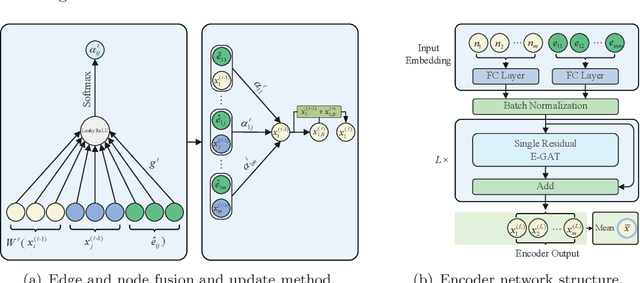
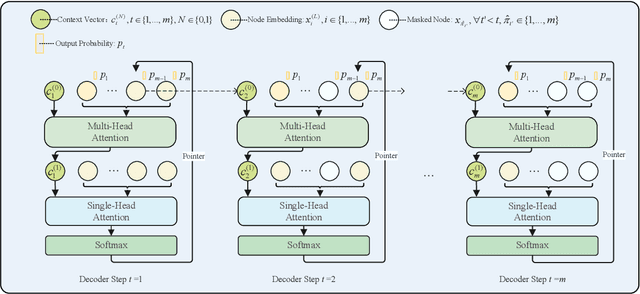
For NP-hard combinatorial optimization problems, it is usually difficult to find high-quality solutions in polynomial time. The design of either an exact algorithm or an approximate algorithm for these problems often requires significantly specialized knowledge. Recently, deep learning methods provide new directions to solve such problems. In this paper, an end-to-end deep reinforcement learning framework is proposed to solve this type of combinatorial optimization problems. This framework can be applied to different problems with only slight changes of input (for example, for a traveling salesman problem (TSP), the input is the two-dimensional coordinates of nodes; while for a capacity-constrained vehicle routing problem (CVRP), the input is simply changed to three-dimensional vectors including the two-dimensional coordinates and the customer demands of nodes), masks and decoder context vectors. The proposed framework is aiming to improve the models in literacy in terms of the neural network model and the training algorithm. The solution quality of TSP and the CVRP up to 100 nodes are significantly improved via our framework. Specifically, the average optimality gap is reduced from 4.53\% (reported best \cite{R22}) to 3.67\% for TSP with 100 nodes and from 7.34\% (reported best \cite{R22}) to 6.68\% for CVRP with 100 nodes when using the greedy decoding strategy. Furthermore, our framework uses about 1/3$\sim$3/4 training samples compared with other existing learning methods while achieving better results. The results performed on randomly generated instances and the benchmark instances from TSPLIB and CVRPLIB confirm that our framework has a linear running time on the problem size (number of nodes) during the testing phase, and has a good generalization performance from random instance training to real-world instance testing.
Real-time Air Pollution prediction model based on Spatiotemporal Big data
Aug 10, 2018

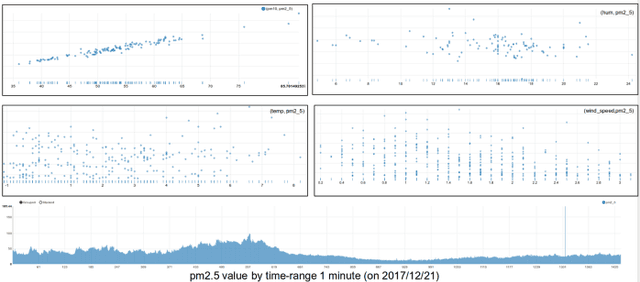
Air pollution is one of the most concerns for urban areas. Many countries have constructed monitoring stations to hourly collect pollution values. Recently, there is a research in Daegu city, Korea for real-time air quality monitoring via sensors installed on taxis running across the whole city. The collected data is huge (1-second interval) and in both Spatial and Temporal format. In this paper, based on this spatiotemporal Big data, we propose a real-time air pollution prediction model based on Convolutional Neural Network (CNN) algorithm for image-like Spatial distribution of air pollution. Regarding to Temporal information in the data, we introduce a combination of a Long Short-Term Memory (LSTM) unit for time series data and a Neural Network model for other air pollution impact factors such as weather conditions to build a hybrid prediction model. This model is simple in architecture but still brings good prediction ability.
* 6 pages
FreeTickets: Accurate, Robust and Efficient Deep Ensemble by Training with Dynamic Sparsity
Jun 28, 2021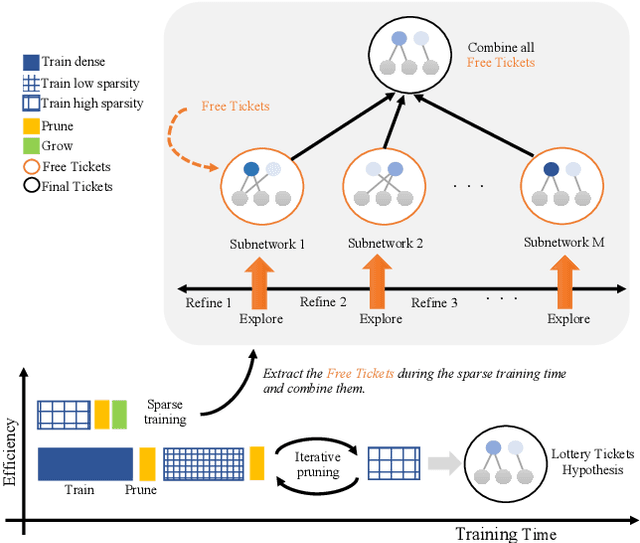
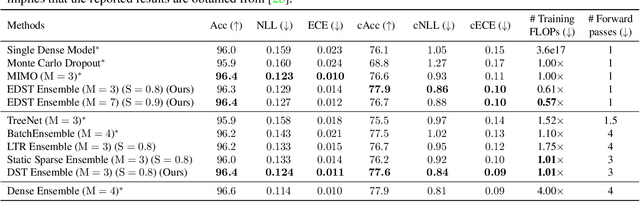
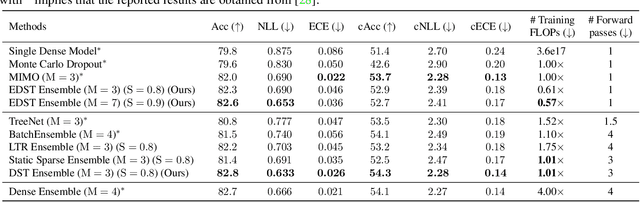
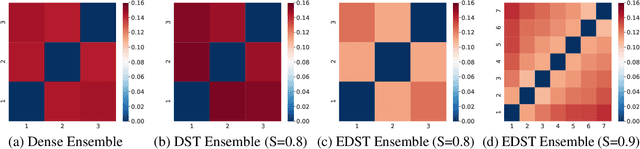
Recent works on sparse neural networks have demonstrated that it is possible to train a sparse network in isolation to match the performance of the corresponding dense networks with a fraction of parameters. However, the identification of these performant sparse neural networks (winning tickets) either involves a costly iterative train-prune-retrain process (e.g., Lottery Ticket Hypothesis) or an over-extended sparse training time (e.g., Training with Dynamic Sparsity), both of which would raise financial and environmental concerns. In this work, we attempt to address this cost-reducing problem by introducing the FreeTickets concept, as the first solution which can boost the performance of sparse convolutional neural networks over their dense network equivalents by a large margin, while using for complete training only a fraction of the computational resources required by the latter. Concretely, we instantiate the FreeTickets concept, by proposing two novel efficient ensemble methods with dynamic sparsity, which yield in one shot many diverse and accurate tickets "for free" during the sparse training process. The combination of these free tickets into an ensemble demonstrates a significant improvement in accuracy, uncertainty estimation, robustness, and efficiency over the corresponding dense (ensemble) networks. Our results provide new insights into the strength of sparse neural networks and suggest that the benefits of sparsity go way beyond the usual training/inference expected efficiency. We will release all codes in https://github.com/Shiweiliuiiiiiii/FreeTickets.
Real Time Elbow Angle Estimation Using Single RGB Camera
Aug 21, 2018The use of motion capture has increased from last decade in a varied spectrum of applications like film special effects, controlling games and robots, rehabilitation system, animations etc. The current human motion capture techniques use markers, structured environment, and high resolution cameras in a dedicated environment. Because of rapid movement, elbow angle estimation is observed as the most difficult problem in human motion capture system. In this paper, we take elbow angle estimation as our research subject and propose a novel, markerless and cost-effective solution that uses RGB camera for estimating elbow angle in real time using part affinity field. We have recruited five (5) participants to perform cup to mouth movement and at the same time measured the angle by both RGB camera and Microsoft Kinect. The experimental results illustrate that markerless and cost-effective RGB camera has a median RMS errors of 3.06{\deg} and 0.95{\deg} in sagittal and coronal plane respectively as compared to Microsoft Kinect.
Dealing with training and test segmentation mismatch: FBK@IWSLT2021
Jun 28, 2021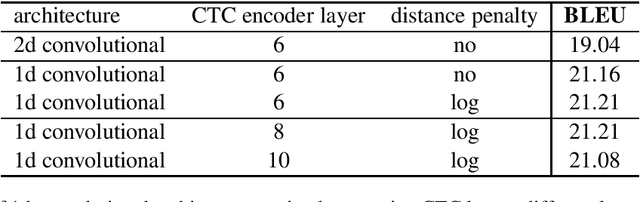

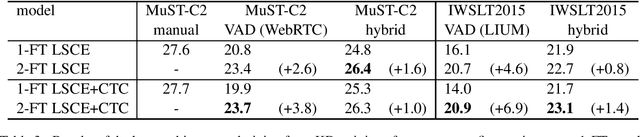
This paper describes FBK's system submission to the IWSLT 2021 Offline Speech Translation task. We participated with a direct model, which is a Transformer-based architecture trained to translate English speech audio data into German texts. The training pipeline is characterized by knowledge distillation and a two-step fine-tuning procedure. Both knowledge distillation and the first fine-tuning step are carried out on manually segmented real and synthetic data, the latter being generated with an MT system trained on the available corpora. Differently, the second fine-tuning step is carried out on a random segmentation of the MuST-C v2 En-De dataset. Its main goal is to reduce the performance drops occurring when a speech translation model trained on manually segmented data (i.e. an ideal, sentence-like segmentation) is evaluated on automatically segmented audio (i.e. actual, more realistic testing conditions). For the same purpose, a custom hybrid segmentation procedure that accounts for both audio content (pauses) and for the length of the produced segments is applied to the test data before passing them to the system. At inference time, we compared this procedure with a baseline segmentation method based on Voice Activity Detection (VAD). Our results indicate the effectiveness of the proposed hybrid approach, shown by a reduction of the gap with manual segmentation from 8.3 to 1.4 BLEU points.
Approximate Novelty Search
May 17, 2021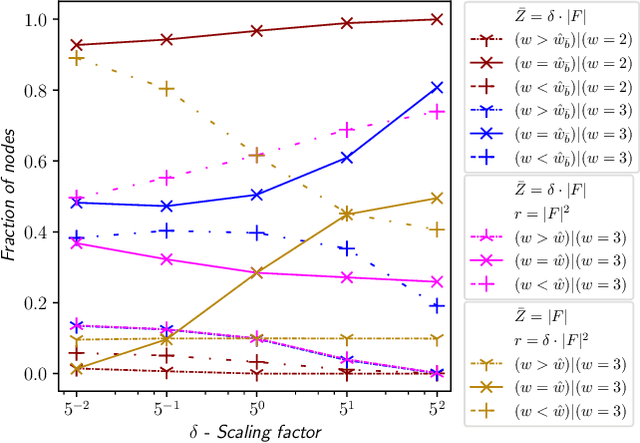
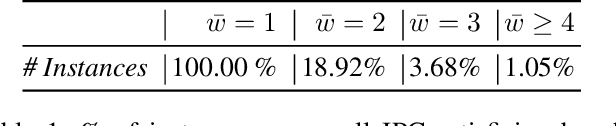
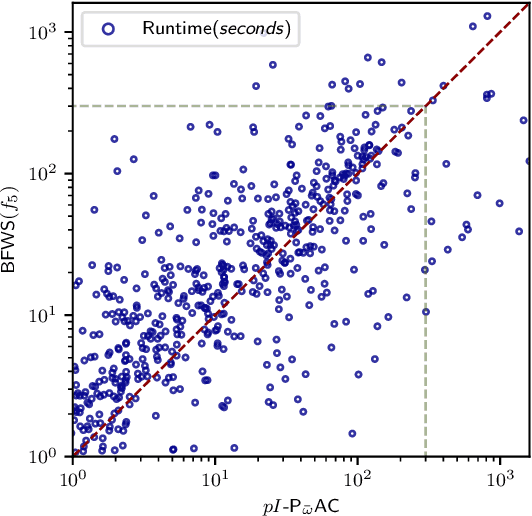
Width-based search algorithms seek plans by prioritizing states according to a suitably defined measure of novelty, that maps states into a set of novelty categories. Space and time complexity to evaluate state novelty is known to be exponential on the cardinality of the set. We present novel methods to obtain polynomial approximations of novelty and width-based search. First, we approximate novelty computation via random sampling and Bloom filters, reducing the runtime and memory footprint. Second, we approximate the best-first search using an adaptive policy that decides whether to forgo the expansion of nodes in the open list. These two techniques are integrated into existing width-based algorithms, resulting in new planners that perform significantly better than other state-of-the-art planners over benchmarks from the International Planning Competitions.
An Explainable Probabilistic Classifier for Categorical Data Inspired to Quantum Physics
May 26, 2021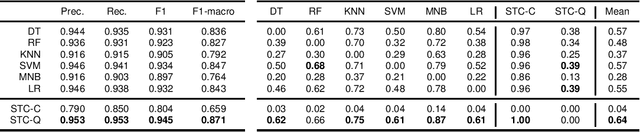

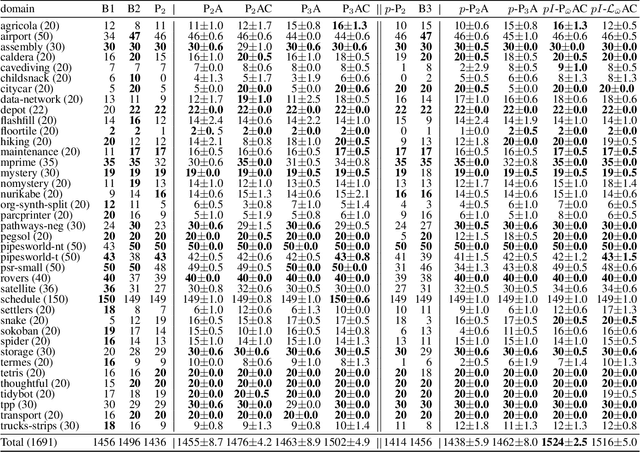
This paper presents Sparse Tensor Classifier (STC), a supervised classification algorithm for categorical data inspired by the notion of superposition of states in quantum physics. By regarding an observation as a superposition of features, we introduce the concept of wave-particle duality in machine learning and propose a generalized framework that unifies the classical and the quantum probability. We show that STC possesses a wide range of desirable properties not available in most other machine learning methods but it is at the same time exceptionally easy to comprehend and use. Empirical evaluation of STC on structured data and text classification demonstrates that our methodology achieves state-of-the-art performances compared to both standard classifiers and deep learning, at the additional benefit of requiring minimal data pre-processing and hyper-parameter tuning. Moreover, STC provides a native explanation of its predictions both for single instances and for each target label globally.
Energy Efficient Reconfigurable Intelligent Surface Enabled Mobile Edge Computing Networks with NOMA
Apr 30, 2021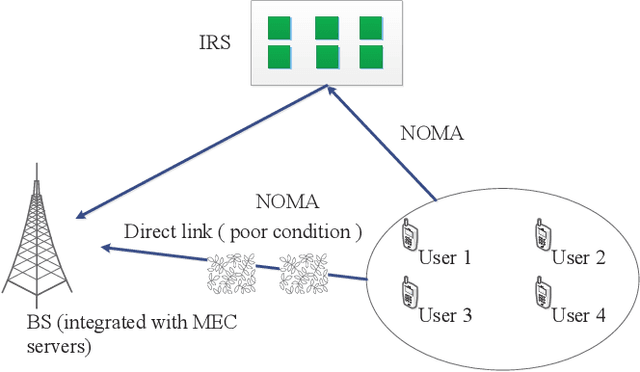
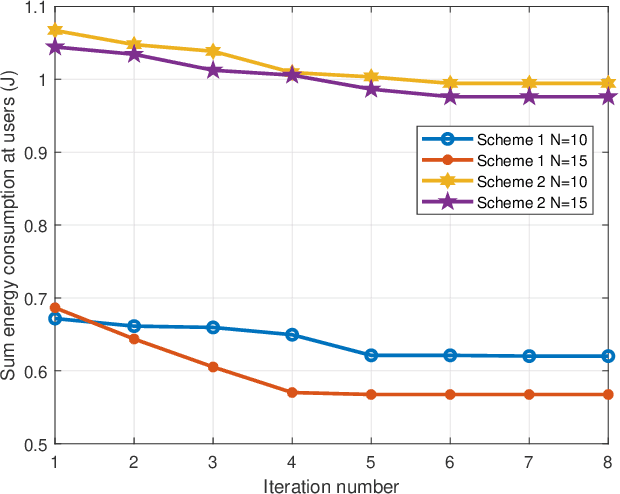
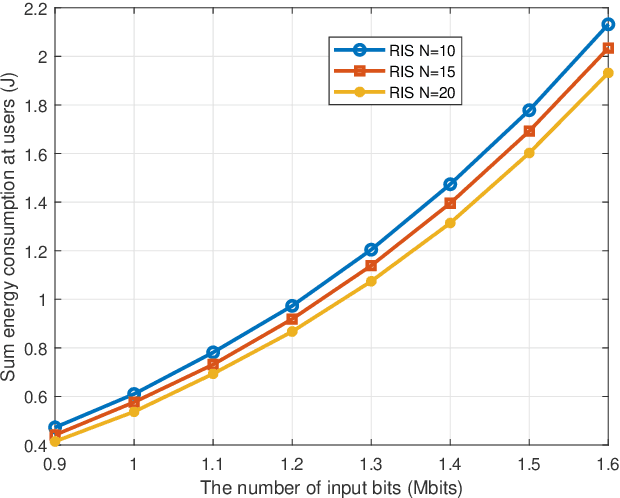
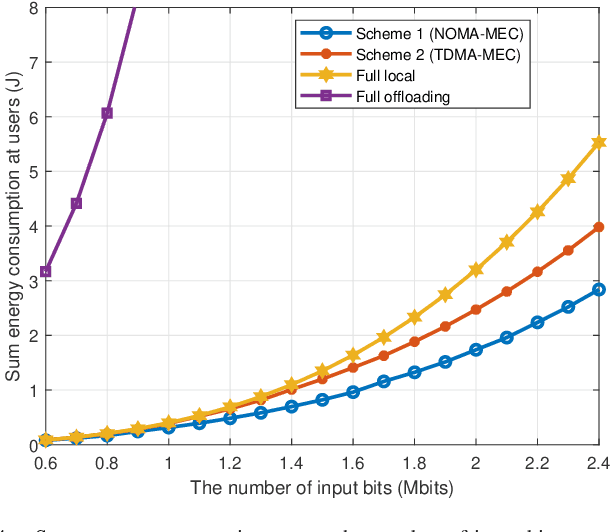
Reconfigurable intelligent surface (RIS) has emerged as a promising technology for achieving high spectrum and energy efficiency in future wireless communication networks. In this paper, we investigate an RIS-aided single-cell multi-user mobile edge computing (MEC) system where an RIS is deployed to support the communication between a base station (BS) equipped with MEC servers and multiple single-antenna users. To utilize the scarce frequency resource efficiently, we assume that users communicate with BS based on a non-orthogonal multiple access (NOMA) protocol. Each user has a computation task which can be computed locally or partially/fully offloaded to the BS. We aim to minimize the sum energy consumption of all users by jointly optimizing the passive phase shifters, the size of transmission data, transmission rate, power control, transmission time and the decoding order. Since the resulting problem is non-convex, we use the block coordinate descent method to alternately optimize two separated subproblems. More specifically, we use the dual method to tackle a subproblem with given phase shift and obtain the closed-form solution; and then we utilize penalty method to solve another subproblem for given power control. Moreover, in order to demonstrate the effectiveness of our proposed algorithm, we propose three benchmark schemes: the time-division multiple access (TDMA)-MEC scheme, the full local computing scheme and the full offloading scheme. We use an alternating 1-D search method and the dual method that can solve the TDMA-based transmission problem well. Numerical results demonstrate that the proposed scheme can increase the energy efficiency and achieve significant performance gains over the three benchmark schemes.
Zero-sample surface defect detection and classification based on semantic feedback neural network
Jun 15, 2021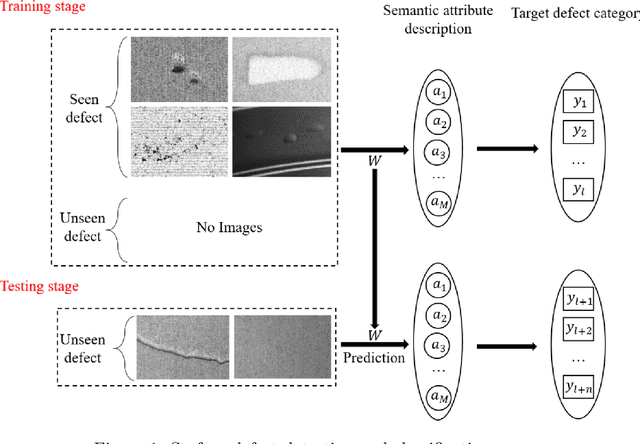



Defect detection and classification technology has changed from traditional artificial visual inspection to current intelligent automated inspection, but most of the current defect detection methods are training related detection models based on a data-driven approach, taking into account the difficulty of collecting some sample data in the industrial field. We apply zero-shot learning technology to the industrial field. Aiming at the problem of the existing "Latent Feature Guide Attribute Attention" (LFGAA) zero-shot image classification network, the output latent attributes and artificially defined attributes are different in the semantic space, which leads to the problem of model performance degradation, proposed an LGFAA network based on semantic feedback, and improved model performance by constructing semantic embedded modules and feedback mechanisms. At the same time, for the common domain shift problem in zero-shot learning, based on the idea of co-training algorithm using the difference information between different views of data to learn from each other, we propose an Ensemble Co-training algorithm, which adaptively reduces the prediction error in image tag embedding from multiple angles. Various experiments conducted on the zero-shot dataset and the cylinder liner dataset in the industrial field provide competitive results.