 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBK's Long-form SpeechLLMs for IWSLT 2026 Instruction Following
Jun 25, 2026This paper describes our submission to the IWSLT 2026 Instruction Following shared task. SpeechLLMs are developed for both short-form and long-form speech instruction following under constrained settings. For the short track, strong performance is achieved on MCIF, with a SIFS score of 2.0708. For the long track, three speech segmentation methods are explored, and the HIFS score is introduced to account for unstable long-form generation. Experimental results show that fixed 30-second segmentation provides the most robust long-form performance, achieving the highest HIFS score of 2.0663. Further analysis shows that hallucination mainly manifests as repetitive insertions in generated outputs, substantially affecting ASR and SSUM, while short-form capabilities are largely retained after long-form extension.
Simulstream: Open-Source Toolkit for Evaluation and Demonstration of Streaming Speech-to-Text Translation Systems
Dec 19, 2025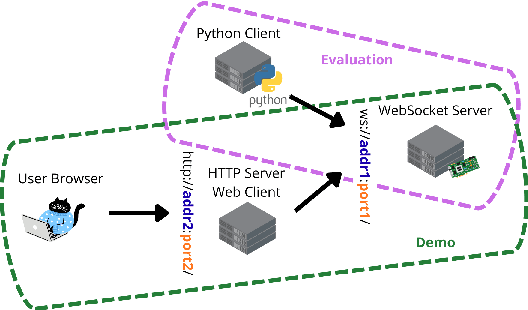
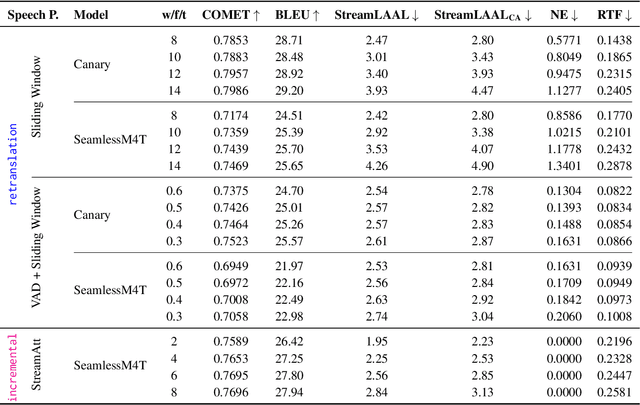
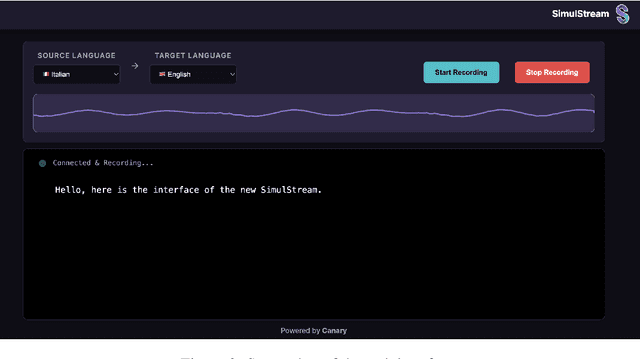
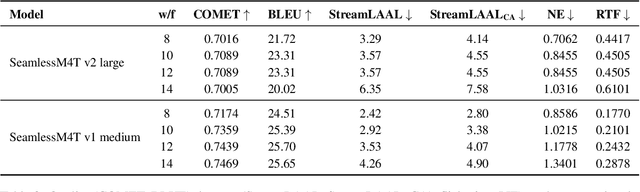
Streaming Speech-to-Text Translation (StreamST) requires producing translations concurrently with incoming speech, imposing strict latency constraints and demanding models that balance partial-information decision-making with high translation quality. Research efforts on the topic have so far relied on the SimulEval repository, which is no longer maintained and does not support systems that revise their outputs. In addition, it has been designed for simulating the processing of short segments, rather than long-form audio streams, and it does not provide an easy method to showcase systems in a demo. As a solution, we introduce simulstream, the first open-source framework dedicated to unified evaluation and demonstration of StreamST systems. Designed for long-form speech processing, it supports not only incremental decoding approaches, but also re-translation methods, enabling for their comparison within the same framework both in terms of quality and latency. In addition, it also offers an interactive web interface to demo any system built within the tool.
The Unheard Alternative: Contrastive Explanations for Speech-to-Text Models
Sep 30, 2025



Contrastive explanations, which indicate why an AI system produced one output (the target) instead of another (the foil), are widely regarded in explainable AI as more informative and interpretable than standard explanations. However, obtaining such explanations for speech-to-text (S2T) generative models remains an open challenge. Drawing from feature attribution techniques, we propose the first method to obtain contrastive explanations in S2T by analyzing how parts of the input spectrogram influence the choice between alternative outputs. Through a case study on gender assignment in speech translation, we show that our method accurately identifies the audio features that drive the selection of one gender over another. By extending the scope of contrastive explanations to S2T, our work provides a foundation for better understanding S2T models.
The Warmup Dilemma: How Learning Rate Strategies Impact Speech-to-Text Model Convergence
May 29, 2025Training large-scale models presents challenges not only in terms of resource requirements but also in terms of their convergence. For this reason, the learning rate (LR) is often decreased when the size of a model is increased. Such a simple solution is not enough in the case of speech-to-text (S2T) trainings, where evolved and more complex variants of the Transformer architecture -- e.g., Conformer or Branchformer -- are used in light of their better performance. As a workaround, OWSM designed a double linear warmup of the LR, increasing it to a very small value in the first phase before updating it to a higher value in the second phase. While this solution worked well in practice, it was not compared with alternative solutions, nor was the impact on the final performance of different LR warmup schedules studied. This paper fills this gap, revealing that i) large-scale S2T trainings demand a sub-exponential LR warmup, and ii) a higher LR in the warmup phase accelerates initial convergence, but it does not boost final performance.
FAMA: The First Large-Scale Open-Science Speech Foundation Model for English and Italian
May 28, 2025The development of speech foundation models (SFMs) like Whisper and SeamlessM4T has significantly advanced the field of speech processing. However, their closed nature--with inaccessible training data and code--poses major reproducibility and fair evaluation challenges. While other domains have made substantial progress toward open science by developing fully transparent models trained on open-source (OS) code and data, similar efforts in speech remain limited. To fill this gap, we introduce FAMA, the first family of open science SFMs for English and Italian, trained on 150k+ hours of OS speech data. Moreover, we present a new dataset containing 16k hours of cleaned and pseudo-labeled speech for both languages. Results show that FAMA achieves competitive performance compared to existing SFMs while being up to 8 times faster. All artifacts, including code, datasets, and models, are released under OS-compliant licenses, promoting openness in speech technology research.
Granary: Speech Recognition and Translation Dataset in 25 European Languages
May 19, 2025Multi-task and multilingual approaches benefit large models, yet speech processing for low-resource languages remains underexplored due to data scarcity. To address this, we present Granary, a large-scale collection of speech datasets for recognition and translation across 25 European languages. This is the first open-source effort at this scale for both transcription and translation. We enhance data quality using a pseudo-labeling pipeline with segmentation, two-pass inference, hallucination filtering, and punctuation restoration. We further generate translation pairs from pseudo-labeled transcriptions using EuroLLM, followed by a data filtration pipeline. Designed for efficiency, our pipeline processes vast amount of data within hours. We assess models trained on processed data by comparing their performance on previously curated datasets for both high- and low-resource languages. Our findings show that these models achieve similar performance using approx. 50% less data. Dataset will be made available at https://hf.co/datasets/nvidia/Granary
NUTSHELL: A Dataset for Abstract Generation from Scientific Talks
Feb 24, 2025Scientific communication is receiving increasing attention in natural language processing, especially to help researches access, summarize, and generate content. One emerging application in this area is Speech-to-Abstract Generation (SAG), which aims to automatically generate abstracts from recorded scientific presentations. SAG enables researchers to efficiently engage with conference talks, but progress has been limited by a lack of large-scale datasets. To address this gap, we introduce NUTSHELL, a novel multimodal dataset of *ACL conference talks paired with their corresponding abstracts. We establish strong baselines for SAG and evaluate the quality of generated abstracts using both automatic metrics and human judgments. Our results highlight the challenges of SAG and demonstrate the benefits of training on NUTSHELL. By releasing NUTSHELL under an open license (CC-BY 4.0), we aim to advance research in SAG and foster the development of improved models and evaluation methods.
Prepending or Cross-Attention for Speech-to-Text? An Empirical Comparison
Jan 04, 2025



Following the remarkable success of Large Language Models (LLMs) in NLP tasks, there is increasing interest in extending their capabilities to speech -- the most common form in communication. To integrate speech into LLMs, one promising approach is dense feature prepending (DFP) which prepends the projected speech representations to the textual representations, allowing end-to-end training with the speech encoder. However, DFP typically requires connecting a text decoder to a speech encoder. This raises questions about the importance of having a sophisticated speech encoder for DFP, and how its performance compares with a standard encoder-decoder (i.e. cross-attention) architecture. In order to perform a controlled architectural comparison, we train all models from scratch, rather than using large pretrained models, and use comparable data and parameter settings, testing speech-to-text recognition (ASR) and translation (ST) on MuST-C v1.0 and CoVoST2 datasets. We study the influence of a speech encoder in DFP. More importantly, we compare DFP and cross-attention under a variety of configurations, such as CTC compression, sequence-level knowledge distillation, generation speed and GPU memory footprint on monolingual, bilingual and multilingual models. Despite the prevalence of DFP over cross-attention, our overall results do not indicate a clear advantage of DFP.
Speech Foundation Models and Crowdsourcing for Efficient, High-Quality Data Collection
Dec 16, 2024



While crowdsourcing is an established solution for facilitating and scaling the collection of speech data, the involvement of non-experts necessitates protocols to ensure final data quality. To reduce the costs of these essential controls, this paper investigates the use of Speech Foundation Models (SFMs) to automate the validation process, examining for the first time the cost/quality trade-off in data acquisition. Experiments conducted on French, German, and Korean data demonstrate that SFM-based validation has the potential to reduce reliance on human validation, resulting in an estimated cost saving of over 40.0% without degrading final data quality. These findings open new opportunities for more efficient, cost-effective, and scalable speech data acquisition.
SPES: Spectrogram Perturbation for Explainable Speech-to-Text Generation
Nov 03, 2024



Spurred by the demand for interpretable models, research on eXplainable AI for language technologies has experienced significant growth, with feature attribution methods emerging as a cornerstone of this progress. While prior work in NLP explored such methods for classification tasks and textual applications, explainability intersecting generation and speech is lagging, with existing techniques failing to account for the autoregressive nature of state-of-the-art models and to provide fine-grained, phonetically meaningful explanations. We address this gap by introducing Spectrogram Perturbation for Explainable Speech-to-text Generation (SPES), a feature attribution technique applicable to sequence generation tasks with autoregressive models. SPES provides explanations for each predicted token based on both the input spectrogram and the previously generated tokens. Extensive evaluation on speech recognition and translation demonstrates that SPES generates explanations that are faithful and plausible to humans.