 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIQA: A Unified Framework for Both Full-Reference and No-Reference Image Quality Assessment
Oct 14, 2023The human visual system (HVS) is effective at distinguishing low-quality images due to its ability to sense the distortion level and the resulting semantic impact. Prior research focuses on developing dedicated networks based on the presence and absence of pristine images, respectively, and this results in limited application scope and potential performance inconsistency when switching from NR to FR IQA. In addition, most methods heavily rely on spatial distortion modeling through difference maps or weighted features, and this may not be able to well capture the correlations between distortion and the semantic impact it causes. To this end, we aim to design a unified network for both Full-Reference (FR) and No-Reference (NR) IQA via semantic impact modeling. Specifically, we employ an encoder to extract multi-level features from input images. Then a Hierarchical Self-Attention (HSA) module is proposed as a universal adapter for both FR and NR inputs to model the spatial distortion level at each encoder stage. Furthermore, considering that distortions contaminate encoder stages and damage image semantic meaning differently, a Cross-Scale Cross-Attention (CSCA) module is proposed to examine correlations between distortion at shallow stages and deep ones. By adopting HSA and CSCA, the proposed network can effectively perform both FR and NR IQA. Extensive experiments demonstrate that the proposed simple network is effective and outperforms the relevant state-of-the-art FR and NR methods on four synthetic-distorted datasets and three authentic-distorted datasets.
SelfReformer: Self-Refined Network with Transformer for Salient Object Detection
May 23, 2022
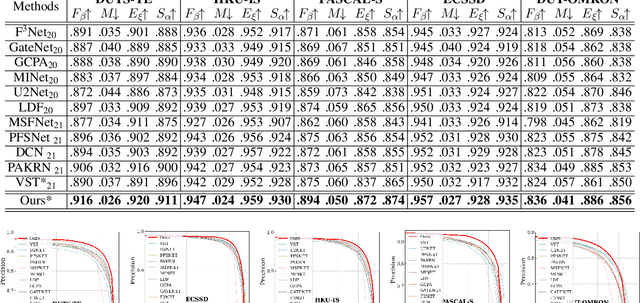
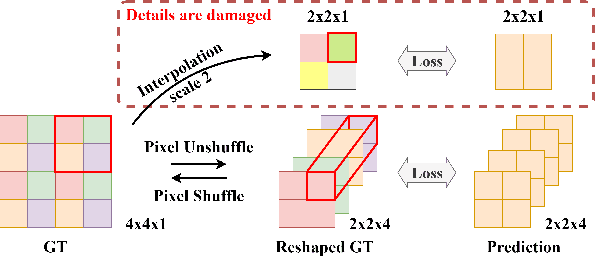

The global and local contexts significantly contribute to the integrity of predictions in Salient Object Detection (SOD). Unfortunately, existing methods still struggle to generate complete predictions with fine details. There are two major problems in conventional approaches: first, for global context, high-level CNN-based encoder features cannot effectively catch long-range dependencies, resulting in incomplete predictions. Second, downsampling the ground truth to fit the size of predictions will introduce inaccuracy as the ground truth details are lost during interpolation or pooling. Thus, in this work, we developed a Transformer-based network and framed a supervised task for a branch to learn the global context information explicitly. Besides, we adopt Pixel Shuffle from Super-Resolution (SR) to reshape the predictions back to the size of ground truth instead of the reverse. Thus details in the ground truth are untouched. In addition, we developed a two-stage Context Refinement Module (CRM) to fuse global context and automatically locate and refine the local details in the predictions. The proposed network can guide and correct itself based on the global and local context generated, thus is named, Self-Refined Transformer (SelfReformer). Extensive experiments and evaluation results on five benchmark datasets demonstrate the outstanding performance of the network, and we achieved the state-of-the-art.
Recursive Contour Saliency Blending Network for Accurate Salient Object Detection
May 31, 2021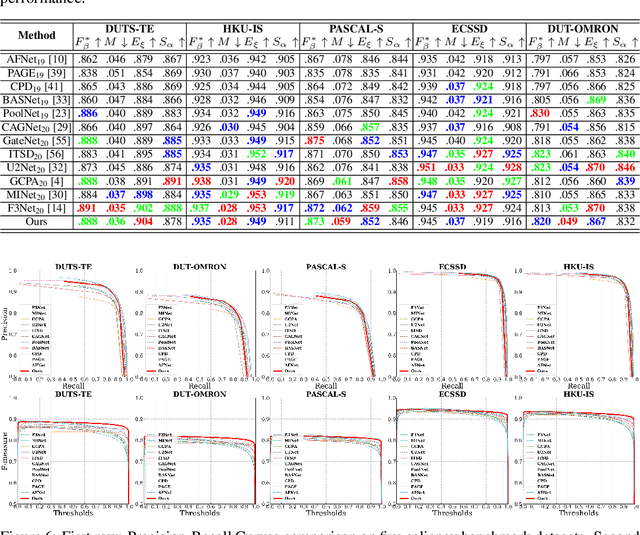
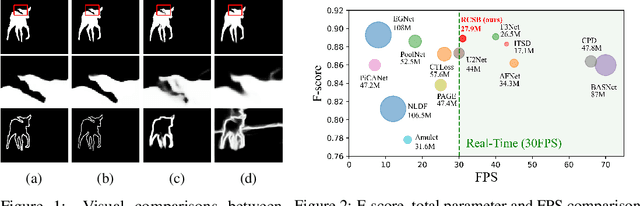
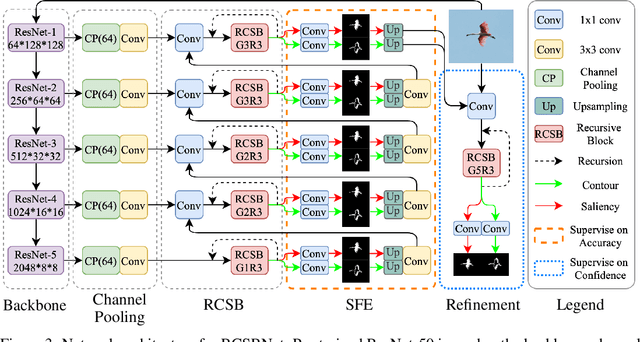
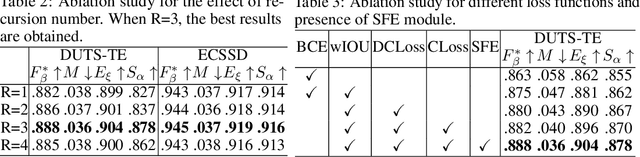
Contour information plays a vital role in salient object detection. However, excessive false positives remain in predictions from existing contour-based models due to insufficient contour-saliency fusion. In this work, we designed a network for better edge quality in salient object detection. We proposed a contour-saliency blending module to exchange information between contour and saliency. We adopted recursive CNN to increase contour-saliency fusion while keeping the total trainable parameters the same. Furthermore, we designed a stage-wise feature extraction module to help the model pick up the most helpful features from previous intermediate saliency predictions. Besides, we proposed two new loss functions, namely Dual Confinement Loss and Confidence Loss, for our model to generate better boundary predictions. Evaluation results on five common benchmark datasets reveal that our model achieves competitive state-of-the-art performance. Last but not least, our model is lightweight and fast, with only 27.9 million parameters and real-time inferencing at 31 FPS.